













圖數(shù)據(jù)庫 | 靈活存儲復雜關聯(lián)關系
在這個數(shù)據(jù)為王的時代,如何存儲及分析海量數(shù)據(jù),是個不那么容易的事情。近年來,圖數(shù)據(jù)庫逐漸映入我們眼簾,已成為NoSQL中關注度***,發(fā)展趨勢最明顯的數(shù)據(jù)庫之一。圖數(shù)據(jù)庫,他是誰?從哪兒來?牛在哪兒?怎樣助力研發(fā)工作?且聽京東攻城獅怎么說。
他是誰
圖數(shù)據(jù)庫并不是存儲圖片的數(shù)據(jù)庫,參照維基百科的定義,他是“以圖數(shù)據(jù)結(jié)構(gòu)來實現(xiàn)語義查詢,并以節(jié)點(node)、邊(edge)、屬性(properties)來表示并存儲數(shù)據(jù)”。是不是聽完感到一臉懵?
用大白話來講,圖數(shù)據(jù)庫就是以“圖數(shù)據(jù)結(jié)構(gòu)”來存儲并查詢數(shù)據(jù)。
如果你連什么是“圖數(shù)據(jù)結(jié)構(gòu)”都不知道,那你的數(shù)據(jù)結(jié)構(gòu)一定是體育老師教的,請回去自行復習《數(shù)據(jù)結(jié)構(gòu)與算法》這本經(jīng)典教材。
讓我們再回到圖數(shù)據(jù)上,看看他的一些關鍵核心概念,圖數(shù)據(jù)庫源于圖理論,具有如下幾個特征:
- 節(jié)點(node):通常表示實體,例如人員、賬戶、事件等,相當于RDBMS中的一行記錄。
- 邊(edge):又被稱為關系(relationships),具有名字和方向,從一個節(jié)點指向另一個節(jié)點,邊是圖數(shù)據(jù)庫中最顯著的一個特征,在RDBMS中沒有對應實現(xiàn)。
- 屬性(properties):類似KV數(shù)據(jù)庫中的鍵值對,節(jié)點和邊都可以有屬性。
圖數(shù)據(jù)庫將數(shù)據(jù)以屬性方式存儲在節(jié)點或邊中,以邊來表示節(jié)點之間的關系,并用特定查詢語言,進行數(shù)據(jù)檢索。
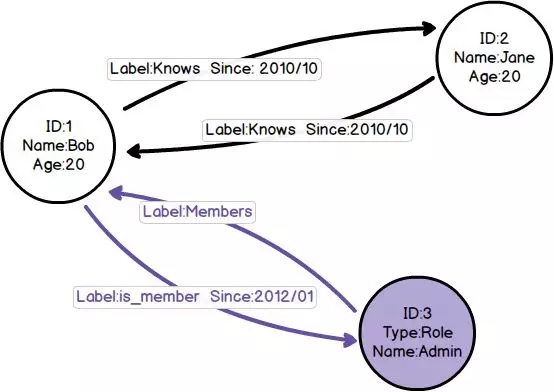
節(jié)點、邊、屬性示意圖
他從哪兒來
從圖數(shù)據(jù)庫的原型出現(xiàn)至今,已經(jīng)發(fā)展超過了半個世紀。圖數(shù)據(jù)庫的前身,可以追溯至上世紀60年代的Navigational databases,IBM開發(fā)了類似樹形結(jié)構(gòu)的數(shù)據(jù)存儲模型。到1969年的網(wǎng)絡數(shù)據(jù)庫語言(Network database language),支持圖數(shù)據(jù)結(jié)構(gòu)的展現(xiàn)。
又經(jīng)過漫長的30年,其間出現(xiàn)過可標記的圖形數(shù)據(jù)庫Logic Data Model,直至21世紀初,人們研發(fā)出具有ACID特性的里程碑式圖數(shù)據(jù)庫產(chǎn)品,例如:Neo4j、Oracle Spatial and Graph。
到2010年后,可支持水平擴展的分布式圖數(shù)據(jù)庫開始興起,例如OrientDB,ArangoDB,MarkLogic。至今,各式各樣的圖數(shù)據(jù)庫越來越受到重視,在Google、LinkedIn、Facebook這些***大公司中,已經(jīng)有了廣泛應用,迎來了他***的時代。
他牛在哪兒
在傳統(tǒng)關系型數(shù)據(jù)庫RDBMS中,并沒有明確的關系概念,或許叫表格數(shù)據(jù)庫更貼切,而圖數(shù)據(jù)庫,恰恰是表現(xiàn)實體之間關系的利器。
在表現(xiàn)實體間關系時,RDBMS會將另一個實體的唯一標識,存儲到表中的某一列,來與其他實體進行關聯(lián),例如典型的主鍵、外鍵。當遇到多對多關系時,典型做法會引入中間表,來存儲兩個實體ID間的關系,例如我們最熟悉的用戶角色多對多關系。在查詢時,需要多個表進行join連接,依次查詢所需信息。
而圖數(shù)據(jù)庫,會直接存儲兩個實體之間的關系。仍以用戶角色多對多關系舉例,用戶實體會有一個指針直接指向?qū)慕巧涗洠@個指針,就是上文所述的“邊(edge或relationships)”。而這樣存儲的好處是,當查詢用戶和角色時,只查詢用戶就可順著“關系”直接取到角色信息,消除了RDBMS表關聯(lián)所花費的性能開銷。
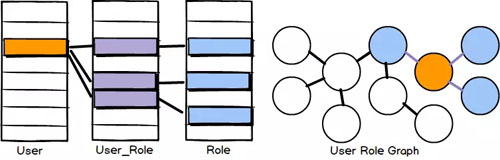
用戶角色關系不同存儲方式示意圖
當然,上述圖數(shù)據(jù)庫和RDBMS的對比只是舉了一個非常簡單的例子。
圖數(shù)據(jù)庫真正的價值,是靈活存儲復雜關聯(lián)關系,在深度超過1層以上關系中查找遍歷,或是基于復雜算法的實時數(shù)據(jù)關系挖掘。
在電商推薦引擎中,通常需要整合商品、客戶、供應商、物流等關鍵信息,挖掘用戶可能感興趣的商品。而圖數(shù)據(jù)庫可以快速記錄這些大量復雜關系,實時為用戶提供可能所需產(chǎn)品。
在社交網(wǎng)絡圖譜場景中,可記錄用戶社交關系,查找直接或間接認識的人,查找交際網(wǎng)中***影響力的人物,這些操作對于圖數(shù)據(jù)庫都是易如反掌。
在搜索引擎場景中,利用圖數(shù)據(jù)庫形成知識網(wǎng)絡,當用戶輸入關鍵詞檢索時,和關鍵詞義衍生的其他條目也可展現(xiàn)出來,在大量數(shù)據(jù)下,可輕松維護這些知識的相互聯(lián)系。
在路徑規(guī)劃場景中,存儲各站點之間的關聯(lián),并實時計算出***路徑…
圖數(shù)據(jù)庫還有其他諸多應用場景,當遇到大數(shù)據(jù)量的復雜實體關系存儲、查詢及可視化,都可以考慮使用圖數(shù)據(jù)庫。
當然人無完人,他在解決復雜關系存儲及查詢時有著諸多便利,但當記錄大量結(jié)構(gòu)化的數(shù)據(jù)時,就比不上傳統(tǒng)大數(shù)據(jù)存儲工具了,例如ES、HBase等。所以我們建議在實際生產(chǎn)環(huán)境中,混合使用傳統(tǒng)RDBMS和圖數(shù)據(jù)庫。
誰能站在圖數(shù)據(jù)庫的C位
圖數(shù)據(jù)庫有如此多的優(yōu)勢,我們團隊也嘗試在實際項目中落地,調(diào)研了若干開源圖數(shù)據(jù)庫引擎,下面是簡單的橫向?qū)Ρ龋└魑粎⒖肌?/p>
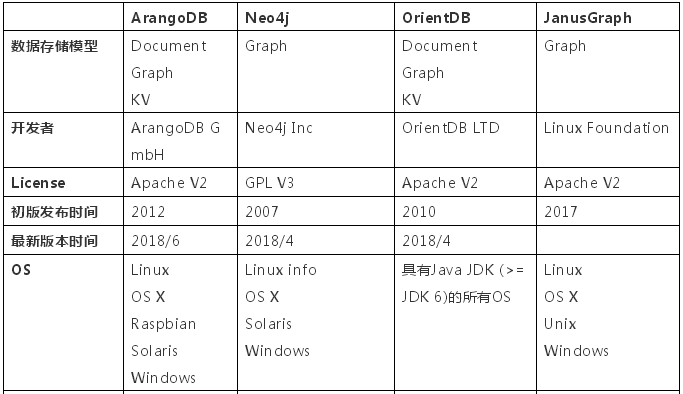
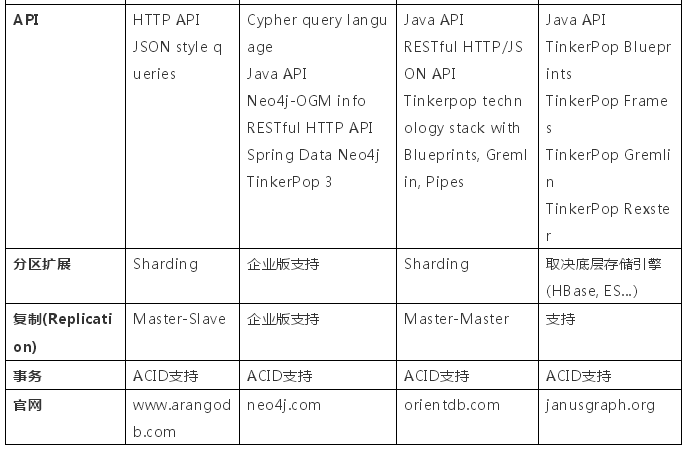
通過以上對比可以得知:
- Neo4j是最早起家做Graph DBMS,產(chǎn)品非常成熟,但是cluster和replication均需要企業(yè)收費版支持,且是GPL V3授權,假如將其用于商業(yè)目的,也需要繳納版權費用。
- JanusGraph是基于Titan圖數(shù)據(jù)庫延續(xù)下來的開源項目,由Linux Foundation進行維護。它并不是原生的圖數(shù)據(jù)庫引擎,而是底層使用ES、HBase等傳統(tǒng)結(jié)構(gòu)存儲,并在上面封裝圖查詢API。
- ArangoDB和OrientDB均支持Document、Graph及KV存儲,分區(qū)擴展及備份完善,具有ACID事務支持。
在技術選型時,有幾個特性我們需要著重考慮:
- 授權,是否商業(yè)付費;
- 底層存儲,有一些圖數(shù)據(jù)庫底層仍使用傳統(tǒng)RDBMS存儲,僅在上層封裝圖查詢API,所以在大數(shù)據(jù)量關系查詢時,也許性能不如人意;
- 分布式支持,為了應對大數(shù)據(jù)量,在生產(chǎn)環(huán)境應能夠水平拆分及復制備份。
結(jié)合以上幾點考慮,我們團隊目前選擇了OrientDB進行下一步落地開發(fā)。
他怎樣助力逆向處置團隊
目前,逆向處置團隊一些有想法的小伙伴們已經(jīng)搭上圖數(shù)據(jù)庫這趟列車,推動技術創(chuàng)新在實際業(yè)務中的應用,進行一些特定場景的數(shù)據(jù)開發(fā)工作。如存儲客戶關系資料、咨詢事件、訂單、服務單等信息。在知識庫項目中也有嘗試,用于開發(fā)知識圖譜特性,建立知識的深層次聯(lián)系。
對于互聯(lián)網(wǎng)公司來說,核心競爭力源于技術,同時對技術的不斷創(chuàng)新,或是對創(chuàng)新技術的應用,亦是推動公司和團隊發(fā)展和進步的重要手段之一。
上述內(nèi)容為我們團隊在近期研發(fā)中做出的大膽探索并取得的一些心得,在此與大家分享。如果這篇文章也激發(fā)了你對圖數(shù)據(jù)庫的興趣,歡迎與我們一同學習,共同探討。



















