













孤立森林:大數據背景下的最佳異常檢測算法
孤立森林或者"iForest"是一個優美動人,簡潔優雅的算法,只需少量參數就可以檢測出異常點。原始論文中只包含了最基本的數學,因而對于廣大群眾而言是通俗易懂的。在這篇文章中,我會總結這個算法,以及其歷史,并分享我實現的代碼來解釋為什么iForest是現在針對大數據而言最好的異常檢測算法。
為什么iForest是現在處理大數據最好的異常檢測算法
總結來說,它在同類算法中有最好的表現。iForest在多種數據集上的ROC表現和精確度都比大多數其他的異常檢測算法要好。我從Python Outlier Detection package的作者們那里取得了基準數據,并在Excel中逐行使用綠-紅梯度的條件格式化。用深綠色來標識那些在這個數據集上有最好的表現的算法,并用深紅色來標識那些表現得最差的:
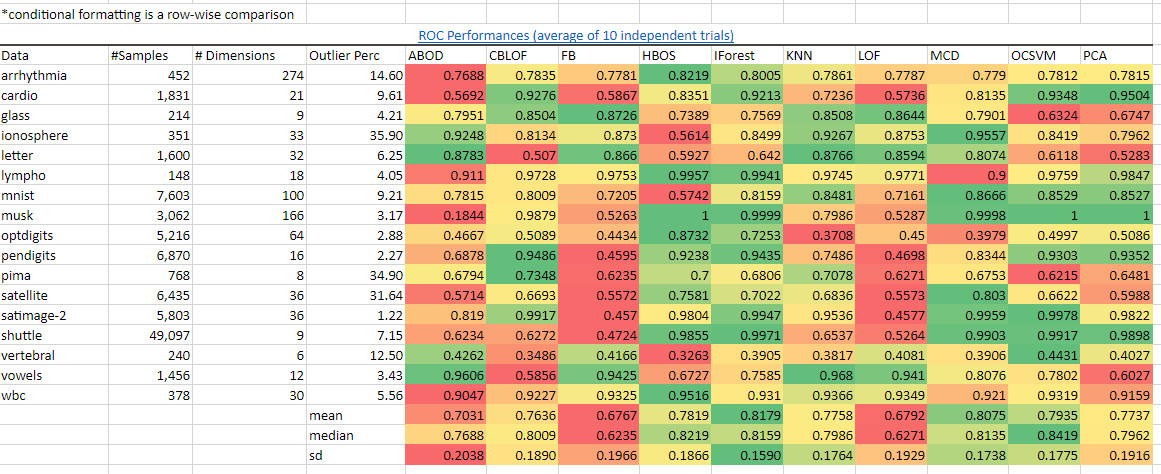
綠色表示"好"而紅色表示"差"。我們看到IForest在很多的數據集以及總體的角度上是領先的,正如平均值,中位數,標準差的顏色所表示。圖源:作者。數據源:https://pyod.readthedocs.io/en/latest/benchmark.html
我們看到IForest在很多的數據集上以及總體上的表現是領先的,正如我計算出來的平均值,中位數,標準差的顏色所表示的一樣。從precision@N(最重要的N項指標的準確度)的表現來看iForest也能得出同樣的優秀結果。
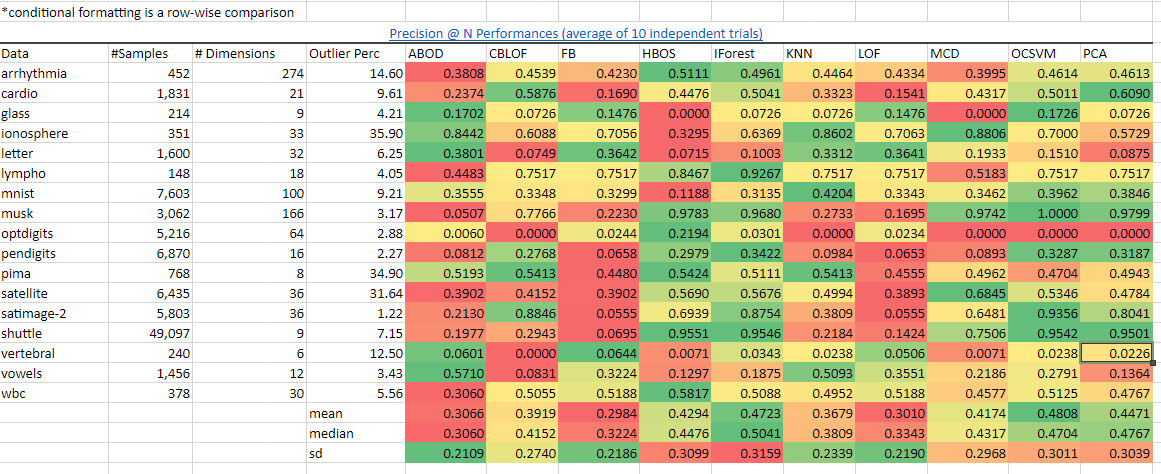
源:https://pyod.readthedocs.io/en/latest/benchmark.html
可擴展性。iForest以它表現出來的性能為標準而言是最快的算法。可以預料到的是,PCA和基于頻數直方圖的異常點檢測算法(HBOS)在所有的數據集上都有更快的速度。
k近鄰算法(KNN)則要慢得多并且隨著數據量變多它會變得越來越慢。
我已經成功地在一個包含一億個樣本和三十六個特征的數據集上構建出孤立森林,在一個集群環境中這需要幾分鐘。而這是我認為sklearn的KNN算法沒辦法做到的。
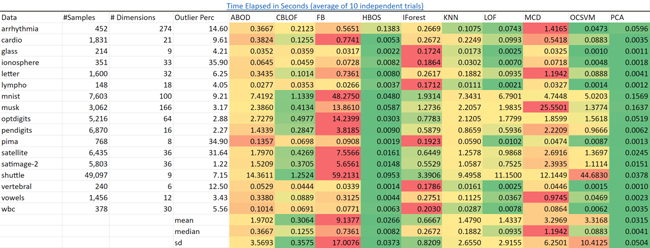
源:https://pyod.readthedocs.io/en/latest/benchmark.html
算法要點/總結
我通過下面的綜述來非常簡潔地總結原來有10頁內容的論文:
- 大多數其他異常檢測(OD)算法嘗試去建立"正常"數據的范圍,從而把不屬于這個正常范疇的個體標注為不正常。iForest則直接通過利用異常點的隱含特質來把他們分隔開:他們在協變量集上會擁有不尋常的值。
- 現有的方法由于計算成本的原因只能被用在低維數據或者小數據集上。一個恰當的例子是:你會在大數據上使用sklearn.neighbor.KNeighborsClassifier嗎?
- 此外,iForest只需要很少的常量和很低的內存需求。也就是說,低開銷。特別地:外部節點的數量是n,因為每個觀測數據,n,都會被孤立。內部節點的總數顯然是n-1,從而總體節點數會是2n-1。因此,我們可以理解為什么需要的內存是有界的,而且隨著樣本數量n線性增加。
孤立樹節點的定義: T 或是一個沒有子節點的葉子節點,或者是一個經過檢驗的內部節點,并擁有兩個子節點(Tl,Tr)。我們通過遞歸地進行下述過程來構造一棵iTree:隨機選擇一項特征q和一個分割值p來劃分X,直到發生下列情形之一為止:(i)樹到達了限制的高度,(ii)所有樣本被孤立成一個只有他們自己的外部節點,或者(iii)所有數據的所有特征都有相同的值。
路徑長度:一個樣本x的路徑長度h(x)指的是從iTree的根節點走到葉子節點所經歷的邊的數量。E(h(x))是一組孤立樹的h(x)的平均值。從這個路徑長度的平均值,我們可以通過公式E(h(x)):s(x, n) = 2^[^[− E(h(x)) / c(n)]來得到一個異常分數s(x,n)。基本上,s和E(h(x))之間存在一個單調的關系。(想知道細節的話請查閱文末的附錄,有一張圖描述了他們之間的關系)。這里我不會討論c(n),因為對于任意給定的靜態數據集而言它是一個常數。
用戶只需要設置兩個變量:孤立樹的數量和訓練單棵樹的子采樣大小。作者通過對用高斯分布生成的數據做實驗來展示了只需要少量的幾棵樹和少量的子采樣數量就可以使平均路徑長度很快地收斂。
小的子采樣數量(抽樣的抽樣)解決了swamping和masking問題。造成這兩個問題的原因是輸入的數據量對于異常檢測這個問題來說太大了。Swamping是指由于某個"正常"的樣本點被異常點所包圍而被錯誤地標注為"異常",masking則是相反的情況。也就是說,如果構建一個樹的樣本中有很多異常點,一個正常的數據點反而會看起來很異常。作者使用乳房x線照相的數據來作為這個現象的一個例子。
小的子采樣數量使得每一棵孤立樹都具有獨特性,因為每一次子采樣都包含一組不同的異常點或者甚至沒有異常點。
iForest不依賴距離或者密度的測量來識別異常點,因此它計算成本低廉且有較快的速度。這引出了下一個議題。
線性的時間復雜度,O(n)。不正規地說,這意味著運行時間隨著輸入大小的增加最多只會線性增加。這是一個非常好的性質:
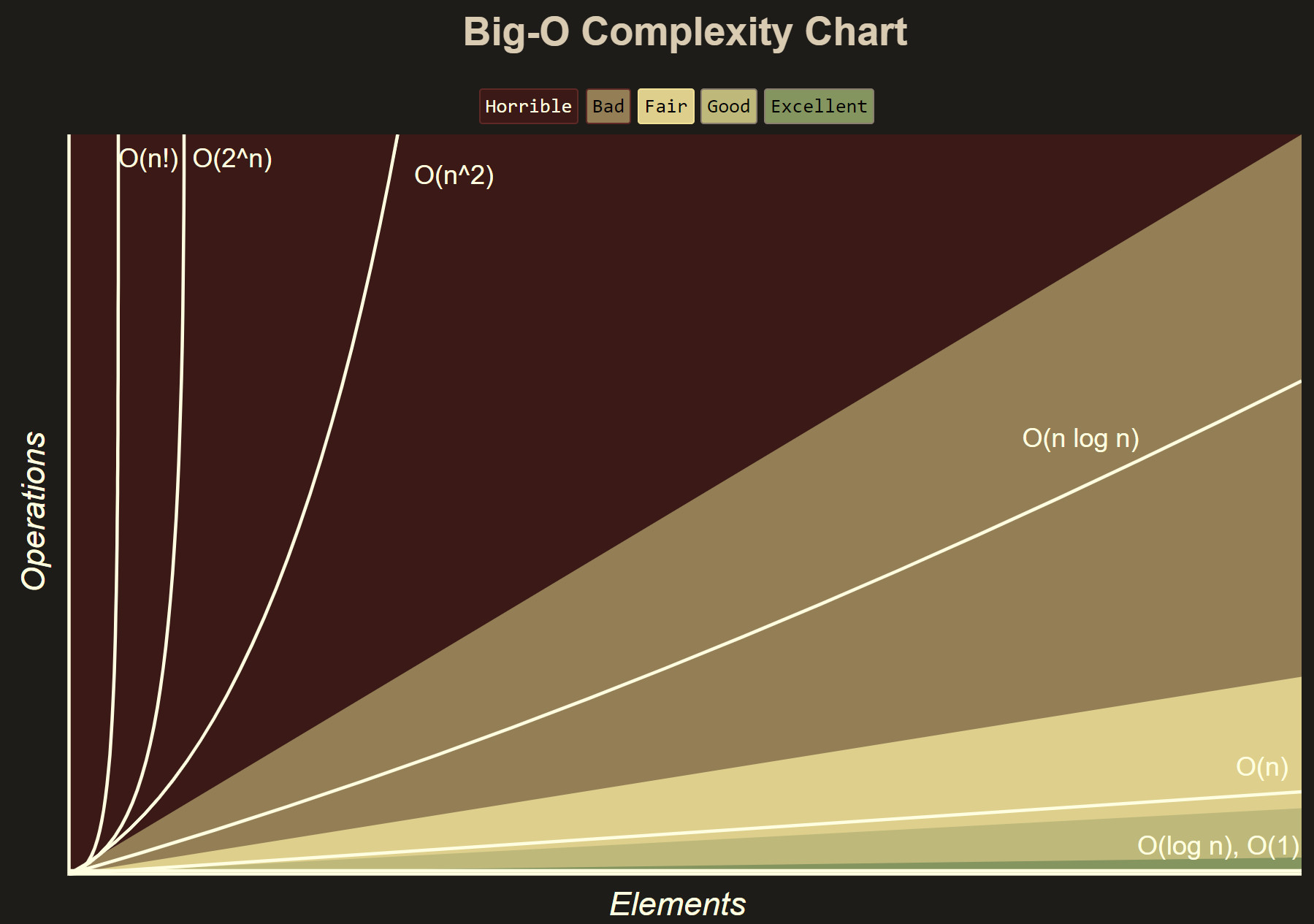
算法歷程
見多識廣的讀者應該知道一個優秀的新想法出現與它的廣泛應用之間可能會有數十年之久的間隔。例如,邏輯函數在1845年被發現,在1922年被重新發現(更多信息可參考)而到如今才被數據科學家頻繁地用于邏輯回歸。在最近幾十年,一個新想法和它被廣泛應用的間隔時間已經變得更短了,但這仍然需要一段相對較為漫長的時間。iForest最先在2008年公開,但直到2018年后期才出現了可行的商業應用。 這是其時間線:
- 12/2008 -iForest的原始論文發布(論文)
- 07/2009 -iForest的作者們最后一次修改其代碼實現(代碼)
- 10/2018 -h2o小組實現了Python版和R版的iForest(代碼)
- 01/2019 -PyOD在Python上發布了異常檢測工具包(代碼,論文)
- 08/2019 -Linkedln 工程小組發布了 iForest的Spark/Scala版本實現(代碼,通訊稿)
代碼實現
由于這篇文章是關于大數據的,我采用了AWS的集群環境。這里省略的大部分的腳手架(軟件質量保證和測試之類的代碼)的代碼。如果在配置AWS集群環境中需要幫助,可以參考我的文章:如何為SparkSQL搭建高效的AWS
EMR集群和Jupyter Notebooks
我發現iForest能很輕易且快捷地處理750萬行,36個特征的數據,只需幾分鐘就完成計算。
Python(h2o):
- import h2o # h2o automated data cleaning well for my datasetimport pkg_resources################################################################### print packages + versions for debugging/future reproducibility ###################################################################dists = [d for d in pkg_resources.working_set] # Filter out distributions you don't care about and use.dists.reverse()
- dists################################################################### initialize h2o cluster and load data##################################################################h2o.init() # import pyarrow.parquet as pq # allow loading of parquet filesimport s3fs # for working in AWS s3s3 = s3fs.S3FileSystem()df = pq.ParquetDataset('s3a://datascience-us-east-1/anyoung/2_processedData/stack_parquetFiles', filesystem=s3).read_pandas().to_pandas()# check input data loaded correctly; pretty print .shapeprint('(' + '; '.join(map('{:,.0f}'.format,
- df.shape)) + ')')# if you need to sample datadf_samp_5M = df.sample(n=5000000, frac=None, replace=False, weights=None, random_state=123, axis=None)# convert Pandas DataFrame object to h2o DataFrame objecthf = h2o.H2OFrame(df)# drop primary key columnhf = hf.drop('referenceID', axis = 1) # referenceID causes errors in subsequent code# you can omit rows with nas for a first passhf_clean = hf.na_omit()# pretty print .shape with thousands comma separatorprint('(' + '; '.join(map('{:,.0f}'.format,
- hf.shape)) + ')')from h2o.estimators import H2OIsolationForestEstimatorfrom h2o.estimators import H2OIsolationForestEstimator
- fullX = ['v1',
- 'v2',
- 'v3' ]# split h2o DataFrame into 80/20 train/testtrain_hf, valid_hf = hf.split_frame(ratios=[.8], seed=123)# specify iForest estimator modelsisolation_model_fullX = H2OIsolationForestEstimator(model_id = "isolation_forest_fullX.hex", seed = 123)
- isolation_model_fullX_cv = H2OIsolationForestEstimator(model_id = "isolation_forest_fullX_cv.hex", seed = 123)# train iForest modelsisolation_model_fullX.train(training_frame = hf, x = fullX)
- isolation_model_fullX_cv.train(training_frame = train_hf, x = fullX)# save models (haven't figured out how to load from s3 w/o permission issues yet)modelfile = isolation_model_fullX.download_mojo(path="~/", get_genmodel_jar=True)print("Model saved to " + modelfile)# predict modelspredictions_fullX = isolation_model_fullX.predict(hf)# visualize resultspredictions_fullX["mean_length"].hist()
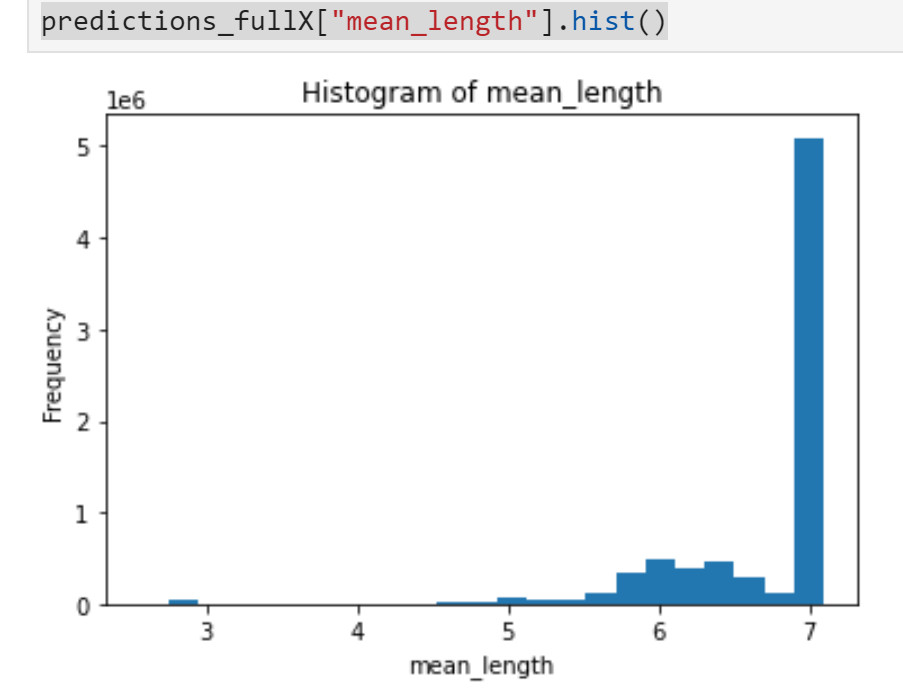
如果你使用iForest來驗證你的帶標簽數據,你可以通過比較數據集中的正常數據的分布,異常數據的分布,以及原來數據集的分布來進行進一步推理。例如,你可以查看原本數據集中不同的特征組合,像這樣:
- N = df.count()
- df[['v1', 'v2', 'id']].groupby(['v1', 'v2']).count() / N
- df[['v1', 'v3', 'id']].groupby(['v1', 'v3']).count() / N
- ...
并與使用iForest得出的正常/異常數據集進行比較。正如下面所展示的這樣:
- ################################################################### column bind predictions from iForest to the original h2o DataFrame##################################################################hf_X_y_fullX = hf.cbind(predictions_fullX)################################################################### Slice using a boolean mask. The output dataset will include rows # with column value meeting condition##################################################################mask = hf_X_y_fullX["label"] == 0hf_X_y_fullX_0 = hf_X_y_fullX[mask,:]
- mask = hf_X_y_fullX["label"] == 1hf_X_y_fullX_1 = hf_X_y_fullX[mask,:]################################################################### Filter to only include records that are clearly normal##################################################################hf_X_y_fullX_ml7 = hf_X_y_fullX[hf_X_y_fullX['mean_length'] >= 7]
- hf_X_y_fullX_0_ml7 = hf_X_y_fullX_1[hf_X_y_fullX_0['mean_length'] >= 7]
- hf_X_y_fullX_1_ml7 = hf_X_y_fullX_3[hf_X_y_fullX_1['mean_length'] >= 7]################################################################### Convert to Pandas DataFrame for easier counting/familiarity##################################################################hf_X_y_fullX_ml7_df = h2o.as_list(hf_X_y_fullX_ml7, use_pandas = True)
- hf_X_y_fullX_0_ml7_df = h2o.as_list(hf_X_y_fullX_0_ml7, use_pandas = True)
- hf_X_y_fullX_1_ml7_df = h2o.as_list(hf_X_y_fullX_1_ml7, use_pandas = True)################################################################### Look at counts by combinations of variable levels for inference##################################################################hf_X_y_fullX_ml7_df[['v1', 'v2', 'id']].groupby(['v1', 'v2']).count()
- hf_X_y_fullX_0_ml7_df = h2o.as_list(hf_X_y_fullX_0_ml7, use_pandas = True)...# Repeat above for anomalous records:################################################################### Filter to only include records that are clearly anomalous##################################################################hf_X_y_fullX_ml3 = hf_X_y_fullX[hf_X_y_fullX['mean_length'] < 3]
- hf_X_y_fullX_0_ml3 = hf_X_y_fullX_1[hf_X_y_fullX_0['mean_length'] < 3]
- hf_X_y_fullX_1_ml3 = hf_X_y_fullX_3[hf_X_y_fullX_1['mean_length'] < 3]################################################################### Convert to Pandas DataFrame for easier counting/familiarity##################################################################hf_X_y_fullX_ml3_df = h2o.as_list(hf_X_y_fullX_ml3, use_pandas = True)
- hf_X_y_fullX_0_ml3_df = h2o.as_list(hf_X_y_fullX_0_ml3, use_pandas = True)
- hf_X_y_fullX_1_ml3_df = h2o.as_list(hf_X_y_fullX_1_ml3, use_pandas = True)
我完整地實現了上面的代碼并把我的數據輸出到Excel中,很快就可以得到如下的一些累積分布函數:

代表的是標識為0的樣本,被認為有可能是異常的。
參考文獻
- F. T. Liu, K. M. Ting, and Z.-H. Zhou.孤立森林. 在:第八屆IEEE數據挖掘國際會議的期間(ICDM' 08),Pisa,Italy,2008,pp.413-422.[代碼]這篇文章在IEEE ICDM'08榮獲了最佳理論/算法論文獎的第二名
- Zhao, Y., Nasrullah, Z. and Li, Z., 2019. PyOD:一個可量化的異常檢測Python工具箱.Journal of machine learning research (JMLR) , 20(96),pp.1-7.
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。


















