無監(jiān)督神經(jīng)機(jī)器翻譯:僅需使用單語語料庫
督神經(jīng)機(jī)器翻譯:僅需使用單語語料庫")
摘要:近期神經(jīng)機(jī)器翻譯(NMT)在標(biāo)準(zhǔn)基準(zhǔn)上取得了很大成功,但是缺乏大型平行語料庫對(duì)很多語言對(duì)是非常大的問題。有幾個(gè)建議可以緩解該問題,比如三角剖分(triangulation)和半監(jiān)督學(xué)習(xí)技術(shù),但它們?nèi)匀恍枰獜?qiáng)大的跨語言信號(hào)(cross-lingual signal)。本論文中,我們完全未使用平行數(shù)據(jù),提出了用完全無監(jiān)督的方式訓(xùn)練 NMT 系統(tǒng)的新方法,該方法只需使用單語語料庫。我們的模型在近期關(guān)于無監(jiān)督嵌入映射的研究基礎(chǔ)上構(gòu)建,包含經(jīng)過少許修改的注意力編碼器-解碼器模型(attentional encoder-decoder model),該模型使用去噪和回譯(backtranslation)結(jié)合的方式在單語語料庫上進(jìn)行訓(xùn)練。盡管該方法很簡單,但我們的系統(tǒng)在 WMT 2014 法語-英語和德語-英語翻譯中分別取得了 15.56 和 10.21 的 BLEU 得分。該模型還可以使用小型平行語料庫,使用 10 萬平行句對(duì)時(shí),該模型分別取得了 21.81 和 15.24 的 BLEU 得分。我們的方法在無監(jiān)督 NMT 方面是一個(gè)突破,為未來的研究帶來了新的機(jī)會(huì)。
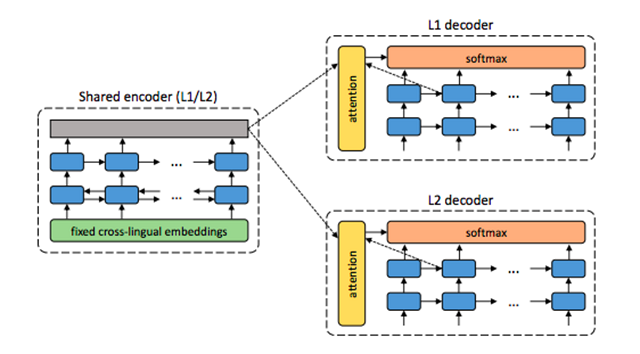
圖 1:系統(tǒng)架構(gòu)。
對(duì)語言 L1 中的每個(gè)句子,該系統(tǒng)都通過兩個(gè)步驟進(jìn)行訓(xùn)練:去噪——利用共享編碼器優(yōu)化對(duì)句子帶噪聲版本進(jìn)行編碼和使用 L1 解碼器重構(gòu)句子的概率;回譯——在推斷模式(inference mode)下翻譯該句子(使用共享編碼器編碼該句子,使用 L2 解碼器進(jìn)行解碼),然后利用共享編碼器優(yōu)化對(duì)譯文句子進(jìn)行編碼和使用 L1 解碼器恢復(fù)源句子的概率。交替執(zhí)行這兩個(gè)步驟對(duì) L1 和 L2 進(jìn)行訓(xùn)練,對(duì) L2 的訓(xùn)練步驟和 L1 類似。
系統(tǒng)架構(gòu)
如圖 1 所示,我們提出的系統(tǒng)使用比較標(biāo)準(zhǔn)的帶有注意力機(jī)制的編碼器-解碼器架構(gòu)(Bahdanau et al., 2014)。具體來說,我們?cè)诰幋a器中使用一個(gè)雙層雙向 RNN,在解碼器中使用另一個(gè)雙層 RNN。所有 RNN 使用帶有 600 個(gè)隱藏單元的 GRU 單元(Cho et al., 2014),嵌入的維度設(shè)置為 300。關(guān)于注意力機(jī)制,我們使用 Luong et al. (2015b) 提出的全局注意力方法,該方法具備常規(guī)對(duì)齊功能。但是,我們的系統(tǒng)與標(biāo)準(zhǔn) NMT 在三個(gè)方面存在差異,而正是這些差異使得我們的系統(tǒng)能夠用無監(jiān)督的方式進(jìn)行訓(xùn)練:
1. 二元結(jié)構(gòu)(Dual structure)。NMT 系統(tǒng)通常為特定的翻譯方向搭建(如法語到英語或英語到法語),而我們利用機(jī)器翻譯的二元本質(zhì)(He et al., 2016; Firat et al., 2016a),同時(shí)進(jìn)行雙向翻譯(如法語 ↔ 英語)。
2. 共享編碼器。我們的系統(tǒng)僅使用一個(gè)編碼器,該編碼器由兩種語言共享。例如,法語和英語使用同一個(gè)編碼器。這一通用編碼器旨在產(chǎn)生輸入文本的語言獨(dú)立表征,然后每個(gè)解碼器將其轉(zhuǎn)換成對(duì)應(yīng)的語言。
3. 編碼器中的固定嵌入。大多數(shù) NMT 系統(tǒng)對(duì)嵌入進(jìn)行隨機(jī)初始化,然后在訓(xùn)練過程中對(duì)其進(jìn)行更新,而我們?cè)诰幋a器中使用預(yù)訓(xùn)練的跨語言嵌入,這些嵌入在訓(xùn)練過程中保持不變。通過這種方式,編碼器獲得語言獨(dú)立的詞級(jí)表征(word-level representation),編碼器只需學(xué)習(xí)如何合成詞級(jí)表征來構(gòu)建較大的詞組表征。如 Section 2.1 中所述,存在多種無監(jiān)督方法利用平行語料庫來訓(xùn)練跨語言嵌入,這在我們的場(chǎng)景中也是可行的。注意:即使嵌入是跨語言的,我們?nèi)匀恍枰褂妹糠N語言各自的詞匯。這樣,同時(shí)存在于英語和法語中的單詞 chair(法語意思是「肌肉」)在每種語言中都會(huì)獲得一個(gè)不同的向量,盡管兩個(gè)向量存在于共同的空間中。
無監(jiān)督訓(xùn)練
NMT 系統(tǒng)通常用平行語料庫進(jìn)行訓(xùn)練,由于我們只有單語語料庫,因此此類監(jiān)督式訓(xùn)練方法在我們的場(chǎng)景中行不通。但是,有了上文提到的架構(gòu),我們能夠使用以下兩種策略用無監(jiān)督的方式訓(xùn)練整個(gè)系統(tǒng):
1. 去噪
我們使用共享編碼器,利用機(jī)器翻譯的二元結(jié)構(gòu),因此本文提出的系統(tǒng)可以直接訓(xùn)練來重構(gòu)輸入。具體來說,整個(gè)系統(tǒng)可以進(jìn)行優(yōu)化,以使用共享編碼器對(duì)給定語言的輸入句子進(jìn)行編碼,然后使用該語言的解碼器重構(gòu)源句子。鑒于我們?cè)诠蚕砭幋a器中使用了預(yù)訓(xùn)練的跨語言嵌入,該編碼器學(xué)習(xí)將兩種語言的嵌入合稱為語言獨(dú)立的表征,每個(gè)解碼器應(yīng)該學(xué)習(xí)將這類表征分解成對(duì)應(yīng)的語言。在推斷階段,我們僅用目標(biāo)語言的解碼器替代源語言的解碼器,這樣系統(tǒng)就可以利用編碼器生成的語言獨(dú)立表征生成輸入文本的譯文。
但是,相應(yīng)的訓(xùn)練過程本質(zhì)上是一個(gè)瑣碎的復(fù)制任務(wù),這使得上述完美行為大打折扣。該任務(wù)的最佳解決方案不需要捕捉語言的內(nèi)部結(jié)構(gòu),盡管會(huì)有很多退化解只會(huì)盲目地復(fù)制輸入序列的所有元素。如果確實(shí)如此的話,該系統(tǒng)的最好情況也不過是在推斷階段進(jìn)行逐詞替換。
為了避免出現(xiàn)此類退化解,使編碼器真正學(xué)會(huì)將輸入詞語合成為語言獨(dú)立的表征,我們提出在輸入句子中引入隨機(jī)噪聲。這個(gè)想法旨在利用去噪自編碼器(denoising autoencoder)同樣的基本原則(Vincent et al., 2010),即系統(tǒng)被訓(xùn)練用于重構(gòu)帶噪聲輸入句子的原始版本(Hill et al., 2017)。為此,我們通過隨機(jī)互換相鄰詞語來改變輸入句子的詞序。具體而言,對(duì)于包含 N 個(gè)元素的序列,我們進(jìn)行 N/2 次此類隨機(jī)互換操作。這樣,該系統(tǒng)需要學(xué)習(xí)該語言的內(nèi)部結(jié)構(gòu)以恢復(fù)正確的詞序。同時(shí),我們不鼓勵(lì)系統(tǒng)過度依賴輸入句子的詞序,這樣我們可以更好地證明跨語言的實(shí)際詞序離散。
2. 回譯
盡管存在去噪策略,上述訓(xùn)練步驟仍然是一個(gè)復(fù)制任務(wù),其中包含一些合成的改動(dòng),最重要的是,每次改動(dòng)都只涉及一種語言,而非同時(shí)考慮翻譯的兩種語言。為了在真正的翻譯環(huán)境中訓(xùn)練新系統(tǒng),而不違反僅使用單語語料庫的限制,研究人員提出引入 Sennrich 等人 2016 年提出的回譯方法。具體說來,這種方法是針對(duì)給定語言的一個(gè)輸入句,系統(tǒng)使用貪心解碼在推斷模式下將其翻譯成另一種語言(即利用共享編碼器和另一種語言的解碼器)。利用這種方法,研究人員得到了一個(gè)偽平行語料庫,然后訓(xùn)練該系統(tǒng)根據(jù)譯文來預(yù)測(cè)原文。

表 1:幾種系統(tǒng)在 newstest2014 上的 BLEU 得分。無監(jiān)督系統(tǒng)利用 News Crawl 單語語料庫進(jìn)行訓(xùn)練,半監(jiān)督系統(tǒng)利用 News Crawl 單語語料庫和來自 News Commentary 平行語料庫的 10 萬句對(duì)進(jìn)行訓(xùn)練,監(jiān)督學(xué)習(xí)系統(tǒng)(作為對(duì)比)使用來自 WMT 2014 的平行語料庫進(jìn)行訓(xùn)練。其中,Wu et al. 2016 年提出的 GNMT 取得了單模型的最佳 BLEU 得分。
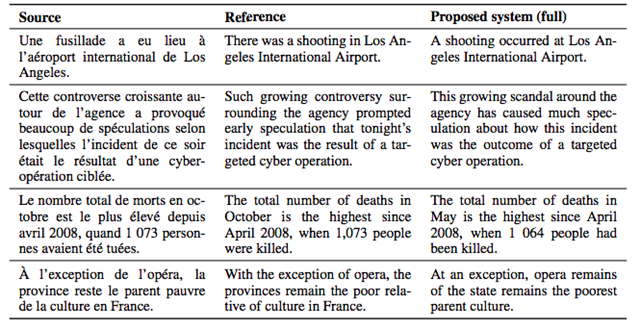
表 2:本文提出的系統(tǒng)使用 BPE 對(duì) newstest2014 中的部分句子進(jìn)行法語到英語的翻譯。
結(jié)論
在本論文中,研究人員提出用無監(jiān)督方法訓(xùn)練神經(jīng)機(jī)器翻譯系統(tǒng)的新方法。它建立在無監(jiān)督跨語言嵌入的現(xiàn)有工作上(Artetxe 等人,2017;Zhang 等人,2017),并將它們納入修改后的注意力編碼器-解碼器模型中。通過使用帶有固定跨語言嵌入的共享編碼器,結(jié)合去噪和回譯,我們實(shí)現(xiàn)了僅利用單語語料庫訓(xùn)練 NMT 系統(tǒng)。
實(shí)驗(yàn)顯示了新方法的有效性,在標(biāo)準(zhǔn) WMT 2014 法語-英語和德語-英語基準(zhǔn)測(cè)試中,新方法的 BLEU 得分顯著超過執(zhí)行逐詞替換的基線系統(tǒng)。我們也手動(dòng)分析并確定了新系統(tǒng)的表現(xiàn),結(jié)果表明它可以建模復(fù)雜的跨語言關(guān)系并生成高質(zhì)量的譯文。此外,實(shí)驗(yàn)還表明新方法結(jié)合一個(gè)小型平行語料庫可以進(jìn)一步提升系統(tǒng)性能,這對(duì)于訓(xùn)練數(shù)據(jù)不足的情況非常有用。
新的工作也為未來研究帶來了新的機(jī)會(huì),盡管該研究在無監(jiān)督 NMT 方面是一個(gè)突破,但仍有很大改進(jìn)空間。其中,在研究中用于比較的監(jiān)督 NMT 系統(tǒng)不是業(yè)內(nèi)最佳,這意味著新方法帶來的修正同樣也限制了其性能。因此,研究人員接下來將檢查這一線性的原因并嘗試緩解。直接解決它們不太可行,我們希望探索兩個(gè)步驟,時(shí)序 i 安按照當(dāng)前方式訓(xùn)練系統(tǒng),然后恢復(fù)主要的架構(gòu)變更,再進(jìn)行精確調(diào)整。另外,研究人員還將探索將字符級(jí)信息納入模型,這可能會(huì)有助于解決訓(xùn)練過程中出現(xiàn)的一些充分性問題。同時(shí),如果解決了罕見詞,特別是命名實(shí)體的問題,該系統(tǒng)的表現(xiàn)將進(jìn)一步提升。