













送給DBA,讓數(shù)據(jù)庫(kù)自己解決繁瑣調(diào)參!
數(shù)據(jù)庫(kù)有很多參數(shù),比如MySQL有幾百個(gè)參數(shù),Oracle有上千個(gè)參數(shù)。這些參數(shù)控制著數(shù)據(jù)庫(kù)的方方面面,很大程度的影響了數(shù)據(jù)庫(kù)的性能。比如緩存容量和檢查點(diǎn)頻次。
DBA會(huì)花大量時(shí)間根據(jù)經(jīng)驗(yàn)來(lái)調(diào)優(yōu)數(shù)據(jù)庫(kù)的參數(shù),而公司需要花很大的價(jià)錢來(lái)雇資深的DBA。但是對(duì)于不同的硬件配置,不同的工作負(fù)載,對(duì)應(yīng)的參數(shù)文件都是不同的。DBA不能簡(jiǎn)單的重復(fù)使用之前調(diào)好的參數(shù)文件。這些復(fù)雜性令數(shù)據(jù)庫(kù)調(diào)優(yōu)變得更加困難。
為解決這些問(wèn)題,卡內(nèi)基梅隆大學(xué)數(shù)據(jù)庫(kù)小組的教授、學(xué)生和研究人員開發(fā)了一個(gè)數(shù)據(jù)庫(kù)自動(dòng)調(diào)參工具OtterTune,它能利用機(jī)器學(xué)習(xí)對(duì)數(shù)據(jù)庫(kù)的參數(shù)文件自動(dòng)化的調(diào)優(yōu),能利用已有的數(shù)據(jù)訓(xùn)練機(jī)器學(xué)習(xí)模型,進(jìn)而自動(dòng)化的推薦參數(shù)。它能很好的幫助DBA進(jìn)行數(shù)據(jù)庫(kù)調(diào)優(yōu),將DBA從復(fù)雜繁瑣的調(diào)參工作中解放出來(lái)。
以前網(wǎng)上就有對(duì)OtterTune的報(bào)道,標(biāo)題都比較嚇人。比如這篇:運(yùn)維要失業(yè)了? 機(jī)器學(xué)習(xí)可自動(dòng)優(yōu)化你的數(shù)據(jù)庫(kù)管理系統(tǒng)[1]。
OtterTune的目的是為了幫助DBA,讓數(shù)據(jù)庫(kù)部署和調(diào)優(yōu)更加容易,用機(jī)器來(lái)代替數(shù)據(jù)庫(kù)調(diào)參這個(gè)冗繁但又很重要的工作,甚至不需要專業(yè)知識(shí)也能完成。
OtterTune現(xiàn)在完全開源,Github上的版本就可以使用[2]。這個(gè)文檔中有一個(gè)步驟較全的例子可以上手,在AWS的m5d.xlarge機(jī)子上調(diào)優(yōu)PostgreSQL 9.6數(shù)據(jù)庫(kù),吞吐量從默認(rèn)參數(shù)文件的每秒約500個(gè)事務(wù)提高到每秒約1000個(gè)事務(wù),有興趣的朋友不妨試一試。
不過(guò)驚喜的是,我們發(fā)現(xiàn)這個(gè)通用模型在業(yè)界的很多地方都有真實(shí)的應(yīng)用,不僅能調(diào)優(yōu)數(shù)據(jù)庫(kù)的參數(shù),還能夠調(diào)優(yōu)操作系統(tǒng)內(nèi)核的參數(shù),甚至可以嘗試調(diào)優(yōu)機(jī)器學(xué)習(xí)模型的參數(shù)。比如以下場(chǎng)景:
- 某歐洲銀行需要自動(dòng)化調(diào)優(yōu)數(shù)據(jù)庫(kù)集群的參數(shù)以提高性能,減少人工成本。
- 某大型云廠商需要在不影響性能的前提下盡量調(diào)低分配的資源(如內(nèi)存), 減少硬件成本。
- 某紐約高頻交易公司需要調(diào)優(yōu)機(jī)器的操作系統(tǒng)參數(shù)以優(yōu)化機(jī)器性能,減少延遲,從而增加利潤(rùn)。
本文將介紹OtterTune的內(nèi)部原理,以及OtterTune的一些進(jìn)展和嘗試,如用深度強(qiáng)化學(xué)習(xí)來(lái)調(diào)優(yōu)數(shù)據(jù)庫(kù)參數(shù)。
由于本人水平有限,寫的不對(duì)的地方歡迎大家指正。更多資料請(qǐng)參考2017年SIGMOD[3]和2018年VLDB的論文[4]。
一、客戶端和服務(wù)端
OtterTune分為客戶端和服務(wù)端。目標(biāo)數(shù)據(jù)庫(kù)是用戶需要調(diào)優(yōu)參數(shù)的數(shù)據(jù)庫(kù):
- OtterTune的客戶端安裝在目標(biāo)數(shù)據(jù)庫(kù)所在機(jī)器上,收集目標(biāo)數(shù)據(jù)庫(kù)的統(tǒng)計(jì)信息,并上傳到服務(wù)端。
- 服務(wù)端一般配置在云上,它收到客戶端的數(shù)據(jù),訓(xùn)練機(jī)器學(xué)習(xí)模型并推薦參數(shù)文件。
客戶端接到推薦的參數(shù)文件后,配置到目標(biāo)數(shù)據(jù)庫(kù)上,測(cè)量其性能。以上步驟可以重復(fù)進(jìn)行直到用戶對(duì)OtterTune推薦的參數(shù)文件滿意。
當(dāng)用戶配置好OtterTune時(shí),它能自動(dòng)的持續(xù)推薦參數(shù)文件并把所得結(jié)果上傳到服務(wù)端可視化出來(lái),而不需要DBA的干預(yù)。這樣能很大簡(jiǎn)化DBA的工作,比如DBA可以配置好OtterTune后回家睡覺(jué),第二天早上OtterTune可能就在一晚上的嘗試中找到了好的參數(shù)文件。
而OtterTune嘗試的所有參數(shù)文件及對(duì)應(yīng)的數(shù)據(jù)庫(kù)性能和統(tǒng)計(jì)信息都能在服務(wù)端的可視化界面上輕易找到。
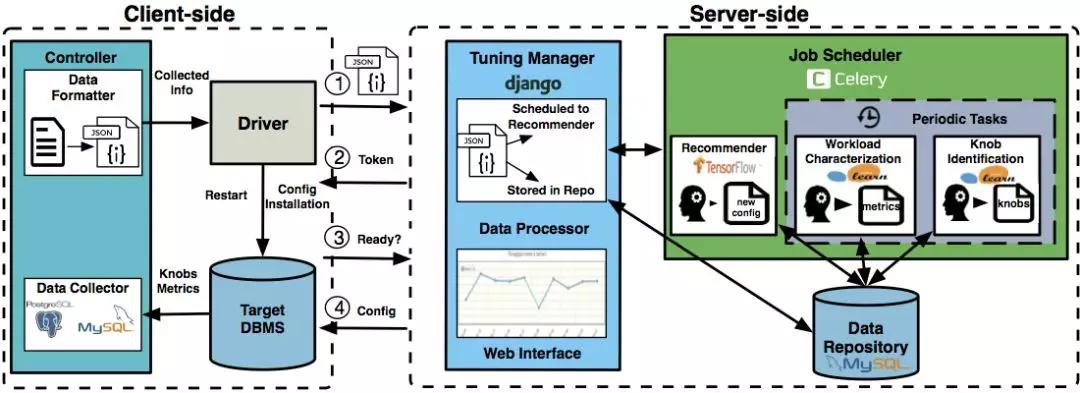
上圖是OtterTune的整體架構(gòu):
- 客戶端中controller由Java實(shí)現(xiàn),用JDBC訪問(wèn)目標(biāo)數(shù)據(jù)庫(kù)來(lái)收集其統(tǒng)計(jì)信息;driver則用了Python的fabric,主要與服務(wù)端交互。
- 服務(wù)端用了Django來(lái)構(gòu)建網(wǎng)站,并用Celery來(lái)調(diào)度機(jī)器學(xué)習(xí)任務(wù);機(jī)器學(xué)習(xí)則調(diào)了tensorflow和sklearn。
關(guān)于OtterTune架構(gòu)更詳細(xì)的內(nèi)容可以參考2018 VLDB的demo paper[4].
二、隨機(jī)采樣
為了敘述方便,我們不妨假設(shè)參數(shù)文件中有10個(gè)重要參數(shù)需要調(diào)優(yōu)。
我們將參數(shù)文件表示為:X=(x1,x2,…x10)
對(duì)應(yīng)的數(shù)據(jù)庫(kù)性能為Y。Y可以是吞吐量,延遲時(shí)間,也可以是用戶自己定義的測(cè)量量。
我們假設(shè)目標(biāo)測(cè)量量是延遲時(shí)間。則我們需要做的是調(diào)整這10個(gè)數(shù)據(jù)庫(kù)參數(shù)的值,使得數(shù)據(jù)庫(kù)的延遲盡可能少。即找到合適的X,使Y盡可能小。一個(gè)好的參數(shù)文件會(huì)降低數(shù)據(jù)庫(kù)的延遲,即X對(duì)應(yīng)的Y越小,我們說(shuō)X越好。
最簡(jiǎn)單和直觀的方法便是隨機(jī)的進(jìn)行嘗試,即給這10個(gè)要調(diào)的參數(shù)較大和較小值,在這范圍內(nèi)隨機(jī)地選擇值進(jìn)行嘗試。顯然這樣隨機(jī)的方法并不高效,可能需要試很多次才能得到好的參數(shù)文件。OtterTune也支持這種隨機(jī)方法以在沒(méi)有訓(xùn)練數(shù)據(jù)時(shí)收集數(shù)據(jù)。
相比隨機(jī)采樣,還有一種更有效率的采樣方法叫做拉丁超立方采樣。
比如在0到3之間隨機(jī)找3個(gè)數(shù),簡(jiǎn)單隨機(jī)抽樣可能找的三個(gè)數(shù)都在0到1之間。而拉丁超立方采樣則在0到1間找一個(gè)數(shù),1到2間找一個(gè)數(shù),2到3間找一個(gè)數(shù),更加分散。
推到高維也是類似的情況。如下圖是二維的情形,x1和x2取值都在0到1之間,用拉丁超立方采樣來(lái)取5個(gè)樣本點(diǎn),先將x1和x2分成不同的范圍,再取樣本點(diǎn)使得每一行中只有一個(gè)樣本點(diǎn),每一列中也只有一個(gè)樣本點(diǎn)。這樣能避免多個(gè)樣本點(diǎn)出現(xiàn)在相近的范圍內(nèi),使其更加分散。
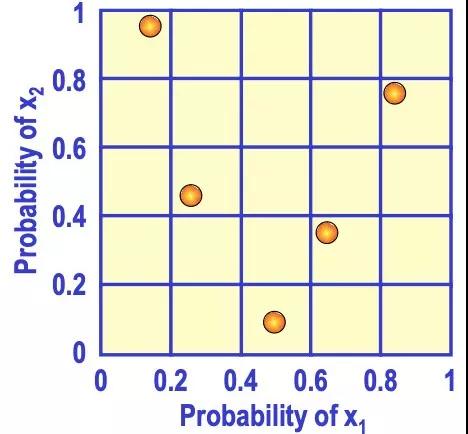
對(duì)于OtterTune來(lái)說(shuō),簡(jiǎn)單隨機(jī)采樣嘗試的參數(shù)文件可能更集中和相似,而拉丁超立方采樣嘗試的參數(shù)文件更分散和不同。顯然后者能給我們更多的信息,因?yàn)閲L試相似的參數(shù)文件很可能得到的數(shù)據(jù)庫(kù)性能也相似,信息量少,而嘗試很不同的參數(shù)文件能更快的找到效果好的一個(gè)。
三、高斯過(guò)程回歸
上述的采樣方法并沒(méi)有利用機(jī)器學(xué)習(xí)模型對(duì)參數(shù)文件的效果進(jìn)行預(yù)測(cè)。
- 當(dāng)OtterTune沒(méi)有數(shù)據(jù)來(lái)訓(xùn)練模型時(shí),可以利用上述方法收集初始數(shù)據(jù)。
- 當(dāng)我們有足夠的數(shù)據(jù)(X,Y)時(shí),OtterTune訓(xùn)練機(jī)器學(xué)習(xí)模型進(jìn)行回歸,即估計(jì)出函數(shù)f:X→Y,使得對(duì)于參數(shù)文件X,用f(X)來(lái)估計(jì)數(shù)據(jù)庫(kù)延遲Y的值。則問(wèn)題變?yōu)閷ふ液线m的X,使f(X)的值盡量小。這樣我們?cè)趂上面做梯度下降即可找出合適的X。
如下圖所示,橫坐標(biāo)是兩個(gè)參數(shù)——緩存大小和日志文件大小,縱坐標(biāo)是數(shù)據(jù)庫(kù)延遲(越低越好):
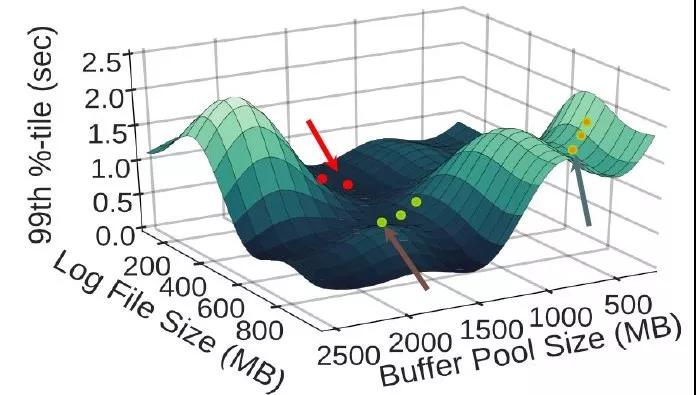
OtterTune用回歸模型估計(jì)出了f,即給定這兩個(gè)參數(shù)值,估計(jì)出其對(duì)應(yīng)的數(shù)據(jù)庫(kù)延遲。接著用梯度下降找到合適的參數(shù)值使延遲盡可能低。
OtterTune用高斯過(guò)程回歸來(lái)估計(jì)上述的函數(shù)f。用高斯回歸的好處之一是它不僅能在給定X時(shí)估計(jì)對(duì)應(yīng)的Y值,還能估計(jì)它的置信區(qū)間。
這能恰當(dāng)?shù)目坍嬚{(diào)參的情況:對(duì)于同樣的參數(shù)文件X, 在數(shù)據(jù)庫(kù)上多次跑相同的查詢時(shí),由于誤差緣故,每次得到的數(shù)據(jù)庫(kù)性能也可能不一樣。比如同樣的參數(shù)文件和查詢語(yǔ)句,這次執(zhí)行的數(shù)據(jù)庫(kù)延遲是1.8秒,下次執(zhí)行的延遲可能是2秒,但每次得到的延遲很大概率是相近的。
高斯過(guò)程回歸能估計(jì)出均值m(X)和標(biāo)準(zhǔn)差s(X),進(jìn)而能求出置信區(qū)間。比如上述例子中,通過(guò)回歸我們估計(jì)其延遲的均值是1.9秒,標(biāo)準(zhǔn)差是0.1秒,則其95%的概率在1.7秒和2.1秒之間。
再來(lái)說(shuō)說(shuō)探索(exploration)和利用(exploitation):
- 探索即在數(shù)據(jù)點(diǎn)不多的未知區(qū)域探索新的點(diǎn)。
- 利用即在數(shù)據(jù)點(diǎn)足夠多的已知區(qū)域利用這些數(shù)據(jù)訓(xùn)練機(jī)器學(xué)習(xí)模型進(jìn)行估計(jì),再找出好的點(diǎn)。
比如說(shuō)我們已知10個(gè)數(shù)據(jù)點(diǎn)(X,Y),有9個(gè)點(diǎn)的X在0到1之間,有1個(gè)點(diǎn)的X在1到2之間。X在0到1之間的數(shù)據(jù)點(diǎn)較多,可以利用這些數(shù)據(jù)點(diǎn)進(jìn)行回歸來(lái)估計(jì)f:X->Y,再利用f來(lái)找到合適的X使估計(jì)的Y值盡量好,這個(gè)過(guò)程即為利用。
而探索則是嘗試未知區(qū)域新的點(diǎn),如X在1到2間的點(diǎn)只有一個(gè)已知點(diǎn),信息很少,很難估計(jì)f。我們?cè)?到2間選一個(gè)X點(diǎn)進(jìn)行嘗試,雖然可能得到的效果不好,但能增加該區(qū)域內(nèi)的信息量。當(dāng)該區(qū)域內(nèi)已知點(diǎn)足夠多時(shí)便能利用回歸找到好的點(diǎn)了。
OtterTune推薦的過(guò)程中,既要探索新的區(qū)域,也要利用已知區(qū)域的數(shù)據(jù)進(jìn)行推薦。即需要平衡探索和利用,否則可能會(huì)陷入局部較優(yōu)而無(wú)法找到全局較優(yōu)的點(diǎn)。比如一直利用已知區(qū)域的數(shù)據(jù)來(lái)推薦,雖然能找到這個(gè)區(qū)域較好的點(diǎn),但未知區(qū)域可能有效果更好的點(diǎn)未被發(fā)現(xiàn)。
如何很好的平衡探索和利用一直是個(gè)復(fù)雜的問(wèn)題,既要求能盡量找到好的點(diǎn),又要求用盡量少的次數(shù)找到這個(gè)點(diǎn)。
而OtterTune采用的高斯過(guò)程回歸能很好的解決這個(gè)問(wèn)題。核心思想是當(dāng)數(shù)據(jù)足夠多時(shí),我們利用這些數(shù)據(jù)推薦;而當(dāng)缺少數(shù)據(jù)時(shí),我們?cè)邳c(diǎn)最少的區(qū)域進(jìn)行探索,探索最未知的區(qū)域能給我們的信息量。
以上利用了高斯過(guò)程回歸的特性:它會(huì)估計(jì)出均值m(X)和標(biāo)準(zhǔn)差s(X),若X周圍的數(shù)據(jù)不多,則它估計(jì)的標(biāo)準(zhǔn)差s(X)會(huì)偏大,直觀的理解是若數(shù)據(jù)不多,則不確定性會(huì)大,體現(xiàn)在標(biāo)準(zhǔn)差偏大。反之,數(shù)據(jù)足夠時(shí),標(biāo)準(zhǔn)差會(huì)偏小,因?yàn)椴淮_定性減少。
而OtterTune用置信區(qū)間上界Upper Confidence Bound來(lái)平衡探索和利用。
不妨假設(shè)我們需要找X使Y值盡可能大。則U(X) = m(X) + k*s(X), 其中k > 0是可調(diào)的系數(shù)。我們只要找X使U(X)盡可能大即可。
- 若U(X)大,則可能m(X)大,也可能s(X)大。
- 若s(X)大,則說(shuō)明X周圍數(shù)據(jù)不多,OtterTune在探索未知區(qū)域新的點(diǎn)。
- 若m(X)大,即估計(jì)的Y值均值大, 則OtterTune在利用已知數(shù)據(jù)找到效果好的點(diǎn)。公式中系數(shù)k影響著探索和利用的比例,k越大,越鼓勵(lì)探索新的區(qū)域。
四、有數(shù)據(jù)和沒(méi)數(shù)據(jù)
OtterTune用來(lái)訓(xùn)練模型的數(shù)據(jù)好壞很大程度上影響了其最終效果。只要有合適的訓(xùn)練數(shù)據(jù),一般OtterTune前幾次推薦的參數(shù)文件就能得到理想的效果。
而當(dāng)缺少訓(xùn)練數(shù)據(jù)(或數(shù)據(jù)集中),甚至沒(méi)有任何之前的數(shù)據(jù)時(shí),OtterTune又該如何處理?
當(dāng)OtterTune沒(méi)有任何數(shù)據(jù)時(shí),高斯過(guò)程回歸也能有效的在盡量少的次數(shù)內(nèi)找到好的參數(shù)文件。當(dāng)數(shù)據(jù)少時(shí),OtterTune傾向探索而非利用,而每次探索新的參數(shù)文件時(shí)都能盡量的增加信息量,從而減少探索的次數(shù)。
這種方法比隨機(jī)采樣和拉丁超立方采樣都要高效。同時(shí)OtterTune也可先用拉丁超立方采樣選取少量的一些參數(shù)文件進(jìn)行嘗試作為初始數(shù)據(jù),之后再用高斯過(guò)程回歸進(jìn)行推薦。
其實(shí)在OtterTune之前,有系統(tǒng)iTuned[5]就用高斯過(guò)程回歸在沒(méi)有數(shù)據(jù)時(shí)推薦參數(shù)文件。
而OtterTune的改進(jìn)是利用之前收集的數(shù)據(jù)進(jìn)行推薦以大幅度減少嘗試的次數(shù)和等待時(shí)間,提高推薦效果。
想想看當(dāng)OtterTune的一個(gè)服務(wù)端配置到云上,而多個(gè)客戶端進(jìn)行訪問(wèn)時(shí),OtterTune會(huì)將所有用戶嘗試的參數(shù)文件和對(duì)應(yīng)的性能數(shù)據(jù)存下來(lái)進(jìn)行利用。這意味著用OtterTune的人越多,用的時(shí)間越長(zhǎng),它收集的訓(xùn)練數(shù)據(jù)越多,推薦效果越好。
除此之外,OtterTune還利用Lasso回歸來(lái)自動(dòng)的選取需要調(diào)整的重要參數(shù)。數(shù)據(jù)庫(kù)有成百上千的參數(shù),而我們只要調(diào)其中重要的幾個(gè),需要調(diào)整哪些參數(shù)可以根據(jù)DBA的經(jīng)驗(yàn),同時(shí)OtterTune也利用機(jī)器學(xué)習(xí)將參數(shù)的重要性排序,從而選出最重要的幾個(gè)參數(shù)。
另外對(duì)于不同的工作負(fù)載,對(duì)應(yīng)的參數(shù)文件也不同。如OLTP工作負(fù)載通常是很多個(gè)簡(jiǎn)單的查詢(如insert,delete),而OLAP工作負(fù)載通常是幾個(gè)復(fù)雜查詢(通常有多個(gè)表的join)。對(duì)于OLAP和OLTP,他們需要調(diào)整的參數(shù)和優(yōu)值都不相同。
OtterTune現(xiàn)在的做法是用一些系統(tǒng)的統(tǒng)計(jì)量(如讀/寫的字節(jié)數(shù))來(lái)刻畫工作負(fù)載,在已有數(shù)據(jù)中找到和用戶工作負(fù)載最相似的一個(gè),然后用最相似的工作負(fù)載對(duì)應(yīng)的數(shù)據(jù)進(jìn)行推薦。
五、深度強(qiáng)化學(xué)習(xí)
在OtterTune的進(jìn)展中,我們嘗試了深度強(qiáng)化學(xué)習(xí)的方法來(lái)進(jìn)行數(shù)據(jù)庫(kù)調(diào)參,因?yàn)槲覀儼l(fā)現(xiàn)數(shù)據(jù)庫(kù)調(diào)參的過(guò)程能很好的刻畫成強(qiáng)化學(xué)習(xí)的問(wèn)題。
強(qiáng)化學(xué)習(xí)問(wèn)題中有狀態(tài)、動(dòng)作,以及環(huán)境所給予的反饋。
如下圖所示,整個(gè)過(guò)程是在當(dāng)前狀態(tài)(st)和環(huán)境的反饋(rt)下做動(dòng)作(at),然后環(huán)境會(huì)產(chǎn)生下一狀態(tài)(st+1)和反饋(rt+1),再進(jìn)行下一個(gè)動(dòng)作(at+1)。
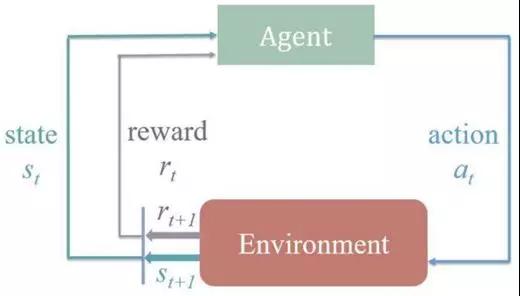
數(shù)據(jù)庫(kù)調(diào)參過(guò)程中,狀態(tài)即是參數(shù)文件,動(dòng)作即是調(diào)整某個(gè)參數(shù)的值,而反饋即是參數(shù)文件下數(shù)據(jù)庫(kù)的性能。
所以我們對(duì)于當(dāng)前的參數(shù)文件,調(diào)整某個(gè)參數(shù)的值,而得到新的參數(shù)文件,對(duì)這個(gè)新的參數(shù)文件做測(cè)試得到對(duì)應(yīng)的數(shù)據(jù)庫(kù)性能,再根據(jù)性能的好壞繼續(xù)調(diào)整參數(shù)的值。
這樣數(shù)據(jù)庫(kù)調(diào)參的過(guò)程就被很好的刻畫成強(qiáng)化學(xué)習(xí)的問(wèn)題,而深度強(qiáng)化學(xué)習(xí)即是其中的狀態(tài)或動(dòng)作由神經(jīng)網(wǎng)絡(luò)來(lái)表示。
我們用了Deep Deterministic Policy Gradient (DDPG)算法,主要是因?yàn)镈DPG能允許動(dòng)作可以在連續(xù)的區(qū)間上取值。對(duì)于調(diào)參來(lái)說(shuō),動(dòng)作即是調(diào)整某個(gè)參數(shù)的值,比如調(diào)整內(nèi)存容量,DDPG允許我們嘗試128MB到16GB的任意值,這個(gè)區(qū)間是連續(xù)的。
而很多別的算法只允許動(dòng)作在離散區(qū)間上,比如只允許取幾個(gè)值中的一個(gè)值。通過(guò)實(shí)現(xiàn)和優(yōu)化DDPG,最終深度強(qiáng)化學(xué)習(xí)推薦出的參數(shù)文件與高斯過(guò)程回歸推薦出的效果相似。但我們發(fā)現(xiàn)之前的高斯過(guò)程回歸(GPR)更有優(yōu)勢(shì),能用更少的時(shí)間和次數(shù)找到滿意的參數(shù)文件。
如下圖中所示,我們跑了TPC-H基準(zhǔn)中的一條查詢(Query 13),OtterTune一次次的推薦參數(shù)文件直到其達(dá)到好的效果(即對(duì)應(yīng)的數(shù)據(jù)庫(kù)延遲變低)。
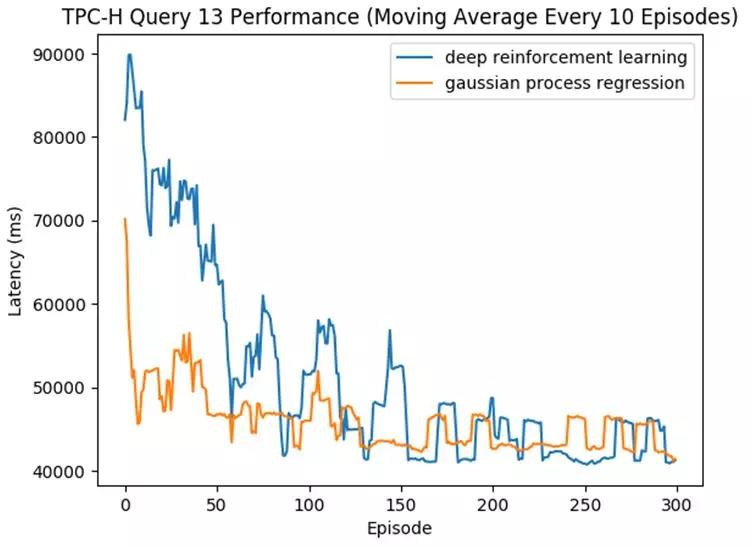
該圖橫坐標(biāo)是推薦的次數(shù),縱坐標(biāo)是數(shù)據(jù)庫(kù)的延遲,延遲越低越好。藍(lán)線是深度強(qiáng)化學(xué)習(xí),而黃線代表高斯過(guò)程回歸模型。
可見(jiàn)兩個(gè)模型最終推薦出的文件效果相似,但高斯過(guò)程回歸用了更少的次數(shù)便收斂,推薦出了好的參數(shù)文件。而深度強(qiáng)化學(xué)習(xí)需要嘗試更多的次數(shù)才能達(dá)到類似效果。
我們發(fā)現(xiàn):
- DDPG算法模型有一些參數(shù)也需要調(diào)整,而這些參數(shù)對(duì)效果的影響很大。調(diào)整算法模型的參數(shù)也是個(gè)費(fèi)時(shí)費(fèi)力的過(guò)程。這樣就陷入尷尬的局面,OtterTune是用來(lái)自動(dòng)調(diào)整數(shù)據(jù)庫(kù)參數(shù)的工具,而OtterTune自己算法模型的參數(shù)也需要調(diào)整。相比而言,GPR的模型參數(shù)可以自動(dòng)的進(jìn)行調(diào)整,從而實(shí)現(xiàn)OtterTune真正的自動(dòng)化。
- GPR能用Upper Confidence Bound更好的平衡探索(exploration)和利用(exploitation),相比DDPG更加高效。 這在沒(méi)有或缺少數(shù)據(jù)的情況下,GPR能用更少的次數(shù)找到好的參數(shù)文件。
- DDPG是更加復(fù)雜的模型,其中還有神經(jīng)網(wǎng)絡(luò),可解釋性差。需要更多的數(shù)據(jù)和更長(zhǎng)的時(shí)間來(lái)訓(xùn)練和收斂。雖然能達(dá)到和GPR一樣的推薦效果,但往往需要更多的次數(shù)和更長(zhǎng)的時(shí)間,意味著用戶需要等更久才能得到滿意的參數(shù)文件。
六、展望
對(duì)于數(shù)據(jù)庫(kù)來(lái)說(shuō),有很多部分都能嘗試與機(jī)器學(xué)習(xí)結(jié)合。比如預(yù)測(cè)數(shù)據(jù)庫(kù)一段時(shí)間的工作負(fù)載,如通過(guò)挖掘數(shù)據(jù)庫(kù)的日志來(lái)做自動(dòng)預(yù)警,再到更核心的部分,如學(xué)習(xí)數(shù)據(jù)庫(kù)索引,甚至幫助優(yōu)化器做查詢優(yōu)化。
OtterTune專注的參數(shù)文件調(diào)優(yōu)只是其中的一部分。由于OtterTune和數(shù)據(jù)庫(kù)的交互只是一個(gè)參數(shù)文件,這使得該工具更加通用,理論上能適用于所有的數(shù)據(jù)庫(kù)。
當(dāng)要調(diào)參一個(gè)新的數(shù)據(jù)庫(kù)時(shí),我們只需要給OtterTune該數(shù)據(jù)庫(kù)的一些參數(shù)和統(tǒng)計(jì)量信息即可,不需要去改動(dòng)這個(gè)數(shù)據(jù)庫(kù)的任何代碼。
再者,OtterTune的通用框架也可以用于其他系統(tǒng)的調(diào)參,如我們嘗試用OtterTune來(lái)調(diào)優(yōu)操作系統(tǒng)的內(nèi)核參數(shù)也取得了不錯(cuò)的效果。
現(xiàn)在的OtterTune仍有要改進(jìn)的地方:
- 比如假定了硬件配置需要一樣,而我們希望OtterTune能利用在不同的硬件配置上的數(shù)據(jù)來(lái)訓(xùn)練模型進(jìn)行推薦。
- 再比如現(xiàn)在OtterTune每次只推薦一個(gè)文件,當(dāng)有多個(gè)相同機(jī)器時(shí),我們希望一次推薦多個(gè)文件并行的去嘗試,這樣能加快推薦速度。
另外還可以嘗試與其他部分的機(jī)器學(xué)習(xí)方法結(jié)合,比如可以先用機(jī)器學(xué)習(xí)方法預(yù)測(cè)工作負(fù)載,再根據(jù)預(yù)測(cè)的工作負(fù)載提前調(diào)優(yōu)參數(shù)文件。
用機(jī)器學(xué)習(xí)來(lái)優(yōu)化系統(tǒng)是最近很火很前沿的一個(gè)話題,無(wú)論是在工業(yè)界還是在學(xué)術(shù)界。
全球數(shù)據(jù)庫(kù)廠商Oracle如今的賣點(diǎn)便是autonomous database[6] ,即自適應(yīng)性數(shù)據(jù)庫(kù),利用機(jī)器學(xué)習(xí)來(lái)自動(dòng)優(yōu)化數(shù)據(jù)庫(kù)來(lái)減少DBA的干預(yù),要知道在美國(guó)雇一個(gè)資深的DBA是多么困難的一件事。Oracle投入大量的專家和資金來(lái)做這件事便證明了它的工業(yè)價(jià)值。
學(xué)術(shù)上,一些ML和系統(tǒng)的大佬在前兩年開了一個(gè)新的會(huì)議叫SysML[7],專注于機(jī)器學(xué)習(xí)和系統(tǒng)的交叉領(lǐng)域。更不用說(shuō)越來(lái)越多的相關(guān)論文,比如卡內(nèi)基梅隆大學(xué)的OtterTune,再如MIT和谷歌開發(fā)的用神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)數(shù)據(jù)庫(kù)的索引[8]。
以谷歌Jeff Dean在演講中的話結(jié)尾:
計(jì)算機(jī)系統(tǒng)中充滿了經(jīng)驗(yàn)性的規(guī)則,到處是在用啟發(fā)式的方法來(lái)做決定,而用機(jī)器學(xué)習(xí)來(lái)學(xué)系統(tǒng)的核心部分會(huì)讓其變得更好更加自適應(yīng),這個(gè)領(lǐng)域充滿著機(jī)會(huì)[9]。
參考
[1]運(yùn)維要失業(yè)了? 機(jī)器學(xué)習(xí)可自動(dòng)優(yōu)化你的數(shù)據(jù)庫(kù)管理系統(tǒng)
www.sohu.com/a/146016004_465914
[2]https://github.com/cmu-db/ottertune
[3]Automatic Database Management System Tuning Through Large-scale Machine Learning. Dana Van Aken, Andrew Pavlo, Geoffrey J. Gordon, Bohan Zhang. SIGMOD 2017
[4]A Demonstration of the OtterTune Automatic Database Management System Tuning Service. Bohan Zhang, Dana Van Aken, Justin Wang, Tao Dai, Shuli Jiang, Siyuan Sheng, Andrew Pavlo, Geoffrey J. Gordon. VLDB 2018
[5]Tuning Database Configuration Parameters with iTuned. Songyun Duan, Vamsidhar Thummala, Shivnath Babu. VLDB 2009
[6]https://www.oracle.com/database/what-is-autonomous-database.html
[7]https://www.sysml.cc/
[8]The Case for Learned Index Structures. Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, Neoklis Polyzotis. SIGMOD 2018
[9]http://learningsys.org/nips17/assets/slides/dean-nips17.pdf














