自然語言處理的神經網絡模型初探
深度學習(Deep Learning)技術對自然語言處理(NLP,Natural Language Processing)領域有著巨大的影響。
但作為初學者,您要從何處開始學習呢?
深度學習和自然語言處理都是較為廣闊的領域,但每個領域重點研究些什么?在自然語言處理領域中,又是哪一方面最受深度學習的影響呢?
通過閱讀本文,您會對自然語言處理中的深度學習有一個初步的認識。
閱讀這篇文章后,您可以知道:
- 對自然語言處理領域影響最為深遠的神經網絡結構。
- 綜觀那些可以通過深度學習成功解決的自然語言處理任務。
- 密集詞表示(Dense word representations)的重要性以及可以用于學習它們的方法。
現在,讓我們開始本次學習之旅。
自然語言處理的神經網絡模型入門
圖片作者 faungg ,部分版權保留。
概覽
本文將遵循相關論文的結構而分為 12 個部分,分別是:
- 關于論文(簡介)
- 神經網絡架構
- 特征表示
- 前饋神經網絡
- 詞嵌入
- 訓練神經網絡
- 級聯和多任務學習
- 結構化輸出預測
- 卷積層
- 循環神經網絡
- 循環神經網絡的具體架構
- 樹型建模
我想給大家介紹一下本文的主要部分和風格,以及高層次的話題介紹。
如果你想繼續深入研究,我強烈推薦閱讀全文或者一些最近出版的的書。
1.關于論文
論文的題目是:“A Primer on Neural Network Models for Natural Language Processing ” (自然語言處理的神經網絡模型入門)。
這篇論文可以免費在 ArXiv 上獲取,最新一次提交則是在 2015 年。它不只是一篇論文,更像是一篇技術報告或教程,并且文中還提供了針對學生與研究人員的,關于自然語言處理(NLP)中的深度學習方法的比較全面的介紹。
本教程從自然語言處理研究的角度對神經網絡模型進行了相關研究,力圖令自然語言領域的研究人員能跟上神經網絡技術的發展速度。
這篇入門論文是由 NLP 領域研究員 Yoav Goldberg 撰寫的,他曾在 Google Research 擔任研究科學家。雖然 Yoav 最近引起了一些爭議,但我不會因此反對他。
這是一份技術報告,大概共有 62 頁,其中約有 13 頁是參考文獻列表。
這篇文章非常適合初學者,其原因有二:
- 它對于讀者的要求并不高,只需要您對這一主題有一定的興趣,并且了解少數關于機器學習與(或者)自然語言處理相關的知識即可。
- 它涵蓋了廣泛的深度學習方法和自然語言問題。
在本教程中,我嘗試給 NLP 從業人員(以及新人)提供基本的背景知識,術語,工具和方法,使他們能夠理解神經網絡模型背后的原理,并將其應用到自己的工作中。 ... 本文的受眾,是那些有興趣使用現存的有用技術,并以實用且富有創造性的方式將其應用到他們最喜歡的 NLP 問題中的讀者。
通常,關鍵的深度學習方法通過語言學或自然語言處理的術語或命名法重新建立,這(在深度學習與自然語言處理之間)提供了一個有用的橋梁。
最后值得一提的是,這篇 2015 年的入門教程已在 2017 年出版,名為 “Neural Network Methods for Natural Language Processing” (自然語言處理中的神經網絡方法)。

如果你喜歡這篇入門教程并且想深入研究,我強烈推薦您繼續閱讀 Yoav 的這本書。
2.神經網絡架構
本小節簡要介紹了各種不同類型的神經網絡架構,在后面的章節中對它們進行了一些交叉引用。
全連接(Fully connected)前饋神經網絡是非線性學習器,在大多數情況下,它可以替換到使用了線性學習器的任何地方。
小節內容涵蓋了四種神經網絡架構,并重點介紹了各種應用和引用的例子:
- 全連接前饋神經網絡,如多層感知器網絡(Multilayer Perceptron Networks)。
- 具有卷積和池化層(Pooling Layers)的網絡,如卷積神經網絡(Convolutional Neural Network)。
- 遞歸神經網絡(Recurrent Neural Networks),如長短期記憶(LSTM,Long Short Term Memory)網絡。
- 循環神經網絡(Recursive Neural Networks)。
如果您只對其中一種特定網絡類型的應用感興趣,并想直接閱讀相關文獻,本節則提供了一些很好的來源。
3.特征表示
本節重點介紹了如何將稀疏表示過渡轉化為密集表示,然后再運用到深度學習模型訓練中。
當把輸入的稀疏線性模型轉變為基于神經網絡的模型時,最大的變化大概就是不再將每個特征表示為一個唯一的維度(所謂的單一表示 [One-hot Representation]),而是將它們表示為密集向量(Dense Vector)。
本節中介紹了 NLP 分類系統的一般結構,可總結如下:
- 提取一組核心語言特征。
- 為每個向量檢索對應的向量。
- 組合成為特征向量。
- 將組合的矢量饋送到一個非線性分類器中。
這個公式的關鍵在于使用了密集特征向量而不是稀疏特征向量,并且用的是核心特征而非特征組合。
請注意,在神經網絡設置中的特征提取階段,僅僅處理核心特征的提取。這與傳統的基于線性模型的 NLP 系統大相徑庭,因為在該系統中,特征設計者不僅必須手動地指定感興趣的核心特征,而且還需要手動指定它們之間的相互作用。
4.前饋神經網絡
本節是前饋人工神經網絡的速成課。
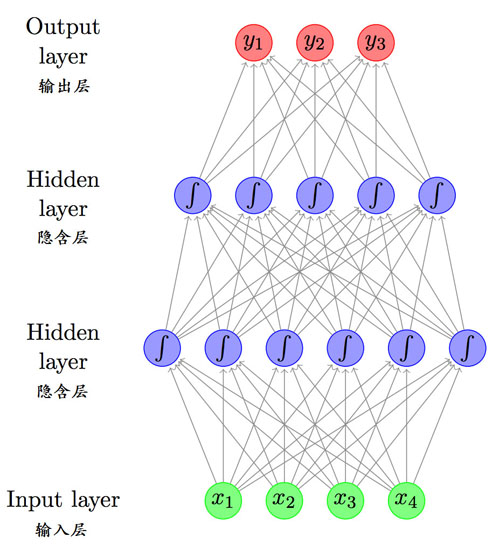
帶有兩個隱藏層的前饋神經網絡,摘自 “A Primer on Neural Network Models for Natural Language Processing”。
網絡是通過大腦啟發的隱喻與數學符號來呈現的。常見的神經網絡主題包括如下幾種:
- 表示能力(例如通用逼近性 [Universal approximation])。
- 常見的非線性關系(例如傳遞函數)。
- 輸出變換(例如 softmax)。
- 詞嵌入(例如內置的學習密集表示)。
- 損失函數(如 Hinge-loss 和對數損失)。
5.詞嵌入
在自然語言處理中,詞嵌入表示(Word Embedding Representations)是神經網絡方法的關鍵部分。本節則擴展了這個主題,并列舉了一些關鍵的方法。
神經網絡方法中的一個主要組成部分是使用嵌入 - 將每個特征表示為低維空間中的向量
本節中介紹了關于詞嵌入的以下幾個主題:
- 隨機初始化(例如,從統一的隨機向量開始訓練)。
- 特定的有監督任務的預訓練(例如,遷移學習 [Transfer Learning])。
- 無監督任務的預訓練(例如,word2vec 與 GloVe 之類的統計學方法)。
- 訓練目標(例如,目標對結果向量的影響)。
- 上下文的選擇(例如,每個單詞受到附近的單詞的影響)。
神經詞嵌入起源于語言建模領域,其中訓練所得的網絡則用于基于先前詞的序列來預測下一個詞。
6.訓練神經網絡
這個較長的章節是為神經網絡新手而寫的,它著重于訓練神經網絡的具體步驟。
神經網絡的訓練,是通過運用基于梯度的方法將訓練集上的損失函數最小化來完成的。
本節重點介紹隨機梯度下降法(還有相似的如 Mini-batch 這樣的方法)以及訓練過程中的一些重要主題,比如說正則化。
有趣的是,本節還提供了神經網絡的計算圖形透視圖,為諸如 Theano 和 TensorFlow 這樣的符號化數值計算庫提供了一個引子,而這些庫則是當前流行的用于實現深度學習模型的基礎。
一旦圖形被構建,就可以直接運行正向計算(計算計算結果)或者反向計算(計算梯度)
7.級聯和多任務學習
在前一節的基礎上,本節總結了級聯 NLP 模型和多語言任務學習模型的作用。
級聯模型(Model cascading):利用神經網絡模型計算圖的定義來使用中間表示(編碼)開發更復雜的模型。
例如,我們可能有一個前饋網絡,它用于根據詞的相鄰詞和(或)構成它的字符來預測詞的詞性。
多任務學習(Multi-task learning):有一些相互關聯的自然語言預測任務,它們不會相互影響,但它們各自的信息可以跨任務共享。
用于預測塊邊界、命名實體邊界和句子中的下一個單詞的信息,都依賴于一些共享的基礎句法語義表示
這兩個先進的概念都是在神經網絡的背景下描述的,它允許模型或信息在訓練(誤差反向傳播)和預測期間具有連通性。
8.結構化輸出預測
本節關注的是使用深度學習方法進行結構化預測的自然語言任務,比如說序列、樹,以及圖。
典型的例子是序列標記(例如詞性標注 [Part-of-speech tagging]),序列分割(分塊,NER [Named-entity Recognition,命名實體識別])以及句法分析。
本部分涵蓋了基于貪心思想和基于搜索的結構化預測,重點關注后者。
常用的自然語言結構化預測方法,是基于搜索的方法。
9.卷積層
本節提供了卷積神經網絡(CNN,Convolutional Neural Networks)的速成課程,以及闡述了這一網絡對自然語言領域的影響。
值得注意的是,當下已經證明了 CNN 對諸如情感分析(Sentiment analysis)這樣的分類 NLP 任務非常有效,例如學習尋找文本中的特定子序列或結構以進行預測。
卷積神經網絡被設計來識別大型結構中的指示性局部預測因子(Indicative local predictors),并且將它們組合起來以產生結構的固定大小的向量表示,從而捕獲這些對于預測任務而言最具信息性的局部方面(Local aspects)。
10.循環神經網絡
與前一節一樣,本節重點介紹了在 NLP 中所使用的特定網絡及其作用與應用。在 NLP 中,遞歸神經網絡(RNN,Recurrent Neural Networks)用于序列建模。
遞歸神經網絡(RNN)允許在固定大小的向量中表示任意大小的結構化輸入,同時也會注意輸入的結構化屬性。
考慮到 RNN,特別是 NLP 中的長短期記憶(LSTM)的普及,這個較大的章節介紹了各種關于循環神經網絡的主題與模型,其中包括:
- RNN 的抽象概念(例如網絡圖中的循環連接)。
- RNN 訓練(例如通過時間進行反向傳播)。
- 多層(堆疊)RNN(例如深度學習的 “深度” 部分)。
- BI-RNN(例如前向和反向序列作為輸入)。
- 用于表示的 RNN 堆疊。
我們將在 RNN 模型結構或結構元素上花費一定的時間,特別是:
- 接受器(Acceptor):完整的序列輸入后,它計算輸出的損失。
- 編碼器(Encoder):最終向量用作輸入序列的編碼器。
- 轉換器(Transducer):為輸入序列中的每個觀測對象創建一個輸出。
- 編碼器 - 解碼器(Encoder-Decoder):輸入序列在被解碼為輸出序列之前,會編碼成為固定長度的向量。
11.循環神經網絡的具體架構
本章節基于上一節的內容,介紹了具體的 RNN 算法。
具體包括如下幾點:
- 簡單的 RNN(SRNN)。
- 長短期記憶(LSTM)。
- 門控循環單元(GRU,Gated Recurrent Unit)。
12.樹型建模
最后一節則重點關注一個更復雜的網絡,我們稱為學習樹型建模的遞歸神經網絡。
樹,可以是句法樹,話語樹,甚至是由一個句子中各個部分所表達的情緒的樹。我們希望基于特定的樹節點或基于根節點來預測值,或者為完整的樹或樹的一部分指定一個質量值。
由于遞歸神經網絡保留了輸入序列的狀態,所以遞歸神經網絡會維持樹中節點的狀態。
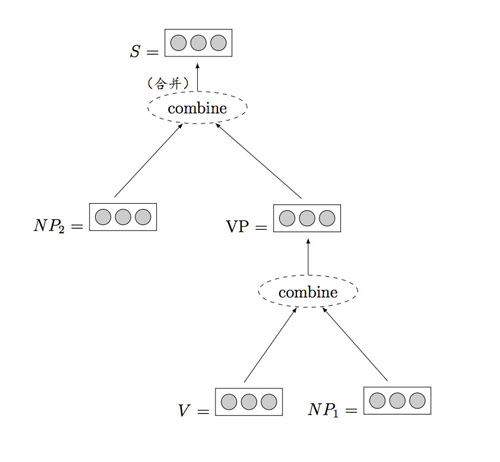
遞歸神經網絡的例子,摘自 “A Primer on Neural Network Models for Natural Language Processing”。
擴展閱讀
如果您正在深入研究,本節將提供更多有關該主題的資源。
A Primer on Neural Network Models for Natural Language Processing,2015 年發表。
Neural Network Methods for Natural Language Processing,2017 年出版。
總結
這篇文章介紹了一些關于自然語言處理中的深度學習的入門知識。
具體來說,你學到了:
- 對自然語言處理領域影響最大的神經網絡結構。
- 對可以通過深度學習算法成功解決的自然語言處理任務有一個廣泛的認識。
- 密集表示以及相應的學習方法的重要性。
原文鏈接:https://machinelearningmastery.com/primer-neural-network-models-natural-language-processing/
作者:Jason Brownlee
【本文是51CTO專欄作者“云加社區”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】