爬蟲解析提取數據的四種方法
一、分析網頁
以經典的爬取豆瓣電影 Top250 信息為例。每條電影信息在 ol class 為 grid_view 下的 li 標簽里,獲取到所有 li 標簽的內容,然后遍歷,就可以從中提取出每一條電影的信息。
翻頁查看url變化規律:
- 第1頁:https://movie.douban.com/top250?start=0&filter=
- 第2頁:https://movie.douban.com/top250?start=25&filter=
- 第3頁:https://movie.douban.com/top250?start=50&filter=
- 第10頁:https://movie.douban.com/top250?start=225&filter=
start參數控制翻頁,start = 25 * (page - 1)
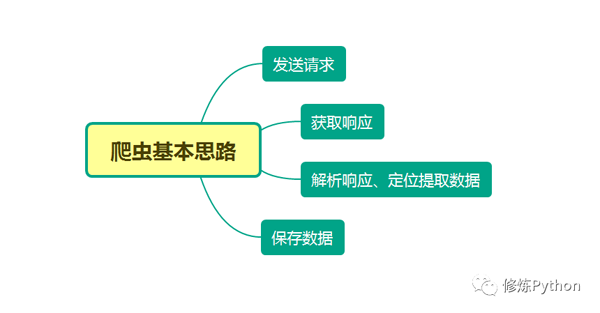
本文分別利用正則表達式、BeautifulSoup、PyQuery、Xpath來解析提取數據,并將豆瓣電影 Top250 信息保存到本地。
二、正則表達式
正則表達式是一個特殊的字符序列,它能幫助你方便地檢查一個字符串是否與某種模式匹配,常用于數據清洗,也可以順便用于爬蟲,從網頁源代碼文本中匹配出我們想要的數據。
re.findall
- 在字符串中找到正則表達式所匹配的所有子串,并返回一個列表,如果沒有找到匹配的,則返回空列表。
- 注意:match和 search 是匹配一次;而 findall 匹配所有。
- 語法格式為:findall(string[, pos[, endpos]])
- string : 待匹配的字符串;pos : 可選參數,指定字符串的起始位置,默認為 0;endpos : 可選參數,指定字符串的結束位置,默認為字符串的長度。
示例如下:
- import re
- text = """
- <div class="box picblock col3" style="width:186px;height:264px">
- <img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26584_s.jpg" 123nfsjgnalt="山水風景攝影圖片">
- <a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
- <img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26518_s.jpg" enrberonbialt="山脈湖泊山水風景圖片">
- <a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
- <img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202006/apic26029_s.jpg" woenigoigniefnirneialt="旅游景點山水風景圖片">
- <a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
- """
- pattern = re.compile(r'\d+') # 查找所有數字
- result1 = pattern.findall('me 123 rich 456 money 1000000000000')
- print(result1)
- img_info = re.findall('<img src2="(.*?)" .*alt="(.*?)">', text) # 匹配src2 alt里的內容
- for src, alt in img_info:
- print(src, alt)
- ['123', '456', '1000000000000']
- http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26584_s.jpg 山水風景攝影圖片
- http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26518_s.jpg 山脈湖泊山水風景圖片
- http://pic2.sc.chinaz.com/Files/pic/pic9/202006/apic26029_s.jpg 旅游景點山水風景圖片
代碼如下:
- # -*- coding: UTF-8 -*-
- """
- @Author :葉庭云
- @公眾號 :修煉Python
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- import re
- from pandas import DataFrame
- from fake_useragent import UserAgent
- import logging
- # 日志輸出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 隨機產生請求頭
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "Connection": "keep-alive",
- "User-Agent": ua.random
- }
- return headers
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('請求網頁失敗')
- def get_data(page):
- url = f"https://movie.douban.com/top250?start={25 * page}&filter="
- html_text = scrape_html(url)
- # 電影名稱 導演 主演
- name = re.findall('<img width="100" alt="(.*?)" src=".*"', html_text)
- director_actor = re.findall('(.*?)<br>', html_text)
- director_actor = [item.strip() for item in director_actor]
- # 上映時間 上映地區 電影類型信息 去除兩端多余空格
- info = re.findall('(.*) / (.*) / (.*)', html_text)
- time_ = [x[0].strip() for x in info]
- area = [x[1].strip() for x in info]
- genres = [x[2].strip() for x in info]
- # 評分 評分人數
- rating_score = re.findall('<span class="rating_num" property="v:average">(.*)</span>', html_text)
- rating_num = re.findall('<span>(.*?)人評價</span>', html_text)
- # 一句話引言
- quote = re.findall('<span class="inq">(.*)</span>', html_text)
- data = {'電影名': name, '導演和主演': director_actor,
- '上映時間': time_, '上映地區': area, '電影類型': genres,
- '評分': rating_score, '評價人數': rating_num, '引言': quote}
- df = DataFrame(data)
- if page == 0:
- df.to_csv('movie_data2.csv', mode='a+', header=True, index=False)
- else:
- df.to_csv('movie_data2.csv', mode='a+', header=False, index=False)
- logging.info(f'已爬取第{page + 1}頁數據')
- if __name__ == '__main__':
- for i in range(10):
- get_data(i)
三、BeautifulSoup
find( )與 find_all( ) 是 BeautifulSoup 對象的兩個方法,它們可以匹配 html 的標簽和屬性,把 BeautifulSoup 對象里符合要求的數據都提取出來:
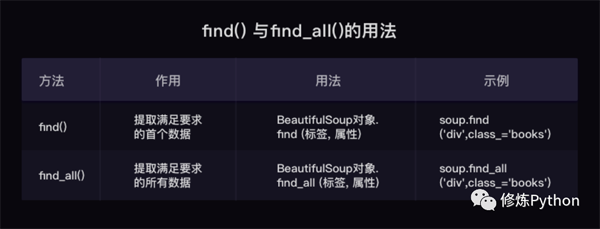
- find( )只提取首個滿足要求的數據
- find_all( )提取出的是所有滿足要求的數據
- find( ) 或 find_all( ) 括號中的參數:標簽和屬性可以任選其一,也可以兩個一起使用,這取決于我們要在網頁中提取的內容。括號里的class_,這里有一個下劃線,是為了和 python 語法中的類 class 區分,避免程序沖突。當然,除了用 class 屬性去匹配,還可以使用其它屬性,比如 style 屬性等;只用其中一個參數就可以準確定位的話,就只用一個參數檢索。如果需要標簽和屬性同時滿足的情況下才能準確定位到我們想找的內容,那就兩個參數一起使用。

代碼如下:
- # -*- coding: UTF-8 -*-
- """
- @Author :葉庭云
- @公眾號 :修煉Python
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- from bs4 import BeautifulSoup
- import openpyxl
- from fake_useragent import UserAgent
- import logging
- # 日志輸出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 隨機產生請求頭
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook() # 創建工作簿對象
- sheet = wb.active # 獲取工作簿的活動表
- sheet.title = "movie" # 工作簿重命名
- sheet.append(["排名", "電影名", "導演和主演", "上映時間", "上映地區", "電影類型", "評分", "評價人數", "引言"])
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "Connection": "keep-alive",
- "User-Agent": ua.random
- }
- return headers
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('請求網頁失敗')
- def get_data(page):
- global rank
- url = f"https://movie.douban.com/top250?start={25 * page}&filter="
- html_text = scrape_html(url)
- soup = BeautifulSoup(html_text, 'html.parser')
- lis = soup.find_all('div', class_='item')
- for li in lis:
- name = li.find('div', class_='hd').a.span.text
- temp = li.find('div', class_='bd').p.text.strip().split('\n')
- director_actor = temp[0]
- temptemp1 = temp[1].rsplit('/', 2)
- time_, area, genres = [item.strip() for item in temp1]
- quote = li.find('p', class_='quote')
- # 有些電影信息沒有一句話引言
- if quote:
- quotequote = quote.span.text
- else:
- quote = None
- rating_score = li.find('span', class_='rating_num').text
- rating_num = li.find('div', class_='star').find_all('span')[-1].text
- sheet.append([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- logging.info([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- rank += 1
- if __name__ == '__main__':
- rank = 1
- for i in range(10):
- get_data(i)
- wb.save(filename='movie_info4.xlsx')
四、PyQuery
- 每個網頁,都有一定的特殊結構和層級關系,并且很多節點都有 id 或 class 作為區分,我們可以借助它們的結構和屬性來提取信息。
- 強大的 HTML 解析庫:pyquery,利用它,我們可以直接解析 DOM 節點的結構,并通過 DOM 節點的一些屬性快速進行內容提取。
如下示例:在解析 HTML 文本的時候,首先需要將其初始化為一個 pyquery 對象。它的初始化方式有多種,比如直接傳入字符串、傳入 URL、傳入文件名等等。
- from pyquery import PyQuery as pq
- html = '''
- <div>
- <ul class="clearfix">
- <li class="item-0">first item</li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li><img src="http://pic.netbian.com/uploads/allimg/210107/215736-1610027856f6ef.jpg"></li>
- <li><img src="http://pic.netbian.com//uploads/allimg/190902/152344-1567409024af8c.jpg"></li>
- </ul>
- </div>
- '''
- doc = pq(html)
- print(doc('li'))
結果如下:
- <li class="item-0">first item</li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li><img src="http://pic.netbian.com/uploads/allimg/210107/215736-1610027856f6ef.jpg"/></li>
- <li><img src="http://pic.netbian.com//uploads/allimg/190902/152344-1567409024af8c.jpg"/></li>
首先引入 pyquery 這個對象,取別名為 pq,然后定義了一個長 HTML 字符串,并將其當作參數傳遞給 pyquery 類,這樣就成功完成了初始化。接下來,將初始化的對象傳入 CSS 選擇器。在這個實例中,我們傳入 li 節點,這樣就可以選擇所有的 li 節點。
代碼如下:
- # -*- coding: UTF-8 -*-
- """
- @Author :葉庭云
- @公眾號 :修煉Python
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- from pyquery import PyQuery as pq
- import openpyxl
- from fake_useragent import UserAgent
- import logging
- # 日志輸出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 隨機產生請求頭
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook() # 創建工作簿對象
- sheet = wb.active # 獲取工作簿的活動表
- sheet.title = "movie" # 工作簿重命名
- sheet.append(["排名", "電影名", "導演和主演", "上映時間", "上映地區", "電影類型", "評分", "評價人數", "引言"])
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "Connection": "keep-alive",
- "User-Agent": ua.random
- }
- return headers
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('請求網頁失敗')
- def get_data(page):
- global rank
- url = f"https://movie.douban.com/top250?start={25 * page}&filter="
- html_text = scrape_html(url)
- doc = pq(html_text)
- lis = doc('.grid_view li')
- for li in lis.items():
- name = li('.hd a span:first-child').text()
- temp = li('.bd p:first-child').text().split('\n')
- director_actor = temp[0]
- temptemp1 = temp[1].rsplit('/', 2)
- time_, area, genres = [item.strip() for item in temp1]
- quote = li('.quote span').text()
- rating_score = li('.star .rating_num').text()
- rating_num = li('.star span:last-child').text()
- sheet.append([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- logging.info([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- rank += 1
- if __name__ == '__main__':
- rank = 1
- for i in range(10):
- get_data(i)
- wb.save(filename='movie_info3.xlsx')
五、Xpath
Xpath是一個非常好用的解析方法,同時也作為爬蟲學習的基礎,在后面的 Selenium 以及 Scrapy 框架中也會涉及到這部分知識。
首先我們使用 lxml 的 etree 庫,然后利用 etree.HTML 初始化,然后我們將其打印出來。其中,這里體現了 lxml 的一個非常實用的功能就是自動修正 html 代碼,大家應該注意到了,最后一個 li 標簽,其實我把尾標簽刪掉了,是不閉合的。不過,lxml 因為繼承了 libxml2 的特性,具有自動修正 HTML 代碼的功能,通過 xpath 表達式可以提取標簽里的內容,如下所示:
- from lxml import etree
- text = '''
- <div>
- <ul>
- <li class="item-0"><a href="link1.html">first item</a></li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li class="item-inactive"><a href="link3.html">third item</a></li>
- <li class="item-1"><a href="link4.html">fourth item</a></li>
- <li class="item-0"><a href="link5.html">fifth item</a>
- </ul>
- </div>
- '''
- html = etree.HTML(text)
- result = etree.tostring(html)
- result1 = html.xpath('//li/@class') # xpath表達式
- print(result1)
- print(result)
- ['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
- <html><body>
- <div>
- <ul>
- <li class="item-0"><a href="link1.html">first item</a></li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li class="item-inactive"><a href="link3.html">third item</a></li>
- <li class="item-1"><a href="link4.html">fourth item</a></li>
- <li class="item-0"><a href="link5.html">fifth item</a></li>
- </ul>
- </div>
- </body></html>
代碼如下:
- # -*- coding: UTF-8 -*-
- """
- @Author :葉庭云
- @公眾號 :修煉Python
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- from lxml import etree
- import openpyxl
- from fake_useragent import UserAgent
- import logging
- # 日志輸出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 隨機產生請求頭
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook() # 創建工作簿對象
- sheet = wb.active # 獲取工作簿的活動表
- sheet.title = "movie" # 工作簿重命名
- sheet.append(["排名", "電影名", "導演和主演", "上映時間", "上映地區", "電影類型", "評分", "評價人數", "引言"])
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "Connection": "keep-alive",
- "User-Agent": ua.random
- }
- return headers
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('請求網頁失敗')
- def get_data(page):
- global rank
- url = f"https://movie.douban.com/top250?start={25 * page}&filter="
- html = etree.HTML(scrape_html(url))
- lis = html.xpath('//ol[@class="grid_view"]/li')
- # 每個li標簽里有每部電影的基本信息
- for li in lis:
- name = li.xpath('.//div[@class="hd"]/a/span[1]/text()')[0]
- director_actor = li.xpath('.//div[@class="bd"]/p/text()')[0].strip()
- info = li.xpath('.//div[@class="bd"]/p/text()')[1].strip()
- # 按"/"切割成列表
- _info = info.split("/")
- # 得到 上映時間 上映地區 電影類型信息 去除兩端多余空格
- time_, area, genres = _info[0].strip(), _info[1].strip(), _info[2].strip()
- # print(time, area, genres)
- rating_score = li.xpath('.//div[@class="star"]/span[2]/text()')[0]
- rating_num = li.xpath('.//div[@class="star"]/span[4]/text()')[0]
- quote = li.xpath('.//p[@class="quote"]/span/text()')
- # 有些電影信息沒有一句話引言 加條件判斷 防止報錯
- if len(quote) == 0:
- quote = None
- else:
- quotequote = quote[0]
- sheet.append([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- logging.info([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- rank += 1
- if __name__ == '__main__':
- rank = 1
- for i in range(10):
- get_data(i)
- wb.save(filename='movie_info1.xlsx')
六、總結
- 爬取網頁數據用正則表達式的話,可以直接從網頁源代碼文本中匹配,但出錯率較高,且熟悉正則表達式的使用也比較難,需要經常翻閱文檔。
- 實際爬取數據大多基于 HTML 結構的 Web 頁面,網頁節點較多,各種層級關系。可以考慮使用 Xpath 解析器、BeautifulSoup解析器、PyQuery CSS解析器抽取結構化數據,使用正則表達式抽取非結構化數據。
- Xpath:可在 XML 中查找信息;支持 HTML 的查找 ;通過元素和屬性進行導航,查找效率很高。在學習 Selenium 以及 Scrapy 框架中也都會用到。
- BeautifulSoup:依賴于 lxml 的解析庫,也可以從 HTML 或 XML 文件中提取數據。
- PyQuery:Python仿照 jQuery 嚴格實現,可以直接解析 DOM 節點的結構,并通過 DOM 節點的一些屬性快速進行內容提取。
對于爬取網頁結構簡單的 Web 頁面,有些代碼是可以復用的,如下所示:
- from fake_useragent import UserAgent
- # 隨機產生請求頭
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "User-Agent": ua.random
- }
- return headers
偽裝請求頭,并可以隨機切換,封裝為函數,便于復用。
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- # print(resp.text)
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('請求網頁失敗')
請求網頁,返回狀態碼為 200 說明能正常請求,并返回網頁源代碼文本。