互聯網架構模板:“存儲層”技術
很多人對于 BAT 的技術有一種莫名的崇拜感,覺得只有天才才能做出這樣的系統,但經過前面對架構的本質、架構的設計原則、架構的設計模式、架構演進等多方位的探討和闡述,你可以看到,其實并沒有什么神秘的力量和魔力融合在技術里面,而是業務的不斷發展推動了技術的發展,這樣一步一個腳印,持續幾年甚至十幾年的發展,才能達到當前技術復雜度和先進性。
拋開 BAT 各自差異很大的業務,站在技術的角度來看,其實 BAT 的技術架構基本是一樣的。再將視角放大,你會發現整個互聯網行業的技術發展,最后都是殊途同歸。
如果你正處于一個創業公司,或者正在為成為另一個 BAT 拼搏,那么深入理解這種技術模式(或者叫技術結構、技術架構),對于自己和公司的發展都大有裨益。
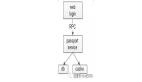
互聯網的標準技術架構如下圖所示,這張圖基本上涵蓋了互聯網技術公司的大部分技術點,不同的公司只是在具體的技術實現上稍有差異,但不會跳出這個框架的范疇。
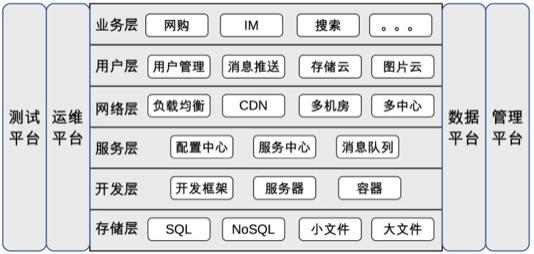
從本期開始,我將逐層介紹每個技術點的產生背景、應用場景、關鍵技術,有的技術點可能已經在前面的架構模式部分有所涉及,因此就不再詳細展開技術細節了,而是將關鍵技術點分門別類,進而形成一張架構大圖,讓架構師對一個公司的整體技術架構有一個完整的全貌認知。
今天我們首先來聊聊互聯網架構模板的“存儲層”技術。
SQL
SQL 即我們通常所說的關系數據。前幾年 NoSQL 火了一陣子,很多人都理解為 NoSQL 是完全拋棄關系數據,全部采用非關系型數據。但經過幾年的試驗后,大家發現關系數據不可能完全被拋棄,NoSQL 不是 No SQL,而是 Not Only SQL,即 NoSQL 是 SQL 的補充。
所以互聯網行業也必須依賴關系數據,考慮到 Oracle 太貴,還需要專人維護,一般情況下互聯網行業都是用 MySQL、PostgreSQL 這類開源數據庫。這類數據庫的特點是開源免費,拿來就用;但缺點是性能相比商業數據庫要差一些。隨著互聯網業務的發展,性能要求越來越高,必然要面對一個問題:將數據拆分到多個數據庫實例才能滿足業務的性能需求(其實 Oracle 也一樣,只是時間早晚的問題)。
數據庫拆分滿足了性能的要求,但帶來了復雜度的問題:數據如何拆分、數據如何組合?這個復雜度的問題解決起來并不容易,如果每個業務都去實現一遍,重復造輪子將導致投入浪費、效率降低,業務開發想快都快不起來。
所以互聯網公司流行的做法是業務發展到一定階段后,就會將這部分功能獨立成中間件,例如百度的 DBProxy、淘寶的 TDDL。不過這部分的技術要求很高,將分庫分表做到自動化和平臺化,不是一件容易的事情,所以一般是規模很大的公司才會自己做。中小公司建議使用開源方案,例如 MySQL 官方推薦的 MySQL Router、360 開源的數據庫中間件 Atlas。
假如公司業務繼續發展,規模繼續擴大,SQL 服務器越來越多,如果每個業務都基于統一的數據庫中間件獨立部署自己的 SQL 集群,就會導致新的復雜度問題,具體表現在:
數據庫資源使用率不高,比較浪費。
各 SQL 集群分開維護,投入的維護成本越來越高。
因此,實力雄厚的大公司此時一般都會在 SQL 集群上構建 SQL 存儲平臺,以對業務透明的形式提供資源分配、數據備份、遷移、容災、讀寫分離、分庫分表等一系列服務,例如淘寶的 UMP(Unified MySQL Platform)系統。
NoSQL
首先 NoSQL 在數據結構上與傳統的 SQL 的不同,例如典型的 Memcache 的 key-value 結構、Redis 的復雜數據結構、MongoDB 的文檔數據結構;其次,NoSQL 無一例外地都會將性能作為自己的一大賣點。NoSQL 的這兩個特點很好地彌補了關系數據庫的不足,因此在互聯網行業 NoSQL 的應用基本上是基礎要求。
由于 NoSQL 方案一般自己本身就提供集群的功能,例如 Memcache 的一致性 Hash 集群、Redis 3.0 的集群,因此 NoSQL 在剛開始應用時很方便,不像 SQL 分庫分表那么復雜。一般公司也不會在開始時就考慮將 NoSQL 包裝成存儲平臺,但如果公司發展很快,例如 Memcache 的節點有上千甚至幾千時,NoSQL 存儲平臺就很有意義了。首先是存儲平臺通過集中管理能夠大大提升運維效率;其次是存儲平臺可以大大提升資源利用效率,2000 臺機器,如果利用率能提升 10%,就可以減少 200 臺機器,一年幾十萬元就節省出來了。
所以,NoSQL 發展到一定規模后,通常都會在 NoSQL 集群的基礎之上再實現統一存儲平臺,統一存儲平臺主要實現這幾個功能:
資源動態按需動態分配:例如同一臺 Memcache 服務器,可以根據內存利用率,分配給多個業務使用。
資源自動化管理:例如新業務只需要申請多少 Memcache 緩存空間就可以了,無需關注具體是哪些 Memcache 服務器在為自己提供服務。
故障自動化處理:例如某臺 Memcache 服務器掛掉后,有另外一臺備份 Memcache 服務器能立刻接管緩存請求,不會導致丟失很多緩存數據。
當然要發展到這個階段,一般也是大公司才會這么做,簡單來說就是如果只有幾十臺 NoSQL 服務器,做存儲平臺收益不大;但如果有幾千臺 NoSQL 服務器,NoSQL 存儲平臺就能夠產生很大的收益。
小文件存儲
除了關系型的業務數據,互聯網行業還有很多用于展示的數據。例如,淘寶的商品圖片、商品描述;Facebook 的用戶圖片;新浪微博的一條微博內容等。這些數據具有三個典型特征:一是數據小,一般在 1MB 以下;二是數量巨大,Facebook 在 2013 年每天上傳的照片就達到了 3.5 億張;三是訪問量巨大,Facebook 每天的訪問量超過 10 億。
由于互聯網行業基本上每個業務都會有大量的小數據,如果每個業務都自己去考慮如何設計海量存儲和海量訪問,效率自然會低,重復造輪子也會投入浪費,所以自然而然就要將小文件存儲做成統一的和業務無關的平臺。
和 SQL 和 NoSQL 不同的是,小文件存儲不一定需要公司或者業務規模很大,基本上認為業務在起步階段就可以考慮做小文件統一存儲。得益于開源運動的發展和最近幾年大數據的火爆,在開源方案的基礎上封裝一個小文件存儲平臺并不是太難的事情。例如,HBase、Hadoop、Hypertable、FastDFS 等都可以作為小文件存儲的底層平臺,只需要將這些開源方案再包裝一下基本上就可以用了。
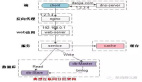
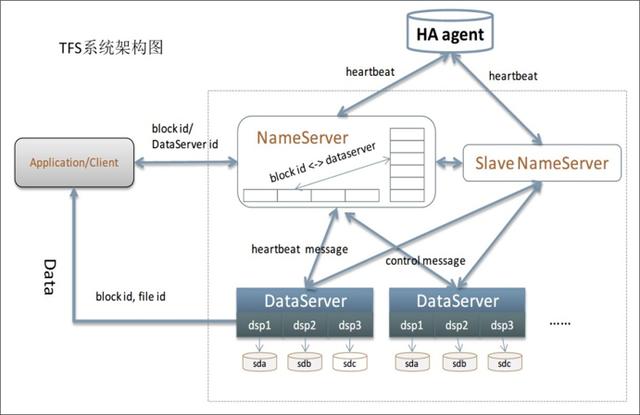
典型的小文件存儲有:淘寶的 TFS、京東 JFS、Facebook 的 Haystack。
下圖是淘寶 TFS 的架構:
大文件存儲
互聯網行業的大文件主要分為兩類:一類是業務上的大數據,例如 Youtube 的視頻、電影網站的電影;另一類是海量的日志數據,例如各種訪問日志、操作日志、用戶軌跡日志等。和小文件的特點正好相反,大文件的數量沒有小文件那么多,但每個文件都很大,幾百 MB、幾個 GB 都是常見的,幾十 GB、幾 TB 也是有可能的,因此在存儲上和小文件有較大差別,不能直接將小文件存儲系統拿來存儲大文件。
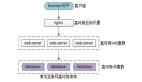
說到大文件,特別要提到 Google 和 Yahoo,Google 的 3 篇大數據論文(Bigtable/Map- Reduce/GFS)開啟了一個大數據的時代,而 Yahoo 開源的 Hadoop 系列(HDFS、HBase 等),基本上壟斷了開源界的大數據處理。當然,江山代有才人出,長江后浪推前浪,Hadoop 后又有更多優秀的開源方案被貢獻出來,現在隨便走到大街上拉住一個程序員,如果他不知道大數據,那基本上可以確定是“火星程序員”。
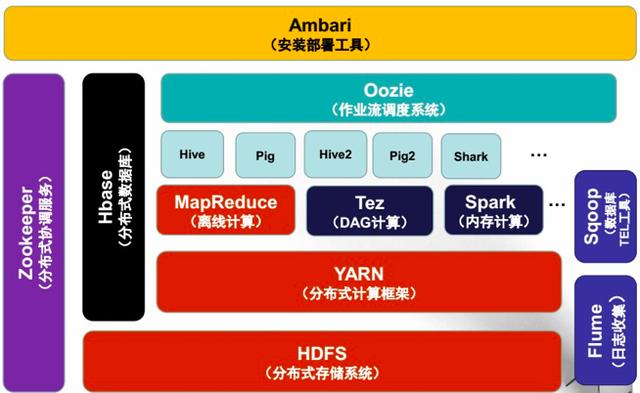
對照 Google 的論文構建一套完整的大數據處理方案的難度和成本實在太高,而且開源方案現在也很成熟了,所以大數據存儲和處理這塊反而是最簡單的,因為你沒有太多選擇,只能用這幾個流行的開源方案,例如,Hadoop、HBase、Storm、Hive 等。實力雄厚一些的大公司會基于這些開源方案,結合自己的業務特點,封裝成大數據平臺,例如淘寶的云梯系統、騰訊的 TDW 系統。
下面是 Hadoop 的生態圈:
小結
今天我為你講了互聯網架構模板中的存儲層技術,可以看到當公司規模發展到一定階段后,基本上都是基于某個開源方案搭建統一的存儲平臺,希望對你有所幫助。
這就是今天的全部內容,留一道思考題給你吧,既然存儲技術發展到最后都是存儲平臺,為何沒有出現存儲平臺的開源方案,但云計算卻都提供了存儲平臺方案?
歡迎你把答案寫到留言區,和我一起討論。相信經過深度思考的回答,也會讓你對知識的理解更加深刻。