













自然語言處理第一番之文本分類器
前言
文本分類應(yīng)該是自然語言處理中最普遍的一個(gè)應(yīng)用,例如文章自動(dòng)分類、郵件自動(dòng)分類、垃圾郵件識(shí)別、用戶情感分類等等,在生活中有很多例子,這篇文章主要從傳統(tǒng)和深度學(xué)習(xí)兩塊來解釋下我們?nèi)绾巫鲆粋€(gè)文本分類器。
文本分類方法
傳統(tǒng)的文本方法的主要流程是人工設(shè)計(jì)一些特征,從原始文檔中提取特征,然后指定分類器如LR、SVM,訓(xùn)練模型對(duì)文章進(jìn)行分類,比較經(jīng)典的特征提取方法如頻次法、tf-idf、互信息方法、N-Gram。
深度學(xué)習(xí)火了之后,也有很多人開始使用一些經(jīng)典的模型如CNN、LSTM這類方法來做特征的提取, 這篇文章會(huì)比較粗地描述下,在文本分類的一些實(shí)驗(yàn)
傳統(tǒng)文本分類方法
這里主要描述兩種特征提取方法:頻次法、tf-idf、互信息、N-Gram。
頻次法
頻次法,顧名思義,十分簡(jiǎn)單,記錄每篇文章的次數(shù)分布,然后將分布輸入機(jī)器學(xué)習(xí)模型,訓(xùn)練一個(gè)合適的分類模型,對(duì)這類數(shù)據(jù)進(jìn)行分類,需要指出的時(shí),在統(tǒng)計(jì)次數(shù)分布時(shí),可合理提出假設(shè),頻次比較小的詞對(duì)文章分類的影響比較小,因此我們可合理地假設(shè)閾值,濾除頻次小于閾值的詞,減少特征空間維度。
TF-IDF
TF-IDF相對(duì)于頻次法,有更進(jìn)一步的考量,詞出現(xiàn)的次數(shù)能從一定程度反應(yīng)文章的特點(diǎn),即TF,而TF-IDF,增加了所謂的反文檔頻率,如果一個(gè)詞在某個(gè)類別上出現(xiàn)的次數(shù)多,而在全部文本上出現(xiàn)的次數(shù)相對(duì)比較少,我們認(rèn)為這個(gè)詞有更強(qiáng)大的文檔區(qū)分能力,TF-IDF就是綜合考慮了頻次和反文檔頻率兩個(gè)因素。
互信息方法
互信息方法也是一種基于統(tǒng)計(jì)的方法,計(jì)算文檔中出現(xiàn)詞和文檔類別的相關(guān)程度,即互信息
N-Gram
基于N-Gram的方法是把文章序列,通過大小為N的窗口,形成一個(gè)個(gè)Group,然后對(duì)這些Group做統(tǒng)計(jì),濾除出現(xiàn)頻次較低的Group,把這些Group組成特征空間,傳入分類器,進(jìn)行分類。
深度學(xué)習(xí)方法
基于CNN的文本分類方法
- 最普通的基于CNN的方法就是Keras上的example做情感分析,接Conv1D,指定大小的window size來遍歷文章,加上一個(gè)maxpool,如此多接入幾個(gè),得到特征表示,然后加上FC,進(jìn)行最終的分類輸出。
- 基于CNN的文本分類方法,最出名的應(yīng)該是2014 Emnlp的 Convolutional Neural Networks for Sentence Classification,使用不同filter的cnn網(wǎng)絡(luò),然后加入maxpool, 然后concat到一起。
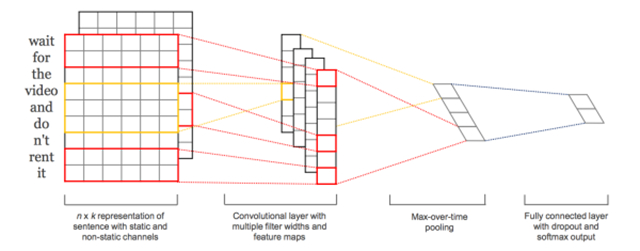
- 這類CNN的方法,通過設(shè)計(jì)不同的window size來建模不同尺度的關(guān)系,但是很明顯,丟失了大部分的上下文關(guān)系,Recurrent Convolutional Neural Networks for Text Classification,將每一個(gè)詞形成向量化表示時(shí),加上上文和下文的信息,每一個(gè)詞的表示如下:
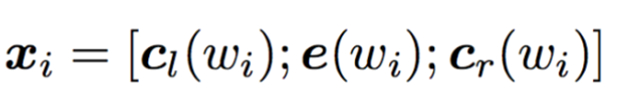
整個(gè)結(jié)構(gòu)框架如下:
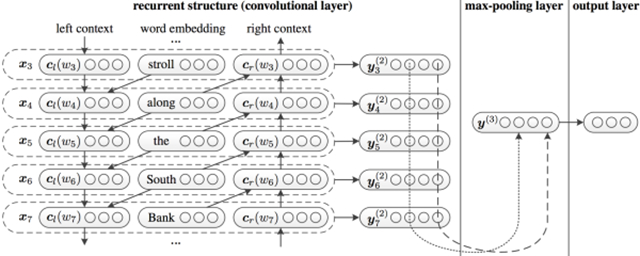
- 如針對(duì)這句話”A sunset stroll along the South Bank affords an array of stunning vantage points”,stroll的表示包括c_l(stroll),pre_word2vec(stroll),c_r(stroll), c_l(stroll)編碼A sunset的語義,而c_r(stroll)編碼along the South Bank affords an array of stunning vantage points的信息,每一個(gè)詞都如此處理,因此會(huì)避免普通cnn方法的上下文缺失的信息。
基于LSTM的方法
- 和基于CNN的方法中***種類似,直接暴力地在embedding之后加入LSTM,然后輸出到一個(gè)FC進(jìn)行分類,基于LSTM的方法,我覺得這也是一種特征提取方式,可能比較偏向建模時(shí)序的特征;
- 在暴力的方法之上,A C-LSTM Neural Network for Text Classification,將embedding輸出不直接接入LSTM,而是接入到cnn,通過cnn得到一些序列,然后吧這些序列再接入到LSTM,文章說這么做會(huì)提高***分類的準(zhǔn)去率。
代碼實(shí)踐
語料及任務(wù)介紹
訓(xùn)練的語料來自于大概31個(gè)新聞?lì)悇e的新聞?wù)Z料,但是其中有一些新聞數(shù)目比較少,所以取了數(shù)量比較多的前20個(gè)新聞?lì)惐鹊男侣務(wù)Z料,每篇新聞稿字?jǐn)?shù)從幾百到幾千不等,任務(wù)就是訓(xùn)練合適的分類器然后將新聞分為不同類別:

Bow
Bow對(duì)語料處理,得到tokens set:
- def __get_all_tokens(self):
- """ get all tokens of the corpus
- """
- fwrite = open(self.data_path.replace("all.csv","all_token.csv"), 'w')
- with open(self.data_path, "r") as fread:
- i = 0
- # while True:
- for line in fread.readlines():
- try:
- line_list = line.strip().split("\t")
- label = line_list[0]
- self.labels.append(label)
- text = line_list[1]
- text_tokens = self.cut_doc_obj.run(text)
- self.corpus.append(' '.join(text_tokens))
- self.dictionary.add_documents([text_tokens])
- fwrite.write(label+"\t"+"\\".join(text_tokens)+"\n")
- i+=1
- except BaseException as e:
- msg = traceback.format_exc()
- print msg
- print "=====>Read Done<======"
- break
- self.token_len = self.dictionary.__len__()
- print "all token len "+ str(self.token_len)
- self.num_data = i
- fwrite.close()
然后,tokens set 以頻率閾值進(jìn)行濾除,然后對(duì)每篇文章做處理來進(jìn)行向量化:
- def __filter_tokens(self, threshold_num=10):
- small_freq_ids = [tokenid for tokenid, docfreq in self.dictionary.dfs.items() if docfreq < threshold_num ]
- self.dictionary.filter_tokens(small_freq_ids)
- self.dictionary.compactify()
- def vec(self):
- """ vec: get a vec representation of bow
- """
- self.__get_all_tokens()
- print "before filter, the tokens len: {0}".format(self.dictionary.__len__())
- self.__filter_tokens()
- print "After filter, the tokens len: {0}".format(self.dictionary.__len__())
- self.bow = []
- for file_token in self.corpus:
- file_bow = self.dictionary.doc2bow(file_token)
- self.bow.append(file_bow)
- # write the bow vec into a file
- bow_vec_file = open(self.data_path.replace("all.csv","bow_vec.pl"), 'wb')
- pickle.dump(self.bow,bow_vec_file)
- bow_vec_file.close()
- bow_label_file = open(self.data_path.replace("all.csv","bow_label.pl"), 'wb')
- pickle.dump(self.labels,bow_label_file)
- bow_label_file.close()
最終就得到每篇文章的bow的向量,由于這塊的代碼是在我的筆記本上運(yùn)行的,直接跑占用內(nèi)存太大,因?yàn)槊恳黄恼略趖oken set中的表示是極其稀疏的,因此我們可以選擇將其轉(zhuǎn)為csr表示,然后進(jìn)行模型訓(xùn)練,轉(zhuǎn)為csr并保存中間結(jié)果代碼如下:
- def to_csr(self):
- self.bow = pickle.load(open(self.data_path.replace("all.csv","bow_vec.pl"), 'rb'))
- self.labels = pickle.load(open(self.data_path.replace("all.csv","bow_label.pl"), 'rb'))
- data = []
- rows = []
- cols = []
- line_count = 0
- for line in self.bow:
- for elem in line:
- rows.append(line_count)
- cols.append(elem[0])
- data.append(elem[1])
- line_count += 1
- print "dictionary shape ({0},{1})".format(line_count, self.dictionary.__len__())
- bow_sparse_matrix = csr_matrix((data,(rows,cols)), shape=[line_count, self.dictionary.__len__()])
- print "bow_sparse matrix shape: "
- print bow_sparse_matrix.shape
- # rarray=np.random.random(size=line_count)
- self.train_set, self.test_set, self.train_tag, self.test_tag = train_test_split(bow_sparse_matrix, self.labels, test_size=0.2)
- print "train set shape: "
- print self.train_set.shape
- train_set_file = open(self.data_path.replace("all.csv","bow_train_set.pl"), 'wb')
- pickle.dump(self.train_set,train_set_file)
- train_tag_file = open(self.data_path.replace("all.csv","bow_train_tag.pl"), 'wb')
- pickle.dump(self.train_tag,train_tag_file)
- test_set_file = open(self.data_path.replace("all.csv","bow_test_set.pl"), 'wb')
- pickle.dump(self.test_set,test_set_file)
- test_tag_file = open(self.data_path.replace("all.csv","bow_test_tag.pl"), 'wb')
- pickle.dump(self.test_tag,test_tag_file)
***訓(xùn)練模型代碼如下:
- def train(self):
- print "Beigin to Train the model"
- lr_model = LogisticRegression()
- lr_model.fit(self.train_set, self.train_tag)
- print "End Now, and evalution the model with test dataset"
- # print "mean accuracy: {0}".format(lr_model.score(self.test_set, self.test_tag))
- y_pred = lr_model.predict(self.test_set)
- print classification_report(self.test_tag, y_pred)
- print confusion_matrix(self.test_tag, y_pred)
- print "save the trained model to lr_model.pl"
- joblib.dump(lr_model, self.data_path.replace("all.csv","bow_lr_model.pl"))
TF-IDF
TF-IDF和Bow的操作十分類似,只是在向量化使使用tf-idf的方法:
- def vec(self):
- """ vec: get a vec representation of bow
- """
- self.__get_all_tokens()
- print "before filter, the tokens len: {0}".format(self.dictionary.__len__())
- vectorizer = CountVectorizer(min_df=1e-5)
- transformer = TfidfTransformer()
- # sparse matrix
- self.tfidf = transformer.fit_transform(vectorizer.fit_transform(self.corpus))
- words = vectorizer.get_feature_names()
- print "word len: {0}".format(len(words))
- # print self.tfidf[0]
- print "tfidf shape ({0},{1})".format(self.tfidf.shape[0], self.tfidf.shape[1])
- # write the tfidf vec into a file
- tfidf_vec_file = open(self.data_path.replace("all.csv","tfidf_vec.pl"), 'wb')
- pickle.dump(self.tfidf,tfidf_vec_file)
- tfidf_vec_file.close()
- tfidf_label_file = open(self.data_path.replace("all.csv","tfidf_label.pl"), 'wb')
- pickle.dump(self.labels,tfidf_label_file)
- tfidf_label_file.close()
這兩類方法效果都不錯(cuò),都能達(dá)到98+%的準(zhǔn)確率。
CNN
語料處理的方法和傳統(tǒng)的差不多,分詞之后,使用pretrain 的word2vec,這里我遇到一個(gè)坑,我開始對(duì)我的分詞太自信了,***模型一直不能收斂,后來向我們組博士請(qǐng)教,極有可能是由于分詞的詞序列中很多在pretrained word2vec里面是不存在的,而我這部分直接丟棄了,所有可能存在問題,分詞添加了詞典,然后,對(duì)于pre-trained word2vec不存在的詞做了一個(gè)隨機(jī)初始化,然后就能收斂了,學(xué)習(xí)了!!!
載入word2vec模型和構(gòu)建cnn網(wǎng)絡(luò)代碼如下(增加了一些bn和dropout的手段):
- def gen_embedding_matrix(self, load4file=True):
- """ gen_embedding_matrix: generate the embedding matrix
- """
- if load4file:
- self.__get_all_tokens_v2()
- else:
- self.__get_all_tokens()
- print "before filter, the tokens len: {0}".format(
- self.dictionary.__len__())
- self.__filter_tokens()
- print "after filter, the tokens len: {0}".format(
- self.dictionary.__len__())
- self.sequence = []
- for file_token in self.corpus:
- temp_sequence = [x for x, y in self.dictionary.doc2bow(file_token)]
- print temp_sequence
- self.sequence.append(temp_sequence)
- self.corpus_size = len(self.dictionary.token2id)
- self.embedding_matrix = np.zeros((self.corpus_size, EMBEDDING_DIM))
- print "corpus size: {0}".format(len(self.dictionary.token2id))
- for key, v in self.dictionary.token2id.items():
- key_vec = self.w2vec.get(key)
- if key_vec is not None:
- self.embedding_matrix[v] = key_vec
- else:
- self.embedding_matrix[v] = np.random.rand(EMBEDDING_DIM) - 0.5
- print "embedding_matrix len {0}".format(len(self.embedding_matrix))
- def __build_network(self):
- embedding_layer = Embedding(
- self.corpus_size,
- EMBEDDING_DIM,
- weights=[self.embedding_matrix],
- input_length=MAX_SEQUENCE_LENGTH,
- trainable=False)
- # train a 1D convnet with global maxpooling
- sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH, ), dtype='int32')
- embedded_sequences = embedding_layer(sequence_input)
- x = Convolution1D(128, 5)(embedded_sequences)
- x = BatchNormalization()(x)
- x = Activation('relu')(x)
- x = MaxPooling1D(5)(x)
- x = Convolution1D(128, 5)(x)
- x = BatchNormalization()(x)
- x = Activation('relu')(x)
- x = MaxPooling1D(5)(x)
- print "before 256", x.get_shape()
- x = Convolution1D(128, 5)(x)
- x = BatchNormalization()(x)
- x = Activation('relu')(x)
- x = MaxPooling1D(15)(x)
- x = Flatten()(x)
- x = Dense(128)(x)
- x = BatchNormalization()(x)
- x = Activation('relu')(x)
- x = Dropout(0.5)(x)
- print x.get_shape()
- preds = Dense(self.class_num, activation='softmax')(x)
- print preds.get_shape()
- adam = Adam(lr=0.0001)
- self.model = Model(sequence_input, preds)
- self.model.compile(
- loss='categorical_crossentropy', optimizer=adam, metrics=['acc'])
另外一種網(wǎng)絡(luò)結(jié)構(gòu),韓國人那篇文章,網(wǎng)絡(luò)構(gòu)造如下:
- def __build_network(self):
- embedding_layer = Embedding(
- self.corpus_size,
- EMBEDDING_DIM,
- weights=[self.embedding_matrix],
- input_length=MAX_SEQUENCE_LENGTH,
- trainable=False)
- # train a 1D convnet with global maxpooling
- sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH, ), dtype='int32')
- embedded_sequences = embedding_layer(sequence_input)
- conv_blocks = []
- for sz in self.filter_sizes:
- conv = Convolution1D(
- self.num_filters,
- sz,
- activation="relu",
- padding='valid',
- strides=1)(embedded_sequences)
- conv = MaxPooling1D(2)(conv)
- conv = Flatten()(conv)
- conv_blocks.append(conv)
- z = Merge(
- conv_blocks,
- mode='concat') if len(conv_blocks) > 1 else conv_blocks[0]
- z = Dropout(0.5)(z)
- z = Dense(self.hidden_dims, activation="relu")(z)
- preds = Dense(self.class_num, activation="softmax")(z)
- rmsprop = RMSprop(lr=0.001)
- self.model = Model(sequence_input, preds)
- self.model.compile(
- loss='categorical_crossentropy',
- optimizer=rmsprop,
- metrics=['acc'])
LSTM
由于我這邊的task是對(duì)文章進(jìn)行分類,序列太長(zhǎng),直接接LSTM后直接爆內(nèi)存,所以我在文章序列直接,接了兩層Conv1D+MaxPool1D來提取維度較低的向量表示然后接入LSTM,網(wǎng)絡(luò)結(jié)構(gòu)代碼如下:
- def __build_network(self):
- embedding_layer = Embedding(
- self.corpus_size,
- EMBEDDING_DIM,
- weights=[self.embedding_matrix],
- input_length=MAX_SEQUENCE_LENGTH,
- trainable=False)
- # train a 1D convnet with global maxpooling
- sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH, ), dtype='int32')
- embedded_sequences = embedding_layer(sequence_input)
- x = Convolution1D(
- self.num_filters, 5, activation="relu")(embedded_sequences)
- x = MaxPooling1D(5)(x)
- x = Convolution1D(self.num_filters, 5, activation="relu")(x)
- x = MaxPooling1D(5)(x)
- x = LSTM(64, dropout_W=0.2, dropout_U=0.2)(x)
- preds = Dense(self.class_num, activation='softmax')(x)
- print preds.get_shape()
- rmsprop = RMSprop(lr=0.01)
- self.model = Model(sequence_input, preds)
- self.model.compile(
- loss='categorical_crossentropy',
- optimizer=rmsprop,
- metrics=['acc'])
CNN 結(jié)果:
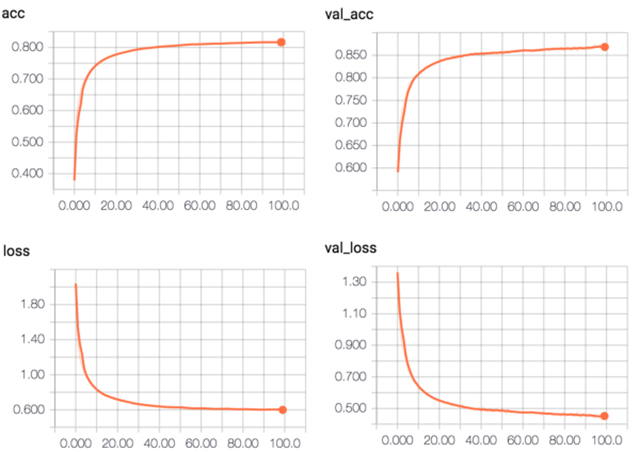
C-LSTM 結(jié)果:
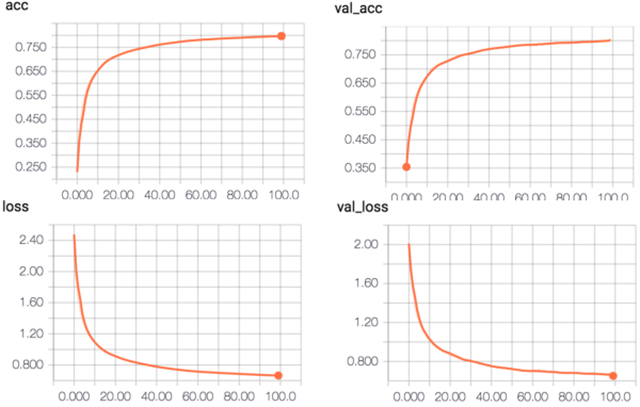
整個(gè)實(shí)驗(yàn)的結(jié)果由于深度學(xué)習(xí)這部分都是在公司資源上跑的,沒有真正意義上地去做一些trick來調(diào)參來提高性能,這里所有的代碼的網(wǎng)絡(luò)配置包括參數(shù)都僅做參考,更深地工作需要耗費(fèi)更多的時(shí)間來做參數(shù)的優(yōu)化。
PS: 這里發(fā)現(xiàn)了一個(gè)keras 1.2.2的bug, 在寫回調(diào)函數(shù)TensorBoard,當(dāng)histogram_freq=1時(shí),顯卡占用明顯增多,M40的24g不夠用,個(gè)人感覺應(yīng)該是一個(gè)bug,但是考慮到1.2.2而非2.0,可能后面2.0都優(yōu)化了。
所有的代碼都在github上:tensorflow-101/nlp/text_classifier/scripts
總結(jié)和展望
在本文的實(shí)驗(yàn)效果中,雖然基于深度學(xué)習(xí)的方法和傳統(tǒng)方法相比沒有什么優(yōu)勢(shì),可能原因有幾個(gè)方面:
- Pretrained Word2vec Model并沒有覆蓋新聞中切分出來的詞,而且比例還挺高,如果能用網(wǎng)絡(luò)新聞?wù)Z料訓(xùn)練出一個(gè)比較精準(zhǔn)的Pretrained Word2vec,效果應(yīng)該會(huì)有很大的提升;
- 可以增加模型訓(xùn)練收斂的trick以及優(yōu)化器,看看是否有準(zhǔn)確率的提升;
- 網(wǎng)絡(luò)模型參數(shù)到現(xiàn)在為止,沒有做過深的優(yōu)化。



















