記一個 ConcurrentHashMap 使用不當導致的并發事故
一、引言
我們都知道ConcurrentHashMap可以保證鍵值對并發插入安全,因為其key值唯一性的原因,所以hutool對其進行了進一步的封裝實現了一個ConcurrentHashSet,代碼如下,即判斷put后是否返回null,若是null則說明是第一次插入,反之就是存在重復元素,返回已存在的元素值。從而保證并發插入元素線程安全且唯一。
//hutool的ConcurrentHashSet通過判斷返回null得知之前是否插入過重復元素
@Override
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}但是如果對于這些映射容器的鍵使用不當就可能導致唯一鍵值對多次插入的情況,所以本文將基于筆者前段時間遇到的經典的例子為切入點,深入剖析該問題的原因和解決思路。

二、詳解ConcurrentHashMap并發重復插入問題
1. 需求說明
我們現在有這樣一個需求,大體是通過數據庫獲取要處理的任務并按照如下步驟執行:
- 從數據庫讀取未完成(status為0)的任務,將其采用并發容器(ConcurrentHashSet)存放,key為這個任務對象
- 工作線程處理,并在內存中將其設置為1
- 定時任務線程從容器中讀取這些任務并移除
- 將已完成任務狀態寫回庫中

2. 落地代碼
對應任務表的實體類封裝如下,我們的加載到ConcurrentHashSet會被多個線程并發的調度處理,處理過程中會并發更新狀態。
@Data
publicclass Task {
privateint id;
/**
* 任務名稱
*/
private String taskName;
/**
* 0.未開始
* 1.進行中
* 2.已完成
*/
privateint status;
}對應的實現代碼如下,可以看到從數據庫讀取未開始的任務,線程1將其更新為處理完成后更新為處理中,線程2處理完成后更新為已完成:
public static void main(String[] args) throws InterruptedException {
ConcurrentHashSet<Task> set = new ConcurrentHashSet<>();
CountDownLatch countDownLatch = new CountDownLatch(2);
//假設從數據庫讀取一個task
Task task = new Task();
task.setId(1);
task.setTaskName("任務1");
task.setStatus(0);
set.add(task);
//模擬多線程并發更新
//線程1更新為處理中
new Thread(() -> {
log.info("線程1處理中....");
task.setStatus(1);
set.add(task);
countDownLatch.countDown();
}, "t1").start();
//線程2更新為已完成
new Thread(() -> {
log.info("線程2處理中....");
task.setStatus(2);
set.add(task);
countDownLatch.countDown();
}, "t2").start();
countDownLatch.await();
log.info("set size:{}", set.size());
}輸出結果如下,可以看到明明同一個對象,結果插入了3次:
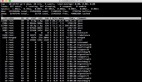
00:44:32.637 [main] INFO com.sharkChili.webTemplate.Main - set size:3調試查看set內部,3個元素都指向我們的唯一的任務-1。

3. 事故原因
我們都知道JDK8版本無論是HashMap還是ConcurrentHashMap底層采用數組+鏈表/紅黑樹,元素進行插入前都需要進行hash運算定位數組索引,然后使用equal和hashCode比較的過程元素是否存在。 很明顯,我們上文并發操作元素時修改了status字典,導致每次得出的hashCode結果值改變了,進而導致同一個元素因為不同的hashCode插入到不同的位置,出現去重失敗:

對應筆者也給出ConcurrentHashMap的put方法底層實現:
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) thrownew NullPointerException();
//計算key的hash值,因為我們動態修改了status導致hash值不同
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//因為hash值不同每次定位到的i位置不同,最終存到不同的位置
elseif ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
}
.....
}4. 解決方案
很明顯出現這個問題的原因就是因為并發操作修改的status影響了hashcode計算結果,進而導致并發操作變得無效,因為id是全局唯一的,所以直接重寫hashCode和equals方法,讓Task對象的計算和比對都通過id進行:
@Data
publicclass Task {
//......略
@Override
public boolean equals(Object o) {
if (this == o) returntrue;
if (o == null || getClass() != o.getClass()) returnfalse;
Task task = (Task) o;
return id == task.id;
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}三、小結
總的來說,對于這類涉及并發操作的重構,建議梳理清晰的數據流向并結合源碼工作流程加以推斷分析,最終明確問題風險點直接進行邏輯修復并及時提測。