













語音識別的下一攀登高峰是“人文境界”?
自從深度學習大熱,廣泛應用于語音識別以來,字幕中的單詞錯誤率急劇下降。盡管如此,語音識別并沒有達到人文水平,它仍會出現一些故障。承認這些然后采取措施來解決這些問題對于語音識別的進步至關重要。這是唯一的從可以識別一些人的ASR到識別任何時間任何人的ASR的方式。
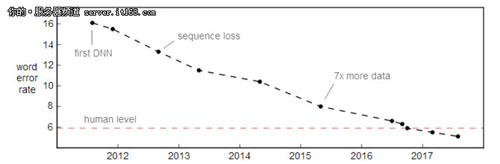
在近期的Switchboard語音識別基準測試中,單詞的錯誤率得到改進。Switchboard集其實是在2000年收集的,它是由兩個隨機的以英語為母語的人之間的40個電話對話組成。
可以說目前我們已經在會話式語音識別上達到“人類”水平,但僅僅只是在Switchboard方面。這個結果就像是在一個陽光燦爛的日子里的某城市中,只有一個人駕駛著自動駕駛汽車進行測試。最近在這方面取得的進步令人驚訝,但是,關于達到“人類”水平的說法還是太過寬泛,以下是一些仍需要改進的幾個方面。
口音和噪音
語音識別中最明顯的缺陷之一是處理口音和背景噪聲。最直接的原因是,大多數訓練數據是由具有高信噪比的美國口音的英語組成。
但是,更多的訓練數據可能并不能自行解決這個問題。現實生活中,也有許多方言和口音。因此,用標注數據去應對所有情況是不可行的。構建一個高質量的語音識別器,轉錄了5000多小時的音頻難道只是為了以英語為母語的人?

將轉錄器與百度的深度語音識別系統Deep Speech 2 比較后發現在轉錄非美國口音時情況更糟糕。可能是由于美國人在轉錄時的偏見。
在背景有噪音的情況下,移動汽車的信噪比低至5DB并不罕見。這種環境下,人們也能夠很好的聽清彼此。另一方面,語音識別器在噪聲方面的降解速度更快。在上圖中,可以清楚看到人力和模型誤差率之間的差距,從低信噪比急劇上升到高信噪比。
語義錯誤
在語音識別系統中,單詞錯誤率通常不是實際的目標,語義錯誤率才是我們關注的重點。因為,語義正確與否關系到對他人話語的理解程度。
一個語義錯誤的例子是,如果有人說“讓我們在星期二見面”,但是語音識別器識別為“我們今天就見面”。這是出現了單詞錯誤卻沒有語義錯誤,當然,情況也可能反過來。
使用錯誤率作為代理服務時,必須謹慎。先舉一個最壞的例子來說明原因。一個5%的回答可能相當于每20個單詞就漏掉一個。那么,如果一句話只有20 個單詞的話,那么這句話的錯誤率可能就是100%。
當將模型與人類進行比較時,檢查錯誤的本質是非常重要的,而不僅僅是將答案視為一個確定的數字。就經驗來看,人類的轉錄要比語音識別器產生更少的語義錯誤。
微軟的研究人員最近比較了人類轉錄及其人類語言識別器所犯的錯誤,發現的一個差異在于,該模型混淆了“uh”和“uh huh”。這兩個詞有完全不同的語義。模型和人力都犯了很多相同類型的錯誤。
單通道,多個揚聲器
由于每個揚聲器都使用單獨的麥克風進行錄音,所以 Switchboard會話任務也更容易。同一音頻流中,多個揚聲器沒有重疊。另一方面,人類可以很好的理解多個揚聲器有時在同一時間進行的通話的內容。
一個好的會話語音識別器必須能夠根據誰在說話(diarisation)來分割音頻。它也應該能夠使用重疊的揚聲器(音源分離)來理解音頻。這是可行的,不需要麥克風每一個揚聲器,以便會話語音可以在任意位置都能工作。
域的變化
口音和背景噪聲是語音識別器的兩個重要的因素,這里還有一些:
- 混響聲音環境變化
- 來自硬件的artefacts
- 用于音頻和壓縮的artefacts
- 采樣率
- 說話人的年齡
大多數人甚至不會注意到mp3和普通wav文件之間的區別。在聲明人力性能之前,語音識別器也需要對這些變化的來源進行強大的支持。
上下文
你會發現,像“開關板”這樣的單詞的錯誤率實際上會很高,如果你和一個朋友交談,他們誤解了每20個字中的1個,那么你就會很難溝通。
其中的一個原因是評估是在上下文中完成的。在現實生活中,我們會使用許多其他線索、結合語境來幫助我們了解某人在說什么。但語音識別器不能識別這些:
- 對話的歷史和討論的話題
- 關于我們正在說話的人的視覺暗示包括表情和唇部運動
- 說話的人的背景
目前,Android的語音識別器已經掌握你的聯系人列表,因此它可以識別你的朋友的姓名。地圖產品中的語音搜索可以使用地理定位來縮小你可能想要瀏覽的感興趣的地點。當使用這種類型的信號時,ASR系統的精度肯定會提高。
部署
當要部署一個新的算法的時候,可以考慮延遲和算法,因為增加計算的算法往往會增加延遲,但為了簡單起見,接下來將分別討論。
延遲:完成轉錄之后,低延遲是十分常見的,它會顯著影響用戶的體驗。因此,幾十毫秒內的延遲要求對于ASR系統來說并不少見。雖然這可能聽起來會有些極端,但這通常是一系列昂貴計算的***步,所以,必須謹慎。

將未來信息有效地納入語音識別的好方法到目前為止仍然是一個開放的問題,有待討論。
計算:記錄話語所需的計算能力是一種經濟約束。我們必須考慮到對語音識別器的每一個精度的改進。如果改進不符合經濟閾值,則無法部署。
一個從未被部署的持續改進的經典例子是集成。1%或2%的誤差降低可能會達到2-8倍的計算增長,現代的RNN語言模型通常也屬于這一類。
實際上,并不建議在很大的計算成本上提高準確性,已經有“先慢但準確,然后加速”的工作模式。但關鍵在于,直到改進足夠快,它仍是不可用的。
未來五年
語音識別中還存在許多開放性和挑戰性的問題。這些包括:
·擴大新領域,口音和遠場,低信噪比
·將更多的上下文融入識別過程
·Diarisation和源分離
·超低延遲和高效推理
期待在今后的五年在這些方面都能取得進展













