分布式系統協調內核——Zookeeper
本文轉載自微信公眾號「木鳥雜記」,作者木鳥雜記。轉載本文請聯系木鳥雜記公眾號。
本篇要介紹 Patrick Hunt 等人在 2010 年發表的、至今仍然廣泛使用的、定位于分布式系統協調組件的論文 —— ZooKeeper: Wait-free coordination for Internet-scale systems。我們在多線程、多進程編程時,免不了進行同步和互斥,常見手段有共享內存、消息隊列、鎖、信號量等等。而在分布式系統中,不同組件間必然也需要類似的協調手段,于是 Zookeeper 應運而生。配合客戶端庫,Zookeeper 可以提供動態參數配置(configuration metadata)、分布式鎖、共享寄存器(shared register)、服務發現、集群關系(group membership)、多節點選主(leader election)等一系列分布式系統的協調服務。
總體來看,Zookeeper 有以下特點:
- Zookeeper 是一個分布式協調內核,本身功能比較內聚,以保持 API 的簡潔與高效。
- Zookeeper 提供一組高性能的、保證 FIFO的、基于事件驅動的非阻塞 API。
- Zookeeper 使用類似文件系統的目錄樹方式對數據進行組織,表達能力強大,方便客戶端構建更復雜的協調源語。
- Zookeeper 是一個自洽的容錯系統,使用 Zab 原子廣播(atomic broadcast)協議保證高可用和一致性。
本文依從論文順序,簡要介紹下 Zookeeper 的服務接口設計與模塊粗略實現。更多細節請參考論文和開源項目主頁。
服務設計
我們在設計服務接口的時候,首先要抽象出服務組織和交互所涉及到的基本概念,進而才能厘清圍繞這些基本概念的動作集合。對于 Zookeeper 來說,這些基本概念稱為術語(Terminology),動作集合稱為服務接口(API)。
術語集
- 客戶端:client,使用 Zookeeper 服務的用戶。
- 服務器:server,提供 Zookeeper 服務的進程。
- 數據樹:data tree,Zookeeper 中所有的數據以樹形結構進行組織。
- z-節點:znode、Zookeeper Node,數據樹中的節點,是基本數據單元。
- 會話:session,客戶端與服務器會新建一個會話來標識一個連接,之后客戶端每次請求都會通過該會話句柄來進行。Watch 事件的生命周期也是和會話綁定的。
后面行文中,對應術語的中英文可能會交雜使用。
數據組織
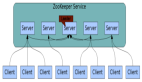
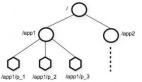
Zookeeper 對所存數據進行類似文件系統的樹形層次化組織,可以提供給使用者更強大的靈活性。比如可以很自然的表示命名閾(namespace),比如使用同一父節點的所有孩子表示成員關系(membership)。一個路徑(Path)可以定位到一個唯一的數據節點,進而能夠唯一標識一個基本數據單元。
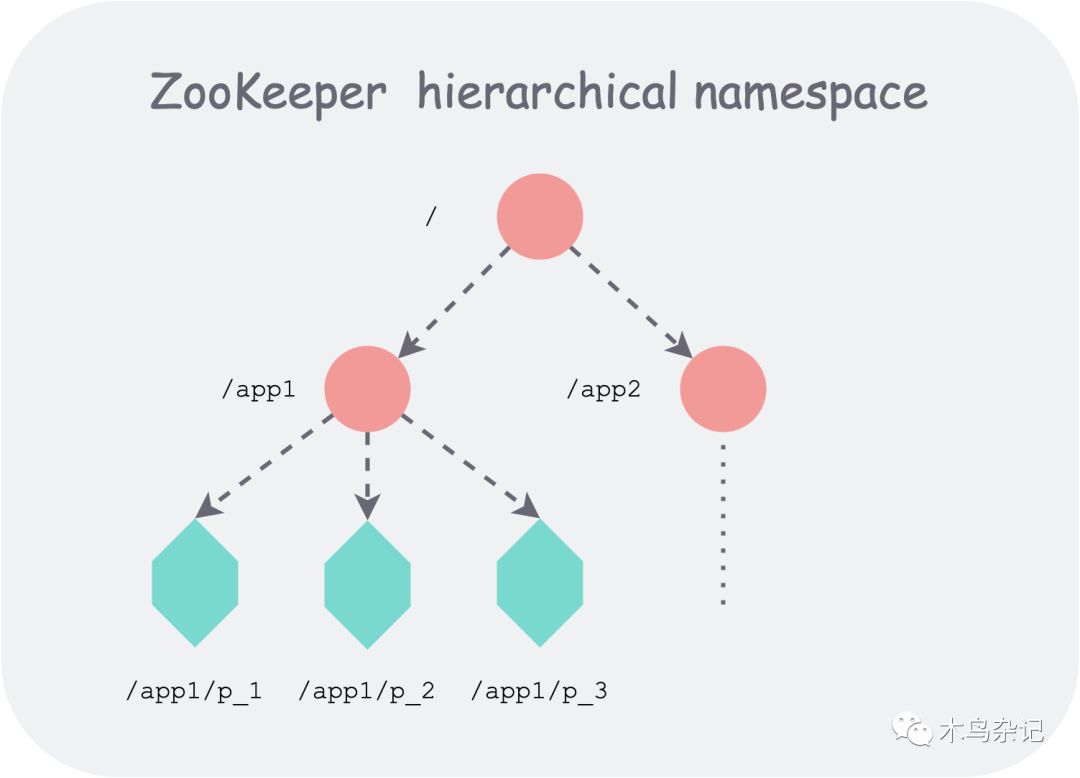
zookeeper 層次化的命名空間組織
樹中支持兩種類型的 znode:
- 普通節點:Regular,生命周期無限,客戶端需要調用接口顯式的對這類節點進行增刪。
- 暫態節點:Ephemeral,生命周期綁定到會話上,會話銷毀,節點刪除。
此外,Zookeeper 允許客戶端在創建 znode 時,附加一個 sequential 標志。Zookeeper 便會自動給節點名字添加一個全局自增的計數作為后綴。
Zookeeper 使用***推***的方式實現訂閱機制,即用戶在訂閱(watch)了某個節點后,當該節點發生變化時,客戶端會收到一次通知(邊緣觸發),一個訂閱是綁定到會話上的,因此會話銷毀后,訂閱的事件也會消失。
會話機制(session)。可以看到,Zookeeper 使用會話機制管理客戶端一次連接的生命周期。在實現時,會話會關聯一個超時間隔(timeout)。如果客戶端死掉或者與 Zookeeper 斷開連接,超時時限內客戶端未進行心跳,Zookeeper 會在服務器端銷毀該會話。
數據模型(Data model)。Zookeeper 本質上提供樹形組織的 KV 模型。除存儲鍵值對數據外,Zookeeper 更多的是以其空間結構和生命周期管理作為表達能力,來提供協調語義。當然,Zookeeper 也允許客戶端為節點附加一些元信息(meta-data)和配置信息(configuration),并且提供版本和時間戳支持,從而提供更強大的表達能力。
API 細節
下面是以偽碼的形式列出 Zookeeper 對客戶端提供的 API 細節和注釋。所有操作對象都是路徑( path) 所對應的數據節點(znode)。
- // 在路徑 path 處創建一個 znode,存入數據 data
- // 并設置 regular, ephemeral, sequential 等 flags 標志。
- // 返回值:znode 名字
- create(path, data, flags)
- // 如果 path 處的 znode 與預期 version 相同,
- // 則刪除該 znode。
- // 指定 version 一般是為了并發安全。
- delete(path, version)
- // watch 讓客戶端在此 path 上添加一個監聽
- // 返回值:路徑對應的 znode,存在時返回 true
- // 不存在返回 false
- exists(path, watch)
- // 獲取路徑 path 對應的 znode 的數據和元信息
- // 當 znode 存在時,允許設置 watch 來監聽
- // znode 數據變化
- getData(path, watch)
- // 當 version 匹配時,將數據 data 寫入
- // path 對應的 znode
- setData(path, data, version)
- // 獲取路徑 path 對應的 znode 的所有孩子
- getChildren(path, watch)
- // 同步最新數據,通常放在 getData 前面
- sync(path)
上面的 API 有以下特點:
異步支持。所有接口都有同步(synchronous)和異步(asynchronous)版本。異步版本以回調函數方式進行執行,客戶端可以根據業務需求,選擇阻塞等待以獲取重要更新,或者異步調用以獲得更好性能。
路徑而非句柄。為了簡化接口設計,并減少服務端維護的狀態, Zookeeper 使用路徑而非 znode 句柄的形式來提供對 znode 的操作接口。畢竟,句柄類似于 session,是有狀態的,會增加分布式系統的實現復雜度。使用路徑,可以配合版本信息做成類似冪等的接口,在處理多客戶端并發時,更容易實現。
版本信息。所有的更新操作(set/delete)都需要指明對應數據的版本號,版本號不匹配則終止更新并返回異常。但可以通過指定特殊版本號 -1 ,跳過版本號檢查。
語義保證
在處理多個客戶端向 Zookeeper 發出的并發請求時, API 有兩個基本順序的保證:
線性化寫(Linearizable writes)。所有 Zookeeper 狀態的更新請求會被串行化執行。
客戶端內的先入先出(FIFO client order)。給定客戶端的請求會按其發送的順序進行執行。
但這里的線性化是一種異步線性化:A-linearizability。即單個客戶端可以同時有多個正在執行的請求(multiple outstanding operations),但是這些請求會按發出順序進行執行。對于讀請求,可以在每個服務器本地(不需要通過主)執行。因此,可以通過增加服務器(Observer)提升讀請求的吞吐。
此外,Zookeeper 還提供可用性和持久性的保證:
可用性(liveness):Zookeeper 集群中過半數節點可用,則可對外正常提供服務。
持久性(durability):任何被成功返回給客戶端的修改請求,都會作用到 Zookeeper 狀態機中。即使不斷有節點故障重啟,只要 Zookeeper 能正常提供服務,就不會影響這一特性。
Zookeeper 架構
為了提供高可靠性,Zookeeper 使用多臺服務器對數據進行冗余存取。然后使用 Zab 共識協議處理所有的更新請求,然后寫入 WAL,進而應用到本地內存狀態機(data tree)。
在 Zab 協議中,所有節點分為兩種角色,Leader 和 Followers,前者只有一個,剩余的都是 Followers。但后來實踐中,可能有 Observers。
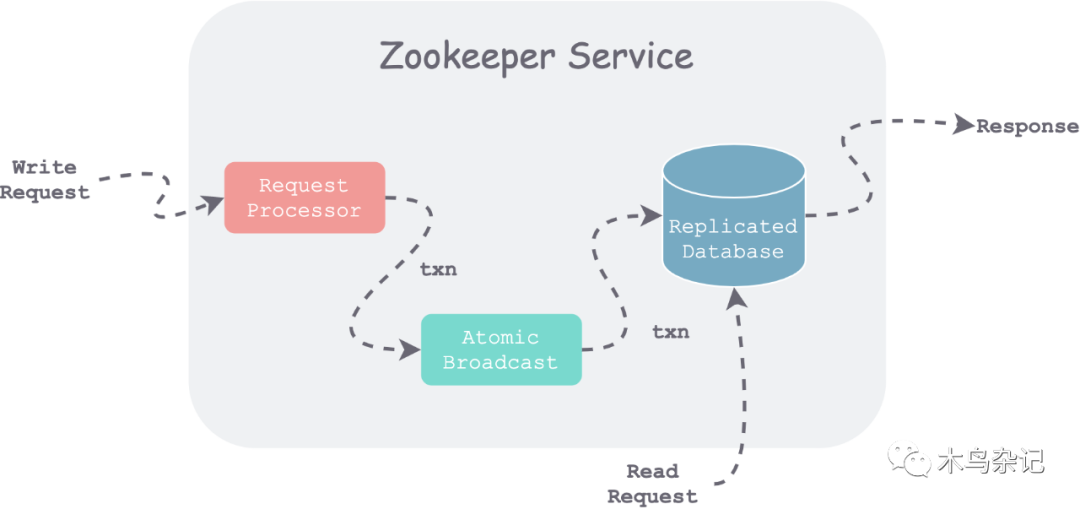
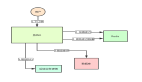
zookeeper 組件與請求流程
如上圖所示,當 Server 收到一個請求時,首先進行預處理(Request Processor),如果是寫請求,則通過 Zab 協議(Atomic Broadcast)達成一致,然后各自提交到本地數據庫(Replicated Database)。對于讀請求,直接讀取本地數據庫中狀態后返回。
請求處理(Request Processor)
所有更新請求都會被轉為冪等(idempotent)的事務(txn),具體方法為獲取當前狀態、計算出目標狀態,封裝為事務,即可使用類似 CAS 的方式處理并發請求。因此,只要保證所有事務按固定順序執行,就能避免不同服務器上的數據副本分裂。
原子廣播(Atomic Broadcast)
所有更新請求都會被轉給 Zookeeper 的 Leader,Leader 首先將事務追加到本地 WAL,然后將變動使用 Zab 協議廣播到各個節點,收到過半成功回復之后,Leader 將變動提交(Commit)到本地內存數據庫,并廣播該 Commit 給 Followers。
由于 Zab 使用多數票原則,因此 2k+1 個節點的集群最多可以容忍 k 個節點的故障(failures)。
為了提高系統吞吐,Zookeeper 使用流水線(pipelined)方式優化多個請求處理過程。
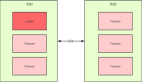
復制狀態機(Replicated Database)
每個服務器都會在本機內存中維護一個 Zookeeper 中所有狀態的副本(replica),為了應對宕機重啟,ZooKeeper 會定期將狀態做快照。不同于普通快照,Zookeeper 稱其快照為 fuzzy snapshots,即在做快照時并不上鎖,通過 DFS 的方式遍歷文件樹 Dump 到本地。之后由于異常宕機重啟時,只需加最新快照,然后重新執行最新快照之后幾條 WAL 即可。由于 WAL 中記錄的事務的冪等性特點,即使快照和 WAL 的時間點不完全對應,也不會影響副本間的一致性。
客戶端服務器交互事宜(Client-Server Interactions)
串行寫。無論是在全局范圍還是具體到一個 Server 本地,所有更新操作都是串行的。在執行某個 Path 數據更新時,該 Server 會觸發所有與之連接的 Client 所訂閱的 Watch 事件。需要注意,這些事件只保存在 Server 本地,因為他們是和會話關聯的,如果 Client 與該 Server 斷開連接,會話便會銷毀,這些事件也隨之消亡。
本地讀。為了獲取極致性能,Zookeeper 的 Server 直接在本地處理讀請求。但這有可能造成客戶端拿到陳舊數據(比如其他客戶端在另外的 Server 更新了同一 Path)。于是 Zookeeper 設計出了 Sync 操作,會將調用 Sync 時刻的最新提交數據同步到與該 Client 連接的 Server 上,然后將最新數據返回給 Client。即,Zookeeper 將性能與時效性的選擇權交給了用戶,方法是是否調用 Sync。
一致性視圖。Zookeeper 全局會維持一個事務自增標識:zxid,它本質上是個邏輯時鐘,可以標識 Zookeeper 一個時刻的數據視圖。Client 在故障重啟后重新連接到一個新的 Server 時,如果該 Server 未執行到客戶端所存 zxid,則要么 Server 執行到該 zxid 后再回復 Client,要么 Client 換一個更新的 Server 進行連接。如此,可以保證 Client 不會看到回退的視圖。
會話過期。會話在 Zookeeper 中本質上標識一個 Client 到 Server 的連接。會話有超時時間,如果 Client 長時間(大于超時間隔)不發請求或者心跳,Server 便會刪除該會話。
小結
Zookeeper 使用目錄樹組織數據、使用 Zab 協議同步數據、使用非阻塞方式提供接口,構建了一個表達能力強大的分布式協調性內核。可以用于分布式系統的控制面以進行協調、調度和控制。近年來基于 Raft 的 Etcd 也是類似地位。