深度解析 Flink 是如何管理好內(nèi)存的?
前言
如今,許多用于分析大型數(shù)據(jù)集的開(kāi)源系統(tǒng)都是用 Java 或者是基于 JVM 的編程語(yǔ)言實(shí)現(xiàn)的。最著名的例子是 Apache Hadoop,還有較新的框架,如 Apache Spark、Apache Drill、Apache Flink。基于 JVM 的數(shù)據(jù)分析引擎面臨的一個(gè)常見(jiàn)挑戰(zhàn)就是如何在內(nèi)存中存儲(chǔ)大量的數(shù)據(jù)(包括緩存和高效處理)。合理的管理好 JVM 內(nèi)存可以將 難以配置且不可預(yù)測(cè)的系統(tǒng) 與 少量配置且穩(wěn)定運(yùn)行的系統(tǒng)區(qū)分開(kāi)來(lái)。
在這篇文章中,我們將討論 Apache Flink 如何管理內(nèi)存,討論其自定義序列化與反序列化機(jī)制,以及它是如何操作二進(jìn)制數(shù)據(jù)的。
數(shù)據(jù)對(duì)象直接放在堆內(nèi)存中
在 JVM 中處理大量數(shù)據(jù)最直接的方式就是將這些數(shù)據(jù)做為對(duì)象存儲(chǔ)在堆內(nèi)存中,然后直接在內(nèi)存中操作這些數(shù)據(jù),如果想進(jìn)行排序則就是對(duì)對(duì)象列表進(jìn)行排序。然而這種方法有一些明顯的缺點(diǎn),首先,在頻繁的創(chuàng)建和銷(xiāo)毀大量對(duì)象的時(shí)候,監(jiān)視和控制堆內(nèi)存的使用并不是一件很簡(jiǎn)單的事情。如果對(duì)象分配過(guò)多的話,那么會(huì)導(dǎo)致內(nèi)存過(guò)度使用,從而觸發(fā) OutOfMemoryError,導(dǎo)致 JVM 進(jìn)程直接被殺死。另一個(gè)方面就是因?yàn)檫@些對(duì)象大都是生存在新生代,當(dāng) JVM 進(jìn)行垃圾回收時(shí),垃圾收集的開(kāi)銷(xiāo)很容易達(dá)到 50% 甚至更多。最后就是 Java 對(duì)象具有一定的空間開(kāi)銷(xiāo)(具體取決于 JVM 和平臺(tái))。對(duì)于具有許多小對(duì)象的數(shù)據(jù)集,這可以顯著減少有效可用的內(nèi)存量。如果你精通系統(tǒng)設(shè)計(jì)和系統(tǒng)調(diào)優(yōu),你可以根據(jù)系統(tǒng)進(jìn)行特定的參數(shù)調(diào)整,可以或多或少的控制出現(xiàn) OutOfMemoryError 的次數(shù)和避免堆內(nèi)存的過(guò)多使用,但是這種設(shè)置和調(diào)優(yōu)的作用有限,尤其是在數(shù)據(jù)量較大和執(zhí)行環(huán)境發(fā)生變化的情況下。
Flink 是怎么做的?
Apache Flink 起源于一個(gè)研究項(xiàng)目,該項(xiàng)目旨在結(jié)合基于 MapReduce 的系統(tǒng)和并行數(shù)據(jù)庫(kù)系統(tǒng)的最佳技術(shù)。在此背景下,F(xiàn)link 一直有自己的內(nèi)存數(shù)據(jù)處理方法。Flink 將對(duì)象序列化為固定數(shù)量的預(yù)先分配的內(nèi)存段,而不是直接把對(duì)象放在堆內(nèi)存上。它的 DBMS 風(fēng)格的排序和連接算法盡可能多地對(duì)這個(gè)二進(jìn)制數(shù)據(jù)進(jìn)行操作,以此將序列化和反序列化開(kāi)銷(xiāo)降到最低。如果需要處理的數(shù)據(jù)多于可以保存在內(nèi)存中的數(shù)據(jù),F(xiàn)link 的運(yùn)算符會(huì)將部分?jǐn)?shù)據(jù)溢出到磁盤(pán)。事實(shí)上,很多Flink 的內(nèi)部實(shí)現(xiàn)看起來(lái)更像是 C / C ++,而不是普通的 Java。下圖概述了 Flink 如何在內(nèi)存段中存儲(chǔ)序列化數(shù)據(jù)并在必要時(shí)溢出到磁盤(pán):
存的?")
Flink 的主動(dòng)內(nèi)存管理和操作二進(jìn)制數(shù)據(jù)有幾個(gè)好處:
- 內(nèi)存安全執(zhí)行和高效的核外算法 由于分配的內(nèi)存段的數(shù)量是固定的,因此監(jiān)控剩余的內(nèi)存資源是非常簡(jiǎn)單的。在內(nèi)存不足的情況下,處理操作符可以有效地將更大批的內(nèi)存段寫(xiě)入磁盤(pán),后面再將它們讀回到內(nèi)存。因此,OutOfMemoryError 就有效的防止了。
- 減少垃圾收集壓力 因?yàn)樗虚L(zhǎng)生命周期的數(shù)據(jù)都是在 Flink 的管理內(nèi)存中以二進(jìn)制表示的,所以所有數(shù)據(jù)對(duì)象都是短暫的,甚至是可變的,并且可以重用。短生命周期的對(duì)象可以更有效地進(jìn)行垃圾收集,這大大降低了垃圾收集的壓力。現(xiàn)在,預(yù)先分配的內(nèi)存段是 JVM 堆上的長(zhǎng)期存在的對(duì)象,為了降低垃圾收集的壓力,F(xiàn)link 社區(qū)正在積極地將其分配到堆外內(nèi)存。這種努力將使得 JVM 堆變得更小,垃圾收集所消耗的時(shí)間將更少。
- 節(jié)省空間的數(shù)據(jù)存儲(chǔ) Java 對(duì)象具有存儲(chǔ)開(kāi)銷(xiāo),如果數(shù)據(jù)以二進(jìn)制的形式存儲(chǔ),則可以避免這種開(kāi)銷(xiāo)。
- 高效的二進(jìn)制操作和緩存敏感性 在給定合適的二進(jìn)制表示的情況下,可以有效地比較和操作二進(jìn)制數(shù)據(jù)。此外,二進(jìn)制表示可以將相關(guān)值、哈希碼、鍵和指針等相鄰地存儲(chǔ)在內(nèi)存中。這使得數(shù)據(jù)結(jié)構(gòu)通常具有更高效的緩存訪問(wèn)模式。
主動(dòng)內(nèi)存管理的這些特性在用于大規(guī)模數(shù)據(jù)分析的數(shù)據(jù)處理系統(tǒng)中是非常可取的,但是要實(shí)現(xiàn)這些功能的代價(jià)也是高昂的。要實(shí)現(xiàn)對(duì)二進(jìn)制數(shù)據(jù)的自動(dòng)內(nèi)存管理和操作并非易事,使用 java.util.HashMap 比實(shí)現(xiàn)一個(gè)可溢出的 hash-table (由字節(jié)數(shù)組和自定義序列化支持)。當(dāng)然,Apache Flink 并不是唯一一個(gè)基于 JVM 且對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作的數(shù)據(jù)處理系統(tǒng)。例如 Apache Drill、Apache Ignite、Apache Geode 也有應(yīng)用類似技術(shù),最近 Apache Spark 也宣布將向這個(gè)方向演進(jìn)。
下面我們將詳細(xì)討論 Flink 如何分配內(nèi)存、如果對(duì)對(duì)象進(jìn)行序列化和反序列化以及如果對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作。我們還將通過(guò)一些性能表現(xiàn)數(shù)據(jù)來(lái)比較處理堆內(nèi)存上的對(duì)象和對(duì)二進(jìn)制數(shù)據(jù)的操作。
Flink 如何分配內(nèi)存?
Flink TaskManager 是由幾個(gè)內(nèi)部組件組成的:actor 系統(tǒng)(負(fù)責(zé)與 Flink master 協(xié)調(diào))、IOManager(負(fù)責(zé)將數(shù)據(jù)溢出到磁盤(pán)并將其讀取回來(lái))、MemoryManager(負(fù)責(zé)協(xié)調(diào)內(nèi)存使用)。在本篇文章中,我們主要講解 MemoryManager。
MemoryManager 負(fù)責(zé)將 MemorySegments 分配、計(jì)算和分發(fā)給數(shù)據(jù)處理操作符,例如 sort 和 join 等操作符。MemorySegment 是 Flink 的內(nèi)存分配單元,由常規(guī) Java 字節(jié)數(shù)組支持(默認(rèn)大小為 32 KB)。MemorySegment 通過(guò)使用 Java 的 unsafe 方法對(duì)其支持的字節(jié)數(shù)組提供非常有效的讀寫(xiě)訪問(wèn)。你可以將 MemorySegment 看作是 Java 的 NIO ByteBuffer 的定制版本。為了在更大的連續(xù)內(nèi)存塊上操作多個(gè) MemorySegment,F(xiàn)link 使用了實(shí)現(xiàn) Java 的 java.io.DataOutput 和 java.io.DataInput 接口的邏輯視圖。
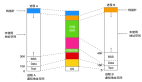
MemorySegments 在 TaskManager 啟動(dòng)時(shí)分配一次,并在 TaskManager 關(guān)閉時(shí)銷(xiāo)毀。因此,在 TaskManager 的整個(gè)生命周期中,MemorySegment 是重用的,而不會(huì)被垃圾收集的。在初始化 TaskManager 的所有內(nèi)部數(shù)據(jù)結(jié)構(gòu)并且已啟動(dòng)所有核心服務(wù)之后,MemoryManager 開(kāi)始創(chuàng)建 MemorySegments。默認(rèn)情況下,服務(wù)初始化后,70% 可用的 JVM 堆內(nèi)存由 MemoryManager 分配(也可以配置全部)。剩余的 JVM 堆內(nèi)存用于在任務(wù)處理期間實(shí)例化的對(duì)象,包括由用戶定義的函數(shù)創(chuàng)建的對(duì)象。下圖顯示了啟動(dòng)后 TaskManager JVM 中的內(nèi)存分布:
存的?")
Flink 如何序列化對(duì)象?
Java 生態(tài)系統(tǒng)提供了幾個(gè)庫(kù),可以將對(duì)象轉(zhuǎn)換為二進(jìn)制表示形式并返回。常見(jiàn)的替代方案是標(biāo)準(zhǔn) Java 序列化,Kryo,Apache Avro,Apache Thrift 或 Google 的 Protobuf。Flink 包含自己的自定義序列化框架,以便控制數(shù)據(jù)的二進(jìn)制表示。這一點(diǎn)很重要,因?yàn)閷?duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作需要對(duì)序列化布局有準(zhǔn)確的了解。此外,根據(jù)在二進(jìn)制數(shù)據(jù)上執(zhí)行的操作配置序列化布局可以顯著提升性能。Flink 的序列化機(jī)制利用了這一特性,即在執(zhí)行程序之前,要序列化和反序列化的對(duì)象的類型是完全已知的。
Flink 程序可以處理表示為任意 Java 或 Scala 對(duì)象的數(shù)據(jù)。在優(yōu)化程序之前,需要識(shí)別程序數(shù)據(jù)流的每個(gè)處理步驟中的數(shù)據(jù)類型。對(duì)于 Java 程序,F(xiàn)link 提供了一個(gè)基于反射的類型提取組件,用于分析用戶定義函數(shù)的返回類型。Scala 程序可以在 Scala 編譯器的幫助下進(jìn)行分析。Flink 使用 TypeInformation 表示每種數(shù)據(jù)類型。
- Flink 有如下幾種數(shù)據(jù)類型的 TypeInformations:
- BasicTypeInfo:所有 Java 的基礎(chǔ)類型或 java.lang.String
- BasicArrayTypeInfo:Java 基本類型構(gòu)成的數(shù)組或 java.lang.String
- WritableTypeInfo:Hadoop 的 Writable 接口的任何實(shí)現(xiàn)
- TupleTypeInfo:任何 Flink tuple(Tuple1 到 Tuple25)。Flink tuples 是具有類型化字段的固定長(zhǎng)度元組的 Java 表示
- CaseClassTypeInfo:任何 Scala CaseClass(包括 Scala tuples)
- PojoTypeInfo:任何 POJO(Java 或 Scala),即所有字段都是 public 的或通過(guò) getter 和 setter 訪問(wèn)的對(duì)象,遵循通用命名約定
- GenericTypeInfo:不能標(biāo)識(shí)為其他類型的任何數(shù)據(jù)類型
每個(gè) TypeInformation 都為它所代表的數(shù)據(jù)類型提供了一個(gè)序列化器。例如,BasicTypeInfo 返回一個(gè)序列化器,該序列化器寫(xiě)入相應(yīng)的基本類型;WritableTypeInfo 的序列化器將序列化和反序列化委托給實(shí)現(xiàn) Hadoop 的 Writable 接口的對(duì)象的 write() 和 readFields() 方法;GenericTypeInfo 返回一個(gè)序列化器,該序列化器將序列化委托給 Kryo。對(duì)象將自動(dòng)通過(guò) Java 中高效的 Unsafe 方法來(lái)序列化到 Flink MemorySegments 支持的 DataOutput。對(duì)于可用作鍵的數(shù)據(jù)類型,例如哈希值,TypeInformation 提供了 TypeComparators,TypeComparators 比較和哈希對(duì)象,并且可以根據(jù)具體的數(shù)據(jù)類型有效的比較二進(jìn)制并提取固定長(zhǎng)度的二進(jìn)制 key 前綴。
Tuple,Pojo 和 CaseClass 類型是復(fù)合類型,它們可能嵌套一個(gè)或者多個(gè)數(shù)據(jù)類型。因此,它們的序列化和比較也都比較復(fù)雜,一般將其成員數(shù)據(jù)類型的序列化和比較都交給各自的 Serializers(序列化器) 和 Comparators(比較器)。下圖說(shuō)明了 Tuple3對(duì)象的序列化,其中Person 是 POJO 并定義如下:
- public class Person {
- public int id;
- public String name;
- }
存的?")
通過(guò)提供定制的 TypeInformations、Serializers(序列化器) 和 Comparators(比較器),可以方便地?cái)U(kuò)展 Flink 的類型系統(tǒng),從而提高序列化和比較自定義數(shù)據(jù)類型的性能。
Flink 如何對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作?
與其他的數(shù)據(jù)處理框架的 API(包括 SQL)類似,F(xiàn)link 的 API 也提供了對(duì)數(shù)據(jù)集進(jìn)行分組、排序和連接等轉(zhuǎn)換操作。這些轉(zhuǎn)換操作的數(shù)據(jù)集可能非常大。關(guān)系數(shù)據(jù)庫(kù)系統(tǒng)具有非常高效的算法,比如 merge-sort、merge-join 和 hash-join。Flink 建立在這種技術(shù)的基礎(chǔ)上,但是主要分為使用自定義序列化和自定義比較器來(lái)處理任意對(duì)象。在下面文章中我們將通過(guò) Flink 的內(nèi)存排序算法示例演示 Flink 如何使用二進(jìn)制數(shù)據(jù)進(jìn)行操作。
Flink 為其數(shù)據(jù)處理操作符預(yù)先分配內(nèi)存,初始化時(shí),排序算法從 MemoryManager 請(qǐng)求內(nèi)存預(yù)算,并接收一組相應(yīng)的 MemorySegments。這些 MemorySegments 變成了緩沖區(qū)的內(nèi)存池,緩沖區(qū)中收集要排序的數(shù)據(jù)。下圖說(shuō)明了如何將數(shù)據(jù)對(duì)象序列化到排序緩沖區(qū)中:
存的?")
排序緩沖區(qū)在內(nèi)部分為兩個(gè)內(nèi)存區(qū)域:第一個(gè)區(qū)域保存所有對(duì)象的完整二進(jìn)制數(shù)據(jù),第二個(gè)區(qū)域包含指向完整二進(jìn)制對(duì)象數(shù)據(jù)的指針(取決于 key 的數(shù)據(jù)類型)。將對(duì)象添加到排序緩沖區(qū)時(shí),它的二進(jìn)制數(shù)據(jù)會(huì)追加到第一個(gè)區(qū)域,指針(可能還有一個(gè) key)被追加到第二個(gè)區(qū)域。分離實(shí)際數(shù)據(jù)和指針以及固定長(zhǎng)度的 key 有兩個(gè)目的:它可以有效的交換固定長(zhǎng)度的 entries(key 和指針),還可以減少排序時(shí)需要移動(dòng)的數(shù)據(jù)。如果排序的 key 是可變長(zhǎng)度的數(shù)據(jù)類型(比如 String),則固定長(zhǎng)度的排序 key 必須是前綴 key,比如字符串的前 n 個(gè)字符。請(qǐng)注意:并非所有數(shù)據(jù)類型都提供固定長(zhǎng)度的前綴排序 key。將對(duì)象序列化到排序緩沖區(qū)時(shí),兩個(gè)內(nèi)存區(qū)域都使用內(nèi)存池中的 MemorySegments 進(jìn)行擴(kuò)展。一旦內(nèi)存池為空且不能再添加對(duì)象時(shí),則排序緩沖區(qū)將會(huì)被完全填充并可以進(jìn)行排序。Flink 的排序緩沖區(qū)提供了比較和交換元素的方法,這使得實(shí)際的排序算法是可插拔的。默認(rèn)情況下, Flink 使用了 Quicksort(快速排序)實(shí)現(xiàn),可以使用 HeapSort(堆排序)。下圖顯示了如何比較兩個(gè)對(duì)象:
存的?")
排序緩沖區(qū)通過(guò)比較它們的二進(jìn)制固定長(zhǎng)度排序 key 來(lái)比較兩個(gè)元素。如果元素的完整 key(不是前綴 key) 或者二進(jìn)制前綴 key 不相等,則代表比較成功。如果前綴 key 相等(或者排序 key 的數(shù)據(jù)類型不提供二進(jìn)制前綴 key),則排序緩沖區(qū)遵循指向?qū)嶋H對(duì)象數(shù)據(jù)的指針,對(duì)兩個(gè)對(duì)象進(jìn)行反序列化并比較對(duì)象。根據(jù)比較結(jié)果,排序算法決定是否交換比較的元素。排序緩沖區(qū)通過(guò)移動(dòng)其固定長(zhǎng)度 key 和指針來(lái)交換兩個(gè)元素,實(shí)際數(shù)據(jù)不會(huì)移動(dòng),排序算法完成后,排序緩沖區(qū)中的指針被正確排序。下圖演示了如何從排序緩沖區(qū)返回已排序的數(shù)據(jù):
存的?")
通過(guò)順序讀取排序緩沖區(qū)的指針區(qū)域,跳過(guò)排序 key 并按照實(shí)際數(shù)據(jù)的排序指針?lè)祷嘏判驍?shù)據(jù)。此數(shù)據(jù)要么反序列化并作為對(duì)象返回,要么在外部合并排序的情況下復(fù)制二進(jìn)制數(shù)據(jù)并將其寫(xiě)入磁盤(pán)。
基準(zhǔn)測(cè)試數(shù)據(jù)
那么,對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作對(duì)性能意味著什么?我們將運(yùn)行一個(gè)基準(zhǔn)測(cè)試,對(duì) 1000 萬(wàn)個(gè)Tuple2對(duì)象進(jìn)行排序以找出答案。整數(shù)字段的值從均勻分布中采樣。String 字段值的長(zhǎng)度為 12 個(gè)字符,并從長(zhǎng)尾分布中進(jìn)行采樣。輸入數(shù)據(jù)由返回可變對(duì)象的迭代器提供,即返回具有不同字段值的相同 Tuple 對(duì)象實(shí)例。Flink 在從內(nèi)存,網(wǎng)絡(luò)或磁盤(pán)讀取數(shù)據(jù)時(shí)使用此技術(shù),以避免不必要的對(duì)象實(shí)例化。基準(zhǔn)測(cè)試在具有 900 MB 堆大小的 JVM 中運(yùn)行,在堆上存儲(chǔ)和排序 1000 萬(wàn)個(gè) Tuple 對(duì)象并且不會(huì)導(dǎo)致觸發(fā) OutOfMemoryError 大約需要這么大的內(nèi)存。我們使用三種排序方法在Integer 字段和 String 字段上對(duì) Tuple 對(duì)象進(jìn)行排序:
- 對(duì)象存在堆中:Tuple 對(duì)象存儲(chǔ)在常用的 java.util.ArrayList 中,初始容量設(shè)置為 1000 萬(wàn),并使用 Java 中常用的集合排序進(jìn)行排序。
- Flink 序列化:使用 Flink 的自定義序列化程序?qū)?Tuple 字段序列化為 600 MB 大小的排序緩沖區(qū),如上所述排序,最后再次反序列化。在 Integer 字段上進(jìn)行排序時(shí),完整的 Integer 用作排序 key,以便排序完全發(fā)生在二進(jìn)制數(shù)據(jù)上(不需要對(duì)象的反序列化)。對(duì)于 String 字段的排序,使用 8 字節(jié)前綴 key,如果前綴 key 相等,則對(duì) Tuple 對(duì)象進(jìn)行反序列化。
- Kryo 序列化:使用 Kryo 序列化將 Tuple 字段序列化為 600 MB 大小的排序緩沖區(qū),并在沒(méi)有二進(jìn)制排序 key 的情況下進(jìn)行排序。這意味著每次比較需要對(duì)兩個(gè)對(duì)象進(jìn)行反序列化。
所有排序方法都使用單線程實(shí)現(xiàn)。結(jié)果的時(shí)間是十次運(yùn)行結(jié)果的平均值。在每次運(yùn)行之后,我們調(diào)用System.gc()請(qǐng)求垃圾收集運(yùn)行,該運(yùn)行不會(huì)進(jìn)入測(cè)量的執(zhí)行時(shí)間。下圖顯示了將輸入數(shù)據(jù)存儲(chǔ)在內(nèi)存中,對(duì)其進(jìn)行排序并將其作為對(duì)象讀回的時(shí)間。
存的?")
我們看到 Flink 使用自己的序列化器對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行排序明顯優(yōu)于其他兩種方法。與存儲(chǔ)在堆內(nèi)存上相比,我們看到將數(shù)據(jù)加載到內(nèi)存中要快得多。因?yàn)槲覀儗?shí)際上是在收集對(duì)象,沒(méi)有機(jī)會(huì)重用對(duì)象實(shí)例,但必須重新創(chuàng)建每個(gè) Tuple。這比 Flink 的序列化器(或Kryo序列化)效率低。另一方面,與反序列化相比,從堆中讀取對(duì)象是無(wú)性能消耗的。在我們的基準(zhǔn)測(cè)試中,對(duì)象克隆比序列化和反序列化組合更耗性能。查看排序時(shí)間,我們看到對(duì)二進(jìn)制數(shù)據(jù)的排序也比 Java 的集合排序更快。使用沒(méi)有二進(jìn)制排序 key 的 Kryo 序列化的數(shù)據(jù)排序比其他方法慢得多。這是因?yàn)榉葱蛄谢瘞?lái)很大的開(kāi)銷(xiāo)。在String 字段上對(duì) Tuple 進(jìn)行排序比在 Integer 字段上排序更快,因?yàn)殚L(zhǎng)尾值分布顯著減少了成對(duì)比較的數(shù)量。為了更好地了解排序過(guò)程中發(fā)生的狀況,我們使用 VisualVM 監(jiān)控執(zhí)行的 JVM。以下截圖顯示了執(zhí)行 10次 運(yùn)行時(shí)的堆內(nèi)存使用情況、垃圾收集情況和 CPU 使用情況。
存的?")
測(cè)試是在 8 核機(jī)器上運(yùn)行單線程,因此一個(gè)核心的完全利用僅對(duì)應(yīng) 12.5% 的總體利用率。截圖顯示,對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作可顯著減少垃圾回收活動(dòng)。對(duì)于對(duì)象存在堆中,垃圾收集器在排序緩沖區(qū)被填滿時(shí)以非常短的時(shí)間間隔運(yùn)行,并且即使對(duì)于單個(gè)處理線程也會(huì)導(dǎo)致大量 CPU 使用(排序本身不會(huì)觸發(fā)垃圾收集器)。JVM 垃圾收集多個(gè)并行線程,解釋了高CPU 總體利用率。另一方面,對(duì)序列化數(shù)據(jù)進(jìn)行操作的方法很少觸發(fā)垃圾收集器并且 CPU 利用率低得多。實(shí)際上,如果使用 Flink 序列化的方式在 Integer 字段上對(duì) Tuple 進(jìn)行排序,則垃圾收集器根本不運(yùn)行,因?yàn)閷?duì)于成對(duì)比較,不需要反序列化任何對(duì)象。Kryo 序列化需要比較多的垃圾收集,因?yàn)樗皇褂枚M(jìn)制排序 key 并且每次排序都要反序列化兩個(gè)對(duì)象。
內(nèi)存使用情況上圖顯示 Flink 序列化和 Kryo 序列化不斷的占用大量?jī)?nèi)存
存使用情況圖表顯示flink-serialized和kryo-serialized不斷占用大量?jī)?nèi)存。這是由于 MemorySegments 的預(yù)分配。實(shí)際內(nèi)存使用率要低得多,因?yàn)榕判蚓彌_區(qū)并未完全填充。下表顯示了每種方法的內(nèi)存消耗。1000 萬(wàn)條數(shù)據(jù)產(chǎn)生大約 280 MB 的二進(jìn)制數(shù)據(jù)(對(duì)象數(shù)據(jù)、指針和排序 key),具體取決于使用的序列化程序以及二進(jìn)制排序 key 的存在和大小。將其與數(shù)據(jù)存儲(chǔ)在堆上的方法進(jìn)行比較,我們發(fā)現(xiàn)對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作可以顯著提高內(nèi)存效率。在我們的基準(zhǔn)測(cè)試中,如果序列化為排序緩沖區(qū)而不是將其作為堆上的對(duì)象保存,則可以在內(nèi)存中對(duì)兩倍以上的數(shù)據(jù)進(jìn)行排序。
存的?")
總而言之,測(cè)試驗(yàn)證了文章前面說(shuō)的對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作的好處。
展望未來(lái)
Apache Flink 具有相當(dāng)多的高級(jí)技術(shù),可以通過(guò)有限的內(nèi)存資源安全有效地處理大量數(shù)據(jù)。但是有幾點(diǎn)可以使 Flink 更有效率。Flink 社區(qū)正在努力將管理內(nèi)存移動(dòng)到堆外內(nèi)存。這將允許更小的 JVM,更低的垃圾收集開(kāi)銷(xiāo),以及更容易的系統(tǒng)配置。使用 Flink 的 Table API,所有操作(如 aggregation 和 projection)的語(yǔ)義都是已知的(與黑盒用戶定義的函數(shù)相反)。因此,我們可以為直接對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作的 Table API 操作生成代碼。進(jìn)一步的改進(jìn)包括序列化設(shè)計(jì),這些設(shè)計(jì)針對(duì)應(yīng)用于二進(jìn)制數(shù)據(jù)的操作和針對(duì)序列化器和比較器的代碼生成而定制。
總結(jié)
- Flink 的主動(dòng)內(nèi)存管理減少了因觸發(fā) OutOfMemoryErrors 而殺死 JVM 進(jìn)程和垃圾收集開(kāi)銷(xiāo)的問(wèn)題。
- Flink 具有高效的數(shù)據(jù)序列化和反序列化機(jī)制,有助于對(duì)二進(jìn)制數(shù)據(jù)進(jìn)行操作,并使更多數(shù)據(jù)適合內(nèi)存。
- Flink 的 DBMS 風(fēng)格的運(yùn)算符本身在二進(jìn)制數(shù)據(jù)上運(yùn)行,在必要時(shí)可以在內(nèi)存中高性能地傳輸?shù)酱疟P(pán)。