NLP/CV模型跨界,視覺Transformer趕超CNN?
在計算機視覺領(lǐng)域中,卷積神經(jīng)網(wǎng)絡(luò)(CNN)一直占據(jù)主流地位。不過,不斷有研究者嘗試將 NLP 領(lǐng)域的 Transformer 進行跨界研究,有的還實現(xiàn)了相當(dāng)不錯的結(jié)果。近日,一篇匿名的 ICLR 2021 投稿論文將標(biāo)準(zhǔn) Transformer 直接應(yīng)用于圖像,提出了一個新的 Vision Transformer 模型,并在多個圖像識別基準(zhǔn)上實現(xiàn)了接近甚至優(yōu)于當(dāng)前 SOTA 方法的性能。
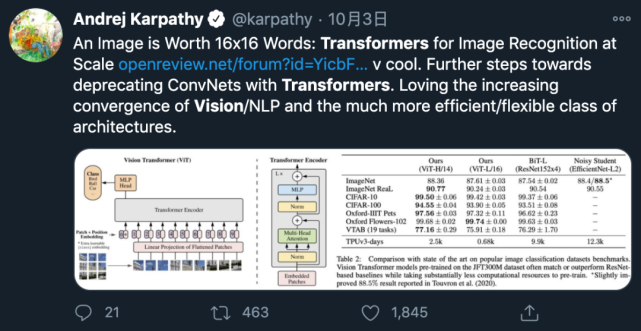
10 月 2 日,深度學(xué)習(xí)領(lǐng)域頂級會議 ICLR 2021 論文投稿結(jié)束,一篇將 Transformer 應(yīng)用于圖像識別的論文引起了廣泛關(guān)注。
特斯拉 AI 負(fù)責(zé)人 Andrej Karpathy 轉(zhuǎn)發(fā)了該論文,并表示「樂見計算機視覺和 NLP 領(lǐng)域日益融合」。
前有 Facebook將 Transformer 應(yīng)用于目標(biāo)檢測任務(wù)、OpenAI 用 GPT-2 做圖像分類的嘗試,這篇「跨界」論文又有哪些新嘗試呢?
Transformer 架構(gòu)早已在自然語言處理任務(wù)中得到廣泛應(yīng)用,但在計算機視覺領(lǐng)域中仍然受到限制。在計算機視覺領(lǐng)域,注意力要么與卷積網(wǎng)絡(luò)結(jié)合使用,要么用來代替卷積網(wǎng)絡(luò)的某些組件,同時保持其整體架構(gòu)不變。
該研究表明,對 CNN 的依賴不是必需的,當(dāng)直接應(yīng)用于圖像塊序列時,transformer 也能很好地執(zhí)行圖像分類任務(wù)。該研究基于大量數(shù)據(jù)進行模型預(yù)訓(xùn)練,并遷移至多個圖像識別基準(zhǔn)數(shù)據(jù)集(ImageNet、CIFAR-100、VTAB 等),結(jié)果表明 Vision Transformer(ViT)模型可以獲得與當(dāng)前最優(yōu)卷積網(wǎng)絡(luò)相媲美的結(jié)果,而其訓(xùn)練所需的計算資源大大減少。
NLP 領(lǐng)域中的 Transformer VS 計算機視覺領(lǐng)域中的 CNN
基于自注意力的架構(gòu),尤其 Transformer,已經(jīng)成為 NLP 領(lǐng)域的首選模型。該主流方法基于大型文本語料庫進行預(yù)訓(xùn)練,然后針對較小的任務(wù)特定數(shù)據(jù)集進行微調(diào)。由于 Transformer 的計算效率和可擴展性,基于它甚至可以訓(xùn)練出參數(shù)超過 100B 的模型。隨著模型和數(shù)據(jù)集的增長,性能仍然沒有飽和的跡象。
然而,在計算機視覺中,卷積架構(gòu)仍然占主導(dǎo)地位。受 NLP 成功的啟發(fā),多項計算機視覺研究嘗試將類 CNN 架構(gòu)與自注意力相結(jié)合,有的甚至完全代替了卷積。后者雖然在理論上有效,但由于其使用了專門的注意力模式,因此尚未在現(xiàn)代硬件加速器上有效地擴展。因此,在大規(guī)模圖像識別任務(wù)中,經(jīng)典的類 ResNet 架構(gòu)仍然是最先進的。
Transformer 向視覺領(lǐng)域的跨界融合
受到 NLP 領(lǐng)域中 Transformer 縮放成功的啟發(fā),這項研究嘗試將標(biāo)準(zhǔn) Transformer 直接應(yīng)用于圖像,并盡可能減少修改。為此,該研究將圖像分割成多個圖像塊(patch),并將這些圖像塊的線性嵌入序列作為 Transformer 的輸入。然后用 NLP 領(lǐng)域中處理 token 的方式處理圖像塊,并以監(jiān)督的方式訓(xùn)練圖像分類模型。
在中等規(guī)模的數(shù)據(jù)集(如 ImageNet)上訓(xùn)練時,這樣的模型產(chǎn)生的結(jié)果并不理想,準(zhǔn)確率比同等大小的 ResNet 低幾個百分點。這個看似令人沮喪的結(jié)果是可以預(yù)料的:Transformer 缺少一些 CNN 固有的歸納偏置,例如平移同變性和局部性,因此在數(shù)據(jù)量不足的情況下進行訓(xùn)練后,Transformer 不能很好地泛化。
但是,如果在大型數(shù)據(jù)集(14M-300M 張圖像)上訓(xùn)練模型,則情況大為不同。該研究發(fā)現(xiàn)大規(guī)模訓(xùn)練勝過歸納偏置。在足夠大的數(shù)據(jù)規(guī)模上進行預(yù)訓(xùn)練并遷移到數(shù)據(jù)點較少的任務(wù)時,Transformer 可以獲得出色的結(jié)果。
該研究提出的 Vision Transformer 在 JFT-300M 數(shù)據(jù)集上進行預(yù)訓(xùn)練,在多個圖像識別基準(zhǔn)上接近或超過了 SOTA 水平,在 ImageNet 上達(dá)到了 88.36% 的準(zhǔn)確率,在 ImageNet ReaL 上達(dá)到了 90.77% 的準(zhǔn)確率,在 CIFAR-100 上達(dá)到了 94.55% 的準(zhǔn)確率,在 VTAB 基準(zhǔn) 19 個任務(wù)中達(dá)到了 77.16% 的準(zhǔn)確率。
模型和方法
研究者盡可能地遵循原始 Transformer 的設(shè)計。這種故意為之的簡單設(shè)置具有以下優(yōu)勢,即可擴展 NLP Transformer 架構(gòu)和相應(yīng)的高效實現(xiàn)幾乎可以實現(xiàn)開箱即用。研究者想要證明,當(dāng)進行適當(dāng)?shù)財U展時,該方法足以超越當(dāng)前最優(yōu)的卷積神經(jīng)網(wǎng)絡(luò)。
Vision Transformer(ViT)
該研究提出的 Vision Transformer 架構(gòu)遵循原版 Transformer 架構(gòu)。下圖 1 為模型架構(gòu)圖。
標(biāo)準(zhǔn) Transformer 接收 1D 序列的 token 嵌入為輸入。為了處理 2D 圖像,研究者將圖像 x ∈ R^H×W×C 變形為一系列的扁平化 2D patch x_p ∈ R^N×(P^2 ·C),其中 (H, W) 表示原始圖像的分辨率,(P, P) 表示每個圖像 patch 的分辨率。然后,N = HW/P^2 成為 Vision Transformer 的有效序列長度。
Vision Transformer 在所有層使用相同的寬度,所以一個可訓(xùn)練的線性投影將每個向量化 patch 映射到模型維度 D 上(公式 1),相應(yīng)的輸出被稱為 patch 嵌入。
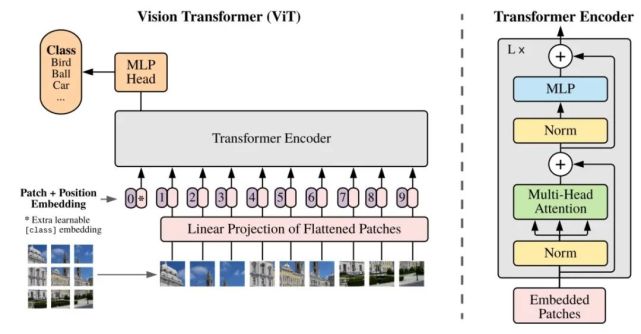
與 BERT 的 [class] token 類似,研究者在一系列嵌入 patch (z_0^0 = x_class)之前預(yù)先添加了一個可學(xué)習(xí)嵌入,它在 Transformer 編碼器(z_0^L )輸出中的狀態(tài)可以作為圖像表示 y(公式 4)。在預(yù)訓(xùn)練和微調(diào)階段,分類頭(head)依附于 z_L^0。
位置嵌入被添加到 patch 嵌入中以保留位置信息。研究者嘗試了位置嵌入的不同 2D 感知變體,但與標(biāo)準(zhǔn) 1D 位置嵌入相比并沒有顯著的增益。所以,編碼器以聯(lián)合嵌入為輸入。
Transformer 編碼器由多個交互層的多頭自注意力(MSA)和 MLP 塊組成(公式 2、3)。每個塊之前應(yīng)用 Layernorm(LN),而殘差連接在每個塊之后應(yīng)用。MLP 包含兩個呈現(xiàn) GELU 非線性的層。
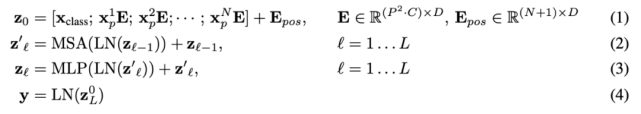
作為將圖像分割成 patch 的一種替代方案,輸出序列可以通過 ResNet 的中間特征圖來形成。在這個混合模型中,patch 嵌入投影(公式 1)被早期階段的 ResNet 取代。ResNet 的其中一個中間 2D 特征圖被扁平化處理成一個序列,映射到 Transformer 維度,然后饋入并作為 Transformer 的輸入序列。最后,如上文所述,將分類輸入嵌入和位置嵌入添加到 Transformer 輸入中。
微調(diào)和更高分辨率
研究者在大型數(shù)據(jù)集上預(yù)訓(xùn)練 ViT 模型,并針對更小規(guī)模的下游任務(wù)對模型進行微調(diào)。為此,研究者移除了預(yù)訓(xùn)練預(yù)測頭,并添加了一個零初始化的 D × K 前饋層,其中 K 表示下游類的數(shù)量。與預(yù)訓(xùn)練相比,在更高分辨率時進行微調(diào)通常更有益處。當(dāng)饋入更高分辨率的圖像時,研究者保持 patch 大小不變,從而得到更大的有效序列長度。
ViT 模型可以處理任意序列長度(取決于內(nèi)存約束),但預(yù)訓(xùn)練位置嵌入或許不再具有意義。所以,研究者根據(jù)預(yù)訓(xùn)練位置嵌入在原始圖像中的位置,對它們進行 2D 插值操作。需要注意的是,只有在分辨率調(diào)整和 patch 提取中,才能將 2D 圖像的歸納偏置手動注入到 ViT 模型中。
實驗
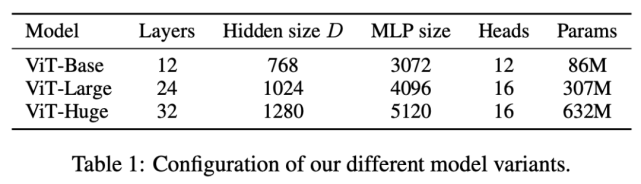
該研究進行了大量實驗,并使用了多個 ViT 模型變體,參見下表 1:
與 SOTA 模型的性能對比
研究者首先將最大的 ViT 模型(在 JFT-300M 數(shù)據(jù)集上預(yù)訓(xùn)練的 ViT-H/14 和 ViT-L/16)與 SOTA CNN 模型進行對比,結(jié)果參見下表 2。
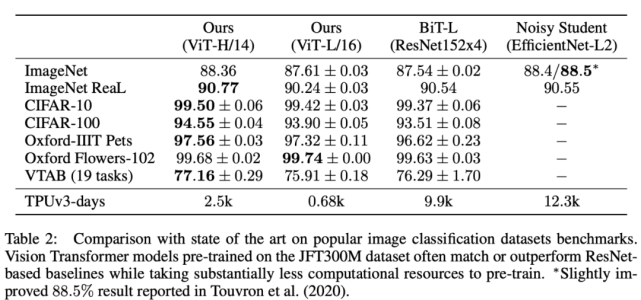
表 2:ViT 模型與 SOTA 模型在流行圖像分類基準(zhǔn)數(shù)據(jù)集上的性能對比。
從上表中可以看出,規(guī)模較小的 ViT-L/16 模型在所有數(shù)據(jù)集上的性能堪比或者超過 BiT-L,同時它需要的算力也少得多。較大的 ViTH-14 模型進一步提升了性能,尤其在更具挑戰(zhàn)性的數(shù)據(jù)集上,如 ImageNet、CIFAR-100 和 VTAB。ViTH-14 模型在所有數(shù)據(jù)集上的性能匹配或超過 SOTA,甚至在某些情況下大幅超過 SOTA 模型(如在 CIFAR-100 數(shù)據(jù)集上的性能高出 1%)。在 ImageNet 數(shù)據(jù)集上,ViT 模型的性能比 Noisy Student 低了大約 0.1%,不過在具備更干凈 ReaL 標(biāo)簽的 ImageNet 數(shù)據(jù)集上,ViT 的性能超過 SOTA 模型。
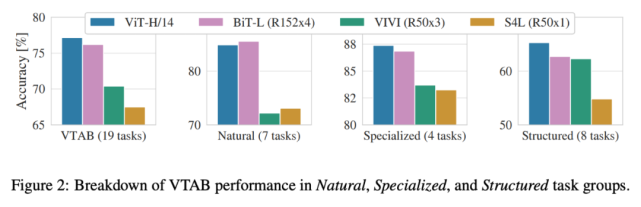
下圖 2 將 VTAB 任務(wù)分解為多個組,并對比了 ViT 與 SOTA 方法的性能,這些方法包括 BiT、VIVI 和 S4L。
在 Natural 任務(wù)中,ViT-H/14 的性能略低于 BiT-R152x4;在 Specialized 任務(wù)中,ViT 的性能超過 BiT 等方法;而在 Structured 任務(wù)中,ViT 顯著優(yōu)于其他方法。
預(yù)訓(xùn)練數(shù)據(jù)要求
Vision Transformer 在大型 JFT-300M 數(shù)據(jù)集上進行預(yù)訓(xùn)練后表現(xiàn)出了優(yōu)秀的性能。在 ViT 的歸納偏置少于 ResNet 的情況下,數(shù)據(jù)集規(guī)模的重要性幾何呢?該研究進行了一些實驗。
首先,在規(guī)模逐漸增加的數(shù)據(jù)集(ImageNet、ImageNet-21k 和 JFT300M)上預(yù)訓(xùn)練 ViT 模型。下圖 3 展示了模型在 ImageNet 數(shù)據(jù)集上的性能:
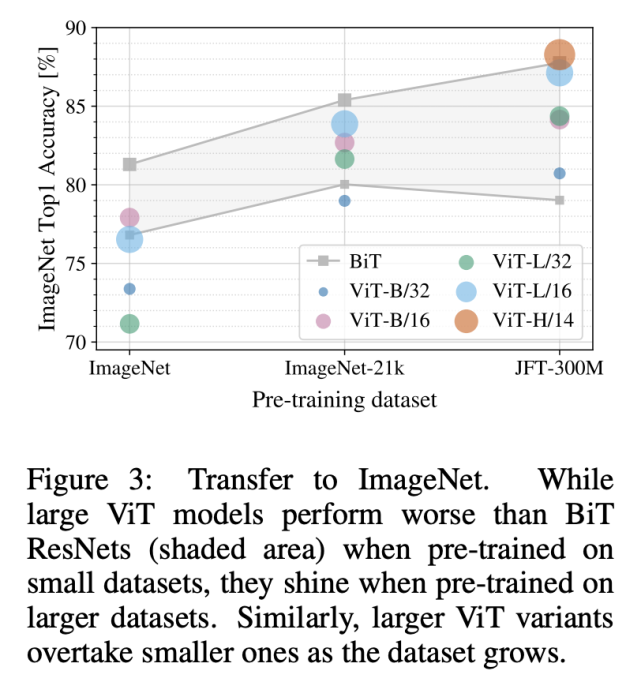
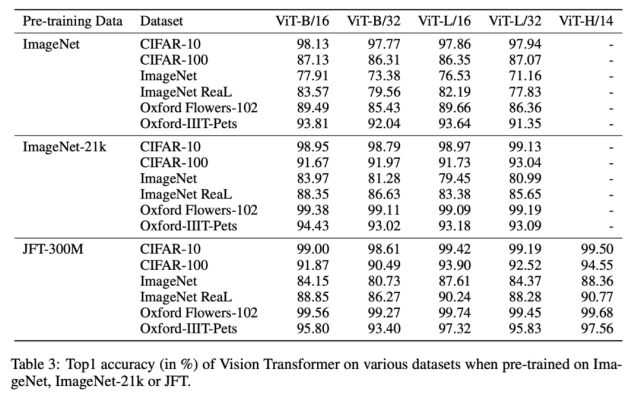
下表 3 展示了模型在 ImageNet、ImageNet-21k 和 JFT300M 數(shù)據(jù)集上的性能對比情況。在前兩個規(guī)模較小的數(shù)據(jù)集上,ViT-Large 模型的性能不如 ViT-Base,但在規(guī)模較大的 JFT300M 數(shù)據(jù)集上,大模型展現(xiàn)出了優(yōu)勢。這說明,隨著數(shù)據(jù)集規(guī)模的增大,較大的 ViT 模型變體優(yōu)于較小的模型。
其次,研究者在 JFT300M 數(shù)據(jù)集的 9M、30M 和 90M 隨機子集以及完整數(shù)據(jù)集上進行了模型訓(xùn)練。結(jié)果參見下圖 4:
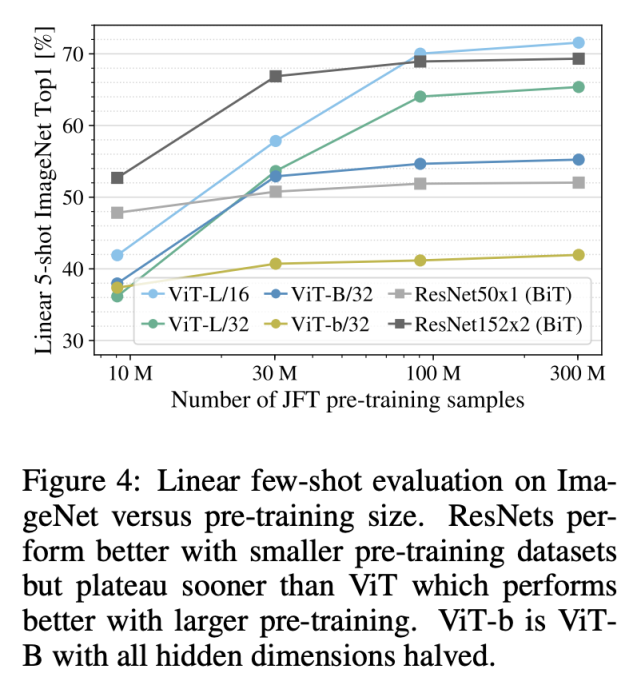
從圖中可以看到,在較小的數(shù)據(jù)集和相同的計算成本下,Vision Transformer 比 ResNet 更加過擬合。該結(jié)果強化了這一認(rèn)知:卷積歸納偏置對于規(guī)模較小的數(shù)據(jù)集較為有用,但對于較大的數(shù)據(jù)集而言,學(xué)習(xí)相關(guān)模式就足夠了,甚至更加有效。
可擴展性研究
研究人員對不同模型執(zhí)行了受控可擴展性研究(scaling study)。下圖 5 展示了模型在不同預(yù)訓(xùn)練計算成本情況下的遷移性能:
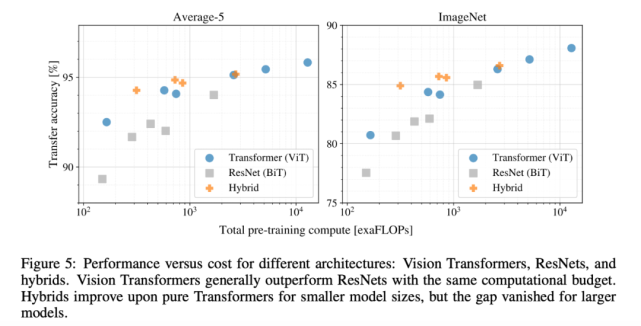
實驗結(jié)果表明:
Vision Transformer 在性能 / 算力權(quán)衡中顯著優(yōu)于 ResNet。
混合模型在較小計算成本的情況下略優(yōu)于 ViT,但在計算成本較高時,這一現(xiàn)象消失。該結(jié)果令人吃驚。
Vision Transformer 在實驗嘗試的算力范圍內(nèi)似乎并未飽和,未來可以進行更多可擴展性研究。
ViT 如何處理圖像數(shù)據(jù)?
為了了解 ViT 處理圖像數(shù)據(jù)的過程,研究者分析了其內(nèi)部表示。
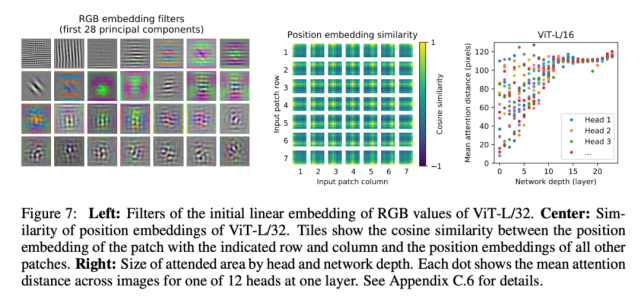
ViT 的第一層將扁平化后的圖像塊線性投影至低維空間(公式 1),下圖(左)展示了學(xué)得嵌入濾波器的主要組件。投影后,將學(xué)得的位置嵌入添加至圖像塊表示。下圖(中)展示了模型學(xué)習(xí)編碼圖像內(nèi)的距離,表明距離越近的圖像塊更有可能具備更相似的位置嵌入。自注意力允許 ViT 集成整個圖像的信息,即使最低層也不例外。研究者調(diào)查了 ViT 網(wǎng)絡(luò)利用這一能力的程度。具體而言,該研究計算圖像空間中的平均距離(基于注意力權(quán)重)參見下圖右。「注意力距離」類似于 CNN 中的感受野大小。
ViT 模型關(guān)注與分類具備語義相關(guān)性的圖像區(qū)域,參見圖 6:

在知乎問題「ICLR 2021 有什么值得關(guān)注的投稿?」下,多個回答提及了這篇論文,有解讀也有吐槽。更有網(wǎng)友表示:「我們正站在模型大變革的前夜,神經(jīng)網(wǎng)絡(luò)的潛力還遠(yuǎn)遠(yuǎn)沒到盡頭。一種嶄新的強大的,足以顛覆整個 CV 和 AI 界的新模型才露出冰山一角,即將全面來襲。」

參考鏈接:
https://openreview.net/pdf?id=YicbFdNTTy
https://www.zhihu.com/question/423975807
如何根據(jù)任務(wù)需求搭配恰當(dāng)類型的數(shù)據(jù)庫?
在AWS推出的白皮書《進入專用數(shù)據(jù)庫時代》中,介紹了8種數(shù)據(jù)庫類型:關(guān)系、鍵值、文檔、內(nèi)存中、關(guān)系圖、時間序列、分類賬、領(lǐng)域?qū)捔校⒅鹨环治隽嗣糠N類型的優(yōu)勢、挑戰(zhàn)與主要使用案例。