大數(shù)據(jù)三大主流平臺(tái)框架的比較
在大數(shù)據(jù)的處理上,起到關(guān)鍵性作用的就是大數(shù)據(jù)框架,通過大數(shù)據(jù)系統(tǒng)框架,實(shí)現(xiàn)對(duì)大規(guī)模數(shù)據(jù)的整合處理。從人工統(tǒng)計(jì)分析到計(jì)算機(jī),再到今天的分布式計(jì)算平臺(tái),數(shù)據(jù)處理速度飛速提高的背后是整體架構(gòu)的不斷演進(jìn)。當(dāng)今,市面上可用的大數(shù)據(jù)框架很多,最流行的莫過于Hadoop,Spark以及Storm這三種了,Hadoop是主流,然而Spark和Storm這兩個(gè)后起之秀也正以迅猛之勢(shì)快速發(fā)展。接下來(lái)讓我們一起了解一下這三個(gè)平臺(tái)。
1、Hadoop
說(shuō)到大數(shù)據(jù),首先想到的肯定是Hadoop,因?yàn)镠adoop是目前世界上使用最廣泛的大數(shù)據(jù)工具。具有良好的跨平臺(tái)性,并且可部署在廉價(jià)的計(jì)算機(jī)集群中,在業(yè)內(nèi)應(yīng)用非常廣泛,是的代名詞,也是分布式計(jì)算架構(gòu)的鼻祖。憑借極高的容錯(cuò)率和極低的硬件價(jià)格,在大數(shù)據(jù)市場(chǎng)上蒸蒸日上。幾乎所有主流廠商都圍繞Hadoop進(jìn)行開發(fā)和提供服務(wù),如谷歌、百度、思科、華為、阿里巴巴、微軟都支持Hadoop。到目前為止,Hadoop已經(jīng)成為一個(gè)巨大的生態(tài)系統(tǒng),并且已經(jīng)實(shí)現(xiàn)了大量的算法和組件。
Hadoop框架當(dāng)中最主要的單個(gè)組件就是HDFS、MapReduce以及Yarn。
在大數(shù)據(jù)處理環(huán)節(jié)當(dāng)中,HDFS負(fù)責(zé)數(shù)據(jù)存儲(chǔ),MapReduce負(fù)責(zé)數(shù)據(jù)計(jì)算,Yarn負(fù)責(zé)資源調(diào)度。基于這三個(gè)核心組件,Hadoop可以實(shí)現(xiàn)對(duì)大規(guī)模數(shù)據(jù)的高效處理,同時(shí)Hadoop出色的故障處理機(jī)制,支持高可伸縮性,容錯(cuò)能力,具有高可用性,更適合大數(shù)據(jù)平臺(tái)研發(fā)。
但是Hadoop存在比較大的一個(gè)局限就是,處理數(shù)據(jù)主要是離線處理,對(duì)于大規(guī)模離線數(shù)據(jù)處理很有一套,但是對(duì)于時(shí)效性要求很高的數(shù)據(jù)處理任務(wù),不能實(shí)現(xiàn)很好的完成。

作為一種對(duì)大量數(shù)據(jù)進(jìn)行分布式處理的軟件框架,Hadoop具有以下幾方面特點(diǎn):

Hadoop架構(gòu)大幅提升了計(jì)算存儲(chǔ)性能,降低計(jì)算平臺(tái)的硬件投入成本。但是由于計(jì)算過程放在硬盤上,受制于硬件條件限制,數(shù)據(jù)的吞吐和處理速度明顯不如使用內(nèi)存快,尤其是在使用Hadoop進(jìn)行迭代計(jì)算時(shí),非常耗資源,且在開發(fā)過程中需要編寫不少相對(duì)底層的代碼,不夠高效。
2、Spark
基于Hadoop在實(shí)時(shí)數(shù)據(jù)處理上的局限,Spark與Storm框架應(yīng)運(yùn)而生,具有改進(jìn)的數(shù)據(jù)流處理的批處理框架,通過內(nèi)存計(jì)算,實(shí)現(xiàn)對(duì)大批量實(shí)時(shí)數(shù)據(jù)的處理,基于Hadoop架構(gòu),彌補(bǔ)了Hadoop在實(shí)時(shí)數(shù)據(jù)處理上的不足。為了使程序運(yùn)行更快,Spark提供了內(nèi)存計(jì)算,減少了迭代計(jì)算時(shí)的I/O開銷。Spark不但具備Hadoop MapReduce的優(yōu)點(diǎn),而且解決了其存在的缺陷,逐漸成為當(dāng)今領(lǐng)域最熱門的計(jì)算平臺(tái)。
作為大數(shù)據(jù)框架的后起之秀,Spark具有更加高效和快速的計(jì)算能力,其特點(diǎn)主要有:

我們知道計(jì)算模式主要有四種,除了圖計(jì)算這種特殊類型,其他三種足以應(yīng)付大部分應(yīng)用場(chǎng)景,因?yàn)閷?shí)際應(yīng)用中處理主要就是這三種:復(fù)雜的批量數(shù)據(jù)處理、基于歷史數(shù)據(jù)的交互式查詢和基于實(shí)時(shí)數(shù)據(jù)流的數(shù)據(jù)處理。
Hadoop MapReduce主要用于計(jì)算,Hive和Impala用于交互式查詢,Storm主要用于流式數(shù)據(jù)處理。以上都只能針對(duì)某一種應(yīng)用,但如果同時(shí)存在三種應(yīng)用需求,Spark就比較合適了。因?yàn)镾park的設(shè)計(jì)理念就是“一個(gè)軟件棧滿足不同應(yīng)用場(chǎng)景”,它有一套完整的生態(tài)系統(tǒng),既能提供內(nèi)存計(jì)算框架,也可支持多種類型計(jì)算(能同時(shí)支持、流式計(jì)算和交互式查詢),提供一站式解決方案。
此外,Spark還能很好地與Hadoop生態(tài)系統(tǒng)兼容,Hadoop應(yīng)用程序可以非常容易地遷移到Spark平臺(tái)上。
除了數(shù)據(jù)存儲(chǔ)需借助Hadoop的HDFS或Amazon S3之外,其主要功能組件包括Spark Core(基本通用功能,可進(jìn)行復(fù)雜的批處理計(jì)算)、Spark SQL(支持基于歷史數(shù)據(jù)的交互式查詢計(jì)算)、Spark Streaming(支持實(shí)時(shí)流式計(jì)算)、MLlib(提供常用機(jī)器學(xué)習(xí),支持基于歷史數(shù)據(jù)的數(shù)據(jù)挖掘)和GraphX(支持圖計(jì)算)等。
盡管Spark有很多優(yōu)點(diǎn),但它并不能完全替代Hadoop,而是主要替代MapReduce計(jì)算模型。Spark沒有像Hadoop那樣有數(shù)萬(wàn)個(gè)級(jí)別的集群,所以在實(shí)際應(yīng)用中,Spark常與Hadoop結(jié)合使用,它可以借助YARN來(lái)實(shí)現(xiàn)資源調(diào)度管理,借助HDFS實(shí)現(xiàn)分布式存儲(chǔ)。此外,比起Hadoop可以用大量廉價(jià)計(jì)算機(jī)集群進(jìn)行分布式存儲(chǔ)計(jì)算(成本低),Spark對(duì)硬件要求較高,成本也相對(duì)高一些。
3、Storm
與Hadoop的批處理模式不同,Storm使用一個(gè)流計(jì)算框架,該框架由Twitter開源,托管在GitHub上。與Hadoop相似,Storm也提出了兩個(gè)計(jì)算角色,Spout和Bolt。
如果說(shuō)Hadoop是一個(gè)水桶,一次只能在一口井里裝一個(gè)水桶,那么Storm是一個(gè)水龍頭,它可以打開來(lái)連續(xù)生產(chǎn)水。Storm還支持許多語(yǔ)言,如Java、Ruby、Python等。因?yàn)镾torm是一個(gè)流計(jì)算框架,它使用內(nèi)存,這在延遲方面有很大優(yōu)勢(shì),但是Storm不會(huì)持久化數(shù)據(jù)。
但Storm的缺點(diǎn)在于,無(wú)論是離線、高延遲,還是交互式查詢,它都不如Spark框架。不同的機(jī)制決定了二者所適用的場(chǎng)景不同,比如炒股,股價(jià)的變化不是按秒計(jì)算的,因此適合采用計(jì)算延遲度為秒級(jí)的Spark框架;而在高頻交易中,高頻獲利與否往往就在1ms之間,就比較適合采用實(shí)時(shí)計(jì)算延遲度的Storm框架。
Storm對(duì)于實(shí)時(shí)計(jì)算的意義類似于Hadoop對(duì)于的意義,可以簡(jiǎn)單、高效、可靠地處理流式數(shù)據(jù)并支持多種語(yǔ)言,它能與多種系統(tǒng)進(jìn)行整合,從而開發(fā)出更強(qiáng)大的實(shí)時(shí)計(jì)算系統(tǒng)。
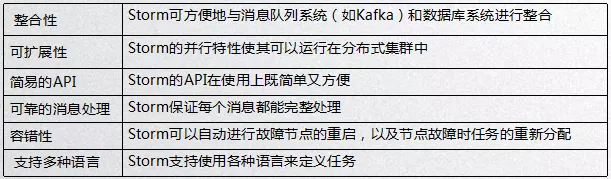
作為一個(gè)實(shí)時(shí)處理流式數(shù)據(jù)的計(jì)算框架,Storm的特點(diǎn)如下:
就像目前云計(jì)算市場(chǎng)中風(fēng)頭最勁的混合云一樣,越來(lái)越多的組織和個(gè)人采用混合式大數(shù)據(jù)平臺(tái)架構(gòu),因?yàn)槊糠N架構(gòu)都有其自身的優(yōu)缺點(diǎn)。
比如Hadoop,其數(shù)據(jù)處理速度和難易度都遠(yuǎn)不如Spark和Storm,但是由于硬盤斷電后其數(shù)據(jù)可以長(zhǎng)期保存,因此在處理需要長(zhǎng)期存儲(chǔ)的數(shù)據(jù)時(shí)還需要借助于它。不過由于Hadoop具有非常好的兼容性,因此也非常容易同Spark和Storm相結(jié)合使用,從而滿足不同組織和個(gè)人的差異化需求。
考慮到網(wǎng)絡(luò)安全態(tài)勢(shì)所應(yīng)用的場(chǎng)景,即大部分是復(fù)雜批量數(shù)據(jù)處理(日志事件)和基于歷史數(shù)據(jù)的交互式查詢以及數(shù)據(jù)挖掘,對(duì)準(zhǔn)實(shí)時(shí)流式數(shù)據(jù)處理也會(huì)有一部分需求(如會(huì)話流的檢測(cè)分析),建議其大數(shù)據(jù)平臺(tái)采用Hadoop和Spark相結(jié)合的建設(shè)模式。
大數(shù)據(jù)處理的框架是一直在不斷更新優(yōu)化的,沒有哪一種結(jié)構(gòu)能夠?qū)崿F(xiàn)對(duì)大數(shù)據(jù)的完美處理,在真正的大數(shù)據(jù)平臺(tái)開發(fā)上,需要根據(jù)實(shí)際需求來(lái)考量。