帶你認(rèn)識HDFS和如何創(chuàng)建3個節(jié)點(diǎn)HDFS集群
在本文中,大數(shù)據(jù)專家將為您介紹如何使用HDFS以及如何利用HDFS創(chuàng)建HDFS集群節(jié)點(diǎn)。
我們將從HDFS、Zookeeper、Hbase和OpenTSDB上的系列博客開始,了解如何利用這些服務(wù)設(shè)置OpenTSDB集群。在本文中,我們將探究HDFS。
HDFS
Hadoop分布式文件系統(tǒng)(HDFS)是一種基于Java的分布式文件系統(tǒng),它具有容錯性、可伸縮性和易擴(kuò)展性等優(yōu)點(diǎn),它可在商用硬件上運(yùn)行,也可以在低成本的硬件上進(jìn)行部署。HDFS是一個分布式存儲的Hadoop應(yīng)用程序,它提供了更易訪問數(shù)據(jù)的接口。
架構(gòu)
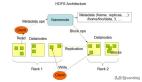
HDFS架構(gòu)包含一個NameNode、DataNode和備用NameNode。
HDFS具有主/從架構(gòu)。
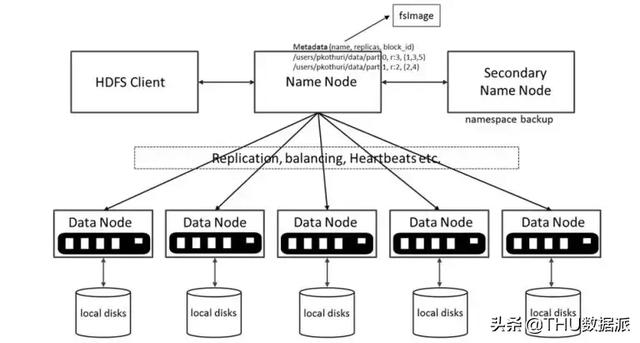
NameNode:HDFS集群包含單個NameNode(主服務(wù)器),它管理文件系統(tǒng)命名空間并控制客戶端對文件的訪問權(quán)限。它維護(hù)和管理文件系統(tǒng)元數(shù)據(jù);例如由哪些塊構(gòu)成文件,以及存儲這些塊的數(shù)據(jù)節(jié)點(diǎn)。
DataNode:可以有多個DataNode,通常是集群中每個節(jié)點(diǎn)有一個DataNode,它負(fù)責(zé)管理運(yùn)行節(jié)點(diǎn)的存儲訪問。HDFS中的DataNode存儲實(shí)際數(shù)據(jù),可以添加更多的DataNode來增加可用空間。
備用NameNode :備用NameNode服務(wù)并非真正的備用NameNode,盡管名稱是稱為備用NameNode。具體來說,它并不為NameNode提供高可用性(HA)。
為什么需要備用NameNode?
- 備用NameNode記錄文件系統(tǒng)的修改痕跡,追加到本機(jī)文件系統(tǒng)文件的后面,作為修改日志。
- 啟動備用NameNode時,它會從映像文件fsimage中讀取HDFS狀態(tài),然后啟用“編輯日志文件”對它進(jìn)行編輯。
- 然后將新的HDFS狀態(tài)寫入fsimage,并使用“空編輯文件”啟動正常操作。
- 由于NameNode只在啟動時合并fsimage和編輯文件,所以在繁忙的集群中,隨著時間的推移,“編輯日志文件”會變得非常大。
- 大“編輯日志文件”的另一個副作用是:在下次重新啟動NameNode時,需要花費(fèi)更長的時間。
- 備用NameNode定期合并fsimage和“編輯日志文件”,并將“編輯日志文件”的大小保持在限定范圍內(nèi)。
- 備用NameNode通常在與主NameNode不同的計(jì)算機(jī)上運(yùn)行,因?yàn)樗膬?nèi)存要求與主NameNode的相同。
關(guān)鍵特征
容錯:為了防止機(jī)器故障,可跨多個DataNode復(fù)制容錯數(shù)據(jù),復(fù)制因子的默認(rèn)值是3(如果有3個DataNode,每個塊至少存儲在三臺計(jì)算機(jī)上)。
可伸縮性- DataNode之間可實(shí)現(xiàn)直接數(shù)據(jù)傳輸,所以讀/寫次數(shù)應(yīng)與DataNode的數(shù)量相匹配。
空間-需要更多的磁盤空間?只需添加更多DataNodes和再平衡。
行業(yè)標(biāo)準(zhǔn)-其他分布式應(yīng)用程序均構(gòu)建在HDFS之上(HBASE,Map-Reduction)。
HDFS是用來處理大數(shù)據(jù)集的,它具有write-once-read-many(一次寫-多次讀)的語義,不適合低延遲訪問。
數(shù)據(jù)結(jié)構(gòu)
- 寫入HDFS的每個文件被分割為64MB或128MB大小的數(shù)據(jù)塊。
- 每個塊存儲在一個或多個節(jié)點(diǎn)上。
- 塊的每個副本均稱為副本。
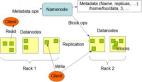
分塊安置策略
- 第一副本放在本地節(jié)點(diǎn)上。
- 第二副本放在不同的機(jī)架上。
- 第三副本與第二副本放置在同一機(jī)架中。
設(shè)置HDFS集群
要創(chuàng)建HDFS集群,會用到Docker。
步驟
創(chuàng)建一個Docker群網(wǎng)絡(luò)。
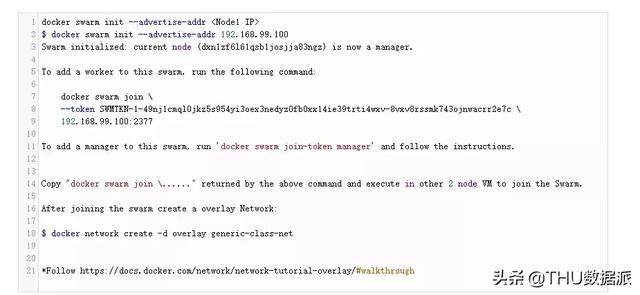
NameNode
在VM1中為NameNode創(chuàng)建環(huán)境變量文件(namenode_env)。
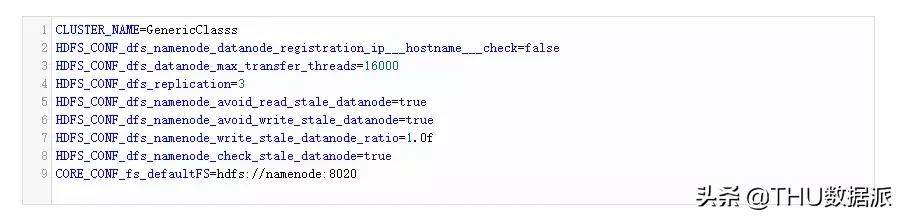
在VM1上創(chuàng)建NameNode:
在所有3個VM中為DataNode創(chuàng)建環(huán)境變量文件(datanode_env)。
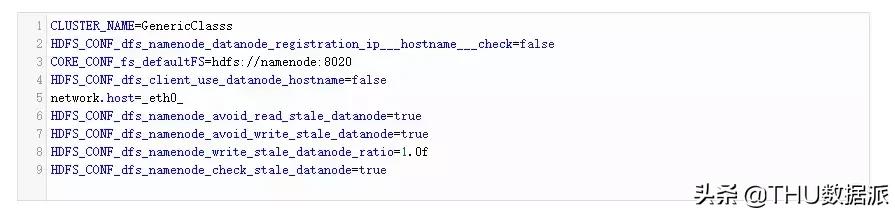
在VM1上創(chuàng)建DataNode1:
在VM2上創(chuàng)建DataNode 2:
在VM 3上創(chuàng)建DataNode 3。
在所有vms中,通過執(zhí)行docker ps檢查所有容器是否已啟動并正常運(yùn)行。
一旦所有容器均已啟動并運(yùn)行,請轉(zhuǎn)到VM1,打開瀏覽器,打開http://localhost:50070/dfshealth.html#tab-datanode.將會看到如下輸出:
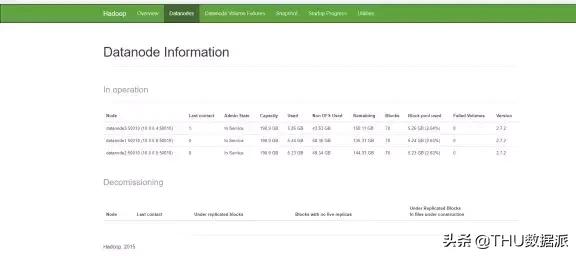
HDFS CLI

在本文中,我們研究了HDFS以及如何創(chuàng)建3個節(jié)點(diǎn)HDFS集群。在下一篇文章中,我們將關(guān)注Zookeeper,并創(chuàng)建一個Zookeeper集群。
原文標(biāo)題:
An Introduction to HDFS
原文鏈接:
https://dzone.com/articles/an-introduction-to-hdfs
譯者
陳之炎,北京交通大學(xué)通信與控制工程專業(yè)畢業(yè),獲得工學(xué)碩士學(xué)位,歷任長城計(jì)算機(jī)軟件與系統(tǒng)公司工程師,大唐微電子公司工程師,現(xiàn)任北京吾譯超群科技有限公司技術(shù)支持。目前從事智能化翻譯教學(xué)系統(tǒng)的運(yùn)營和維護(hù),在人工智能深度學(xué)習(xí)和自然語言處理(NLP)方面積累有一定的經(jīng)驗(yàn)。業(yè)余時間喜愛翻譯創(chuàng)作,翻譯作品主要有:IEC-ISO 7816、伊拉克石油工程項(xiàng)目、新財(cái)稅主義宣言等等,其中中譯英作品“新財(cái)稅主義宣言”在GLOBAL TIMES正式發(fā)表。能夠利用業(yè)余時間加入到THU 數(shù)據(jù)派平臺的翻譯志愿者小組,希望能和大家一起交流分享,共同進(jìn)步