高并發(fā)的“大殺器”:異步化、并行化
高并發(fā)的大殺器:異步化
同步和異步,阻塞和非阻塞
同步和異步,阻塞和非阻塞,這幾個(gè)詞已經(jīng)是老生常談,但是還是有很多同學(xué)分不清楚,以為同步肯定就是阻塞,異步肯定就是非阻塞,其實(shí)他們并不是一回事。
同步和異步關(guān)注的是結(jié)果消息的通信機(jī)制:
- 同步:調(diào)用方需要主動(dòng)等待結(jié)果的返回。
- 異步:不需要主動(dòng)等待結(jié)果的返回,而是通過(guò)其他手段,比如狀態(tài)通知,回調(diào)函數(shù)等。
阻塞和非阻塞主要關(guān)注的是等待結(jié)果返回調(diào)用方的狀態(tài):
- 阻塞:是指結(jié)果返回之前,當(dāng)前線(xiàn)程被掛起,不做任何事。
- 非阻塞:是指結(jié)果在返回之前,線(xiàn)程可以做一些其他事,不會(huì)被掛起。
可以看見(jiàn)同步和異步,阻塞和非阻塞主要關(guān)注的點(diǎn)不同,有人會(huì)問(wèn)同步還能非阻塞,異步還能阻塞?
當(dāng)然是可以的,下面為了更好的說(shuō)明它們的組合之間的意思,用幾個(gè)簡(jiǎn)單的例子說(shuō)明:
同步阻塞:同步阻塞基本也是編程中最常見(jiàn)的模型,打個(gè)比方你去商店買(mǎi)衣服,你去了之后發(fā)現(xiàn)衣服賣(mài)完了,那你就在店里面一直等,期間不做任何事(包括看手機(jī)),等著商家進(jìn)貨,直到有貨為止,這個(gè)效率很低。
- 同步非阻塞:同步非阻塞在編程中可以抽象為一個(gè)輪詢(xún)模式,你去了商店之后,發(fā)現(xiàn)衣服賣(mài)完了。
這個(gè)時(shí)候不需要傻傻的等著,你可以去其他地方比如奶茶店,買(mǎi)杯水,但是你還是需要時(shí)不時(shí)的去商店問(wèn)老板新衣服到了嗎。
- 異步阻塞:異步阻塞這個(gè)編程里面用的較少,有點(diǎn)類(lèi)似你寫(xiě)了個(gè)線(xiàn)程池,submit 然后馬上 future.get(),這樣線(xiàn)程其實(shí)還是掛起的。
有點(diǎn)像你去商店買(mǎi)衣服,這個(gè)時(shí)候發(fā)現(xiàn)衣服沒(méi)有了,這個(gè)時(shí)候你就給老板留個(gè)電話(huà),說(shuō)衣服到了就給我打電話(huà),然后你就守著這個(gè)電話(huà),一直等著它響什么事也不做。這樣感覺(jué)的確有點(diǎn)傻,所以這個(gè)模式用得比較少。
- 異步非阻塞:這也是現(xiàn)在高并發(fā)編程的一個(gè)核心,也是今天主要講的一個(gè)核心。
好比你去商店買(mǎi)衣服,衣服沒(méi)了,你只需要給老板說(shuō)這是我的電話(huà),衣服到了就打。然后你就隨心所欲的去玩,也不用操心衣服什么時(shí)候到,衣服一到,電話(huà)一響就可以去買(mǎi)衣服了。
同步阻塞 PK 異步非阻塞
上面已經(jīng)看到了同步阻塞的效率是多么的低,如果使用同步阻塞的方式去買(mǎi)衣服,你有可能一天只能買(mǎi)一件衣服,其他什么事都不能干;如果用異步非阻塞的方式去買(mǎi),買(mǎi)衣服只是你一天中進(jìn)行的一個(gè)小事。
我們把這個(gè)映射到我們代碼中,當(dāng)我們的線(xiàn)程發(fā)生一次 RPC 調(diào)用或者 HTTP 調(diào)用,又或者其他的一些耗時(shí)的 IO 調(diào)用。
發(fā)起之后,如果是同步阻塞,我們的這個(gè)線(xiàn)程就會(huì)被阻塞掛起,直到結(jié)果返回,試想一下,如果 IO 調(diào)用很頻繁那我們的 CPU 使用率會(huì)很低很低。
正所謂是物盡其用,既然 CPU 的使用率被 IO 調(diào)用搞得很低,那我們就可以使用異步非阻塞。
當(dāng)發(fā)生 IO 調(diào)用時(shí)我并不馬上關(guān)心結(jié)果,我只需要把回調(diào)函數(shù)寫(xiě)入這次 IO 調(diào)用,這個(gè)時(shí)候線(xiàn)程可以繼續(xù)處理新的請(qǐng)求,當(dāng) IO 調(diào)用結(jié)束時(shí),會(huì)調(diào)用回調(diào)函數(shù)。
而我們的線(xiàn)程始終處于忙碌之中,這樣就能做更多的有意義的事了。這里首先要說(shuō)明的是,異步化不是萬(wàn)能,異步化并不能縮短你整個(gè)鏈路調(diào)用時(shí)間長(zhǎng)的問(wèn)題,但是它能極大的提升你的最大 QPS。
一般我們的業(yè)務(wù)中有兩處比較耗時(shí):
- CPU:CPU 耗時(shí)指的是我們的一般的業(yè)務(wù)處理邏輯,比如一些數(shù)據(jù)的運(yùn)算,對(duì)象的序列化。這些異步化是不能解決的,得需要靠一些算法的優(yōu)化,或者一些高性能框架。
- IO Wait:IO 耗時(shí)就像我們上面說(shuō)的,一般發(fā)生在網(wǎng)絡(luò)調(diào)用,文件傳輸中等等,這個(gè)時(shí)候線(xiàn)程一般會(huì)掛起阻塞。而我們的異步化通常用于解決這部分的問(wèn)題。
哪些可以異步化
上面說(shuō)了異步化是用于解決 IO 阻塞的問(wèn)題,而我們一般項(xiàng)目中可以使用異步化的情況如下:
- Servlet 異步化
- Spring MVC 異步化
- RPC 調(diào)用如(Dubbo,Thrift),HTTP 調(diào)用異步化
- 數(shù)據(jù)庫(kù)調(diào)用,緩存調(diào)用異步化
下面我會(huì)從上面幾個(gè)方面進(jìn)行異步化的介紹。
Servlet 異步化
對(duì)于 Java 開(kāi)發(fā)程序員來(lái)說(shuō) Servlet 并不陌生,在項(xiàng)目中不論你使用 Struts2,還是使用的 Spring MVC,本質(zhì)上都是封裝的 Servlet。
但是我們一般的開(kāi)發(fā)都是使用的同步阻塞,模式如下:
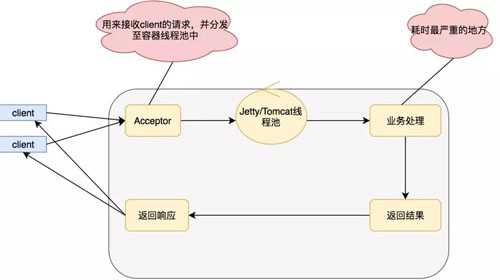
上面的模式優(yōu)點(diǎn)在于編碼簡(jiǎn)單,適合在項(xiàng)目啟動(dòng)初期,訪(fǎng)問(wèn)量較少,或者是 CPU 運(yùn)算較多的項(xiàng)目。
缺點(diǎn)在于,業(yè)務(wù)邏輯線(xiàn)程和 Servlet 容器線(xiàn)程是同一個(gè),一般的業(yè)務(wù)邏輯總得發(fā)生點(diǎn) IO,比如查詢(xún)數(shù)據(jù)庫(kù),比如產(chǎn)生 RPC 調(diào)用,這個(gè)時(shí)候就會(huì)發(fā)生阻塞。
而我們的 Servlet 容器線(xiàn)程肯定是有限的,當(dāng) Servlet 容器線(xiàn)程都被阻塞的時(shí)候我們的服務(wù)這個(gè)時(shí)候就會(huì)發(fā)生拒絕訪(fǎng)問(wèn),線(xiàn)程不夠我當(dāng)然可以通過(guò)增加機(jī)器的一系列手段來(lái)解決這個(gè)問(wèn)題。
但是俗話(huà)說(shuō)得好靠人不如靠自己,靠別人替我分擔(dān)請(qǐng)求,還不如我自己搞定。
所以在 Servlet 3.0 之后支持了異步化,我們采用異步化之后,模式變成如下:
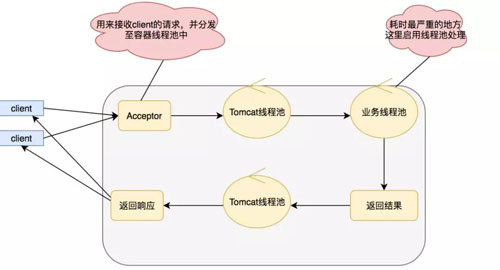
在這里我們采用新的線(xiàn)程處理業(yè)務(wù)邏輯,IO 調(diào)用的阻塞就不會(huì)影響我們的 Serlvet 了,實(shí)現(xiàn)異步 Serlvet 的代碼也比較簡(jiǎn)單,如下:
- @WebServlet(name = "WorkServlet",urlPatterns = "/work",asyncSupported =true)
- public class WorkServlet extends HttpServlet{
- private static final long serialVersionUID = 1L;
- @Override
- protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
- this.doPost(req, resp);
- }
- @Override
- protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
- //設(shè)置ContentType,關(guān)閉緩存
- resp.setContentType("text/plain;charset=UTF-8");
- resp.setHeader("Cache-Control","private");
- resp.setHeader("Pragma","no-cache");
- final PrintWriter writer= resp.getWriter();
- writer.println("老師檢查作業(yè)了");
- writer.flush();
- List<String> zuoyes=new ArrayList<String>();
- for (int i = 0; i < 10; i++) {
- zuoyes.add("zuoye"+i);;
- }
- //開(kāi)啟異步請(qǐng)求
- final AsyncContext ac=req.startAsync();
- doZuoye(ac, zuoyes);
- writer.println("老師布置作業(yè)");
- writer.flush();
- }
- private void doZuoye(final AsyncContext ac, final List<String> zuoyes) {
- ac.setTimeout(1*60*60*1000L);
- ac.start(new Runnable() {
- @Override
- public void run() {
- //通過(guò)response獲得字符輸出流
- try {
- PrintWriter writer=ac.getResponse().getWriter();
- for (String zuoye:zuoyes) {
- writer.println("\""+zuoye+"\"請(qǐng)求處理中");
- Thread.sleep(1*1000L);
- writer.flush();
- }
- ac.complete();
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- });
- }
- }
實(shí)現(xiàn) Serlvet 的關(guān)鍵在于 HTTP 采取了長(zhǎng)連接,也就是當(dāng)請(qǐng)求打過(guò)來(lái)的時(shí)候就算有返回也不會(huì)關(guān)閉,因?yàn)榭赡苓€會(huì)有數(shù)據(jù),直到返回關(guān)閉指令。
AsyncContext ac=req.startAsync();用于獲取異步上下文,后續(xù)我們通過(guò)這個(gè)異步上下文進(jìn)行回調(diào)返回?cái)?shù)據(jù),有點(diǎn)像我們買(mǎi)衣服的時(shí)候,留給老板一個(gè)電話(huà)。
而這個(gè)上下文也是一個(gè)電話(huà),當(dāng)有衣服到的時(shí)候,也就是當(dāng)有數(shù)據(jù)準(zhǔn)備好的時(shí)候就可以打電話(huà)發(fā)送數(shù)據(jù)了。ac.complete();用來(lái)進(jìn)行長(zhǎng)鏈接的關(guān)閉。
Spring MVC 異步化
現(xiàn)在其實(shí)很少人來(lái)進(jìn)行 Serlvet 編程,都是直接采用現(xiàn)成的一些框架,比如 Struts2,Spring MVC。下面介紹下使用 Spring MVC 如何進(jìn)行異步化:
首先確認(rèn)你的項(xiàng)目中的 Servlet 是 3.0 以上,其次 Spring MVC 4.0+:
- <dependency>
- <groupId>javax.servlet</groupId>
- <artifactId>javax.servlet-api</artifactId>
- <version>3.1.0</version>
- <scope>provided</scope>
- </dependency>
- <dependency>
- <groupId>org.springframework</groupId>
- <artifactId>spring-webmvc</artifactId>
- <version>4.2.3.RELEASE</version>
- </dependency>
web.xml 頭部聲明,必須要 3.0,F(xiàn)ilter 和 Serverlet 設(shè)置為異步:
- <?xml version="1.0" encoding="UTF-8"?>
- <web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
- http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
- <filter>
- <filter-name>testFilter</filter-name>
- <filter-class>com.TestFilter</filter-class>
- <async-supported>true</async-supported>
- </filter>
- <servlet>
- <servlet-name>mvc-dispatcher</servlet-name>
- <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
- .........
- <async-supported>true</async-supported>
- </servlet>
使用 Spring MVC 封裝了 Servlet 的 AsyncContext,使用起來(lái)比較簡(jiǎn)單。以前我們同步的模式的 Controller 是返回 ModelAndView。
而異步模式直接生成一個(gè) DeferredResult(支持我們超時(shí)擴(kuò)展)即可保存上下文,下面給出如何和我們 HttpClient 搭配的簡(jiǎn)單 demo:
- @RequestMapping(value="/asynctask", method = RequestMethod.GET)
- public DeferredResult<String> asyncTask() throws IOReactorException {
- IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(1).build();
- ConnectingIOReactor ioReactor = new DefaultConnectingIOReactor(ioReactorConfig);
- PoolingNHttpClientConnectionManager conManager = new PoolingNHttpClientConnectionManager(ioReactor);
- conManager.setMaxTotal(100);
- conManager.setDefaultMaxPerRoute(100);
- CloseableHttpAsyncClient httpclient = HttpAsyncClients.custom().setConnectionManager(conManager).build();
- // Start the client
- httpclient.start();
- //設(shè)置超時(shí)時(shí)間200ms
- final DeferredResult<String> deferredResult = new DeferredResult<String>(200L);
- deferredResult.onTimeout(new Runnable() {
- @Override
- public void run() {
- System.out.println("異步調(diào)用執(zhí)行超時(shí)!thread id is : " + Thread.currentThread().getId());
- deferredResult.setResult("超時(shí)了");
- }
- });
- System.out.println("/asynctask 調(diào)用!thread id is : " + Thread.currentThread().getId());
- final HttpGet request2 = new HttpGet("http://www.apache.org/");
- httpclient.execute(request2, new FutureCallback<HttpResponse>() {
- public void completed(final HttpResponse response2) {
- System.out.println(request2.getRequestLine() + "->" + response2.getStatusLine());
- deferredResult.setResult(request2.getRequestLine() + "->" + response2.getStatusLine());
- }
- public void failed(final Exception ex) {
- System.out.println(request2.getRequestLine() + "->" + ex);
- }
- public void cancelled() {
- System.out.println(request2.getRequestLine() + " cancelled");
- }
- });
- return deferredResult;
- }
注意:在 Serlvet 異步化中有個(gè)問(wèn)題是 Filter 的后置結(jié)果處理,沒(méi)法使用,對(duì)于我們一些打點(diǎn),結(jié)果統(tǒng)計(jì)直接使用 Serlvet 異步是沒(méi)法用的。
在 Spring MVC 中就很好的解決了這個(gè)問(wèn)題,Spring MVC 采用了一個(gè)比較取巧的方式通過(guò)請(qǐng)求轉(zhuǎn)發(fā),能讓請(qǐng)求再次通過(guò)過(guò)濾器。
但是又引入了新的一個(gè)問(wèn)題那就是過(guò)濾器會(huì)處理兩次,這里可以通過(guò) Spring MVC 源碼中自身判斷的方法。
我們可以在 Filter 中使用下面這句話(huà)來(lái)進(jìn)行判斷是不是屬于 Spring MVC 轉(zhuǎn)發(fā)過(guò)來(lái)的請(qǐng)求,從而不處理 Filter 的前置事件,只處理后置事件:
- Object asyncManagerAttr = servletRequest.getAttribute(WEB_ASYNC_MANAGER_ATTRIBUTE);
- return asyncManagerAttr instanceof WebAsyncManager ;
全鏈路異步化
上面我們介紹了 Serlvet 的異步化,相信細(xì)心的同學(xué)都看出來(lái)似乎并沒(méi)有解決根本的問(wèn)題,我的 IO 阻塞依然存在,只是換了個(gè)位置而已。
當(dāng) IO 調(diào)用頻繁同樣會(huì)讓業(yè)務(wù)線(xiàn)程池快速變滿(mǎn),雖然 Serlvet 容器線(xiàn)程不被阻塞,但是這個(gè)業(yè)務(wù)依然會(huì)變得不可用。
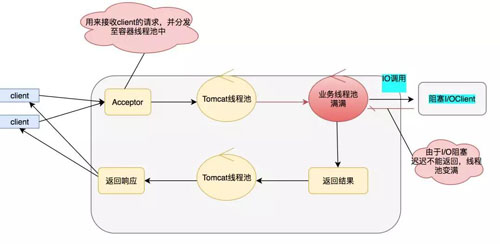
那么怎么才能解決上面的問(wèn)題呢?答案就是全鏈路異步化,全鏈路異步追求的是沒(méi)有阻塞,打滿(mǎn)你的 CPU,把機(jī)器的性能壓榨到極致。模型圖如下:
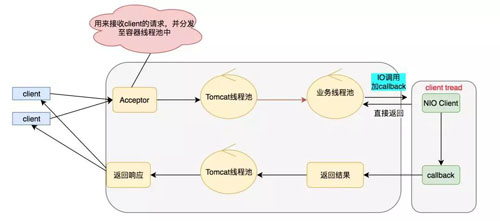
具體的 NIO Client 到底做了什么事呢,具體如下面模型:
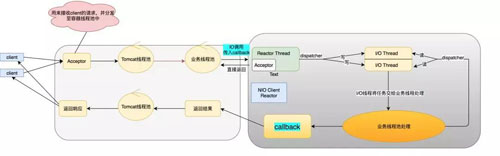
上面就是我們?nèi)溌樊惒降膱D了(部分線(xiàn)程池可以?xún)?yōu)化)。全鏈路的核心在于只要我們遇到 IO 調(diào)用的時(shí)候,我們就可以使用 NIO,從而避免阻塞,也就解決了之前說(shuō)的業(yè)務(wù)線(xiàn)程池被打滿(mǎn)的尷尬場(chǎng)景。
遠(yuǎn)程調(diào)用異步化
我們一般遠(yuǎn)程調(diào)用使用 RPC 或者 HTTP:
- 對(duì)于 RPC 來(lái)說(shuō),一般 Thrift,HTTP,Motan 等支持都異步調(diào)用,其內(nèi)部原理也都是采用事件驅(qū)動(dòng)的 NIO 模型。
- 對(duì)于 HTTP 來(lái)說(shuō),一般的 Apache HTTP Client 和 Okhttp 也都提供了異步調(diào)用。
下面簡(jiǎn)單介紹下 HTTP 異步化調(diào)用是怎么做的。首先來(lái)看一個(gè)例子:
- public class HTTPAsyncClientDemo {
- public static void main(String[] args) throws ExecutionException, InterruptedException, IOReactorException {
- //具體參數(shù)含義下文會(huì)講
- //apache提供了ioReactor的參數(shù)配置,這里我們配置IO 線(xiàn)程為1
- IOReactorConfig ioReactorConfig = IOReactorConfig.custom().setIoThreadCount(1).build();
- //根據(jù)這個(gè)配置創(chuàng)建一個(gè)ioReactor
- ConnectingIOReactor ioReactor = new DefaultConnectingIOReactor(ioReactorConfig);
- //asyncHttpClient使用PoolingNHttpClientConnectionManager管理我們客戶(hù)端連接
- PoolingNHttpClientConnectionManager conManager = new PoolingNHttpClientConnectionManager(ioReactor);
- //設(shè)置總共的連接的最大數(shù)量
- conManager.setMaxTotal(100);
- //設(shè)置每個(gè)路由的連接的最大數(shù)量
- conManager.setDefaultMaxPerRoute(100);
- //創(chuàng)建一個(gè)Client
- CloseableHttpAsyncClient httpclient = HttpAsyncClients.custom().setConnectionManager(conManager).build();
- // Start the client
- httpclient.start();
- // Execute request
- final HttpGet request1 = new HttpGet("http://www.apache.org/");
- Future<HttpResponse> future = httpclient.execute(request1, null);
- // and wait until a response is received
- HttpResponse response1 = future.get();
- System.out.println(request1.getRequestLine() + "->" + response1.getStatusLine());
- // One most likely would want to use a callback for operation result
- final HttpGet request2 = new HttpGet("http://www.apache.org/");
- httpclient.execute(request2, new FutureCallback<HttpResponse>() {
- //Complete成功后會(huì)回調(diào)這個(gè)方法
- public void completed(final HttpResponse response2) {
- System.out.println(request2.getRequestLine() + "->" + response2.getStatusLine());
- }
- public void failed(final Exception ex) {
- System.out.println(request2.getRequestLine() + "->" + ex);
- }
- public void cancelled() {
- System.out.println(request2.getRequestLine() + " cancelled");
- }
- });
- }
- }
下面給出 httpAsync 的整個(gè)類(lèi)圖:
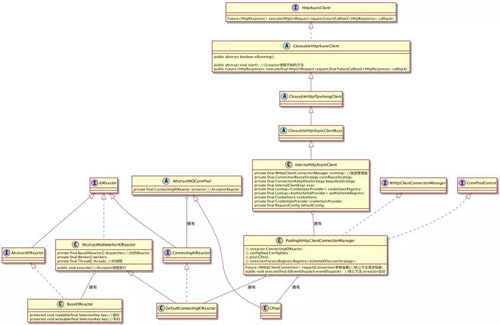
對(duì)于我們的 HTTPAysncClient 最后使用的是 InternalHttpAsyncClient,在 InternalHttpAsyncClient 中有個(gè) ConnectionManager,這個(gè)就是我們管理連接的管理器。
而在 httpAsync 中只有一個(gè)實(shí)現(xiàn)那就是 PoolingNHttpClientConnectionManager。
這個(gè)連接管理器中有兩個(gè)我們比較關(guān)心的,一個(gè)是 Reactor,一個(gè)是 Cpool:
- Reactor:所有的 Reactor 這里都是實(shí)現(xiàn)了 IOReactor 接口。在 PoolingNHttpClientConnectionManager 中會(huì)有擁有一個(gè) Reactor,那就是 DefaultConnectingIOReactor,這個(gè) DefaultConnectingIOReactor,負(fù)責(zé)處理 Acceptor。
在 DefaultConnectingIOReactor 有個(gè) excutor 方法,生成 IOReactor 也就是我們圖中的 BaseIOReactor,進(jìn)行 IO 的操作。這個(gè)模型就是我們上面的 1.2.2 的模型。
- CPool:在 PoolingNHttpClientConnectionManager 中有個(gè) CPool,主要是負(fù)責(zé)控制我們連接,我們上面所說(shuō)的 maxTotal 和 defaultMaxPerRoute,都是由其進(jìn)行控制。
如果每個(gè)路由有滿(mǎn)了,它會(huì)斷開(kāi)最老的一個(gè)鏈接;如果總共的 total 滿(mǎn)了,它會(huì)放入 leased 隊(duì)列,釋放空間的時(shí)候就會(huì)將其重新連接。
數(shù)據(jù)庫(kù)調(diào)用異步化
對(duì)于數(shù)據(jù)庫(kù)調(diào)用一般的框架并沒(méi)有提供異步化的方法,這里推薦自己封裝或者使用網(wǎng)上開(kāi)源的。
異步化并不是高并發(fā)的銀彈,但是有了異步化的確能提高你機(jī)器的 QPS,吞吐量等等。
上述講的一些模型如果能合理的做一些優(yōu)化,然后進(jìn)行應(yīng)用,相信能對(duì)你的服務(wù)有很大的幫助。
高并發(fā)大殺器:并行化
想必?zé)釔?ài)游戲的同學(xué)小時(shí)候都幻想過(guò)要是自己會(huì)分身之術(shù),就能一邊打游戲一邊上課了。
可惜現(xiàn)實(shí)中并沒(méi)有這個(gè)技術(shù),你要么只有老老實(shí)實(shí)的上課,要么就只有逃課去打游戲了。
雖然在現(xiàn)實(shí)中我們無(wú)法實(shí)現(xiàn)分身這樣的技術(shù),但是我們可以在計(jì)算機(jī)世界中實(shí)現(xiàn)這樣的愿望。
計(jì)算機(jī)中的分身術(shù)
計(jì)算機(jī)中的分身術(shù)不是天生就有了。在 1971 年,英特爾推出的全球第一顆通用型微處理器 4004,由 2300 個(gè)晶體管構(gòu)成。
當(dāng)時(shí),公司的聯(lián)合創(chuàng)始人之一戈登摩爾就提出大名鼎鼎的“摩爾定律”——每過(guò) 18 個(gè)月,芯片上可以集成的晶體管數(shù)目將增加一倍。
最初的主頻 740KHz(每秒運(yùn)行 74 萬(wàn)次),現(xiàn)在過(guò)了快 50 年了,大家去買(mǎi)電腦的時(shí)候會(huì)發(fā)現(xiàn)現(xiàn)在的主頻都能達(dá)到 4.0GHZ了(每秒 40 億次)。
但是主頻越高帶來(lái)的收益卻是越來(lái)越小:
- 據(jù)測(cè)算,主頻每增加 1G,功耗將上升 25 瓦,而在芯片功耗超過(guò) 150 瓦后,現(xiàn)有的風(fēng)冷散熱系統(tǒng)將無(wú)法滿(mǎn)足散熱的需要。有部分 CPU 都可以用來(lái)煎雞蛋了。
- 流水線(xiàn)過(guò)長(zhǎng),使得單位頻率效能低下,越大的主頻其實(shí)整體性能反而不如小的主頻。
- 戈登摩爾認(rèn)為摩爾定律未來(lái) 10-20 年會(huì)失效。
在單核主頻遇到瓶頸的情況下,多核 CPU 應(yīng)運(yùn)而生,不僅提升了性能,并且降低了功耗。
所以多核 CPU 逐漸成為現(xiàn)在市場(chǎng)的主流,這樣讓我們的多線(xiàn)程編程也更加的容易。
說(shuō)到了多核 CPU 就一定要說(shuō) GPU,大家可能對(duì)這個(gè)比較陌生,但是一說(shuō)到顯卡就肯定不陌生,筆者搞過(guò)一段時(shí)間的 CUDA 編程,我才意識(shí)到這個(gè)才是真正的并行計(jì)算。
大家都知道圖片像素點(diǎn)吧,比如 1920*1080 的圖片有 210 萬(wàn)個(gè)像素點(diǎn),如果想要把一張圖片的每個(gè)像素點(diǎn)都進(jìn)行轉(zhuǎn)換一下,那在我們 Java 里面可能就要循環(huán)遍歷 210 萬(wàn)次。
就算我們用多線(xiàn)程 8 核 CPU,那也得循環(huán)幾十萬(wàn)次。但是如果使用 Cuda,最多可以 365535*512 = 100661760(一億)個(gè)線(xiàn)程并行執(zhí)行,就這種級(jí)別的圖片那也是馬上處理完成。
但是 Cuda 一般適合于圖片這種,有大量的像素點(diǎn)需要同時(shí)處理,但是指令集很少所以邏輯不能太復(fù)雜。
應(yīng)用中的并行
一說(shuō)起讓你的服務(wù)高性能的手段,那么異步化,并行化這些肯定會(huì)第一時(shí)間在你腦海中顯現(xiàn)出來(lái),并行化可以用來(lái)配合異步化,也可以用來(lái)單獨(dú)做優(yōu)化。
我們可以想想有這么一個(gè)需求,在你下外賣(mài)訂單的時(shí)候,這筆訂單可能還需要查用戶(hù)信息,折扣信息,商家信息,菜品信息等。
用同步的方式調(diào)用,如下圖所示:
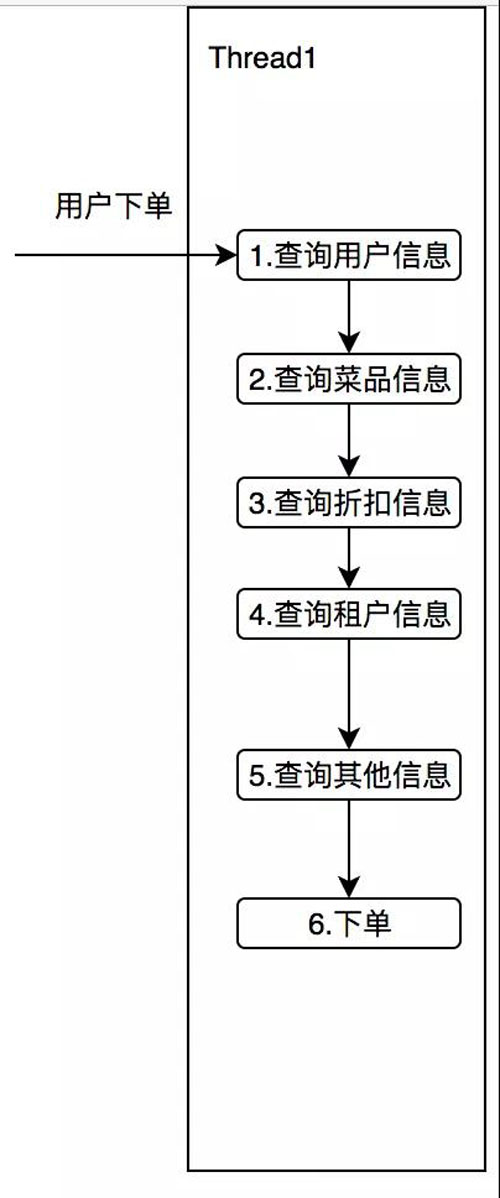
設(shè)想一下這 5 個(gè)查詢(xún)服務(wù),平均每次消耗 50ms,那么本次調(diào)用至少是 250ms,我們細(xì)想一下,這五個(gè)服務(wù)其實(shí)并沒(méi)有任何的依賴(lài),誰(shuí)先獲取誰(shuí)后獲取都可以。
那么我們可以想想,是否可以用多重影分身之術(shù),同時(shí)獲取這五個(gè)服務(wù)的信息呢?
優(yōu)化如下:
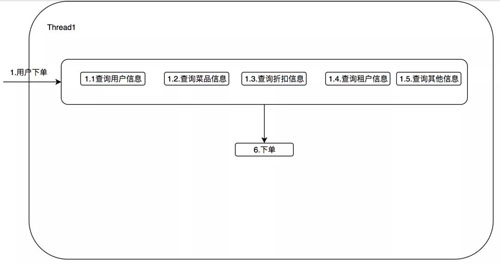
將這五個(gè)查詢(xún)服務(wù)并行查詢(xún),在理想情況下可以?xún)?yōu)化至 50ms。當(dāng)然說(shuō)起來(lái)簡(jiǎn)單,我們真正如何落地呢?
CountDownLatch/Phaser
CountDownLatch 和 Phaser 是 JDK 提供的同步工具類(lèi)。Phaser 是 1.7 版本之后提供的工具類(lèi)。而 CountDownLatch 是 1.5 版本之后提供的工具類(lèi)。
這里簡(jiǎn)單介紹一下 CountDownLatch,可以將其看成是一個(gè)計(jì)數(shù)器,await()方法可以阻塞至超時(shí)或者計(jì)數(shù)器減至 0,其他線(xiàn)程當(dāng)完成自己目標(biāo)的時(shí)候可以減少 1,利用這個(gè)機(jī)制我們可以用來(lái)做并發(fā)。
可以用如下的代碼實(shí)現(xiàn)我們上面的下訂單的需求:
- public class CountDownTask {
- private static final int CORE_POOL_SIZE = 4;
- private static final int MAX_POOL_SIZE = 12;
- private static final long KEEP_ALIVE_TIME = 5L;
- private final static int QUEUE_SIZE = 1600;
- protected final static ExecutorService THREAD_POOL = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE,
- KEEP_ALIVE_TIME, TimeUnit.SECONDS, new LinkedBlockingQueue<>(QUEUE_SIZE));
- public static void main(String[] args) throws InterruptedException {
- // 新建一個(gè)為5的計(jì)數(shù)器
- CountDownLatch countDownLatch = new CountDownLatch(5);
- OrderInfo orderInfo = new OrderInfo();
- THREAD_POOL.execute(() -> {
- System.out.println("當(dāng)前任務(wù)Customer,線(xiàn)程名字為:" + Thread.currentThread().getName());
- orderInfo.setCustomerInfo(new CustomerInfo());
- countDownLatch.countDown();
- });
- THREAD_POOL.execute(() -> {
- System.out.println("當(dāng)前任務(wù)Discount,線(xiàn)程名字為:" + Thread.currentThread().getName());
- orderInfo.setDiscountInfo(new DiscountInfo());
- countDownLatch.countDown();
- });
- THREAD_POOL.execute(() -> {
- System.out.println("當(dāng)前任務(wù)Food,線(xiàn)程名字為:" + Thread.currentThread().getName());
- orderInfo.setFoodListInfo(new FoodListInfo());
- countDownLatch.countDown();
- });
- THREAD_POOL.execute(() -> {
- System.out.println("當(dāng)前任務(wù)Tenant,線(xiàn)程名字為:" + Thread.currentThread().getName());
- orderInfo.setTenantInfo(new TenantInfo());
- countDownLatch.countDown();
- });
- THREAD_POOL.execute(() -> {
- System.out.println("當(dāng)前任務(wù)OtherInfo,線(xiàn)程名字為:" + Thread.currentThread().getName());
- orderInfo.setOtherInfo(new OtherInfo());
- countDownLatch.countDown();
- });
- countDownLatch.await(1, TimeUnit.SECONDS);
- System.out.println("主線(xiàn)程:"+ Thread.currentThread().getName());
- }
- }
建立一個(gè)線(xiàn)程池(具體配置根據(jù)具體業(yè)務(wù),具體機(jī)器配置),進(jìn)行并發(fā)的執(zhí)行我們的任務(wù)(生成用戶(hù)信息,菜品信息等),最后利用 await 方法阻塞等待結(jié)果成功返回。
CompletableFuture
相信各位同學(xué)已經(jīng)發(fā)現(xiàn),CountDownLatch 雖然能實(shí)現(xiàn)我們需要滿(mǎn)足的功能但是其仍然有個(gè)問(wèn)題是,我們的業(yè)務(wù)代碼需要耦合 CountDownLatch 的代碼。
比如在我們獲取用戶(hù)信息之后,我們會(huì)執(zhí)行 countDownLatch.countDown(),很明顯我們的業(yè)務(wù)代碼顯然不應(yīng)該關(guān)心這一部分邏輯,并且在開(kāi)發(fā)的過(guò)程中萬(wàn)一寫(xiě)漏了,那我們的 await 方法將只會(huì)被各種異常喚醒。
所以在 JDK 1.8 中提供了一個(gè)類(lèi) CompletableFuture,它是一個(gè)多功能的非阻塞的 Future。(什么是 Future:用來(lái)代表異步結(jié)果,并且提供了檢查計(jì)算完成,等待完成,檢索結(jié)果完成等方法。)
我們將每個(gè)任務(wù)的計(jì)算完成的結(jié)果都用 CompletableFuture 來(lái)表示,利用 CompletableFuture.allOf 匯聚成一個(gè)大的 CompletableFuture,那么利用 get()方法就可以阻塞。
- public class CompletableFutureParallel {
- private static final int CORE_POOL_SIZE = 4;
- private static final int MAX_POOL_SIZE = 12;
- private static final long KEEP_ALIVE_TIME = 5L;
- private final static int QUEUE_SIZE = 1600;
- protected final static ExecutorService THREAD_POOL = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_POOL_SIZE,
- KEEP_ALIVE_TIME, TimeUnit.SECONDS, new LinkedBlockingQueue<>(QUEUE_SIZE));
- public static void main(String[] args) throws InterruptedException, ExecutionException, TimeoutException {
- OrderInfo orderInfo = new OrderInfo();
- //CompletableFuture 的List
- List<CompletableFuture> futures = new ArrayList<>();
- futures.add(CompletableFuture.runAsync(() -> {
- System.out.println("當(dāng)前任務(wù)Customer,線(xiàn)程名字為:" + Thread.currentThread().getName());
- orderInfo.setCustomerInfo(new CustomerInfo());
- }, THREAD_POOL));
- futures.add(CompletableFuture.runAsync(() -> {
- System.out.println("當(dāng)前任務(wù)Discount,線(xiàn)程名字為:" + Thread.currentThread().getName());
- orderInfo.setDiscountInfo(new DiscountInfo());
- }, THREAD_POOL));
- futures.add( CompletableFuture.runAsync(() -> {
- System.out.println("當(dāng)前任務(wù)Food,線(xiàn)程名字為:" + Thread.currentThread().getName());
- orderInfo.setFoodListInfo(new FoodListInfo());
- }, THREAD_POOL));
- futures.add(CompletableFuture.runAsync(() -> {
- System.out.println("當(dāng)前任務(wù)Other,線(xiàn)程名字為:" + Thread.currentThread().getName());
- orderInfo.setOtherInfo(new OtherInfo());
- }, THREAD_POOL));
- CompletableFuture allDoneFuture = CompletableFuture.allOf(futures.toArray(new CompletableFuture[futures.size()]));
- allDoneFuture.get(10, TimeUnit.SECONDS);
- System.out.println(orderInfo);
- }
- }
可以看見(jiàn)我們使用 CompletableFuture 能很快的完成需求,當(dāng)然這還不夠。
Fork/Join
我們上面用 CompletableFuture 完成了對(duì)多組任務(wù)并行執(zhí)行,但是它依然是依賴(lài)我們的線(xiàn)程池。
在我們的線(xiàn)程池中使用的是阻塞隊(duì)列,也就是當(dāng)我們某個(gè)線(xiàn)程執(zhí)行完任務(wù)的時(shí)候需要通過(guò)這個(gè)阻塞隊(duì)列進(jìn)行,那么肯定會(huì)發(fā)生競(jìng)爭(zhēng),所以在 JDK 1.7 中提供了 ForkJoinTask 和 ForkJoinPool。
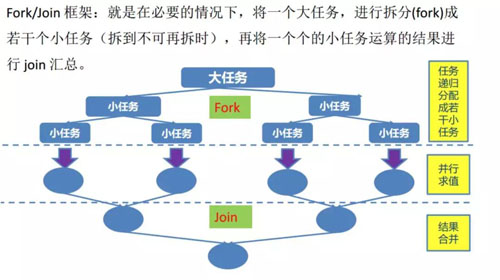
ForkJoinPool 中每個(gè)線(xiàn)程都有自己的工作隊(duì)列,并且采用 Work-Steal 算法防止線(xiàn)程饑餓。
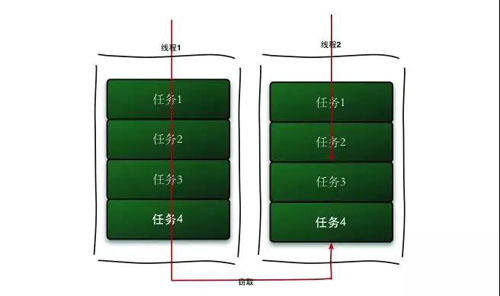
Worker 線(xiàn)程用 LIFO 的方法取出任務(wù),但是會(huì)用 FIFO 的方法去偷取別人隊(duì)列的任務(wù),這樣就減少了鎖的沖突。
網(wǎng)上這個(gè)框架的例子很多,我們看看如何使用代碼完成我們上面的下訂單需求:
- public class OrderTask extends RecursiveTask<OrderInfo> {
- @Override
- protected OrderInfo compute() {
- System.out.println("執(zhí)行"+ this.getClass().getSimpleName() + "線(xiàn)程名字為:" + Thread.currentThread().getName());
- // 定義其他五種并行TasK
- CustomerTask customerTask = new CustomerTask();
- TenantTask tenantTask = new TenantTask();
- DiscountTask discountTask = new DiscountTask();
- FoodTask foodTask = new FoodTask();
- OtherTask otherTask = new OtherTask();
- invokeAll(customerTask, tenantTask, discountTask, foodTask, otherTask);
- OrderInfo orderInfo = new OrderInfo(customerTask.join(), tenantTask.join(), discountTask.join(), foodTask.join(), otherTask.join());
- return orderInfo;
- }
- public static void main(String[] args) {
- ForkJoinPool forkJoinPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors() -1 );
- System.out.println(forkJoinPool.invoke(new OrderTask()));
- }
- }
- class CustomerTask extends RecursiveTask<CustomerInfo>{
- @Override
- protected CustomerInfo compute() {
- System.out.println("執(zhí)行"+ this.getClass().getSimpleName() + "線(xiàn)程名字為:" + Thread.currentThread().getName());
- return new CustomerInfo();
- }
- }
- class TenantTask extends RecursiveTask<TenantInfo>{
- @Override
- protected TenantInfo compute() {
- System.out.println("執(zhí)行"+ this.getClass().getSimpleName() + "線(xiàn)程名字為:" + Thread.currentThread().getName());
- return new TenantInfo();
- }
- }
- class DiscountTask extends RecursiveTask<DiscountInfo>{
- @Override
- protected DiscountInfo compute() {
- System.out.println("執(zhí)行"+ this.getClass().getSimpleName() + "線(xiàn)程名字為:" + Thread.currentThread().getName());
- return new DiscountInfo();
- }
- }
- class FoodTask extends RecursiveTask<FoodListInfo>{
- @Override
- protected FoodListInfo compute() {
- System.out.println("執(zhí)行"+ this.getClass().getSimpleName() + "線(xiàn)程名字為:" + Thread.currentThread().getName());
- return new FoodListInfo();
- }
- }
- class OtherTask extends RecursiveTask<OtherInfo>{
- @Override
- protected OtherInfo compute() {
- System.out.println("執(zhí)行"+ this.getClass().getSimpleName() + "線(xiàn)程名字為:" + Thread.currentThread().getName());
- return new OtherInfo();
- }
- }
我們定義一個(gè) Order Task 并且定義五個(gè)獲取信息的任務(wù),在 Compute 中分別 Fork 執(zhí)行這五個(gè)任務(wù),最后在將這五個(gè)任務(wù)的結(jié)果通過(guò) Join 獲得,最后完成我們的并行化的需求。
parallelStream
在 JDK 1.8 中提供了并行流的 API,當(dāng)我們使用集合的時(shí)候能很好的進(jìn)行并行處理。
下面舉了一個(gè)簡(jiǎn)單的例子從 1 加到 100:
- public class ParallelStream {
- public static void main(String[] args) {
- ArrayList<Integer> list = new ArrayList<Integer>();
- for (int i = 1; i <= 100; i++) {
- list.add(i);
- }
- LongAdder sum = new LongAdder();
- list.parallelStream().forEach(integer -> {
- // System.out.println("當(dāng)前線(xiàn)程" + Thread.currentThread().getName());
- sum.add(integer);
- });
- System.out.println(sum);
- }
- }
parallelStream 中底層使用的那一套也是 Fork/Join 的那一套,默認(rèn)的并發(fā)程度是可用 CPU 數(shù) -1。
分片
可以想象有這么一個(gè)需求,每天定時(shí)對(duì) ID 在某個(gè)范圍之間的用戶(hù)發(fā)券,比如這個(gè)范圍之間的用戶(hù)有幾百萬(wàn),如果給一臺(tái)機(jī)器發(fā)的話(huà),可能全部發(fā)完需要很久的時(shí)間。
所以分布式調(diào)度框架比如:elastic-job 都提供了分片的功能,比如你用 50 臺(tái)機(jī)器,那么 id%50 = 0 的在第 0 臺(tái)機(jī)器上;=1 的在第 1 臺(tái)機(jī)器上發(fā)券,那么我們的執(zhí)行時(shí)間其實(shí)就分?jǐn)偟搅瞬煌臋C(jī)器上了。
并行化注意事項(xiàng)
線(xiàn)程安全:在 parallelStream 中我們列舉的代碼中使用的是 LongAdder,并沒(méi)有直接使用我們的 Integer 和 Long,這個(gè)是因?yàn)樵诙嗑€(xiàn)程環(huán)境下 Integer 和 Long 線(xiàn)程不安全。所以線(xiàn)程安全我們需要特別注意。
合理參數(shù)配置:可以看見(jiàn)我們需要配置的參數(shù)比較多,比如我們的線(xiàn)程池的大小,等待隊(duì)列大小,并行度大小以及我們的等待超時(shí)時(shí)間等等。
我們都需要根據(jù)自己的業(yè)務(wù)不斷的調(diào)優(yōu)防止出現(xiàn)隊(duì)列不夠用或者超時(shí)時(shí)間不合理等等。
上面介紹了什么是并行化,并行化的各種歷史,在 Java 中如何實(shí)現(xiàn)并行化,以及并行化的注意事項(xiàng)。希望大家對(duì)并行化有個(gè)比較全面的認(rèn)識(shí)。
最后給大家提個(gè)兩個(gè)小問(wèn)題:
- 在我們并行化當(dāng)中有某個(gè)任務(wù)如果某個(gè)任務(wù)出現(xiàn)了異常應(yīng)該怎么辦?
- 在我們并行化當(dāng)中有某個(gè)任務(wù)的信息并不是強(qiáng)依賴(lài),也就是如果出現(xiàn)了問(wèn)題這部分信息我們也可以不需要,當(dāng)并行化的時(shí)候,這種任務(wù)出現(xiàn)了異常應(yīng)該怎么辦?