如何實時檢測同一設備/賬號的異常下單行為?
在電商、金融、出行等互聯網業務中,黑產團伙利用自動化腳本或“羊毛黨”利用規則漏洞進行刷單、套利、囤貨等行為,是每個公司都必須直面的一場攻防戰。這些行為往往具備一個共同特征:在短時間內,從同一個源(設備、賬號、IP等)產生大量看似正常但實則異常的請求。 我們的目標就是要在訂單產生的瞬間,精準地識別并攔截這些異常行為。
一、問題拆解:什么是“異常”?
在動手之前,我們必須先定義清楚“敵人”是誰。異常下單行為通常表現為以下幾種模式:
1. 高頻次: 同一賬號/設備在極短時間內(如1分鐘)下單次數遠超正常人類操作極限(例如10次以上)。
2. 單一目標: 所有訂單都集中在某個特定商品(如限量秒殺品、高價值券)。
3. 規律性操作: 下單時間間隔呈現出機器般的規律,如精確的每秒一次。
4. 信息雷同/無效: 使用自動生成的收貨地址、虛擬手機號等。
5. 新人賬號集中爆發: 大量新注冊的賬號在短時間內進行首單購買。
我們的實時檢測系統,核心就是要捕捉到這些模式。
二、核心技術架構:流處理與規則引擎
要實現“實時”,傳統的批量處理(T+1)完全無能為力。我們必須采用流式處理 架構。其核心思想是:將源源不斷產生的訂單事件看作一條數據流,我們的系統像一道堤壩,在每一滴水流過的瞬間就進行檢查和判斷。
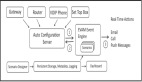
一個典型的實時檢測系統架構如下:
[數據源:App/Web下單請求]
-> [實時消息隊列:Kafka]
-> [流處理引擎:Flink/Spark Streaming]
-> [特征計算與規則判斷]
-> [風險決策與執行:攔截/放行/審核]為什么是Kafka?Kafka就像一個高速傳輸帶,它能以極高的吞吐量承接前端海量的下單請求,并保證數據不丟失,為后續的流處理引擎提供穩定可靠的數據源。
為什么是Flink?Flink是目前業界公認的、在狀態管理和時間處理上最強大的流處理引擎之一。它完美契合了我們這種需要“實時聚合統計”的場景。
三、關鍵技術細節與實戰
下面,我們聚焦于最核心的“特征計算與規則判斷”部分,看看如何用代碼實現幾個經典的檢測策略。
策略1:基于時間窗口的頻次控制
這是最直接、最有效的規則。例如:“同一設備ID,在1分鐘內下單超過5次,則觸發警報。”
技術要點:
? 鍵控流: 我們需要以“設備ID”或“賬號ID”作為Key,將數據流分割成多個獨立的子流。這樣,對設備A的統計就不會和設備B的混淆。
? 滾動窗口: 定義一個固定長度的、不重復的時間窗口(如1分鐘),每個窗口獨立進行計算。
? 狀態管理: Flink強大的狀態后端(State Backend)會幫我們為每個Key在窗口內維護一個計數器。
簡化版代碼示例(使用 Apache Flink Java API):
// 定義輸入數據流:訂單事件
DataStream<OrderEvent> orderStream = ...; // 從Kafka接入的數據
// 轉換并鍵控流
KeyedStream<OrderEvent, String> keyedByDeviceStream = orderStream
.keyBy(OrderEvent::getDeviceId); // 以設備ID進行分組
// 應用1分鐘的滾動窗口,并計算每個窗口內的訂單數
DataStream<Alert> windowedAlerts = keyedByDeviceStream
.window(TumblingProcessingTimeWindows.of(Time.minutes(1))) // 1分鐘滾動窗口
.process(newProcessWindowFunction<OrderEvent, Alert, String, TimeWindow>() {
@Override
publicvoidprocess(String deviceId,
Context context,
Iterable<OrderEvent> elements,
Collector<Alert> out) {
// 計算當前窗口內該設備的訂單數量
longcount=0;
for (OrderEvent element : elements) {
count++;
}
// 定義閾值,例如5次
intthreshold=5;
if (count > threshold) {
// 觸發警報
out.collect(newAlert(
"高頻下單警報:設備 " + deviceId +
" 在1分鐘內下單 " + count + " 次,超過閾值 " + threshold,
System.currentTimeMillis()
));
}
}
});
// 將警報輸出到日志、風控控制臺或另一個Kafka Topic,以便執行攔截
windowedAlerts.print();策略2:基于滑動窗口的智能檢測
滾動窗口有一個缺點:它只在窗口結束時輸出結果。如果一個惡意用戶恰好在窗口邊界處進行操作,可能會被漏掉。滑動窗口可以解決這個問題。
例如,規則:“同一賬號,在10分鐘內下單超過10次,且每1分鐘評估一次。”
技術要點:
? 滑動窗口: 窗口長度(10分鐘)和滑動步長(1分鐘)。這意味著,每過1分鐘,系統就會計算過去10分鐘內的數據。
在Flink中,只需將上面的 .window(...) 部分替換為:
.window(SlidingProcessingTimeWindows.of(Time.minutes(10), Time.minutes(1)))策略3:復雜模式匹配(CEP)
對于更復雜的場景,比如“在3分鐘內,先下單A商品,緊接著下單B商品,然后又下單A商品”,這種序列模式就需要更強大的工具——Flink CEP。
技術要點:
? 定義模式: 使用類似于正則表達式的語法來描述復雜的事件序列。
示例:檢測“下單-取消-再次下單同一商品”的異常模式
// 1. 定義模式
Pattern<OrderEvent, ?> suspiciousPattern = Pattern.<OrderEvent>begin("first_order")
.where(newSimpleCondition<OrderEvent>() {
@Override
publicbooleanfilter(OrderEvent value) {
return"CREATE".equals(value.getType());
}
})
.next("cancel")
.where(newSimpleCondition<OrderEvent>() {
@Override
publicbooleanfilter(OrderEvent value) {
return"CANCEL".equals(value.getType());
}
})
.next("second_order")
.where(newSimpleCondition<OrderEvent>() {
@Override
publicbooleanfilter(OrderEvent value) {
return"CREATE".equals(value.getType());
}
})
.within(Time.minutes(5)); // 在5分鐘內完成整個序列
// 2. 將模式應用到數據流上
PatternStream<OrderEvent> patternStream = CEP.pattern(
keyedByDeviceStream, // 同樣需要先按Key分組
suspiciousPattern
);
// 3. 處理匹配到的事件
DataStream<Alert> cepAlerts = patternStream.process(
newPatternProcessFunction<OrderEvent, Alert>() {
@Override
publicvoidprocessMatch(
Map<String, List<OrderEvent>> match,
Context ctx,
Collector<Alert> out)throws Exception {
OrderEventfirst= match.get("first_order").get(0);
OrderEventcancel= match.get("cancel").get(0);
OrderEventsecond= match.get("second_order").get(0);
// 檢查是否是同一商品
if (first.getProductId().equals(second.getProductId())) {
out.collect(newAlert(
"可疑下單-取消-再下單模式:設備 " + first.getDeviceId() +
" 對商品 " + first.getProductId() + " 進行了可疑操作序列。",
System.currentTimeMillis()
));
}
}
});四、超越簡單規則:簡易模型與特征工程
單純依靠閾值規則很容易產生誤殺(正常用戶搶熱門商品)和漏過(黑產降低頻率)。更高級的系統會引入輕量級的統計模型。
核心思想: 我們不只問“他下單了多少次?”,而是問“他現在的行為和他自己/群體的歷史正常行為相比,有多反常?”
1. 特征向量化: 為每一個下單請求,實時計算一組特征。
? f1: 當前設備在本小時內的下單次數。
? f2: 當前賬號在過去30分鐘內的下單總金額。
? f3: 本次下單與上一次下單的時間間隔(秒)。
? f4: 該設備關聯的賬號數量(需查詢外部數據庫或維表)。
? f5: 本次收貨地址與常用地址的匹配度。
2. 實時評分:
? 可以預先用一個離線模型(如孤立森林、邏輯回歸)訓練好一組權重 [w1, w2, w3, w4, w5]。
? 在流處理中,對每個訂單,實時計算一個風險分數:Score = f1*w1 + f2*w2 + f3*w3 + f4*w4 + f5*w5。
? 如果 Score 超過某個閾值,則觸發風控。
這個過程依然可以在Flink中高效完成,因為它本質上是為每個事件進行了一次點積運算,計算開銷很小。
五、系統設計的其他重要考量
1. 設備指紋技術: 如何準確標識一個“設備”是關鍵。不能單純依賴容易篡改的設備ID。需要結合多種信息(如IP、User-Agent、屏幕分辨率、安裝字體等)生成一個高穩定性的設備指紋。這是整個風控體系的基石。
2. 外部維表關聯: 有些特征(如“該設備歷史關聯賬號數”)需要查詢外部數據庫(如Redis、HBase)。Flink提供了 Async I/O 功能,可以在不阻塞流處理的前提下進行高效查詢,避免成為性能瓶頸。
3. 動態規則與灰度發布: 風控規則不能是一成不變的。需要一個配置中心,支持不重啟服務的情況下,動態添加、修改、禁用規則,并對新規則進行小流量灰度測試,觀察效果。
4. 誤殺與用戶體驗: 任何風控系統都會有誤判。對于高風險但不確定的訂單,更優的策略是將其標記為“待審核”,轉入人工審核流程,而不是直接拒絕,從而在安全與體驗之間取得平衡。
六、總結
構建一個實時異常下單檢測系統,是一項融合了業務洞察、數據流技術和算法模型的綜合性工程。其核心路徑非常清晰:
? 架構上,采用 Kafka + Flink 的流式管道,保障實時性。
? 策略上,從簡單的 時間窗口計數 入手,逐步過渡到 復雜事件序列 和 基于特征的輕量模型。
? 工程上,重視 設備指紋 的準確性,利用 Async I/O 解決維表關聯問題,并通過 動態配置 保持系統的靈活性和可進化性。
這場與黑產的對抗是一場永無止境的“貓鼠游戲”。沒有一勞永逸的銀彈,唯一不變的就是變化本身。因此,一個可觀測、可迭代、能快速響應攻擊模式變化的實時風控系統,已然成為現代互聯網業務的核心基礎設施。