微服務(wù)+多級緩存,性能起飛!
兄弟們,上周四半夜三點,朋友發(fā)來消息:“哥救急!”,后面跟著一串截圖:線上微服務(wù)接口超時率飆到 30%,數(shù)據(jù)庫 CPU 干到 100%,運維小哥已經(jīng)在群里 @他八百次了。
我讓他先把接口監(jiān)控發(fā)過來,一眼就看出來問題:商品列表接口沒加緩存,用戶一點開 APP,所有請求直接扎進數(shù)據(jù)庫,就像春運的時候所有人都擠一個檢票口,不堵才怪。后來給他加了個多級緩存,半小時不到,接口響應(yīng)時間從 500ms 降到 20ms,數(shù)據(jù)庫 CPU 直接掉到 10% 以下。 這就是今天要跟大家聊的 “微服務(wù) + 多級緩存”,不是什么高深黑科技,但用好了是真能救命。
一、先吐槽下:單級緩存就是 “瘸腿走路”
很多同學(xué)做微服務(wù),一提緩存就只想到 Redis—— 不是說 Redis 不好,而是單靠它,就像穿一只鞋跑步,跑不遠還容易摔。咱們先掰扯下常見的 “單級緩存誤區(qū)”,看看你是不是也踩過。
1. 只靠本地緩存:像家里冰箱只能自己用
有些同學(xué)圖省事,在服務(wù)里用個 HashMap 當(dāng)本地緩存(更講究點的用 Guava Cache),確實快 —— 畢竟是內(nèi)存操作,比查數(shù)據(jù)庫快 100 倍都不止。但問題來了:微服務(wù)不是單臺機器跑啊!
你部署 10 臺服務(wù)實例,每臺機器的本地緩存都是 “獨立王國”。比如商品價格改了,你只更了其中一臺的緩存,剩下 9 臺還存著舊價格,用戶刷到的價格一會兒高一會兒低,客服電話能被打爆。更坑的是,如果某臺機器緩存里的熱點數(shù)據(jù)過期了,所有請求會突然全扎進這臺機器的數(shù)據(jù)庫,直接把它干崩(這叫 “緩存擊穿” 的局部版)。
簡單說:本地緩存是 “自家冰箱”,只能自己用,鄰居(其他實例)用不上,還容易藏 “過期食物”(舊數(shù)據(jù))。
2. 只靠 Redis:網(wǎng)絡(luò)是個 “隱形殺手”
更多同學(xué)會選 Redis 當(dāng)分布式緩存,畢竟能跨實例共享數(shù)據(jù),還能抗高并發(fā)。但你有沒有算過一筆賬:Redis 再快,也是 “遠程調(diào)用”—— 從服務(wù)實例發(fā)請求到 Redis,再等 Redis 返回,這中間的網(wǎng)絡(luò)開銷可不小。
舉個真實例子:之前幫一個電商項目調(diào)優(yōu),商品詳情接口用了 Redis 緩存,響應(yīng)時間大概 80ms。后來加了本地緩存(Caffeine),同樣的接口直接降到 15ms—— 差了 5 倍多!為啥?因為本地緩存不用走網(wǎng)絡(luò),直接讀內(nèi)存,就像你從口袋里掏手機,比從快遞站取快遞快多了。
更要命的是 Redis 也會 “累”。比如秒殺活動,每秒幾萬請求打過來,就算 Redis 能扛住,網(wǎng)絡(luò)帶寬也可能被占滿,后面正常請求全卡住。這時候要是再遇到緩存雪崩(大量 key 同時過期),所有請求一起沖去數(shù)據(jù)庫,那場面,數(shù)據(jù)庫直接 “原地去世”。
3. 結(jié)論:多級緩存是 “組合拳”,不是 “單選題”
單級緩存的問題本質(zhì)是:本地緩存缺 “共享”,Redis 缺 “速度”。那解決辦法就很簡單了 —— 把兩者結(jié)合起來,再加上網(wǎng)關(guān)層的緩存(比如 Nginx),搞個 “多級緩存”,讓請求像走 “過濾網(wǎng)” 一樣,一層一層被擋住,最后漏到數(shù)據(jù)庫的請求就沒幾個了。
就像小區(qū)安保:先看大門(網(wǎng)關(guān)緩存),不是小區(qū)的直接攔;進了大門看單元門(本地緩存),住戶直接進;單元門沒卡,再查物業(yè)登記(Redis);最后實在不行才找業(yè)主確認(rèn)(數(shù)據(jù)庫)—— 這樣效率才高,還不容易出亂子。
二、多級緩存怎么搭?從 “三層架構(gòu)” 講透
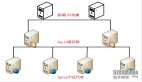
咱們聊最實用的 “三級緩存架構(gòu)”:網(wǎng)關(guān)緩存(Nginx)→ 本地緩存(Caffeine)→ 分布式緩存(Redis)。不是說必須三層都上,小項目可能本地 + Redis 就夠了,大項目再補個網(wǎng)關(guān)緩存,按需搭配。
先給個整體流程圖,后面逐個拆解:
用戶請求 → Nginx網(wǎng)關(guān)(查網(wǎng)關(guān)緩存)→ 有就返回
↓ 沒有
微服務(wù)實例(查本地緩存Caffeine)→ 有就返回
↓ 沒有
Redis分布式緩存 → 有就返回(同時回寫本地緩存)
↓ 沒有
數(shù)據(jù)庫 → 查詢結(jié)果(同時回寫Redis和本地緩存)→ 返回1. 第一層:網(wǎng)關(guān)緩存(Nginx)——“大門衛(wèi)”,攔高頻靜態(tài)請求
網(wǎng)關(guān)是請求進入微服務(wù)的第一站,用 Nginx 做緩存,主要攔那些 “不怎么變” 的靜態(tài)請求,比如商品分類列表、首頁 Banner 圖這些。
為啥用 Nginx?因為它比 Java 服務(wù)輕量,抗并發(fā)能力更強 ——Java 服務(wù)單機撐幾千 QPS 就不錯了,Nginx 輕松上萬。而且請求不用進 Java 服務(wù),直接在 Nginx 層面返回,效率高到飛起。
實戰(zhàn)配置:Nginx 緩存靜態(tài)接口
比如要緩存 “/api/v1/category/list” 這個分類接口,Nginx 配置大概長這樣:
http {
# 定義緩存區(qū):名字叫micro_cache,內(nèi)存100M,過期時間10分鐘
proxy_cache_path /var/nginx/cache levels=1:2 keys_zone=micro_cache:100m inactive=10m max_size=1g;
server {
listen 80;
server_name api.yourecommerce.com;
location /api/v1/category/list {
# 啟用緩存,用上面定義的micro_cache
proxy_cache micro_cache;
# 緩存key:用請求URI+參數(shù),避免不同請求混了
proxy_cache_key $uri$is_args$args;
# 200和304狀態(tài)碼緩存10分鐘
proxy_cache_valid 200 304 10m;
# 緩存命中率這些信息,加在響應(yīng)頭里,方便監(jiān)控
add_header X-Cache-Status $upstream_cache_status;
# 轉(zhuǎn)發(fā)到微服務(wù)集群
proxy_pass http://micro_service_cluster;
}
}
}注意點:別瞎緩存動態(tài)接口
Nginx 緩存適合 “純靜態(tài)、少變化” 的接口,比如分類、Banner。像用戶訂單、購物車這種 “每個人都不一樣” 的動態(tài)接口,千萬別用 Nginx 緩存 —— 不然張三能看到李四的訂單,那就等著背鍋吧。
如果非要緩存動態(tài)接口,得在 key 里加用戶標(biāo)識,比如proxy_cache_key $uri$is_args$args$cookie_user_id;,但這樣緩存命中率會很低,不如不用,所以一般不推薦。
2. 第二層:本地緩存(Caffeine)——“貼身管家”,快到離譜
本地緩存是微服務(wù)實例自己的 “內(nèi)存緩存”,用 Caffeine(Guava Cache 的升級版)最合適 —— 性能比 Guava 好,配置還靈活,現(xiàn)在 Java 項目基本都用它。
它的核心優(yōu)勢就一個字:快!不用走網(wǎng)絡(luò),直接讀 JVM 內(nèi)存,響應(yīng)時間能做到毫秒級甚至微秒級。適合存那些 “高頻訪問、短期不變” 的數(shù)據(jù),比如商品詳情、熱門商品列表。
第一步:Spring Boot 集成 Caffeine(直接抄代碼)
先加依賴(Maven):
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version> <!-- 用最新版就行 -->
</dependency>然后寫個配置類,定義緩存規(guī)則:
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.util.concurrent.TimeUnit;
@Configuration
@EnableCaching // 開啟緩存注解支持
public class CaffeineConfig {
// 定義緩存管理器:不同緩存用不同規(guī)則
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
// 1. 商品詳情緩存:最多存1000個,10分鐘過期
Caffeine<Object, Object> productCache = Caffeine.newBuilder()
.maximumSize(1000) // 最大緩存數(shù)量(滿了會刪最少用的)
.expireAfterWrite(10, TimeUnit.MINUTES) // 寫入后10分鐘過期
.recordStats(); // 記錄緩存命中率(方便監(jiān)控)
// 2. 熱門商品緩存:最多存500個,5分鐘過期(更新更頻繁)
Caffeine<Object, Object> hotProductCache = Caffeine.newBuilder()
.maximumSize(500)
.expireAfterWrite(5, TimeUnit.MINUTES)
.recordStats();
// 把不同緩存規(guī)則加進去,用名字區(qū)分
cacheManager.setCaffeineMap(Map.of(
"productDetailCache", productCache,
"hotProductCache", hotProductCache
));
return cacheManager;
}
}然后在 Service 層用注解就能用:
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
// 查商品詳情:用productDetailCache緩存
@Cacheable(value = "productDetailCache", key = "#productId")
public ProductVO getProductDetail(Long productId) {
// 這里查數(shù)據(jù)庫,沒緩存時才會執(zhí)行
ProductDO productDO = productMapper.selectById(productId);
// 轉(zhuǎn)成VO返回
return convertToVO(productDO);
}
// 查熱門商品:用hotProductCache緩存
@Cacheable(value = "hotProductCache", key = "'hotList'") // 固定key,因為是列表
public List<ProductVO> getHotProductList() {
return productMapper.selectHotProductList();
}
}第二步:Caffeine 核心配置解讀(別瞎配)
很多同學(xué)用 Caffeine 只知道設(shè)過期時間,其實幾個關(guān)鍵參數(shù)能決定緩存效果:
- maximumSize:最大緩存數(shù)量,必須設(shè)!不然緩存會無限膨脹,最后 JVM 內(nèi)存爆了,運維小哥會提著刀找你。
- expireAfterWrite:寫入后過期時間,適合數(shù)據(jù)會變的場景(比如商品價格)。
- expireAfterAccess:訪問后過期時間,適合 “不用就過期” 的場景(比如用戶會話)。
- recordStats:記錄命中率,一定要開!后面監(jiān)控用,命中率低于 80% 就得調(diào)緩存策略了。
第三步:Caffeine 底層為啥快?(稍微深入點)
Caffeine 用的是 “W-TinyLFU” 算法,比傳統(tǒng)的 LRU(最近最少使用)聰明多了。舉個例子:
LRU 就像你整理衣柜,只把最久沒穿的衣服扔掉。但有時候你剛買的新衣服(最近用了一次),因為之前沒穿過,會被 LRU 當(dāng)成 “久沒穿” 的扔掉 —— 這就很蠢。
W-TinyLFU 會 “記仇”:它會統(tǒng)計每個 key 的訪問次數(shù),哪怕是新 key,只要最近訪問過,就不會輕易扔掉。簡單說,它既照顧 “最近用的”,又照顧 “經(jīng)常用的”,緩存命中率比 LRU 高不少。
3. 第三層:分布式緩存(Redis)——“共享倉庫”,跨實例通用
Redis 是多級緩存的 “中堅力量”,主要解決本地緩存 “不共享” 的問題。比如你有 10 臺服務(wù)實例,本地緩存各存各的,Redis 就是那個 “共享倉庫”,讓所有實例都能拿到最新數(shù)據(jù)。
這部分重點不是教你怎么用 Redis(畢竟大家基本都會),而是講怎么避坑 —— 緩存穿透、擊穿、雪崩這三大難題,必須解決,不然 Redis 加了也白加。
第一步:Spring Boot 集成 Redis(基礎(chǔ)操作)
先加依賴:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 用Redisson,功能更多,比如分布式鎖 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.23.5</version>
</dependency>配置文件(application.yml):
spring:
redis:
host: 192.168.1.100
port: 6379
password: your_redis_password
lettuce:
pool:
max-active: 8 # 最大連接數(shù)
max-idle: 8 # 最大空閑連接
min-idle: 2 # 最小空閑連接
timeout: 2000ms # 超時時間
redisson:
singleServerConfig:
address: redis://192.168.1.100:6379
password: your_redis_password
connectionMinimumIdleSize: 2
connectionPoolSize: 8然后用 RedisTemplate 或者 @Cacheable(和 Caffeine 類似),這里推薦用 Redisson,因為它自帶分布式鎖、布隆過濾器這些工具,后面解決問題要用。
第二步:三大難題解決方案(實戰(zhàn)版)
這部分是重點,咱們一個個來,每個問題都給 “能直接用的代碼”。
1. 緩存穿透:故意查不存在的數(shù)據(jù),繞開緩存打數(shù)據(jù)庫
比如有人故意查productId=-1,這個 ID 在數(shù)據(jù)庫里根本沒有,所以緩存里也沒有,每次請求都會扎進數(shù)據(jù)庫 —— 如果每秒幾千個這種請求,數(shù)據(jù)庫直接扛不住。
解決方案:布隆過濾器 + 緩存空值
- 布隆過濾器:像小區(qū)門禁,先判斷這個 ID 在不在數(shù)據(jù)庫里,不在就直接返回,不用查緩存和數(shù)據(jù)庫。
- 緩存空值:就算布隆過濾器漏了,查數(shù)據(jù)庫沒找到,也往緩存里存?zhèn)€ “空值”(比如null),過期時間設(shè)短點(比如 1 分鐘),避免下次再查。
代碼實現(xiàn)(用 Redisson 布隆過濾器):
先初始化布隆過濾器(項目啟動時執(zhí)行):
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.List;
@Component
public class BloomFilterInit implements CommandLineRunner {
@Resource
private RedissonClient redissonClient;
@Resource
private ProductMapper productMapper;
// 布隆過濾器名字
private static final String PRODUCT_BLOOM_FILTER = "productBloomFilter";
// 預(yù)計數(shù)據(jù)量(比如100萬商品)
private static final long EXPECTED_INSERTIONS = 1000000;
// 誤判率(越小越費內(nèi)存,一般設(shè)0.01就行)
private static final double FALSE_POSITIVE_RATE = 0.01;
@Override
public void run(String... args) throws Exception {
// 獲取布隆過濾器
RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter(PRODUCT_BLOOM_FILTER);
// 初始化:如果沒初始化過才執(zhí)行
if (!bloomFilter.isExists()) {
bloomFilter.tryInit(EXPECTED_INSERTIONS, FALSE_POSITIVE_RATE);
// 把數(shù)據(jù)庫里所有商品ID加載到布隆過濾器
List<Long> allProductIds = productMapper.selectAllProductIds();
allProductIds.forEach(bloomFilter::add);
}
}
}然后在 Service 層用:
@Service
publicclass ProductService {
@Resource
private RedissonClient redissonClient;
@Resource
private ProductMapper productMapper;
@Resource
private StringRedisTemplate stringRedisTemplate;
// 查商品詳情(防穿透版)
public ProductVO getProductDetail(Long productId) {
String cacheKey = "product:detail:" + productId;
RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter("productBloomFilter");
// 1. 先過布隆過濾器:不在就直接返回
if (!bloomFilter.contains(productId)) {
returnnull; // 或者返回“商品不存在”
}
// 2. 查Redis緩存
String cacheValue = stringRedisTemplate.opsForValue().get(cacheKey);
if (cacheValue != null) {
// 緩存有值:如果是空值,返回null;否則轉(zhuǎn)VO
return"null".equals(cacheValue) ? null : JSON.parseObject(cacheValue, ProductVO.class);
}
// 3. 查數(shù)據(jù)庫
ProductDO productDO = productMapper.selectById(productId);
if (productDO == null) {
// 數(shù)據(jù)庫沒找到,緩存空值,1分鐘過期
stringRedisTemplate.opsForValue().set(cacheKey, "null", 1, TimeUnit.MINUTES);
returnnull;
}
// 4. 數(shù)據(jù)庫找到,緩存真實數(shù)據(jù),30分鐘過期
ProductVO productVO = convertToVO(productDO);
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(productVO), 30, TimeUnit.MINUTES);
return productVO;
}
}2. 緩存擊穿:熱點數(shù)據(jù)過期,所有請求打數(shù)據(jù)庫
比如某個熱門商品(比如秒殺商品)的緩存過期了,這時候每秒幾萬請求過來,都發(fā)現(xiàn)緩存沒了,一起沖去數(shù)據(jù)庫查 —— 數(shù)據(jù)庫直接被打崩。
解決方案:分布式互斥鎖 + 熱點數(shù)據(jù)永不過期
- 分布式互斥鎖:只有一個線程能去查數(shù)據(jù)庫,其他線程等著,查到后更新緩存,其他線程再從緩存拿數(shù)據(jù)。
- 熱點數(shù)據(jù)永不過期:對特別熱門的數(shù)據(jù),不設(shè)過期時間,而是用定時任務(wù)主動更新緩存(比如每 5 分鐘更一次)。
代碼實現(xiàn)(用 Redisson 分布式鎖):
public ProductVO getHotProductDetail(Long productId) {
String cacheKey = "product:hot:detail:" + productId;
String lockKey = "lock:product:hot:" + productId;
// 1. 先查本地緩存(Caffeine):熱點數(shù)據(jù)優(yōu)先讀本地
ProductVO localCache = caffeineCache.getIfPresent(cacheKey);
if (localCache != null) {
return localCache;
}
// 2. 查Redis緩存
String redisValue = stringRedisTemplate.opsForValue().get(cacheKey);
if (redisValue != null && !"null".equals(redisValue)) {
ProductVO productVO = JSON.parseObject(redisValue, ProductVO.class);
// 回寫本地緩存
caffeineCache.put(cacheKey, productVO);
return productVO;
}
// 3. 加分布式鎖:只有一個線程能查數(shù)據(jù)庫
RLock lock = redissonClient.getLock(lockKey);
try {
// 加鎖:30秒自動釋放(避免死鎖),最多等5秒
boolean locked = lock.tryLock(5, 30, TimeUnit.SECONDS);
if (locked) {
// 4. 加鎖成功,查數(shù)據(jù)庫
ProductDO productDO = productMapper.selectById(productId);
if (productDO == null) {
stringRedisTemplate.opsForValue().set(cacheKey, "null", 1, TimeUnit.MINUTES);
returnnull;
}
// 5. 數(shù)據(jù)庫有數(shù)據(jù),更新Redis和本地緩存
ProductVO productVO = convertToVO(productDO);
// Redis不設(shè)過期時間(永不過期),靠定時任務(wù)更新
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(productVO));
// 本地緩存設(shè)5分鐘過期
caffeineCache.put(cacheKey, productVO, 5, TimeUnit.MINUTES);
return productVO;
} else {
// 加鎖失敗,等100ms再重試(遞歸或循環(huán)都行)
Thread.sleep(100);
return getHotProductDetail(productId);
}
} catch (InterruptedException e) {
log.error("獲取鎖異常", e);
returnnull;
} finally {
// 釋放鎖:只有持有鎖的線程才能釋放
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
// 定時任務(wù)更新熱點商品緩存(每5分鐘執(zhí)行一次)
@Scheduled(fixedRate = 5 * 60 * 1000)
public void refreshHotProductCache() {
List<Long> hotProductIds = productMapper.selectHotProductIds(); // 查熱門商品ID列表
for (Long productId : hotProductIds) {
String cacheKey = "product:hot:detail:" + productId;
ProductDO productDO = productMapper.selectById(productId);
if (productDO != null) {
ProductVO productVO = convertToVO(productDO);
// 更新Redis緩存
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(productVO));
// 更新本地緩存
caffeineCache.put(cacheKey, productVO, 5, TimeUnit.MINUTES);
}
}
}3. 緩存雪崩:大量 key 同時過期,請求全打數(shù)據(jù)庫
比如你給所有商品緩存都設(shè)了 “凌晨 3 點過期”,到點后所有商品緩存一起失效,請求全沖去數(shù)據(jù)庫 —— 這就是雪崩,比擊穿更嚴(yán)重。
解決方案:過期時間隨機 + Redis 集群 + 服務(wù)熔斷降級
- 過期時間隨機:給每個 key 的過期時間加個隨機值(比如 30 分鐘 ±5 分鐘),避免同時過期。
- Redis 集群:別用單機 Redis,搞個主從 + 哨兵或者 Redis Cluster,就算一臺崩了,其他的還能扛。
- 服務(wù)熔斷降級:用 Sentinel 或者 Resilience4j,當(dāng)數(shù)據(jù)庫壓力太大時,直接返回緩存的舊數(shù)據(jù)或者提示 “服務(wù)繁忙”,別硬扛。
代碼實現(xiàn)(過期時間隨機):
// 給緩存加隨機過期時間:30分鐘±5分鐘(25-35分鐘)
int baseExpire = 30; // 基礎(chǔ)過期時間(分鐘)
int randomExpire = new Random().nextInt(10); // 0-10分鐘隨機值
int totalExpire = baseExpire - 5 + randomExpire; // 25-35分鐘
// 存Redis時用這個總過期時間
stringRedisTemplate.opsForValue().set(cacheKey, JSON.toJSONString(productVO), totalExpire, TimeUnit.MINUTES);服務(wù)熔斷降級(用 Resilience4j):
加依賴:
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot2</artifactId>
<version>2.1.0</version>
</dependency>配置文件:
resilience4j:
circuitbreaker:
instances:
productDbCircuit: # 熔斷器名字
slidingWindowSize: 100 # 滑動窗口大小
failureRateThreshold: 50 # 失敗率閾值:50%失敗就熔斷
waitDurationInOpenState: 60000 # 熔斷后60秒嘗試恢復(fù)
permittedNumberOfCallsInHalfOpenState: 10 # 半開狀態(tài)允許10個請求測試
fallback:
instances:
productDbCircuit:
fallback-exception: # 哪些異常觸發(fā)降級
- java.sql.SQLException
- org.springframework.dao.DataAccessExceptionService 層用注解:
// 查數(shù)據(jù)庫時加熔斷降級:失敗了就返回緩存的舊數(shù)據(jù)(如果有的話)
@CircuitBreaker(name = "productDbCircuit", fallbackMethod = "getProductDetailFallback")
private ProductDO getProductFromDb(Long productId) {
return productMapper.selectById(productId);
}
// 降級方法:參數(shù)和返回值要和原方法一致
private ProductDO getProductDetailFallback(Long productId, Exception e) {
log.error("查數(shù)據(jù)庫失敗,觸發(fā)降級", e);
// 嘗試從Redis拿舊數(shù)據(jù)(就算過期了也拿)
String cacheKey = "product:detail:" + productId;
String redisValue = stringRedisTemplate.opsForValue().get(cacheKey);
if (redisValue != null && !"null".equals(redisValue)) {
ProductVO productVO = JSON.parseObject(redisValue, ProductVO.class);
return convertToDO(productVO); // 轉(zhuǎn)成DO返回
}
// 沒舊數(shù)據(jù)就拋異常(或者返回默認(rèn)值)
thrownew RuntimeException("服務(wù)繁忙,請稍后再試");
}三、多級緩存協(xié)同:怎么讓三級緩存 “配合默契”
光搭好每一級還不夠,得讓它們 “協(xié)同工作”—— 什么時候讀哪一級,什么時候更哪一級,不然會出現(xiàn) “數(shù)據(jù)不一致” 的問題(比如數(shù)據(jù)庫改了,緩存還是舊的)。
1. 查詢流程:從外到內(nèi),層層過濾
前面給過流程圖,這里再細化下,加個實際例子(查商品詳情):
- 用戶請求/api/v1/product/123,先到 Nginx 網(wǎng)關(guān) ——Nginx 查自己的緩存,發(fā)現(xiàn)沒有(因為商品詳情是動態(tài)的,一般不存 Nginx),轉(zhuǎn)發(fā)到微服務(wù)。
- 微服務(wù)實例收到請求,先查本地緩存 Caffeine(key=productDetailCache:123)—— 如果有,直接返回,全程 20ms 以內(nèi)。
- 本地緩存沒有,查 Redis(key=product:detail:123)—— 如果有,返回給用戶,同時把數(shù)據(jù)回寫到本地緩存(下次再查就快了)。
- Redis 也沒有,查數(shù)據(jù)庫 —— 查到后,先更 Redis,再更本地緩存,最后返回給用戶。
整個流程下來,大部分請求會被本地緩存和 Redis 擋住,數(shù)據(jù)庫壓力很小。
2. 更新策略:兩種方案,按需選擇
當(dāng)數(shù)據(jù)更新時(比如商品價格改了),怎么同步緩存?主要兩種方案:
方案 1:失效模式(推薦)—— 更新數(shù)據(jù)庫后,刪除緩存
流程:更新數(shù)據(jù)庫 → 刪除 Redis 緩存 → 發(fā)送消息通知所有微服務(wù)實例刪除本地緩存。
優(yōu)點:安全,避免更新緩存失敗導(dǎo)致不一致。
缺點:刪除緩存后,第一次請求會查數(shù)據(jù)庫(但有互斥鎖擋著,問題不大)。
代碼實現(xiàn)(用 RabbitMQ 通知本地緩存):
更新商品價格的 Service:
@Service
publicclass ProductUpdateService {
@Resource
private ProductMapper productMapper;
@Resource
private StringRedisTemplate stringRedisTemplate;
@Resource
private RabbitTemplate rabbitTemplate;
@Transactional// 加事務(wù),確保數(shù)據(jù)庫更新成功才刪緩存
public void updateProductPrice(Long productId, BigDecimal newPrice) {
// 1. 更新數(shù)據(jù)庫
ProductDO productDO = new ProductDO();
productDO.setId(productId);
productDO.setPrice(newPrice);
productMapper.updateById(productDO);
// 2. 刪除Redis緩存
String redisKey = "product:detail:" + productId;
stringRedisTemplate.delete(redisKey);
// 3. 發(fā)送消息,通知所有實例刪除本地緩存
rabbitTemplate.convertAndSend("cache-invalidate-exchange", "product.detail", productId);
}
}微服務(wù)實例接收消息,刪除本地緩存:
@Component
publicclass CacheInvalidateConsumer {
@Resource
private CacheManager cacheManager;
@RabbitListener(queues = "product-detail-cache-queue")
public void handleCacheInvalidate(Long productId) {
// 獲取本地緩存,刪除對應(yīng)的key
Cache productCache = cacheManager.getCache("productDetailCache");
if (productCache != null) {
productCache.evict(productId);
}
log.info("刪除本地緩存:productDetailCache:{}", productId);
}
}方案 2:更新模式 —— 更新數(shù)據(jù)庫后,直接更新緩存
流程:更新數(shù)據(jù)庫 → 更新 Redis 緩存 → 通知更新本地緩存。
優(yōu)點:更新后緩存是最新的,第一次請求不用查數(shù)據(jù)庫。
缺點:有并發(fā)問題,比如兩個線程同時更新,可能導(dǎo)致緩存存舊數(shù)據(jù)。
比如:線程 A 更新數(shù)據(jù)庫(價格 100)→ 線程 B 更新數(shù)據(jù)庫(價格 200)→ 線程 B 更新緩存(200)→ 線程 A 更新緩存(100)—— 最后緩存是 100,數(shù)據(jù)庫是 200,不一致了。
所以一般推薦用 “失效模式”,雖然第一次請求會查數(shù)據(jù)庫,但更安全。
3. 數(shù)據(jù)一致性:終極解決方案(Canal)
如果你的項目對數(shù)據(jù)一致性要求特別高(比如金融場景),光靠刪除緩存還不夠 —— 比如更新數(shù)據(jù)庫成功了,但刪除 Redis 緩存失敗了,這時候緩存還是舊的。
這時候可以用Canal—— 它能監(jiān)聽 MySQL 的 binlog 日志,當(dāng)數(shù)據(jù)庫數(shù)據(jù)變化時,自動同步更新緩存。
簡單流程:
- Canal 偽裝成 MySQL 的從庫,監(jiān)聽 binlog 日志。
- 當(dāng) product 表的數(shù)據(jù)更新時,Canal 捕獲到這個變化。
- Canal 發(fā)送消息給微服務(wù),微服務(wù)收到后,更新 Redis 和本地緩存。
這樣就算手動刪除緩存失敗,Canal 也能兜底,確保緩存和數(shù)據(jù)庫一致。
四、實戰(zhàn)案例:從 “卡成狗” 到 “飛起來” 的優(yōu)化過程
最后給個真實案例,讓大家看看多級緩存的效果 —— 去年幫一個電商客戶做的商品詳情接口優(yōu)化,數(shù)據(jù)說話最有說服力。
優(yōu)化前:只有 Redis 緩存
- 接口響應(yīng)時間:80-120ms
- QPS 峰值:5000(再高就超時)
- 數(shù)據(jù)庫 CPU:高峰期 60%-70%
- 問題:秒殺活動時,Redis 扛不住,接口超時率 20%+
優(yōu)化后:Nginx+Caffeine+Redis 三級緩存
- 接口響應(yīng)時間:15-30ms(降了 70%+)
- QPS 峰值:10 萬(翻了 20 倍)
- 數(shù)據(jù)庫 CPU:高峰期 5%-10%(降了 90%)
- 效果:秒殺活動時,接口零超時,數(shù)據(jù)庫壓力幾乎可以忽略。
關(guān)鍵優(yōu)化點:
- 首頁 Banner 圖、分類列表這些靜態(tài)數(shù)據(jù),用 Nginx 緩存,QPS 直接扛住 5 萬。
- 熱門商品詳情用 Caffeine 本地緩存,90% 的請求直接在本地返回,不用查 Redis。
- Redis 只存非熱門商品和兜底數(shù)據(jù),壓力大減,再配合集群,穩(wěn)如老狗。
- 用 Canal 同步緩存,數(shù)據(jù)一致性沒問題,客服再也沒收到 “價格不一致” 的投訴。
五、踩坑指南:這些坑我替你踩過了
- 本地緩存沒設(shè)最大數(shù)量:之前有個同學(xué)用 Caffeine 沒設(shè) maximumSize,上線后 JVM 內(nèi)存一天天漲,最后 OOM 崩潰 —— 記住,本地緩存一定要設(shè)最大數(shù)量!
- Redis 緩存 key 沒加前綴:不同業(yè)務(wù)的 key 混在一起,比如product:123和order:123,后面清理緩存時容易刪錯 ——key 一定要加業(yè)務(wù)前綴,比如product:detail:123。
- 分布式鎖沒設(shè)過期時間:加鎖后如果服務(wù)崩了,鎖沒釋放,其他線程永遠拿不到鎖 —— 鎖一定要設(shè)自動過期時間,比如 30 秒。
- 緩存命中率沒監(jiān)控:不知道緩存效果怎么樣,瞎調(diào)參數(shù) —— 一定要監(jiān)控 Caffeine 和 Redis 的命中率,Caffeine 命中率低于 80% 就調(diào) maximumSize,Redis 低于 70% 就調(diào)過期時間。
- 熱點數(shù)據(jù)沒單獨處理:把熱門商品和普通商品放一個緩存,熱門商品過期時導(dǎo)致雪崩 —— 熱門商品要單獨設(shè)緩存規(guī)則,用永不過期 + 定時更新。
六、總結(jié):多級緩存不是 “銀彈”,但真能救命
最后跟大家說句實在的:多級緩存不是萬能的,但在微服務(wù)性能優(yōu)化里,它是性價比最高的方案 —— 不用改太多代碼,就能讓性能翻好幾倍。
記住幾個核心原則:
- 分層過濾:網(wǎng)關(guān)攔靜態(tài),本地攔高頻,Redis 攔中頻,數(shù)據(jù)庫扛低頻。
- 按需選擇:小項目本地 + Redis 就夠了,大項目再補網(wǎng)關(guān)和 Canal。
- 先穩(wěn)后快:先解決緩存穿透、擊穿、雪崩這些問題,再追求性能極致。
- 監(jiān)控為王:緩存命中率、Redis 內(nèi)存、數(shù)據(jù)庫壓力,這些指標(biāo)一定要監(jiān)控,不然出問題都不知道在哪。
下次再遇到微服務(wù)性能不行,別光顧著加機器,先試試多級緩存,說不定幾行代碼就能解決問題,還能省不少服務(wù)器錢。