深入剖析:商品搜索接口TP99從50ms突增至2s,我是如何快速定位并殲滅問(wèn)題的?
在互聯(lián)網(wǎng)電商領(lǐng)域,商品搜索接口是流量的生命線,其性能穩(wěn)定性直接關(guān)系到用戶體驗(yàn)和公司營(yíng)收。一個(gè)健康的搜索接口,其TP99指標(biāo)通常在幾十毫秒級(jí)別。然而,在一個(gè)平靜的下午,監(jiān)控系統(tǒng)突然告警:商品搜索接口的TP99從平時(shí)的50ms飆升至2s!這無(wú)異于一場(chǎng)線上風(fēng)暴。
作為負(fù)責(zé)該系統(tǒng)的工程師,我們必須像偵探一樣,快速、精準(zhǔn)地找到問(wèn)題的根源并解決它。本文將詳細(xì)還原此次故障的排查全過(guò)程,深入技術(shù)細(xì)節(jié),并總結(jié)出一套可復(fù)用的性能問(wèn)題定位方法論。
一、問(wèn)題確認(rèn)與影響范圍評(píng)估
收到告警后,切忌盲目行動(dòng)。第一步是確認(rèn)問(wèn)題并評(píng)估影響范圍。
1. 確認(rèn)告警真實(shí)性:登錄APM(應(yīng)用性能管理)系統(tǒng),如SkyWalking、Pinpoint或Cat,查看該接口的響應(yīng)時(shí)間趨勢(shì)圖。確認(rèn)TP99、TP95、AVG等指標(biāo)是否全部上漲,還是僅TP99異常?從50ms到2s,40倍的飆升,基本可以排除是偶發(fā)的毛刺,而是系統(tǒng)性故障。
2. 評(píng)估影響面:
? 業(yè)務(wù)影響:搜索接口的QPS(每秒查詢量)是否下降?訂單轉(zhuǎn)化率是否有異常波動(dòng)?通過(guò)業(yè)務(wù)監(jiān)控大盤快速確認(rèn)。
? 范圍影響:是所有搜索請(qǐng)求都變慢,還是特定查詢條件(如某些關(guān)鍵詞、篩選條件)的請(qǐng)求變慢?是全部流量都受影響,還是僅某個(gè)機(jī)房、某個(gè)集群?通過(guò)查看網(wǎng)關(guān)/LB的流量和響應(yīng)時(shí)間分布圖來(lái)判斷。
初步發(fā)現(xiàn):在本次案例中,監(jiān)控顯示TP95也從30ms升至約500ms,平均響應(yīng)時(shí)間也有顯著上升。QPS略有下降,但未完全不可用。影響范圍是全網(wǎng)全量流量,但慢請(qǐng)求在時(shí)間分布上并不均勻。
二、系統(tǒng)性排查:遵循從外到內(nèi)、由表及里的原則
面對(duì)這種全局性的性能劣化,需要一個(gè)清晰的排查路徑。我遵循了經(jīng)典的“從外部依賴到內(nèi)部應(yīng)用,從基礎(chǔ)設(shè)施到應(yīng)用代碼”的排查思路。
2.1 基礎(chǔ)設(shè)施層檢查
首先,排除最底層的基礎(chǔ)設(shè)施問(wèn)題。
1. 主機(jī)資源:查看Kubernetes集群或物理機(jī)的監(jiān)控。
? CPU:CPU使用率是否飆升?特別是%us(用戶態(tài))和%sy(系統(tǒng)態(tài))的比例。如果%sy過(guò)高,可能意味著系統(tǒng)調(diào)用頻繁,存在IO等待或鎖競(jìng)爭(zhēng)。
? 內(nèi)存:內(nèi)存使用率是否正常?有無(wú)發(fā)生大量Swap,導(dǎo)致內(nèi)存頁(yè)交換拖慢速度?
? 磁盤IO:雖然搜索服務(wù)可能不直接頻繁寫磁盤,但日志寫入、臨時(shí)文件等也可能成為瓶頸。檢查磁盤的util(使用率)、await(IO等待時(shí)間)。
? 網(wǎng)絡(luò):網(wǎng)絡(luò)帶寬是否打滿?網(wǎng)絡(luò)包的錯(cuò)誤率、重傳率是否異常?
檢查結(jié)果:本次排查中,集群節(jié)點(diǎn)的CPU、內(nèi)存、磁盤IO均處于正常水位,網(wǎng)絡(luò)帶寬也未打滿。初步排除基礎(chǔ)設(shè)施瓶頸。
2.2 中間件與外部依賴排查
搜索接口強(qiáng)依賴于搜索引擎(如Elasticsearch)和緩存(如Redis)。這里是最大的懷疑對(duì)象。
1. Elasticsearch集群健康度:
? 立即查看ES的集群狀態(tài)(GET /_cluster/health)。關(guān)注 status 是否為green,number_of_pending_tasks 是否有堆積,unassigned_shards 是否有未分配的分片。
? 查看ES的節(jié)點(diǎn)監(jiān)控:CPU、負(fù)載、堆內(nèi)存使用率(Heap Used)。重點(diǎn)中的重點(diǎn):JVM堆內(nèi)存使用率是否長(zhǎng)時(shí)間高于90%?GC情況如何? 頻繁的Full GC會(huì)導(dǎo)致世界暫停(Stop-The-World),使得所有請(qǐng)求卡住,表現(xiàn)就是應(yīng)用端請(qǐng)求超時(shí)或響應(yīng)極慢。查看ES的GC日志,如果發(fā)現(xiàn)ConcurrentMarkSweep 或 G1 的Full GC耗時(shí)長(zhǎng)達(dá)數(shù)秒甚至數(shù)十秒,那么問(wèn)題很可能在此。
? 查看ES的索引性能:indexing 和 search 的線程池(thread_pool)隊(duì)列是否已滿?是否有拒絕(rejected)的情況?隊(duì)列積壓會(huì)導(dǎo)致新到的搜索請(qǐng)求等待。
? 分析ES的慢查詢?nèi)罩荆哼@是最關(guān)鍵的一步。ES可以記錄超過(guò)指定閾值的查詢耗時(shí)。立即登錄Kibana或直接查看日志,分析在問(wèn)題發(fā)生時(shí)間點(diǎn)附近,有哪些慢查詢。關(guān)注點(diǎn):查詢語(yǔ)句是否復(fù)雜?是否使用了script_query(腳本查詢,性能殺手)?filter上下文是否被濫用?分頁(yè)深度是否過(guò)大(from + size)?
2. Redis緩存:
? 檢查Redis的監(jiān)控:連接數(shù)、內(nèi)存使用、QPS、響應(yīng)時(shí)間。
? 使用redis-cli --latency命令檢測(cè)Redis服務(wù)端到客戶端的網(wǎng)絡(luò)延遲。
? 檢查是否有大Key(單個(gè)String值過(guò)大或Hash/List等元素過(guò)多)或熱Key(某個(gè)Key被高頻訪問(wèn))?執(zhí)行slowlog get命令查看Redis慢查詢。
檢查結(jié)果:在本次案例中,一查看ES監(jiān)控,立刻發(fā)現(xiàn)了異常:
? ES集群狀態(tài)為yellow,有一個(gè)節(jié)點(diǎn)的分片未分配。
? 該節(jié)點(diǎn)的JVM堆內(nèi)存使用率持續(xù)在95%以上,GC監(jiān)控顯示過(guò)去幾分鐘內(nèi)發(fā)生了多次長(zhǎng)達(dá)1.5秒的Full GC。
? ES的search線程池有少量拒絕記錄。
至此,問(wèn)題的根源似乎已經(jīng)指向了Elasticsearch的GC問(wèn)題。 但作為嚴(yán)謹(jǐn)?shù)墓こ處煟覀冃枰^續(xù)深入,回答兩個(gè)問(wèn)題:1. 為什么ES會(huì)頻繁Full GC? 2. 為什么應(yīng)用端的表現(xiàn)是TP99高達(dá)2s,而不是全部超時(shí)?
2.3 應(yīng)用層代碼與配置分析
現(xiàn)在,我們將焦點(diǎn)從中間件拉回到應(yīng)用服務(wù)本身。
1. 應(yīng)用服務(wù)監(jiān)控:
? 查看應(yīng)用服務(wù)的JVM情況(如果應(yīng)用是Java)。同樣關(guān)注GC和堆內(nèi)存。雖然ES的問(wèn)題更明顯,但應(yīng)用本身也可能存在內(nèi)存泄漏,導(dǎo)致對(duì)ES的請(qǐng)求被阻塞在客戶端隊(duì)列。
? 查看應(yīng)用服務(wù)的線程池。特別是用于調(diào)用ES的HTTP客戶端或數(shù)據(jù)庫(kù)連接池。如果這些池耗盡,請(qǐng)求會(huì)排隊(duì)等待,增加響應(yīng)時(shí)間。
2. 鏈路追蹤分析:
? 這是定位分布式系統(tǒng)性能問(wèn)題的“核武器”。在APM系統(tǒng)中,過(guò)濾出響應(yīng)時(shí)間在2s左右的慢請(qǐng)求Trace。
? 打開(kāi)一個(gè)具體的Trace詳情,你會(huì)看到一個(gè)清晰的調(diào)用鏈樹(shù)狀圖。重點(diǎn)關(guān)注時(shí)間消耗在了哪個(gè)環(huán)節(jié)。
? 如果90%的時(shí)間都花在了一次ES Search調(diào)用上,那么問(wèn)題基本鎖定在ES。
? 如果時(shí)間分散在多次ES調(diào)用、或者還有Redis調(diào)用、外部RPC調(diào)用等,則需要具體分析。
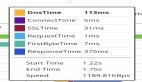
? 在本次案例的Trace中,我們清晰地看到,一個(gè)搜索請(qǐng)求,在應(yīng)用端只耗費(fèi)了不到50ms,但在一次名為/goods_index/_search的ES調(diào)用上,耗時(shí)了1950ms。 這完美地解釋了2s的TP99。
3. 日志分析:
? 搜索應(yīng)用服務(wù)的錯(cuò)誤日志和WARN日志。查看在問(wèn)題時(shí)間點(diǎn),是否有大量的ES連接超時(shí)、讀超時(shí)等異常(如Elasticsearch的TimeoutException)。
? 結(jié)合鏈路追蹤中的Trace ID,可以精準(zhǔn)定位到某一次慢請(qǐng)求的完整上下文日志。
三、根因定位:連接點(diǎn)與深度剖析
現(xiàn)在,我們將所有線索串聯(lián)起來(lái),形成一個(gè)完整的證據(jù)鏈:
表象:應(yīng)用端TP99 = 2s。
直接原因:APM鏈路追蹤顯示,時(shí)間主要耗費(fèi)在Elasticsearch查詢上。
中間層原因:ES監(jiān)控顯示,ES節(jié)點(diǎn)因堆內(nèi)存不足,發(fā)生頻繁且耗時(shí)的Full GC。
根本原因:為什么堆內(nèi)存會(huì)不足?
我們需要深入分析在問(wèn)題發(fā)生前,ES集群發(fā)生了什么變化。常見(jiàn)的根本原因包括:
? 大查詢/聚合查詢:某個(gè)或某些復(fù)雜的查詢,需要加載大量的FieldData或Global Ordinals到堆內(nèi)存中,瞬間吃滿內(nèi)存,觸發(fā)GC。FieldData用于分詞字段的聚合和排序,是JVM堆內(nèi)存的主要消耗者之一。
? 數(shù)據(jù)激增:是否有定時(shí)任務(wù)導(dǎo)入了大量數(shù)據(jù)?導(dǎo)致索引的segment增多,內(nèi)存壓力增大。
? 錯(cuò)誤的ES查詢語(yǔ)句:檢查應(yīng)用代碼中構(gòu)建的DSL查詢。我們通過(guò)ES慢查詢?nèi)罩荆l(fā)現(xiàn)了一個(gè)關(guān)鍵的線索:在問(wèn)題發(fā)生的時(shí)間點(diǎn),開(kāi)始出現(xiàn)大量使用script_query的查詢,且腳本內(nèi)容非常低效。
// 一個(gè)示例的低效腳本查詢
{
"query": {
"bool": {
"filter": {
"script": {
"script": {
"source": "doc['price'].value > params.minPrice && doc['sales'].value > params.minSales",
"params": {
"minPrice": 100,
"minSales": 50
}
}
}
}
}
}
}這種腳本查詢,會(huì)對(duì)索引中滿足filter條件的每一個(gè)文檔執(zhí)行一次腳本解釋執(zhí)行,計(jì)算開(kāi)銷極大,嚴(yán)重消耗CPU和內(nèi)存,是導(dǎo)致ES集群不堪重負(fù)的“元兇”。
那么,為什么突然出現(xiàn)這種查詢? 進(jìn)一步排查發(fā)現(xiàn),前端團(tuán)隊(duì)在一個(gè)小時(shí)前上線了一個(gè)新的“高級(jí)篩選”功能,該功能允許用戶組合多個(gè)復(fù)雜的條件。由于后端開(kāi)發(fā)人員對(duì)ES性能優(yōu)化理解不深,為了方便,直接使用了腳本查詢來(lái)實(shí)現(xiàn)動(dòng)態(tài)的業(yè)務(wù)規(guī)則。
四、解決方案與快速恢復(fù)
定位到根因后,我們需要立即止損并徹底修復(fù)。
1. 緊急回滾/下線:立即通過(guò)與前端團(tuán)隊(duì)溝通,臨時(shí)下線或禁用那個(gè)新上的“高級(jí)篩選”功能。這是最快恢復(fù)服務(wù)的辦法。
2. 優(yōu)化ES查詢:長(zhǎng)期方案是重寫那個(gè)低效的查詢。上述腳本查詢完全可以用高效的ES布爾查詢來(lái)替代。
// 優(yōu)化后的布爾查詢
{
"query": {
"bool": {
"filter": [
{"range": {"price": {"gt": 100}}},
{"range": {"sales": {"gt": 50}}}
]
}
}
}優(yōu)化后的查詢利用了Lucene索引的原生能力,性能相比腳本有數(shù)量級(jí)的提升。
3. ES集群緊急擴(kuò)容:由于當(dāng)前集群狀態(tài)已經(jīng)yellow且內(nèi)存壓力大,立即對(duì)ES集群進(jìn)行臨時(shí)擴(kuò)容,增加節(jié)點(diǎn),以分?jǐn)傌?fù)載和分配未分配的分片,確保服務(wù)可用性。
4. ES配置調(diào)優(yōu):審視ES的配置,如indices.fielddata.cache.size,設(shè)置一個(gè)硬限制,防止單個(gè)查詢耗盡內(nèi)存。考慮將一些用于聚合但不用于搜索的字段設(shè)置為"doc_values": true而非"fielddata": true。
五、總結(jié)與反思:構(gòu)建防御體系
問(wèn)題解決后,復(fù)盤是必不可少的。如何避免類似問(wèn)題再次發(fā)生?
1. 強(qiáng)化監(jiān)控與告警:
? 對(duì)ES的關(guān)鍵指標(biāo)(JVM堆內(nèi)存、GC時(shí)間、線程池隊(duì)列、集群狀態(tài))設(shè)置更敏感的多級(jí)告警。
? 在APM中為關(guān)鍵外部服務(wù)(如ES、Redis)的調(diào)用耗時(shí)設(shè)置SLI/SLO,并配置告警。
2. 建立ES查詢規(guī)范:
? 在團(tuán)隊(duì)內(nèi)推行ES查詢最佳實(shí)踐,明令禁止在線上查詢中使用腳本(除非萬(wàn)不得已)。
? 代碼審查階段,必須對(duì)ES的DSL語(yǔ)句進(jìn)行重點(diǎn)審查。
3. 引入熔斷與降級(jí)機(jī)制:
? 在應(yīng)用端,使用Hystrix或Resilience4j等組件,對(duì)ES調(diào)用實(shí)現(xiàn)熔斷。當(dāng)錯(cuò)誤率或慢請(qǐng)求比例超過(guò)閾值時(shí),自動(dòng)熔斷,快速失敗,并返回降級(jí)內(nèi)容(如緩存數(shù)據(jù)、默認(rèn)結(jié)果),避免雪崩效應(yīng)。
4. 預(yù)發(fā)布環(huán)境壓測(cè):
? 任何涉及核心接口或查詢邏輯的變更,必須在預(yù)發(fā)布環(huán)境進(jìn)行充分的壓力測(cè)試,提前發(fā)現(xiàn)性能隱患。
結(jié)論
從一次TP99的突增告警,到最終定位是一個(gè)新功能引入的低效ES腳本查詢,整個(gè)過(guò)程是一次典型的系統(tǒng)性性能問(wèn)題排查。它要求工程師具備跨多個(gè)技術(shù)棧(應(yīng)用、中間件、基礎(chǔ)設(shè)施)的廣度和深度知識(shí),并熟練運(yùn)用監(jiān)控、鏈路追蹤、日志分析這三大工具。通過(guò)建立“從外到內(nèi)、由表及里”的排查框架,我們可以像偵探破案一樣,層層遞進(jìn),最終精準(zhǔn)地揪出問(wèn)題的“真兇”,并建立起防止其卷土重來(lái)的堅(jiān)固防線。