Apache Kafka:大數據的實時處理時代
在過去幾年,對于 Apache Kafka 的使用范疇已經遠不僅是分布式的消息系統:我們可以將每一次用戶點擊,每一個數據庫更改,每一條日志的生成,都轉化成實時的結構化數據流,更早的存儲和分析它們,并從中獲得價值。同時,越來越多的企業應用也開始從批處理數據平臺向實時的流數據數據平臺轉移。本演講將介紹最近 Apache Kafka 添加的一些系統架構,包括 Kafka Connect 和 Kafka Streams,并且描述一些如何使用它們的實際應用體驗。
注:本文由王國璋在 QCon 北京 2017 站上的演講整理而成。
流處理
在流處理剛被提出來的時候,很多人認為流處理只能進行做近似的結果或者增量的計算,倘若你想保證其安全性,以 Lamda 架構為基礎,利用流處理得到最現在的結果。但同時你需要采用 batch processing 等其他方式來保證其全局的安全性以正確性。
在如此多年的研究結果下,在我看來,流處理并不一定是近似的,或者是僅僅以無法保證真確性為代價而提高速度的一種數據處理方式。相反,流處理應該是一個與全局計算、batch processing 稍微有點不同的計算模型。跟批量處理不同之處在于,批量處理將數據引向計算,而流處理將計算引向數據。這句話大概有點模糊,接下來,我舉幾個大家熟悉的計算模型例子。
***個計算模型例子—請求應答模型。

請求應答模型是業務生活中最常用的模型例子。首先提交一個請求到服務方,而服務方可能是一個數據庫、也可能是別的存儲工具;然后進行等待…等待;***得到一個回答。這便是一次請求、一次計算、一次回答。該模型非常簡單、也極易操作,當你需要延展到多個機器上時,只要簡單地增加客戶端以及處理器即可成功。但是缺點在于,不能達到大的吞吐量,每提交一次請求,都需要等待時間來獲得最終應答的結果。

第二種常見的模型就是批量處理如上圖所示。如果請求應答模型在譜系的一端,那么 typo 的另一端則認為是批量處理。當我積累數據數量足夠多的時候,一次性提交任務到數據倉庫,再進行等待,等待時間短則幾秒鐘、幾分鐘,長則幾小時,***才得到最終的結果—所有輸入對應的所有輸出。該批處理模型的好處在于能夠提高其吞吐率,一次的請求和應答可以得出較多結果。但它的缺點是具有高延時性,比如某數據產生時間為上午 6 點鐘,用戶點擊某網頁,由于批處理模型,每 12 小時才會運行一次,那么它必須等到上午 6 點到下午 6 點的所有數據完整以后才會進行工作,那么運行結果可能是用戶點擊的 12 個小時之后。高延遲性是批處理自身帶有的特性。
那么什么是流處理呢? 在我看來,流處理就是介于請求應答和批處理之間的一種新型計算模型或者編程模型。流處理并不等待數據的完整性,或者說數據本沒有完整性這一講法,數據本身就是一個數據流,當每個數據流每產生一個新數據的時候立刻被計算出、進行返回,因此數據是源源不斷地通向計算,并且源源不斷有結果被輸出。你可以設想,與等待數據完全完成之后發布到計算上相比,流處理就是將計算移到你數據發生地進行實時計算的方式。
為什么很多人之前有這樣一種錯覺,他們認為流處理可能存在有丟包的情況、或者說只可以得到近似的結果,其實這是早期的一些數據流處理系統所自帶的一些限制。因此以 Lamda 架構為基礎,在流處理上需要討論不同維度的取舍。接下里我將舉三個例子,延遲、、成本和正確性。正如很多人之前提及的,在進行流處理時候,其大多數情況需要用時間來換取正確性,或者用更多的成本換取時間等等。
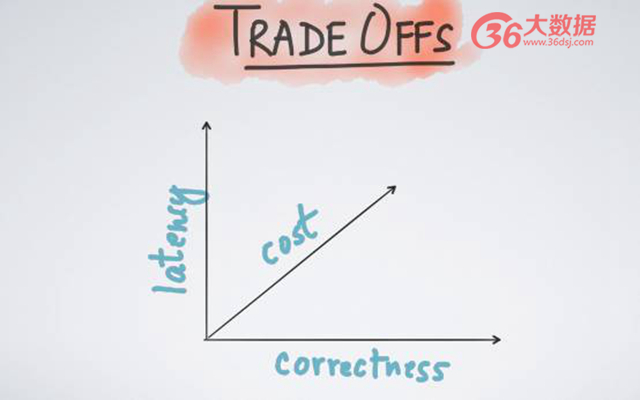
***個例子,說如果你需要做一個實時的 ETL 處理。而關于 ETL 處理不需要太小的延遲,為達到低成本的一種保證,我們可以忍受幾分鐘或者 1 分鐘的延遲;但是,如果你正在進行一個實時的在線監測,存在著幾毫秒的延遲,那么這時候可能更愿意選擇花大量的金錢,或者采取一些可能不必要的 possibility 來達到一種低延遲的效果;第二個例子,假設你在做一個在線付費協議,它也是一個流處理平臺。由于在線付費協議可能關乎到其機構,或者其公司的利益所在,因此你會說,我需要保證***的正確性,我不希望有任何丟包情況;
第三個例子,如果你是做一個實時的日志處理,實時收集所有日志,并將其導入 root,在這種情況下,你可能會說,為了降低成本,我愿意付出一小部分正確性的代價,即使不能達到 100%、達到 99.99%、達到 99.9%,這樣的結果都可以接受。這本是用戶在定義不同流處理應用或者業務的時候應該可以自己做出的選擇。但比較遺憾的是,多數早期的流處理平臺其實并沒有給予用戶該種選擇,他們自身的設計理念,那就是為了低延遲直接放棄掉正確性,或者說為了更高的吞吐量直接放棄低延遲。
以上是我想分享的關于流處理的一些誤會認知,如果我的分享能夠讓大家帶走兩個答案的話,我希望這就是一個。我認為流處理僅僅是一種不一樣的計算模型或者編程模型,它將計算帶到數據上,而不是將數據引用到計算上,并且在流處理的時候,用戶往往需要在正確性、延遲性、成本等不同的維度上做出選擇。
Kafka 的角色
為什么當我們說到流處理的時候,很多人都在說 Kafka。大多數人在最早接觸 Kafka 時會說,Kafka 就是一個分布式發布訂閱的消息系統,但是如果我們去觀察 Kafka 的最初一些設計特性可發現以下幾點內容。***點,它可以作為一個寫在磁盤上的緩存來使用,或者說,并不是僅基于內存來存儲流數據,它可以保證數據包不被及時消費時,依然可用且不被丟失;第二點,由于位移的存在提供了邏輯上的順序,在同一個話題上,***個數據比第二個數據***被發布的時候,也可保證在消費時也是永遠***個數據比第二個數據先被消費;第三點,因為 Kafka 是一個公有的大數據中轉站,就是說,所有的數據只要在 Kafka 上,永遠可以在 Kafka 周圍進行業務的開發或者認知事物的開發。接下來我將花費一些時間詳細介紹這三點之間的關系。
Kafka 不僅僅是一個訂閱消息系統,同時也是一個大規模的流數據平臺,那么它提供了什么呢?***,提供訂閱和發布消息;第二,提供一個緩存的流數據存儲平臺;第三,提供流數據的處理平臺。今天,我將著重討論流式計算在 Kafka 上面的應用。
流式計算在 Kafka 上的應用主要有哪些選項呢?***個選項就是 DIY,Kafka 提供了兩個客戶端 —— 一個簡單的發布者和一個簡單的消費者,我們可以使用這兩個客戶端進行簡單的流處理操作。舉個簡單的例子,利用消息消費者來實時消費數據,每當得到新的消費數據時,可做一些計算的結果,再通過數據發布者發布到 Kafka 上,或者將它存儲到第三方存儲系統中。DIY 的流處理需要成本。打個比方,考慮數據的延遲性,考慮不同時間上的管理分配,正如很多人提到的 processing time,這將是我后文會重點提及的概念。以上這些都說明,利用 DIY 做流處理任務、或者做流處理業務的應用都不是非常簡單的一件事情。
第二個選項是進行開源、閉源的流處理平臺。比如,spark。關于流處理平臺的一個公有認知的表示是,如果你想進行流處理操作,首先拿出一個集群,且該集群包含所有必需內容,比如,如果你要用 spark,那么必須用 spark 的 runtime。因為他們劃定了你作為一個流處理平臺使用者需要用到的所有行為,比如,資源管理系統、參數調配系統、容器配置、代碼封裝、分發等,以上行為都已被該平臺所限定。一旦你選擇使用甲就必須用甲套餐裝備,如果選擇使用乙就必須使用乙套餐裝備。有人不禁提出疑問,我能不能既選擇流處理平臺,又使用自己選擇的,我能不能這樣做呢?
這個應用場景其實很普遍,舉個例子,可異步式微服務處理。什么叫異步式微服務處理?假設 Kafka 作為一個緩存數據,在該緩存區含有很多不同的業務。打個比方,一個網店的機構可以有不同的組、不同的員工,有人負責銷售、有人負責商品分發,有人負責價格管理、有人負責在線實時的限流監控,不同的組、不同的員工可能會以不同的時間,或者以不同的代碼來更新他們的產品,只要擁有一個異步式緩存機制,即 Kafka,便可擴大該微服務,而不需要他們的任何一個組之間進行同步請求應答機制。
在該微服務情況下,每個小組的喜好、特性并不一致,有的組表示我需要做流處理平臺,從 Kafka 讀數據,處理完再寫回 Kafka,并且想要使用 EWS 把我的應用部署在云端大規模集群上;而另外小組表示我不需要那么復雜,我只是小規模數據,不希望起一個集群,只需起三個機器,并且每個機器有 1GB 內存足以,可進行手動控制操作,不需要資源管理器。那么我們能不能同時滿足他們不同的需求呢? 答案就是我接下來要說的第三種選項。
第三種選項是使用一個輕量級流處理的庫,而不需要使用一個廣泛、復雜的框架或者平臺來滿足他們不同的需求。在 Kafka 0.10 當中已發布輕量級流處理內容平臺,我們可以設想,跟其他客戶端發布者和消費者一樣,它也是一個客戶端,不同之處在于它是一個計算者客戶端,一個好用的、功能強大的客戶端,并且支持 state processing、Windows 延時的、異步的、甚至不同數據的調控。 最重要的是 Kafka 作為一個庫,可以采用多種方法來發布流處理平臺的使用。比如,你可以構建一個集群;你可以把它作為一個手提電腦來使用;甚至還可以在黑莓上運行 Kafka。以上都是尤其簡單的運行庫的概念。

因此我們要做的事情與使用 Kafka 其他的客戶端類似,比如發布者、消費者,只要在代碼里邊加入就可以使用各種各樣的 API。當你要調配控制 Kafka Stream 應用的時候,選擇最基礎的 War File 來運行或者采用 Java、C,甚至資源管理器來運行都是可行的。因為 Kafka Stream 是一個輕量級流處理的庫,可支持各種各樣的運維方式。
在我們看來,簡單的就是美的,只有給用戶提供***的兼容性與***的延展性,用戶才能得到***的用戶體驗。
Kafka Stream 的編程語言

如果接觸過 Storm、Spark 等流處理平臺的同學可以發現,它們與 Kafka Stream 高階位 DSL 語言其實有相似之處。如上圖所示,首先定義一個 Streams 流, Streams 是從 topic1 中的 topic 獲取得到,即定義 Streams、處理 Streams、得到新的 Streams。比如,從 topic1 里面得到兩個原始數據流,然后數據流進行 countByKey 得到新的數據流叫做 Counts。那么 counts.to(“topic2”) 是什么意思呢?在獲取到新的數據流之后寫回 Kafka topic2 內,啟動 KafkaStreams 進程,與 Kafka producer、Kafka consumer 類似,讓它來運行已定義計算。

正如大家所了解的,API 的使用其實很簡單。提供一個簡單的 API,用戶簡單地寫入運行邏輯即可運行。但是編程應用總是容易的,而它的復雜程度在于,一旦你開始運維該應用,當你想要把業務拓展到更大規模,或者業務出現變化,或者集群不穩定,需要強大的運維時,運維的程度便顯得異常重要,最上面的編程可能只是冰山一角。Kafka Stream 的設計理念是最簡單的就是最美的,包括 API、運維、debugging,以及各種各樣的方式,都是希望給用戶帶來最簡單的體驗。它的核心思想就是把難問題直接給 Kafka 集群本身。
Kafka 的介紹
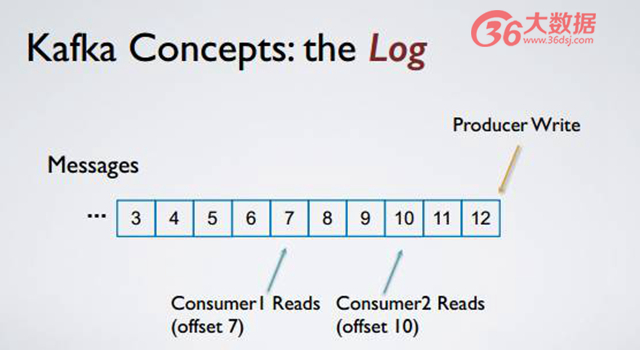
Kafka 的核心思想是什么?就是把這些消息全部存成一個有序日志,所有的消息發布者把消息發布到底端,從某一個邏輯上的位移開始順序讀取所有的消息。它的一個好處在于所有的讀和寫,盡管都是刷到磁盤上,但都是按照順序進行,該方式對磁盤的使用比較有效,倘若消費者和發布者隔得比較近,將利用 page cash 直接讀數據。
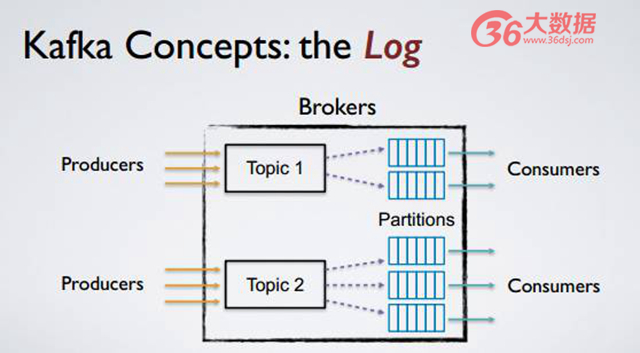
延展性。如上圖,提供 topic 以及 topic partitions,即話題與話題分區的機制。每個用戶有不同的 topic,每個 topic 可以有多個分區,每個分區可被裝載在不同的機器上,當用戶提高規模之后,Kafka 只需要簡單地增加機器和 topic partitions 數量,或者采用 ROM balance 的方式到不同機器上,即可達到線性延展方式。
以上是 Kafka 最簡單的核心思想,接下來我將介紹 Kafka Streams 作為 Kafka 客戶端如何利用以上核心思想來設計流處理的平臺。數據流其實就是有序的記錄或消息,每個消息是一個 Key 加一個 Value,并且 record 與 Kafka 自身 massage 具有一一對應關系。

用戶所提供的業務上的計算模型,其實可用拓補結構進行表達。如上圖,圖的左邊。用戶首先進行定義數據流,然后對數據流進行計算,得到新的數據流,最終將數據流寫回到 Kafka 內。每當用戶進行定義的時候,每一步都會變成拓撲結構里面的一個點,每個點通過流進行計算,變成新的流來進行新的連接,最終在 Kafka 內部形成拓撲結構。用戶并不需要在意該拓補結構,只需明白定義流、計算流、得到新的流,寫回 Kafka。
連接每一個不同的運算單元就是一個 Stream,即 record stream,每一個 Stream 都在源源不斷地實時產生 record,每一個 record 是一個 key 加一個 value。利用 Stream Processor 連接 Stream,每個用戶定義的流的一個計算單位對應著一個 Stream Processor。
當用戶定義每一步計算的時候,就是定義每個拓撲結構里面的每個點,最終把整個拓補結構定義完整到 Kafka Stream 來運行。計算單元其實可分成兩個特殊的單元,一個叫做元的計算單元,只有輸出流,沒有輸入流,它們唯一的認同就是從 Kafka 讀取數據形成數據流,傳遞給下方其他數據處理。而 Stream Processor 底端的數據流,沒有輸出流,只有輸入流,它們的功能是把所有輸入流寫回到 Kafka。Kafka 的運行操作簡單,源數據從 Kafka log 讀取消息變成數據流,每個消息貫穿整個拓撲結構,最終從 Stream Processor 寫回到 Kafka。以上為 Kafka Stream 運行情況。
用戶進行并行發布進程、應用或者多個計算的操作其實也非常簡單。Kafka 是一個庫,當你用 Kafka 庫寫成應用,當 record 寫入多臺機器時,Kafka Stream 庫本身就會自動調動 partitions 方式,假設你有兩臺機器,每臺機器上都運行了 Kafka Streams,當它同時進行運行時,不同的 streams application instance 就會從不同的 Kafka partitions 內讀取數據來達到并行任務的分發與執行,任務之間沒有任何的數據重疊,當你需要更多線性地增長任務時,你只需要在不同的機器上運行同樣的 record,所有的 instance 將會自動進行 rebalance,把新的 application 寫入,然后獲取到延展。
很多人看到不同的計算方式的時候會發現,有的計算方式,比如說 fliter、map,沒有“計算狀態”需要保存,一個數據進來計算、一個數據出去。但是有的計算,比如說 join、aggregate,就需要動態維護一個“計算狀態”,每一次新的信息或者日志進來的時候, Stream 就要進行更新甚至進行讀取。后者被稱為 Stateful Processing,前者為 Stateless Processing。
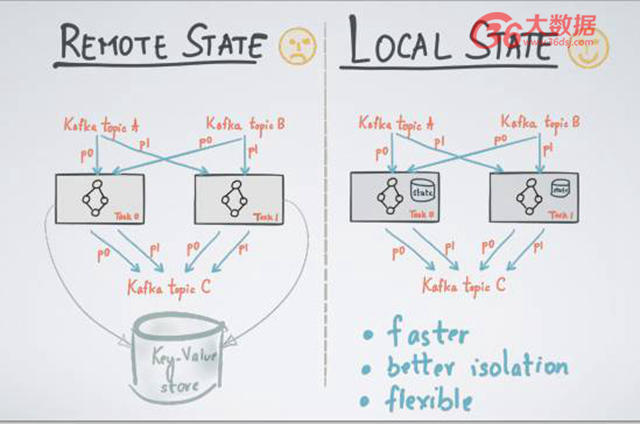
那么如何進行管理流處理的 states 呢?有兩個通用的方式,一個方式是 remote State,利用遠程的數據庫或者遠程的 key value store 存儲所有流處理的 states,每一次計算的時候,發送一個遠程請求來讀取 states。遠程請求的缺點在于需要進行遠程的請求和應答。因為 states 存在于 Remove State 上,states 之間可能會有 overlation,不能很好做到 accesstion. 比如我是團隊 A,只負責 sell,另外一個是團隊 B,只負責 ajustment, 兩個不同的流有著不同的 job,但是 state 存在一起,所以兩者會相互影響;
另外一個方式是 Local State,意味著所有的 state 和所有的處理單元是并發在一起的,每個單元上存著 state。在 Kafka Stream 里面,每個計算單元之間不需要有任何交互,state 之間亦如此。我們只要把 state 存到 Local 計算單元上就足矣。***,可以保證 better isolation,它們之間沒有任何的 access;第二,local state 可以做到更好的時效性,不需要遠程讀寫。

如上圖,在 Kafka 內有 aggregateByKey(…)語句,類似于 Stateful Processing。當用戶定義 Stateful Processing 的時候,在 Kafka Stream 庫內部就會自動生成 State Strom,且與 aggregate opprate 進行連接,只有該 opprate 能夠對該 State Strom 進行讀寫,因為每個 opprate 有自己獨有的 State Strom,可達到 State Strom 完全 Local 化。
當我們有多個并發流處理任務的時候,每個計算單元除了有一個自己的拓撲結構進行計算之外,也有一份 State Store。每個 State Strom 之間是存儲完全不相干的流處理信息和數據。

接下來討論的是 Kafka Streams 里面另一個重要概念,流與數據庫表的關系?正如大家所看見的,在 Kafka Streams 內部有兩種流—— KStream 與 Ktable,那么什么叫做 KStream?什么叫做 Ktable 呢?在開發 Kafka Streams 時的一個核心出發點是流和它所對應的表或者數據庫的 State 彼此之間具有一一影射關系。為什么一一影射呢?
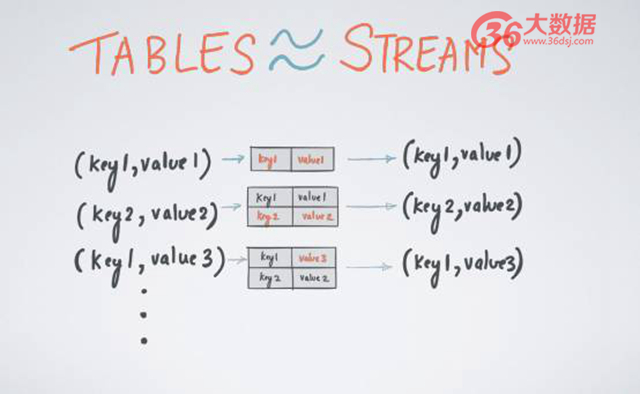
舉個例子,假設你有一個上圖的數據流,該數據流代表著某張表,即變量的日志或者更新日志。更新日志內含有 Key 和 Valve,比如第三條的更新日志(key1,value3)其實正在更新第 1 日志(key1,value1)的新信息,換句話說,原本 key1 所對應的是 value1,但是在這一時刻被改成對應 value3,如果我們重復更新該日志,我們能夠得到什么呢?我們可以得到該表在任意時間段內的一個實時的可視化圖。
同理,如果我們只有這樣一個表,并且正在不斷更新這個表,只要在每次更新時保留該日志,就能夠從表反推回該更新日志的數據流所應的所有內容,這就是流和表或者流和狀態之間的一一對應關系。總而言之,只要你有一個日志更新流,即可重構回你表狀態在任意時間內的 value;如果你有一個表,也可以通過表的更新來找到該表所對應的流。這就是我所說的 A Stream is a changelog of a table ;A table is a materialized view at tiome of a stream. 流和表具有對應關系。
這促使我們定義兩種不同的——KStream 和 KTable。KStream 是很普通的數據流,在數據流之間不存在任何因果關系和邏輯關系,可以被認為是 append only Stream。Typo 是更新日志流,每個日志里面相同的 key 所對應的就是對表的更新。那么為什么要定義這兩種不同的數據流呢?我舉個例子。
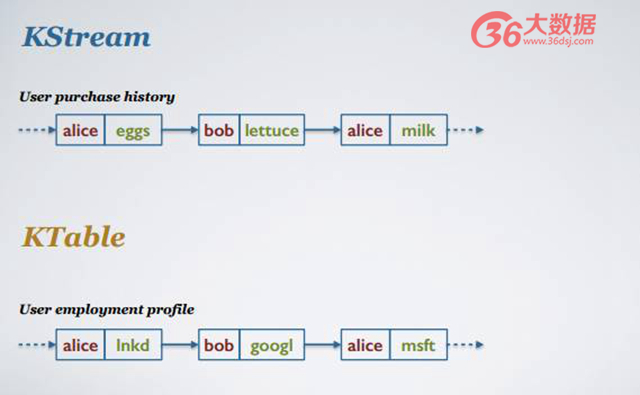
如上圖,用戶購買歷史記錄。比如 Alice 曾經買過雞蛋和牛奶,雞蛋和牛奶這兩者之間不存在任何因果關系,Alice 買過牛奶只是在 Alice 買過雞蛋上很簡單的增量。用戶雇傭狀態的更新日志,比如 Alice 曾經在 LinkedIn 工作,之后信息被更新到 Alice 在微軟工作,現在 Alice 在微軟工作覆蓋了之前的工作信息。
如果以當前的時間狀態進行解讀這兩個流,***個流顯示的信息為 Alice 曾經買過雞蛋,第二個流信息顯示為 Alice 在 LinkedIn 工作。如果將時間往前推,查看更新的數據流信息可以發現,***個 KStream 顯示 Alice 買了雞蛋又買了牛奶;但是在第二種情況下,Alice 并不是同時在 LinkedIn 和微軟工作,而是 Alice 已經在微軟工作,不在 LinkedIn 工作了。
為什么兩種不同的流有兩種定義呢?因為當你做相同操作的時候,比方說簡單做一個合計操作,不同的流得出的結果是不一樣的。在上者,如果我們將時間往前推,可得出 Alice 的合計結果是 2+3;但是在下面,如果對其進行 KTable 的 aggregate,顯示 Alice 的結果是將其原本數值 2 變成 3,而不是 +3 的關系。
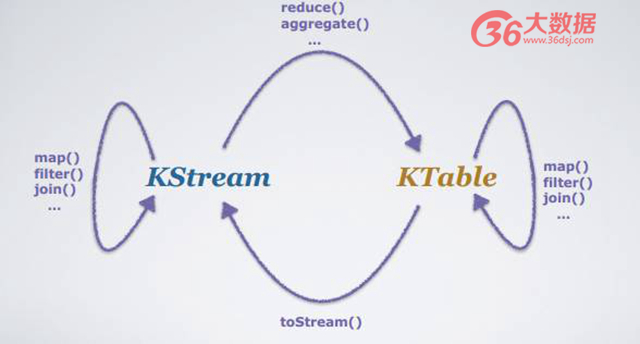
在 Kafka Stream 的 DSL 里面有多種不同的 aggregate,reduce 操作等, 不同的數據流可能將 KStream 變成 KTable,也可能把 KTable 變回 KStream,在用戶定義如下不同的 operation 的時候,在后臺不同狀態的流可采用不同計算方式、計算模型。
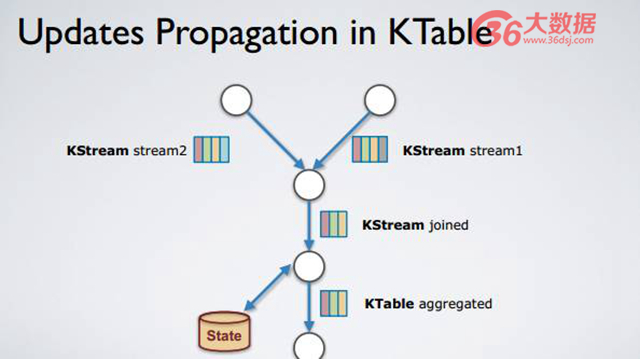
如上圖,KTable。當一條新消息進來時該如何進行拓撲計算呢?舉個例子,在該拓撲結構內,Stream2 出現了一個新的 record,即紅顏色標記,該標記與***條 record 顏色相近,因為它們是同個 key,不同 value。Stream2 和 Stream1 進行 join 操作成為一個新的 record,該新 record 會被放入到 KStream joined 里面,然后 KStream joined 進行 aggregate 操作,而 aggregate 操作得到的結果是 state 被更新,新 record 被 append 到 aggregate 流內,但是 append 操作將之前的紅顏色 record 復寫了,換句話說,因為有了該新 record 的存在,之前紅顏色的 record 由于被復寫已經不重要了。
Kafka Stream 運維
如果我們有一個 fault,那么我們如何在 Kafka Stream 上做 fault tolerance?
正如上文所提及的,Tables 和 Stream 之間存在一一影射關系,Kafka Stream 有效地利用了該特性。舉個例子,有個 Kafka Stream 的應用業務,該業務有三個并發 task,每個 task 有自己的 local state,每當 State 進行更新時,Kafka Stream 就會自動將更新消息寫到更新日志內,更新日志也自動生成。每更新一個狀態時,消息日志就被更新該日志上。
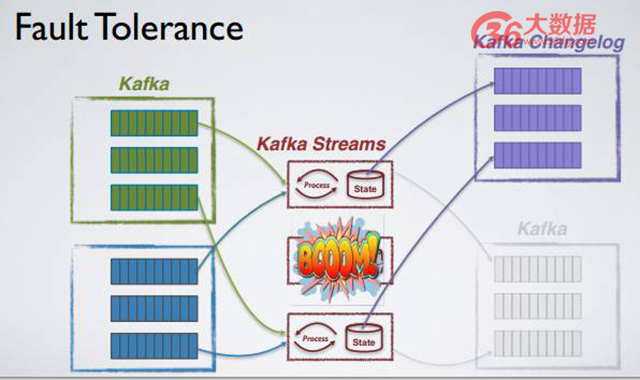
比如過了一段時間,中間的 task 壞掉了,那么 Kafka Stream 會做什么呢?首先它會檢測異常,自動地在已有的 instance 上重新啟動原本壞掉的 task,重新構建 State,那么 State 怎么 build 呢?通過更新 changelog,直到 restore 整個原本正在進行的狀態的 restoration,只有新狀態被 restore 完整之后才能繼續 task 同步計算。
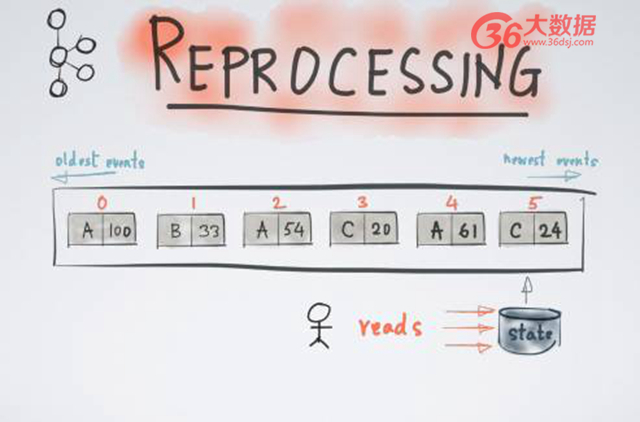
消息回溯也是類似的原理。比方說,某應用已被運行了很多年,發現 stream 流處理計算里面存在 Bug,我們不得不將已計算的結果舍棄,回溯到一個更早的歷史時間重新進行計算,即計算回溯。Reprocessing 在 Kafka Stream 也是一種簡單的方式,當我們達到某一個位移,比如位移 5,需要進行消息回溯時,用戶可以簡單地起一個新的狀態 -New State,該 State 完全沒有任何內容,然后從最早的時間開始重新進行計算,直到計算到趕上現有 task 時候。只需要 switch over 就可以完成消息回溯,且該整個消息回溯過程不需要關閉整個流處理任務。于是很多人便問,那么 Kafka Stream 能不能支持 Streaming processing 呢?
舉個例子,我不希望 Kafka Stream 一直在運行,希望它可以每 6 個小時 run 一次,并且每 run 一次可將當前所有已累計的 Kafka massage 全部處理掉。這個操作也很簡單,從 outsite A 開始,一直位移到 B 結束或者到 C 結束,表示已停止整個應用;6 個小時之后當它重啟的時候,再從新的位移開始進行下一段的位移,這是批處理計算結果,即從一個 outsite 到另外一個 outsite,緊接著是另外一個 outsite…Kafka Stream 通過位移的控制和管理進行批處理結果,而不需要運行整個 Kafka Stream。
時間的管理
時間管理是流處理上非常重要的觀念,同時也是區別于流處理和批量式處理非常重要的概念。很多人都已熟悉 Event Time 和 Processing Time 的區別,Event Time 是每個日志、消息、狀態發生的時候所發生的時間,而 Processing Time 是日志被計算和處理的時候所發生的時間。這兩者可能并不是完全融合的,可能存在位移,這便是所謂的時間延遲。

如上圖,以《星球大戰》故事時間和拍攝時間為例。《星球大戰》有七步曲,Processing Time 是電影真正拍攝時間,是在現實生活中的時間——1999 年到 2015 年;但是拍攝時間和星球大戰所發生時間并不一一對應,存在延遲。對其做流處理時候可以發現,類似 out of order 的現象很常見,比如因為數據量太大而導致數據發生延遲,或者說數據處理發生了延遲等,都會發生延時情況。
那么 Kafka Stream 怎么解決該問題呢? Kafka Stream 允許給每個日志定義時間戳,該時間戳可以是當前系統時間,也可以是提取時間戳,也可以從當前 record 被生成的時候所提取的時間戳,這些即被定義成 Event Time。類似的,如果 record 是一個 Jason format,將其時間戳提取出來也可被定義成 Event Time。
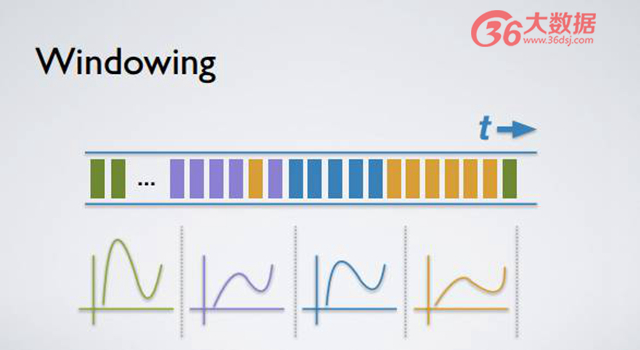
有如此時間戳,我們可以基于該時間戳進行各式計算,比方說 Windowing 的計算。舉個例子,每隔 5 分鐘計算一個平均值、總和或者合計,每一個 Windowing 正如上圖顏色所示,不同顏色代表不同的時間戳和不同的 Windowing。當你收到一個 record,而該 record 時間戳指向非常未來的時間,你便得到一個非常未來的日志。Kafka 不會直接更新當前的 Windowing,而是會生成該時間戳所對應的 Windowing 更新 aggregate。
同理,倘若你繼續計算,你會發現有個古老日志的時間戳指向很早以前的 Windowing。Kafka Stream 可以通過更新原本的 aggregate 來達到這樣延時結果。用戶在現在時間進行如下定義,比方說定義 Window aggregation,每一個 Windowing 是 5 分鐘,但是我希望每個 Windowing 可保持整整一天時間,只要該 Windowing 在當前 24 小時之內依然存在即可做到。
寫在***
上文分享了較多內容,從 ordering 到狀態、一直到 partitioning & scalability ,但其實最重要的是所有的這些都是由 Kafka Stream 庫自動完成的。我們希望用戶不要受到以上任何問題的影響,只需定義自己的業務,所有如上的問題都由 Kafka Stream 解決,盡管它只是一個庫,但依然有足夠強大的能力去處理所有事物。
我們在 Kafka 0.10 里面公布 Kafka Stream 之后,把 Streams 延展到 Java 以外的語言,比如支持 python,或者像 SQL 一樣的更高階編程模型來讓用戶更方便地定義自己的流處理應用。在 7 月份的 release 里面,我們也會增加正好一次(exactly-once)計算方式的 aggregate。
很多人可能會好奇,Kafka Stream 很好,可是我的數據原本不在 Kafka 內,而 Kafka Stream 只能從 Kafka 內部獲取,如何將數據導入 Kafka 呢? 答案是 Kafka Connect,一個簡單的數據導入導出框架。 時至去年年底,Kafka Connect 已經有 40 個不同規模的 Connect,包括從 JDBC 到 HDFS、一直到 MYSQL,以及所有可以想到的第三方系統,用戶可以簡單地把數據從第三方系統導入和導出 Kafka。
總之,回到本源,Kafka 到底是什么? Kafka 是一個中央式的流處理平臺,他們支持消息的發布、消費、傳輸和存儲,以及消息的計算和消息的處理。
以上是本文分享的全部內容。關注兩個 Take-aways,***個 Take-away,流處理只是不同的計算模型,它不會只給你近似的結果,只能用來做增量的結果;第二個 Take- away,因為 Kafka Stream 的存在使得 Stream processing 存在更加簡單。