













有bug!PyTorch在AMD CPU的計算機上卡死了

PyTorch 作為機器學習中廣泛使用的開源框架,具有速度快、效率高等特點。而近年來廣受好評的 AMD 處理器具有多核、多任務性能良好、性價比高等優勢。開發者們一直希望二者聯合起來,在 AMD 處理器上使用 PyTorch 進行深度學習的開發和研究。
前段時間發布的 PyTorch 1.8 新增了對 AMD ROCm 的支持,對于想在 AMD 上用 PyTorch 進行深度學習的開發者來說,這是一個好消息。
但是,對使用 AMD cpu 的開發者用 PyTorch 做 AI 開發,也許沒那么順利。
這不,我們就從 PyTorch 的 Github 上發現這么一個還未解決的 issue。
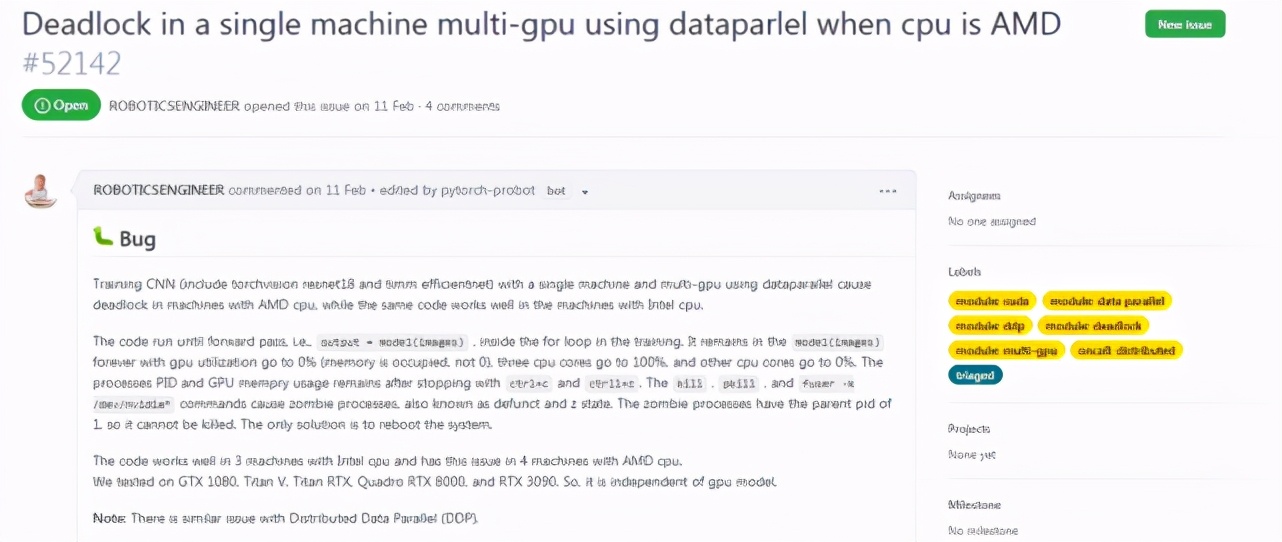
GitHub 地址:
https://github.com/pytorch/pytorch/issues/52142
有開發者表示:PyTorch 在 AMD CPU 的計算機上,用數據并行單機和多 GPU 訓練 CNN 會導致死鎖,而相同的代碼在 Intel CPU 的計算機中就不會出現死鎖。TensorFlow 也不會出現這種問題。
遇到了什么 bug
讓我們來具體看一下這個死鎖是怎么產生的?
在提交的 Issue 中,開發者表述在訓練的 for 循環中,代碼會一直運行,直到前向傳播 output = model(images)。代碼會一直停留在 model(images)階段,而 gpu 的利用率為 0% (內存占用率不是 0),有 3 個 cpu 核的利用率達到 100%,而其他 cpu 核為 0%。使用 ctrl+c 和 ctrll+z 停止后,進程 PID 和 GPU 內存使用情況保持不變。kill 、pkill 和 fuser -k /dev/nvidia * 命令導致僵尸進程(也稱為 Defunct 進程)。僵尸進程的父進程 pid 為 1,因此不能 kill 它。唯一的解決辦法是重新啟動系統。
代碼在 3 臺 Intel cpu 計算機上運行良好,但在 4 臺使用 AMD cpu 的機器上就會出現上述問題。開發者進一步測試了 GTX 1080、Titan V、 Titan RTX、Quadro RTX 8000 和 RTX 3090,證明該 bug 與 GPU 模型無關。
此外,該項目還提到分布式數據并行(DDP)也存在類似的問題。
感興趣的開發者可以按照如下配置復現一下這個 bug:
使用帶有 AMD cpu 和多個 NVIDIA gpu 的機器;
Linux、Python3.8、cuda 11.0、pytorch 1.7.1、 torchvision 0.8.2;
編寫代碼在 torchvision 中訓練 resnet18 模型;
可以嘗試測試數據并行 (DP) 和分布式數據并行(DDP),以檢查是否都會出現這種情況。
根據該項目的描述,復現之后可能會出現:
當使用 AMD cpu 時,在訓練的第一個 epoch 和第一次迭代的前向傳播時會發生死鎖;
當使用 intel cpu 時,相同的代碼運行良好。
尚未解決
對于這次發現的 bug,有網友表示也存在相同的問題。

發現該 bug 的研究者在 ImagNet、mini ImageNet、 CIFAR 10 以及其他數據集上進行了實驗,由于 CIFAR 10 具有輕量級、利于調試的特點,因此開發者在 CIFAR 10 上給出了相應的代碼示例:
此外,有開發者表示使用 TensorFlow 則不會出現該 bug。
提交 Issue 后,PyTorch 運維團隊的成員也留言參與了討論,在被問到「測試階段是否包含使用 AMD CPU 的用例」時,該成員表示:「在和其他隊友討論之后,我們意識到測試中沒有涉及 AMD CPU 的用例,目前我們還沒有辦法重現這個問題。如果今年晚些時候我們通過支持更多的硬件類型改進了測試環境,將重新討論這個問題。」

此前有網友發現了 AMD cpu 下 PyTorch 多卡并行卡死的問題,查看日志之后找到錯誤原因,問題才得以解決。而這次暴露的 bug 目前仍未解決。



















