













當前深度神經(jīng)網(wǎng)絡模型壓縮和加速方法速覽
大型神經(jīng)網(wǎng)絡具有大量的層級與結(jié)點,因此考慮如何減少它們所需要的內(nèi)存與計算量就顯得極為重要,特別是對于在線學習和增量學習等實時應用。此外,近來智能可穿戴設備的流行也為研究員提供了在資源(內(nèi)存、CPU、能耗和帶寬等)有限的便攜式設備上部署深度學習應用提供了機會。高效的深度學習方法可以顯著地影響分布式系統(tǒng)、嵌入式設備和用于人工智能的 FPGA 等。典型的例子是 ResNet-50[5],它有 50 層卷積網(wǎng)絡、超過 95MB 的儲存需求和計算每一張圖片所需要的浮點數(shù)乘法時間。如果剪枝一些冗余的權(quán)重后,其大概能節(jié)約 75% 的參數(shù)和 50% 的計算時間。對于只有兆字節(jié)資源的手機和 FPGA 等設備,如何使用這些方法壓縮模型就很重要了。
實現(xiàn)這個目標需要聯(lián)合多個學科以尋找解決方案,包括但不限于機器學習、最優(yōu)化、計算機架構(gòu)、數(shù)據(jù)壓縮、索引和硬件設計等。在本論文中,我們回顧了在壓縮和加速深度神經(jīng)網(wǎng)絡方面的工作,它們廣泛受到了深度學習社區(qū)的關注,并且近年來已經(jīng)實現(xiàn)了很大的進展。
我們將這些方法分為四個類別:參數(shù)修剪和共享、低秩分解、遷移/壓縮卷積濾波器和知識精煉等。基于參數(shù)修剪(parameter pruning)和共享的方法關注于探索模型參數(shù)中冗余的部分,并嘗試去除冗余和不重要的參數(shù)。基于低秩分解(Low-rank factorization)技術的方法使用矩陣/張量分解以估計深層 CNN 中最具信息量的參數(shù)。基于遷移/壓縮卷積濾波器(transferred/compact convolutional filters)的方法設計了特殊結(jié)構(gòu)的卷積濾波器以減少存儲和計算的復雜度。而知識精煉(knowledge distillation)則學習了一個精煉模型,即訓練一個更加緊湊的神經(jīng)網(wǎng)絡以再現(xiàn)大型網(wǎng)絡的輸出結(jié)果。
在表 1 中,我們簡單地總結(jié)了這四種方法。通常參數(shù)修剪和分享、低秩分解和知識精煉方法可以通過全連接層和卷積層用于 DNN,它們能實現(xiàn)有競爭力的性能。另外,使用遷移/壓縮濾波器的方法只適用于全卷積神經(jīng)網(wǎng)絡。低秩分解和遷移/壓縮濾波器的方法提供了一種端到端的流程,并且它們很容易直接在 CPU/GPU 環(huán)境中實現(xiàn)。而參數(shù)修剪和共享使用了不同的方法,如向量量化、二進制編碼和系數(shù)約束以執(zhí)行這些任務,通常他們需要花一些處理步驟才能達到最終的目標。
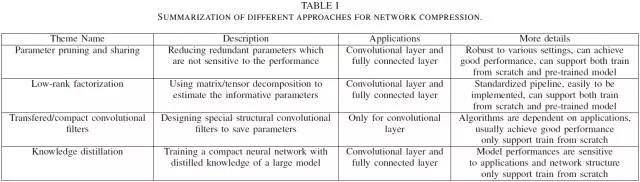
表 1. 不同的模型壓縮方法。
至于訓練協(xié)議,基于參數(shù)修剪/共享、低秩分解的模型可以從預訓練的模型中抽取或者從頭開始訓練,這些訓練比較靈活高效。而遷移/壓縮濾波器和知識精煉模型只支持從頭開始訓練。這些方法獨立設計,互為補充。例如,遷移層和參數(shù)修剪/共享可以一起使用,模型量化/二進制化(binarization)可以和低秩分解一起使用,以實現(xiàn)進一步提速。論文作者詳細介紹了每一類方法,包括特性、優(yōu)勢和缺陷等。
參數(shù)修剪和共享
根據(jù)減少冗余(信息冗余或參數(shù)空間冗余)的方式,這些技術可以進一步分為三類:模型量化和二進制化、參數(shù)共享和結(jié)構(gòu)化矩陣(structural matrix)。
A. 量化和二進制化
網(wǎng)絡量化通過減少表示每個權(quán)重所需的比特數(shù)來壓縮原始網(wǎng)絡。Gong et al. [6] 和 Wu et al. [7] 對參數(shù)值使用 K 均值標量量化。Vanhoucke et al. [8] 展示了 8 比特參數(shù)量化可以在準確率損失極小的同時實現(xiàn)大幅加速。[9] 中的研究在基于隨機修約(stochastic rounding)的 CNN 訓練中使用 16 比特定點表示法(fixed-point representation),顯著降低內(nèi)存和浮點運算,同時分類準確率幾乎沒有受到損失。
[10] 提出的方法是首先修剪不重要的連接,重新訓練稀疏連接的網(wǎng)絡。然后使用權(quán)重共享量化連接的權(quán)重,再對量化后的權(quán)重和碼本(codebook)使用霍夫曼編碼,以進一步降低壓縮率。如圖 1 所示,該方法首先通過正常的網(wǎng)絡訓練來學習連接,然后再修剪權(quán)重較小的連接,最后重新訓練網(wǎng)絡來學習剩余稀疏連接的最終權(quán)重。
缺陷:此類二元網(wǎng)絡的準確率在處理大型 CNN 網(wǎng)絡如 GoogleNet 時會大大降低。另一個缺陷是現(xiàn)有的二進制化方法都基于簡單的矩陣近似,忽視了二進制化對準確率損失的影響。
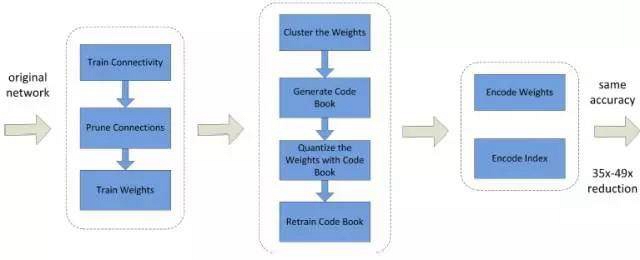
圖 1. [10] 中提到的三階段壓縮方法:修剪、量化(quantization)和霍夫曼編碼。修剪減少了需要編碼的權(quán)重數(shù)量,量化和霍夫曼編碼減少了用于對每個權(quán)重編碼的比特數(shù)。稀疏表示的元數(shù)據(jù)包含壓縮率。壓縮機制不會帶來任何準確率損失。
B. 剪枝和共享
網(wǎng)絡剪枝和共享已經(jīng)被用于降低網(wǎng)絡復雜度和解決過擬合問題。有一種早期應用的剪枝方法稱為偏差權(quán)重衰減(Biased Weight Decay),其中最優(yōu)腦損傷(Optimal Brain Damage)和最優(yōu)腦手術(Optimal Brain Surgeon)方法基于損失函數(shù)的 Hessian 矩陣減少連接的數(shù)量,他們的研究表明這種剪枝方法的精確度比基于重要性的剪枝方法(比如 weight dDecay 方法)更高。
缺陷:剪枝和共享方法存在一些潛在的問題。首先,若使用了 L1 或 L2 正則化,則剪枝方法需要更多的迭代次數(shù)才能收斂,此外,所有的剪枝方法都需要手動設置層的敏感度,即需要精調(diào)超參數(shù),在某些應用中會顯得很冗長繁重。
C. 設計結(jié)構(gòu)化矩陣
如果一個 m x n 階矩陣只需要少于 m×n 個參數(shù)來描述,就是一個結(jié)構(gòu)化矩陣(structured matrix)。通常這樣的結(jié)構(gòu)不僅能減少內(nèi)存消耗,還能通過快速的矩陣-向量乘法和梯度計算顯著加快推理和訓練的速度。
低秩分解和稀疏性
一個典型的 CNN 卷積核是一個 4D 張量,需要注意的是這些張量中可能存在大量的冗余。而基于張量分解的思想也許是減少冗余的很有潛力的方法。而全連接層也可以當成一個 2D 矩陣,低秩分解同樣可行。
所有近似過程都是一層接著一層做的,在一個層經(jīng)過低秩濾波器近似之后,該層的參數(shù)就被固定了,而之前的層已經(jīng)用一種重構(gòu)誤差標準(reconstruction error criterion)微調(diào)過。這是壓縮 2D 卷積層的典型低秩方法,如圖 2 所示。
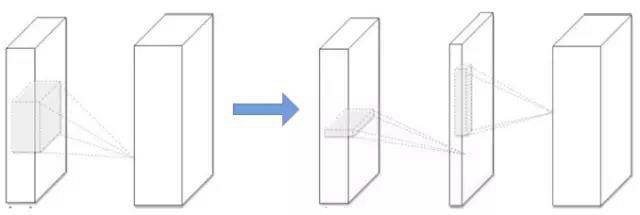
圖 2. CNN 模型壓縮的低秩近似(Low-rank approximation)。左:原始卷積層。右:使用秩 K 進行低秩約束的卷積層。
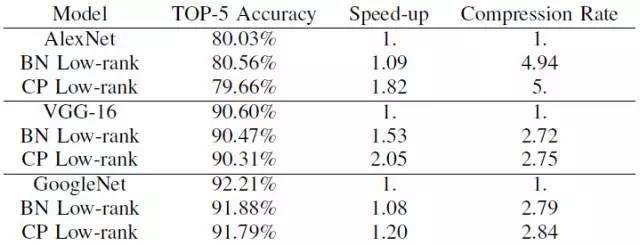
表 2. 低秩模型及其基線模型在 ILSVRC-2012 數(shù)據(jù)集上的性能對比。
缺陷:低秩方法很適合模型壓縮和加速,該方法補充了深度學習的近期發(fā)展,如 dropout、修正單元(rectified unit)和 maxout。但是,低秩方法的實現(xiàn)并不容易,因為它涉及計算成本高昂的分解操作。另一個問題是目前的方法逐層執(zhí)行低秩近似,無法執(zhí)行非常重要的全局參數(shù)壓縮,因為不同的層具備不同的信息。最后,分解需要大量的重新訓練來達到收斂。
遷移/壓縮卷積濾波器
使用遷移卷積層對 CNN 模型進行壓縮受到 [42] 中研究的啟發(fā),該論文介紹了等變?nèi)赫?equivariant group theory)。使 x 作為輸入,Φ(·) 作為網(wǎng)絡或?qū)樱琓 (·) 作為變換矩陣。則等變概念可以定義為:
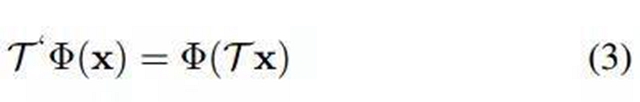
即使用變換矩陣 T (·) 轉(zhuǎn)換輸入 x,然后將其傳送至網(wǎng)絡或?qū)?Phi;(·),其結(jié)果和先將 x 映射到網(wǎng)絡再變換映射后的表征結(jié)果一致。
根據(jù)該理論,將變換矩陣應用到層或濾波器Φ(·) 來對整個網(wǎng)絡模型進行壓縮是合理的。
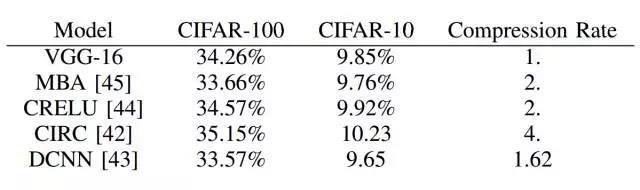
表 3. 基于遷移卷積濾波器的不同方法在 CIFAR-10 和 CIFAR-100 數(shù)據(jù)集上的性能對比。
缺陷:將遷移信息應用到卷積濾波器的方法需要解決幾個問題。首先,這些方法的性能可與寬/平坦的架構(gòu)(如 VGGNet)相媲美,但是無法與較窄/特殊的架構(gòu)(如 GoogleNet、Residual Net)相比。其次,遷移假設有時過于強大以致于無法指導算法,使得在某些數(shù)據(jù)集上的結(jié)果不穩(wěn)定。
知識精煉
據(jù)我們所知,Caruana 等人 [49] 首先提出利用知識遷移(KT)來壓縮模型。他們通過集成強分類器標注的偽數(shù)據(jù)訓練了一個壓縮模型,并再現(xiàn)了原大型網(wǎng)絡的輸出結(jié)果。然而他們的工作僅限于淺層網(wǎng)絡。這個想法近來在 [50] 中擴展為知識精煉(Knowledge Distillation/KD),它可以將深度和寬度的網(wǎng)絡壓縮為淺層模型,該壓縮模型模仿了復雜模型所能實現(xiàn)的功能。KD 的基本思想是通過軟 softmax 學習教師輸出的類別分布而降大型教師模型(teacher model)的知識精煉為較小的模型。
[51] 中的工作引入了 KD 壓縮框架,即通過遵循學生-教師的范式減少深度網(wǎng)絡的訓練量,這種學生-教師的范式即通過軟化教師的輸出而懲罰學生。該框架將深層網(wǎng)絡(教師)的集成壓縮為相同深度的學生網(wǎng)絡。為了完成這一點,學生學要訓練以預測教師的輸出,即真實的分類標簽。盡管 KD 方法十分簡單,但它同樣在各種圖像分類任務中表現(xiàn)出期望的結(jié)果。
缺點:基于 KD 的方法能令更深的模型變得更加淺而顯著地降低計算成本。但是也有一些缺點,例如 KD 方法只能用于具有 Softmax 損失函數(shù)分類任務,這阻礙了其應用。另一個缺點是模型的假設有時太嚴格了,以至于其性能有時比不上其它方法。
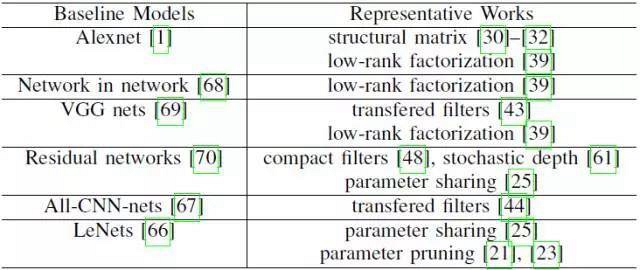
表 4. 模型壓縮不同的代表性研究中使用的基線模型。
討論與挑戰(zhàn)
深度模型的壓縮和加速技術還處在早期階段,目前還存在以下挑戰(zhàn):
- 大多數(shù)目前的頂尖方法都建立在設計完善的 CNN 模型的基礎上,這限制了改變配置的自由度(例如,網(wǎng)絡結(jié)構(gòu)和超參數(shù))。為了處理更加復雜的任務,還需要更加可靠的模型壓縮方法。
- 剪枝是一種壓縮和加速 CNN 的有效方式。目前大多數(shù)的剪枝技術都是以減少神經(jīng)元之間的連接設計的。另一方面,對通道進行剪枝可以直接減小特征映射的寬度并壓縮模型。這很有效,但也存在挑戰(zhàn),因為減少通道會顯著地改變下一層的輸入。確定這類問題的解決方式同樣很重要。
- 正如之前所提到的,結(jié)構(gòu)化矩陣和遷移卷積濾波器方法必須使模型具有人類先驗知識,這對模型的性能和穩(wěn)定性有顯著的影響。研究如何控制強加先驗知識的影響是很重要的。
- 知識精煉(knowledge distillation/KD)方法有很多益處比如不需要特定的硬件或?qū)崿F(xiàn)就能直接加速模型。開發(fā)基于 KD 的方法并探索如何提升性能仍然值得一試。
- 多種小型平臺(例如,移動設備、機器人、自動駕駛汽車)的硬件限制仍然是阻礙深層 CNN 擴展的主要問題。如何全面利用有限的可用計算資源以及如何為這些平臺設計特定的壓縮方法仍然是個挑戰(zhàn)。























