別再用Pandas處理大數(shù)據(jù)了!現(xiàn)在你擁有更好的選擇
本文轉(zhuǎn)載自公眾號“讀芯術(shù)”(ID:AI_Discovery)
眾所周知,Pandas是最好的探索性數(shù)據(jù)分析工具之一。但它并非對于每個工作來說都是最佳選擇,大數(shù)據(jù)處理就與它“氣場不合”。
Pandas并不具備多處理器,并且處理較大的數(shù)據(jù)集速度很慢。筆者消耗在等待Pandas讀取一堆文件或?qū)ζ溥M(jìn)行匯總計(jì)算上的時間太多太多了。最近,筆者發(fā)現(xiàn)了一個更好的工具可以更新數(shù)據(jù)處理管道,使這些CPU內(nèi)核正常工作!
筆者使用該工具進(jìn)行繁重的數(shù)據(jù)處理,例如讀取包含10 G數(shù)據(jù)的多個文件,對其進(jìn)行過濾并匯總。數(shù)據(jù)處理工作結(jié)束之后,再將結(jié)果保存到一個較小的適用于Pandas的CSV文件中,然后繼續(xù)對Pandas進(jìn)行探索性數(shù)據(jù)分析。這就方便許多啦,一起來認(rèn)識認(rèn)識這個新工具吧!
認(rèn)識Dask

Dask提供了高級并行性的分析功能,得以擁有大規(guī)模處理數(shù)據(jù)的性能。適用于Dask的算法工具包有numpy, pandas和sklearn。
Dask是一個開源且免費(fèi)的工具。它使用現(xiàn)有的PythonAPI和數(shù)據(jù)結(jié)構(gòu)來簡化在Dask支持的等效項(xiàng)之間的切換。它使簡單的事情變得更容易,讓復(fù)雜的事情變得可能。
Pandas vs Dask
來看一個實(shí)際的例子。在工作中,我們通常會得到一堆需要分析的文件。下面模擬筆者的工作日,并創(chuàng)建10個具有100K條目的文件(每個文件有196 MB)。
- fromsklearn.datasets import make_classification
- import pandas as pdfor i in range(1, 11):
- print('Generating trainset %d' % i)
- x, y =make_classification(n_samples=100_000, n_features=100)
- df = pd.DataFrame(data=x)
- df['y'] = y
- df.to_csv('trainset_%d.csv' % i,index=False)
先用Pandas讀取這些文件并測算時間。Pandas不支持本地glob,因此需要循環(huán)讀取文件。
- %%timeimport globdf_list = []
- for filename in glob.glob('trainset_*.csv'):
- df_ = pd.read_csv(filename)
- df_list.append(df_)
- df = pd.concat(df_list)
- df.shape
Pandas花了16秒讀取文件。
- CPU times: user 14.6 s, sys:1.29 s, total: 15.9 s
- Wall time: 16 s
想象一下如果文件擴(kuò)大100倍,Pandas可能就無能為力了,你甚至無法用Pandas讀取它們。
而Dask可以處理無法讀入內(nèi)存的數(shù)據(jù),它會將數(shù)據(jù)分成多個塊并指定任務(wù)鏈。現(xiàn)在我們來計(jì)算一下Dask加載這些文件需要多長時間。
- importdask.dataframe as dd%%time
- df = dd.read_csv('trainset_*.csv')CPU times: user 154 ms, sys: 58.6 ms, total:212 ms
- Wall time: 212 ms
只要154 ms! 這是怎么做到的?事實(shí)上,這個時間是不準(zhǔn)確的。Dask延遲了執(zhí)行模式。它僅在需要時才進(jìn)行計(jì)算。定義執(zhí)行圖,Dask得以優(yōu)化任務(wù)的執(zhí)行,并重復(fù)該實(shí)驗(yàn)。此外,Dask的read_csv函數(shù)在本機(jī)使用glob。
- %%timedf= dd.read_csv('trainset_*.csv').compute()CPU times: user 39.5 s, sys: 5.3 s,total: 44.8 s
- Wall time: 8.21 s
計(jì)算功能強(qiáng)制Dask返回結(jié)果,Dask讀取文件的速度是Pandas的兩倍。
Pandas vs Dask CPU使用率
Dask是否用到了所提供的所有CPU核心功能?比較一下讀取文件時Pandas和Dask之間的CPU使用率就知道了,看看代碼是否與上面的相同。
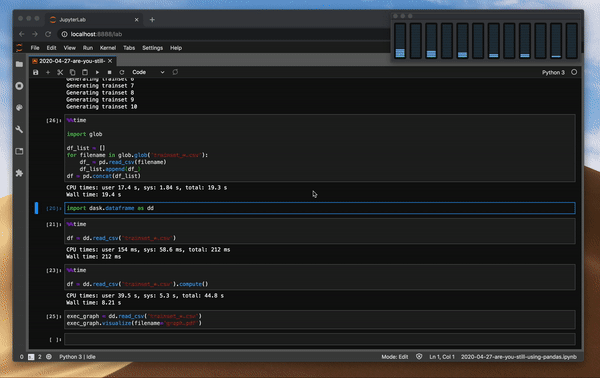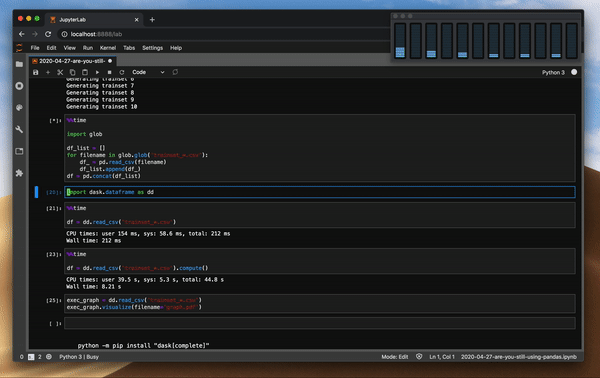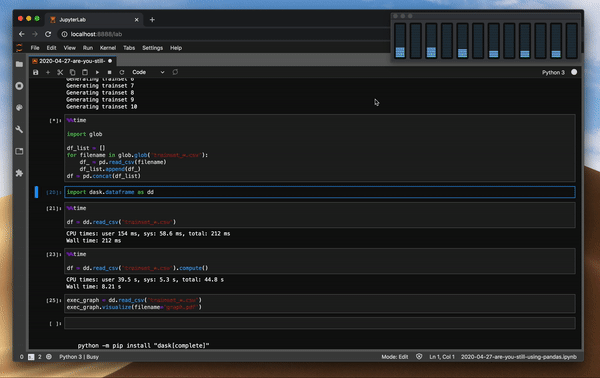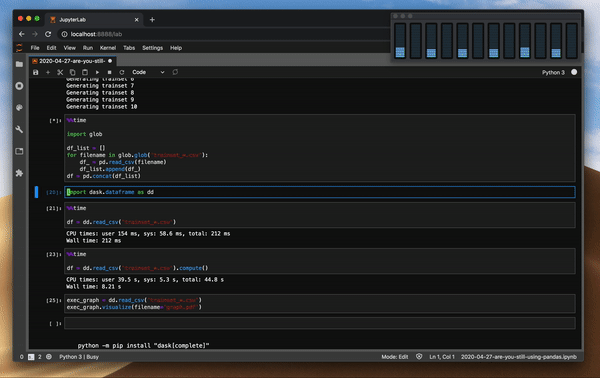
讀取文件時Dask的CPU使用情況
我們可以看到,Pandas和Dask在讀取文件時的多處理差異很明顯。
究竟發(fā)生了什么?
Dask的數(shù)據(jù)框架由多個Pandas的數(shù)據(jù)框架組成,按索引劃分。當(dāng)使用Dask執(zhí)行read_csv函數(shù)時,多個進(jìn)程將讀取一個文件,甚至能夠被可視化為執(zhí)行圖。
- exec_graph= dd.read_csv('trainset_*.csv')
- exec_graph.visualize()
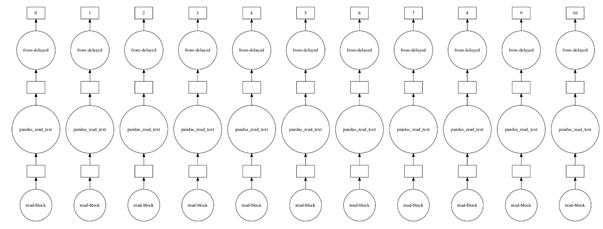
讀取多個文件時,Dask執(zhí)行速度較慢。
安裝方法
要安裝Dask,只需運(yùn)行:
- python-m pip install "dask[complete]"
Dask的缺點(diǎn)
既然Dask這么出色,我們能否直接用它取代Pandas呢?哪有這么簡單的事兒。只有來自Pandas的某些特定功能,才能被遷移到Dask。其中一些功能很難并行化,例如排序值和在未排序的列上設(shè)置索引。
Dask也并非是萬能的,用于不適合主內(nèi)存的數(shù)據(jù)集是最適合它的“舞臺”。Dask是建立在Pandas之上的,Pandas運(yùn)行緩慢,Dask則同樣運(yùn)行緩慢。Dask在數(shù)據(jù)管道過程中僅僅是一個好用的工具,它不能替代其他庫。
為你的工作挑選合適的工具,為你的工具尋找匹配的“舞臺”,這樣它才能夠盡情“表演”。