小米數據工場的技術架構和小團隊如何玩轉大數據
原創本文是WOT2016互聯網運維與開發者大會的現場干貨, 新一屆主題為WOT2016企業安全技術峰會將在2016年6月24日-25日于北京珠三角JW萬豪酒店隆重召開!
盧學裕的演講分為小米數據工場的技術架構和小團隊如何玩轉大數據兩部分,從中開發者可以知道小米數據工場的技術架構是怎樣的? 面對大數據的技術紛繁復雜,小團隊要如何面臨缺技術/缺分析師/缺數據等問題?在這種現狀下如何做好技術選型,如何權衡面臨的使用成本和數據隱私擔憂?盧學裕主張一半自建一半用云,然而這又要面臨哪些運維挑戰?
小米數據工場的技術架構
盧學裕表示, 小米數據工廠跟各家的大數據平臺、數據系統有很多類似之處也有自己獨特的點。工廠整個底層基礎平臺建立在Hadoop體系,除此小米跟Cloudera合作也非常緊密。小米整個底層平臺會有專門平臺組去開發,***用的HDFS,上面用的Hive、Spark和Mapreduce這些是混合到一個亞運集群上。Impala小米很早就在用,是一個很重的計算角色。
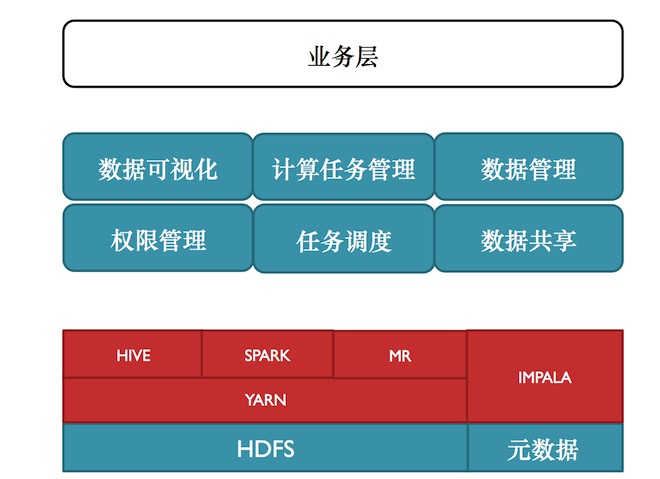
小米數據工場總體結構
如上圖, 上半部分是自研的數據工廠,是為最頂業務層提供服務的。數據工廠主要是提供數據可視化、計算任務管理、數據管理、權限管理、任務調度、數據共享等服務。盧學裕表示,公司越大就更希望數據能夠開放給公司的各個部門,數據可相互利用。但不能沒有任何限制的去使用,所以需要對數據權限做管理。任務調度是整個工廠里面最重的部分。數據共享就是類似非常火的用戶畫像類數據,還有其他公共數據如IP庫,這些數據具有公共特點,就不用重復計算,就可以通過數據共享的方式在各個團隊之間使用這些數據。
數據管理,分為數據預覽、元數據、數據源三部分。數據預覽是每個團隊用來互相了解數據的。
元數據,就是數據使用過程中要把非結構化的數據轉換結構化的數據。元數據管理就是去了解每個字段的含義和機器解析。機器解析包括Mapreduce程序可直接讀文件可解析,如用Impala、Spark和Hive同樣也能解析,而不需要每個使用者再去格式化,再去解析這個數據。但面臨的問題是數據一旦出現格式的轉變或者某些字段的調整,以前任務可能都會出現問題,故一定要統一管理的地方。數據源,數據管理非常核心的是數據集成,能夠把各個地方的數據集成到平臺上來。
HDFS目錄管理。有公共數據空間、業務數據空間、團隊數據空間、個人數據空間、Yarn計算空間五部分。
- 公共數據空間,是用來把公共數據放到上面,把維護權限和讀的權限分開。這樣大部分都是讀這個空間,空間數據安全性等級相對來講比較低,可以付給更多人。
- 業務數據空間,因為每個業務數據的增長量是不一樣的,甚至有些業務會出現如剛上來一個新功能,數據量迅速的增大,有的甚至會出現某個團隊的數據增加,導致把整個集群空間全吃掉,又沒有事先招呼。這種情況下做好業務間的限額配額是非常重要,防止某一個團隊的增長導致整個集群出現一些問題。
- 團隊數據空間,就是把權限控制到個人,用來幫助做團隊之間的數據協作。如把線上任務會放到團隊賬號中去,團隊賬號的權限要做好控制,權限不隨便開放。團隊人員發生變動后,整個團隊任務不用再去切換賬戶而導致交接的復雜性。
- 個人數據空間,數據工程師、開發工程師等是需要做一些調試或做自己的計算這就要給這些人一定空間的同時對其數據做配額。這是為了防止這些人過多的使用資源和為了空間不夠需要清理數據時,哪些數據要清理,哪些數據不能清理一目了然。這樣限制空間的情況下,這種廢文件或者垃圾文件的積累會相對較少。
- Yarn計算空間,做配額限制呢是為了杜絕空間濫用的問題。盧學裕舉例道,“之前發生過一件事,某人在Reduce里面寫了一個死循環,不停的輸出數據,導致整個集群很快就去報警。后來才發現這個計算造成的一些問題,***差點導致那些日志上傳、數據的寫入都出問題,幸虧處理的比較及時。”所以,Yarn計算空間是需要做一個配額限制,防止對整個集群造成過大的影響。
盧學裕表示,小米數據存儲格式統一采用的Parquet,優點在于其使用的是列式存儲,支持Mapreduce、Hive、Impala、Spark和讀取快占用空間少。

客戶端數據接入兩種模式優劣勢
客戶端數據接入。客戶端指的是如說Wap、App等數據,存在方式有SDK和服務端Log兩種模式。上圖為兩種模式的優劣勢。
服務器端數據源。除前端數據源外,整個處理數據時還會有大量服務器端數據源需要處理。業務數據庫類,用ETL工具做導入。服務器端日志,用Scribe將數據寫入HDFS。
元數據管理。當公司業務變多后,每一個數據的處理方式都有可能不一樣,這時候就凸顯出元數據管理的重要性。如視頻播放日志,分析師希望用Hive,用Impala直接寫SQL去計算,但數據挖掘工程師就要去寫Mapreduce,寫Spark的方式去讀,去解析。元數據管理就是要做數據統一,既能夠滿足Hive、Spark、Impala,還能滿足Mapreduce。這樣一來節省大家對數據理解、執行的時間。
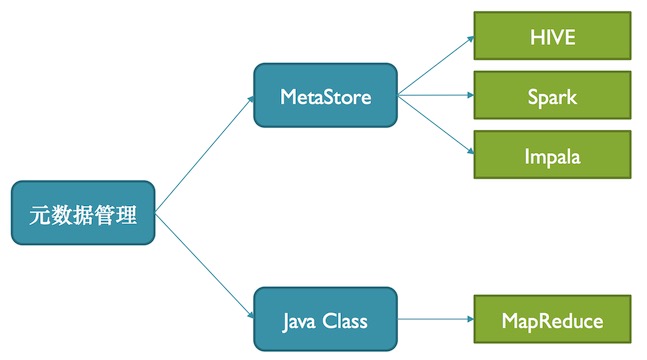
元數據管理
如上圖,小米數據工廠是每一份數據的描述都需要在數據工廠上提交,之后數據工廠會在MetaStore中做建表的同時帶上元數據的行為,供Hive、Spark、Impala使用。數據管理還會生成Jave Class,給Mapreduce使用。當去解析用某個數據時候,可以直接用這樣的方式把它解析成Jave類。

計算管理
計算管理。盧學裕表示,計算是很重要的事情,數據管理相對來講是一次性的活,計算就是很復雜的事情。計算任務數一天達到幾千或過萬時,就會變得非常復雜。對于計算管理這快優化,小米做了如上圖的一些工作。
Docker。為了管理好這些紛繁的計算框架和模型,在計算的執行方面,小米使用Docker來解決對環境的不同需求和異構問題,并且與Hive、Impala、Spark這些不同的計算模型都進行了對接,去適配不同應用場景計算不同數據的模型。另外,在不同業務場景下,同一個計算邏輯也可以選用不同的計算模型,Docker 的使用也避免了資源的浪費。比如一個計算任務每天凌晨運行,為了追求吞吐量,可以放到Hive里跑;還是同樣一個計算模型,現在就要跑,可以不用更改,就放到Impala里運行。Docker不僅解決了環境的異構,也解決了資源問題。另外,Docker的環境適應性很強,做橫向擴展會比較容易。對于數據隱私方面,小米考慮得非常重。采用Docker與自身安全策略的綜合,小米用戶數據的隱私和安全性也得到了極其嚴格的控制。
小團隊如何玩轉大數據
小團隊玩大數據會面臨哪些問題?小團隊會面臨人力資源不足,技術儲備不足,時間有限等問題。面對這些問題,盧學裕在技術選型上給出如下三個建議。
- 選擇熱門技術。因為人才比較多,相對獲取這樣人才會比較容易。技術成熟,因為小團隊沒有時間去踩坑。還有幫助多,這如說網上文檔幫助、社群幫助,朋友幫助等。
- 夠用。針對一些小團隊或者初創公司的特點,業務變化特別快,也不穩定,這種情況下做到夠用就好,不需要過分的設計和采用過重的系統。盡量根據業務驅動,業務需要什么數據就抓什么數據。
- 演進。隨著需求的變化需要不斷的演進,包括系統演進、使用方式演進。
一定要做好數據積累。盧學裕表示,無論你用什么樣的技術,用Hadoop也好,不用Hadoop也好,一定要做好數據的積累,這是對一家數據公司非常重要的部分。這就需要提前規劃好數據,還要避免邏輯孤島。還需要注意ID問題,也就是關聯的問題。當采集了數據,卻發現沒有采用戶ID,沒有提前做好這個規劃,當算到用戶級別時候那就尷尬了。
演講***,盧學裕強調:“現在越來越多業務都回到了用戶時代,以前講的是流量時代,講的是PV如何。回到用戶時代,核心問題就是我們要做好用戶的數據積累,尤其是用戶模型建立。模型包括的畫像、用戶點點滴滴行為等。這些行為在業務發展之后,尤其是要做數據挖掘,做推薦系統時,會非常非常的有幫助。建議大家做好這樣的數據積累,在數據技術上隨著變化可以不停的再做一些改變,甚至做一些混合,在不同的地方用不同的方式。
演講視頻:http://edu.51cto.com/lesson/id-100757.html
講師簡介:
現任火線數據創始人兼CEO,前小米科技小米云團隊,負責小米數據工場。之前擔任優酷土豆大數據團隊技術總監,打造了優酷土豆的大數據開放平臺、數據分析、數據挖掘、推薦系統等。最早服務于騰訊客戶端安全團隊做技術開發。