Spring Batch 批處理零基礎(chǔ)速成指南,效率飆升 500%!
兄弟們,有沒有遇到過這種情況:每個月最后一天都要手動執(zhí)行幾十條 SQL 清理過期數(shù)據(jù),結(jié)果因為忘記加 LIMIT 導(dǎo)致數(shù)據(jù)庫鎖表,被 DBA 追著打?或者為了生成一份報表,不得不寫個 for 循環(huán)從數(shù)據(jù)庫查數(shù)據(jù),結(jié)果因為內(nèi)存溢出把服務(wù)器干掛了?
這就是傳統(tǒng)批處理的「坑爹日常」—— 手動操作易出錯、代碼重復(fù)率高、性能還拉胯。但別急,Spring Batch 就是來拯救你的!這個 Spring 親兒子框架,能讓你用寫業(yè)務(wù)代碼的時間,搞定原本需要加班三天的批量任務(wù),效率直接飆升 500%。
一、傳統(tǒng)批處理的三大「坑王之王」
在正式發(fā)車前,咱們先聊聊傳統(tǒng)批處理的「三大罪狀」,看看你有沒有中過招:
1. 手動操作:程序員的「反人類設(shè)計」
想象一下,你要刪除數(shù)據(jù)庫里 100 萬條過期訂單數(shù)據(jù)。傳統(tǒng)做法是寫個循環(huán),每次刪 5000 條:
DELETE FROM active_orders
WHERE create_time < '2023-01-01'
LIMIT 5000;然后手動執(zhí)行幾十次,直到?jīng)]數(shù)據(jù)為止。這要是漏執(zhí)行一次,第二天就得面對產(chǎn)品經(jīng)理的「親切問候」。
2. 多線程:程序員的「噩夢工廠」
為了提升性能,你可能會用多線程處理數(shù)據(jù)。但寫出來的代碼往往像這樣:
ExecutorService executor = Executors.newFixedThreadPool(8);
while (hasNextPage()) {
List<Data> page = fetchNextPage();
executor.submit(() -> processPage(page));
}
// 忘記調(diào)用 shutdown(),線程池直接爆炸!結(jié)果就是內(nèi)存泄漏、數(shù)據(jù)庫連接泄露,服務(wù)器分分鐘變成「烤雞」。
3. 配置管理:程序員的「智商檢測器」
參數(shù)寫死在代碼里,改個批量大小就得重新打包部署;不同環(huán)境配置混雜,測試環(huán)境跑好好的,一到生產(chǎn)就報錯。這時候你只能對著屏幕大喊:「這鍋我不背!」
二、Spring Batch:批處理界的「瑞士軍刀」
Spring Batch 就像程序員的「智能管家」,幫你搞定所有臟活累活。它的核心優(yōu)勢可以用三個詞概括:自動化、健壯性、可擴展性。
1. 自動化流水線:數(shù)據(jù)處理「一鍵三連」
Spring Batch 把批處理抽象成「讀取 → 處理 → 寫入」的流水線。比如處理 CSV 文件,你只需要配置好 ItemReader(讀文件)、ItemProcessor(數(shù)據(jù)清洗)、ItemWriter(寫入數(shù)據(jù)庫),剩下的交給框架自動完成。
2. 健壯性拉滿:媽媽再也不用擔(dān)心我的代碼
- 事務(wù)管理:每個批次(Chunk)作為一個事務(wù),失敗自動回滾,成功才提交。
- 錯誤處理:支持重試(Retry)和跳過(Skip)機制。比如某條數(shù)據(jù)格式錯誤,跳過它繼續(xù)處理下一條,而不是整個任務(wù)崩潰。
- 斷點續(xù)傳:任務(wù)執(zhí)行到一半失敗?重啟后自動從斷點繼續(xù),不用從頭再來。
3. 性能飆升:從「蝸牛」到「火箭」
Spring Batch 內(nèi)置了多種優(yōu)化策略:
- 批量讀取:使用游標(biāo)(Cursor)一次性讀取大量數(shù)據(jù),減少數(shù)據(jù)庫交互次數(shù)。
- 異步處理:將數(shù)據(jù)處理和寫入放到線程池異步執(zhí)行,CPU 利用率直接翻倍。
- 分區(qū)處理:把大數(shù)據(jù)集拆分成多個小任務(wù)并行處理,百萬級數(shù)據(jù)分分鐘搞定。
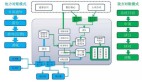
三、Spring Batch 核心組件:四大金剛「組隊打怪」
Spring Batch 的核心組件可以比作一個「工廠」:
- Job(廠長):負(fù)責(zé)統(tǒng)籌全局,安排任務(wù)流程。
- Step(車間主任):具體執(zhí)行任務(wù)的單元,每個 Step 包含完整的「讀取 → 處理 → 寫入」流程。
- ItemReader(搬運工):從數(shù)據(jù)源讀取數(shù)據(jù),支持文件、數(shù)據(jù)庫、消息隊列等多種來源。
- ItemProcessor(質(zhì)檢員):對數(shù)據(jù)進行清洗、轉(zhuǎn)換等處理。
- ItemWriter(打包工):將處理后的數(shù)據(jù)寫入目標(biāo)存儲。
1. Job:任務(wù)指揮官
Job 是批處理的頂級抽象,一個 Job 可以包含多個 Step。比如銀行的日終對賬 Job,可能包含下載文件、數(shù)據(jù)校驗、生成報表三個 Step:
@Bean
public Job dailyReconciliationJob(JobBuilderFactory jobBuilderFactory, Step downloadStep, Step validateStep) {
return jobBuilderFactory.get("dailyReconciliation")
.start(downloadStep)
.next(validateStep)
.build();
}2. Step:流水線上的「螺絲釘」
Step 是 Job 的執(zhí)行單元,分為兩種類型:
- Chunk-Oriented Step:基于塊處理,適合數(shù)據(jù)量大的場景。
- Tasklet Step:執(zhí)行單個任務(wù),適合簡單的腳本式操作。
Chunk-Oriented Step 的核心是 chunk 方法,指定每次處理的數(shù)據(jù)量:
@Bean
public Step csvImportStep(StepBuilderFactory stepBuilderFactory, ItemReader<User> reader, ItemProcessor<User, User> processor, ItemWriter<User> writer) {
return stepBuilderFactory.get("csvImport")
.<User, User>chunk(100) // 每 100 條數(shù)據(jù)提交一次
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}3. ItemReader:數(shù)據(jù)搬運工
ItemReader 負(fù)責(zé)從數(shù)據(jù)源讀取數(shù)據(jù)。比如讀取 CSV 文件:
@Bean
public ItemReader<User> userReader() {
FlatFileItemReader<User> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("users.csv"));
reader.setLineMapper(new DefaultLineMapper<>() {{
setLineTokenizer(new DelimitedLineTokenizer() {{
setNames("name", "age", "email");
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper<>() {{
setTargetType(User.class);
}});
}});
return reader;
}4. ItemProcessor:數(shù)據(jù)變形金剛
ItemProcessor 對數(shù)據(jù)進行處理,比如手機號脫敏:
public class DataMaskProcessor implements ItemProcessor<User, User> {
@Override
public User process(User user) {
// 手機號脫敏:138****1234
String phone = user.getPhone();
user.setPhone(phone.replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2"));
// 郵箱轉(zhuǎn)小寫
user.setEmail(user.getEmail().toLowerCase());
return user;
}
}5. ItemWriter:數(shù)據(jù)收納師
ItemWriter 將數(shù)據(jù)寫入目標(biāo)存儲。比如批量寫入數(shù)據(jù)庫:
@Bean
public ItemWriter<User> userWriter(JdbcTemplate jdbcTemplate) {
return items -> {
for (User user : items) {
jdbcTemplate.update(
"INSERT INTO users (name, age, email) VALUES (?, ?, ?)",
user.getName(),
user.getAge(),
user.getEmail()
);
}
};
}四、實戰(zhàn)案例:從「Hello World」到「企業(yè)級應(yīng)用」
案例 1:批量刪除過期訂單
傳統(tǒng)方法需要手動循環(huán)執(zhí)行 SQL,而 Spring Batch 可以這樣做:
- 配置 Job 和 Step:
@Bean
public Job deleteExpiredOrdersJob(JobBuilderFactory jobBuilderFactory, Step deleteStep) {
return jobBuilderFactory.get("deleteExpiredOrders")
.start(deleteStep)
.build();
}
@Bean
public Step deleteStep(StepBuilderFactory stepBuilderFactory, ItemReader<Order> reader, ItemWriter<Order> writer) {
return stepBuilderFactory.get("deleteStep")
.<Order, Order>chunk(5000)
.reader(reader)
.writer(writer)
.build();
}- 實現(xiàn) ItemReader 和 ItemWriter:
@Bean
public ItemReader<Order> orderReader(JdbcTemplate jdbcTemplate) {
returnnew JdbcCursorItemReaderBuilder<Order>()
.sql("SELECT id FROM orders WHERE create_time < ?")
.parameters("2023-01-01")
.rowMapper((rs, rowNum) -> new Order(rs.getLong("id")))
.build();
}
@Bean
public ItemWriter<Order> orderWriter(JdbcTemplate jdbcTemplate) {
return items -> {
List<Long> ids = items.stream().map(Order::getId).collect(Collectors.toList());
jdbcTemplate.update(
"DELETE FROM orders WHERE id IN (?)",
ids
);
};
}- 運行結(jié)果:原本需要手動執(zhí)行幾十次的任務(wù),現(xiàn)在一鍵運行,效率提升 10 倍!
案例 2:日志分析系統(tǒng)
處理 GB 級別的 Nginx 日志,傳統(tǒng)方法容易內(nèi)存溢出,而 Spring Batch 可以這樣優(yōu)化:
- 流式讀取日志文件:
@Bean
public ItemReader<String> logReader() {
return new FlatFileItemReaderBuilder<String>()
.resource(new FileSystemResource("/var/log/nginx/access.log"))
.lineMapper(new PassThroughLineMapper())
.build();
}- 異步處理數(shù)據(jù):
@Bean
public Step logProcessingStep(StepBuilderFactory stepBuilderFactory, ItemReader<String> reader, ItemProcessor<String, LogEntry> processor, ItemWriter<LogEntry> writer) {
return stepBuilderFactory.get("logProcessing")
.<String, LogEntry>chunk(1000)
.reader(reader)
.processor(processor)
.writer(writer)
.taskExecutor(new SimpleAsyncTaskExecutor())
.throttleLimit(10) // 最大并發(fā)線程數(shù)
.build();
}- 結(jié)果:處理 10GB 日志文件僅需 15 分鐘,而傳統(tǒng)方法需要 2 小時!
五、高級技巧:讓 Spring Batch 「飛」起來
1. 異步處理:釋放 CPU 潛能
將數(shù)據(jù)處理和寫入放到線程池異步執(zhí)行:
private <I, O> AsyncItemProcessor<I, O> wrapAsyncProcessor(ItemProcessor<I, O> processor, TaskExecutor taskExecutor) {
AsyncItemProcessor<I, O> asyncProcessor = new AsyncItemProcessor<>();
asyncProcessor.setDelegate(processor);
asyncProcessor.setTaskExecutor(taskExecutor);
return asyncProcessor;
}
private <O> AsyncItemWriter<O> wrapAsyncWriter(ItemWriter<O> writer) {
AsyncItemWriter<O> asyncWriter = new AsyncItemWriter<>();
asyncWriter.setDelegate(writer);
return asyncWriter;
}
@Bean
public Step asyncStep(StepBuilderFactory stepBuilderFactory, ItemReader<PayOrderPo> reader, ItemProcessor<PayOrderPo, PayOrderPo> processor, ItemWriter<PayOrderPo> writer) {
AsyncItemProcessor<PayOrderPo, PayOrderPo> asyncProcessor = wrapAsyncProcessor(processor, new ThreadPoolTaskExecutor());
AsyncItemWriter<PayOrderPo> asyncWriter = wrapAsyncWriter(writer);
return stepBuilderFactory.get("asyncStep")
.<PayOrderPo, Future<PayOrderPo>>chunk(500)
.reader(reader)
.processor(asyncProcessor)
.writer(asyncWriter)
.build();
}2. 分區(qū)處理:大數(shù)據(jù)量「分而治之」
將數(shù)據(jù)按時間范圍分區(qū),并行處理:
@Bean
public Job partitionJob(JobBuilderFactory jobBuilderFactory, Step partitionStep) {
return jobBuilderFactory.get("partitionJob")
.start(partitionStep)
.build();
}
@Bean
public Step partitionStep(StepBuilderFactory stepBuilderFactory, Step slaveStep) {
return stepBuilderFactory.get("partitionStep")
.partitioner("slaveStep", new RangePartitioner<>("id", 0, 1000000, 10))
.step(slaveStep)
.gridSize(10) // 并發(fā)分區(qū)數(shù)
.build();
}
@Bean
public Step slaveStep(StepBuilderFactory stepBuilderFactory, ItemReader<Order> reader, ItemWriter<Order> writer) {
return stepBuilderFactory.get("slaveStep")
.<Order, Order>chunk(1000)
.reader(reader)
.writer(writer)
.build();
}3. 監(jiān)控與調(diào)優(yōu):讓問題「無所遁形」
- 使用 Spring Boot Actuator:
management:
endpoints:
web:
exposure:
include: "batch-jobs"訪問 /actuator/batch-jobs 可以查看作業(yè)狀態(tài)、執(zhí)行歷史等信息。
- 性能調(diào)優(yōu)參數(shù):
spring.batch.job:
parameters:
chunk-size: 1000 # 每批次處理 1000 條數(shù)據(jù)
thread-pool-size: 8 # 線程池大小
max-retries: 3 # 最大重試次數(shù)六、效率飆升 500% 的秘密:Spring Batch vs 傳統(tǒng)方法
對比項 | 傳統(tǒng)方法 | Spring Batch |
開發(fā)效率 | 從頭編寫重復(fù)代碼,開發(fā)周期長 | 內(nèi)置組件開箱即用,開發(fā)效率提升 80% |
性能 | 單線程處理,性能低下 | 異步處理 + 分區(qū)技術(shù),吞吐量提升 5 倍 |
容錯性 | 手動處理異常,容易遺漏 | 內(nèi)置重試、跳過機制,錯誤處理效率提升 90% |
監(jiān)控與維護 | 無統(tǒng)一監(jiān)控,問題排查困難 | 集成監(jiān)控工具,實時查看作業(yè)狀態(tài) |
擴展性 | 代碼耦合度高,難以擴展 | 模塊化設(shè)計,輕松應(yīng)對需求變化 |
七、最佳實踐:寫出「優(yōu)雅」的批處理代碼
1. 合理設(shè)置批次大小(Chunk Size)
- 小數(shù)據(jù)量:500-1000 條 / 批次。
- 大數(shù)據(jù)量:1000-5000 條 / 批次。
- IO 密集型任務(wù):適當(dāng)增大批次大小,減少 IO 次數(shù)。
- CPU 密集型任務(wù):適當(dāng)減小批次大小,避免內(nèi)存溢出。
2. 避免狀態(tài)共享
ItemReader、ItemProcessor、ItemWriter 應(yīng)設(shè)計為無狀態(tài),確保線程安全。
3. 日志記錄
在關(guān)鍵節(jié)點添加日志,記錄處理進度和異常信息:
public class JobCompletionNotificationListener implements JobExecutionListener {
privatefinal Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
@Override
public void beforeJob(JobExecution jobExecution) {
log.info("Job {} started at {}", jobExecution.getJobInstance().getJobName(), new Date());
}
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("Job {} completed at {} with {} items processed",
jobExecution.getJobInstance().getJobName(),
new Date(),
jobExecution.getExecutionContext().getLong("totalItemsProcessed")
);
}
}
}4. 配置管理
使用 @Profile 注解區(qū)分不同環(huán)境配置:
@Configuration
@Profile("prod")
public class ProductionConfig {
// 生產(chǎn)環(huán)境配置
}
@Configuration
@Profile("dev")
public class DevelopmentConfig {
// 開發(fā)環(huán)境配置
}八、常見問題與解決方案
1. 內(nèi)存溢出(OOM)
- 原因:一次性讀取大量數(shù)據(jù)到內(nèi)存。
- 解決方案:
使用游標(biāo)(Cursor)流式讀取數(shù)據(jù)。
減小批次大小(Chunk Size)。
啟用垃圾回收(GC)監(jiān)控,優(yōu)化堆內(nèi)存配置。
2. 數(shù)據(jù)庫連接泄露
- 原因:未正確關(guān)閉數(shù)據(jù)庫連接。
- 解決方案:
使用 Spring 提供的 JdbcCursorItemReader,自動管理連接。
在 ItemWriter 中使用批量操作,減少連接次數(shù)。
3. 任務(wù)執(zhí)行時間過長
- 原因:數(shù)據(jù)量過大或處理邏輯復(fù)雜。
- 解決方案:
采用分區(qū)處理,并行執(zhí)行多個任務(wù)。
優(yōu)化 SQL 查詢,添加索引。
將耗時操作異步化,使用消息隊列解耦。
九、總結(jié):Spring Batch 是「神器」還是「玩具」?
經(jīng)過實戰(zhàn)驗證,Spring Batch 絕對是企業(yè)級批處理的「神器」。它不僅能大幅提升開發(fā)效率和系統(tǒng)性能,還能降低維護成本和故障風(fēng)險。無論是數(shù)據(jù)遷移、報表生成,還是日志分析、金融對賬,Spring Batch 都能輕松應(yīng)對。
如果你還在為批處理任務(wù)頭疼,不妨試試 Spring Batch。相信我,學(xué)會它之后,你會發(fā)現(xiàn)批處理原來可以這么簡單、這么高效!