RocketMQ 千錘百煉 - 哈啰在分布式消息治理和微服務(wù)治理中的實(shí)踐
背景
哈啰已進(jìn)化為包括兩輪出行(哈啰單車、哈啰助力車、哈啰電動(dòng)車、小哈換電)、四輪出行(哈啰順風(fēng)車、全網(wǎng)叫車、哈啰打車)等的綜合化移動(dòng)出行平臺(tái),并向酒店、到店團(tuán)購(gòu)等眾多本地生活化生態(tài)探索。
隨著公司業(yè)務(wù)的不斷發(fā)展,流量也在不斷增長(zhǎng)。我們發(fā)現(xiàn)生產(chǎn)中的一些重大事故,往往是被突發(fā)的流量沖跨的,對(duì)流量的治理和防護(hù),保障系統(tǒng)高可用就尤為重要。
本文就哈啰在消息流量和微服務(wù)調(diào)用的治理中踩過的坑、積累的經(jīng)驗(yàn)進(jìn)行分享。
聊聊治理這件事
開始之前先聊聊治理這件事情,下面是老梁個(gè)人理解:
治理在干一件什么事?
讓我們的環(huán)境變得美好一些
需要知道哪些地方還不夠好?
以往經(jīng)驗(yàn)
用戶反饋
業(yè)內(nèi)對(duì)比
還需要知道是不是一直都是好的?
監(jiān)控跟蹤
告警通知
不好的時(shí)候如何再讓其變好?
治理措施
應(yīng)急方案
目錄
打造分布式消息治理平臺(tái)
RocketMQ 實(shí)戰(zhàn)踩坑和解決
打造微服務(wù)高可用治理平臺(tái)
背景
裸奔的 RabbitMQ
公司之前使用 RabbitMQ ,下面在使用 RabbitMQ 時(shí)的痛點(diǎn),其中很多事故由于 RabbitMQ 集群限流引起的。
積壓過多是清理還是不清理?這是個(gè)問題,我再想想。
積壓過多觸發(fā)集群流控?那是真的影響業(yè)務(wù)了。
想消費(fèi)前兩天的數(shù)據(jù)?請(qǐng)您重發(fā)一遍吧。
要統(tǒng)計(jì)哪些服務(wù)接入了?您要多等等了,我得去撈IP看看。
有沒有使用風(fēng)險(xiǎn)比如大消息?這個(gè)我猜猜。
裸奔的服務(wù)
曾經(jīng)有這么一個(gè)故障,多個(gè)業(yè)務(wù)共用一個(gè)數(shù)據(jù)庫(kù)。在一次晚高峰流量陡增,把數(shù)據(jù)庫(kù)打掛了。
數(shù)據(jù)庫(kù)單機(jī)升級(jí)到最高配依然無(wú)法解決
重啟后緩一緩,不一會(huì)就又被打掛了
如此循環(huán)著、煎熬著、默默等待著高峰過去
思考:無(wú)論消息還是服務(wù)都需要完善的治理措施
打造分布式消息治理平臺(tái)
設(shè)計(jì)指南
哪些是我們的關(guān)鍵指標(biāo),哪些是我們的次要指標(biāo),這是消息治理的首要問題。
設(shè)計(jì)目標(biāo)
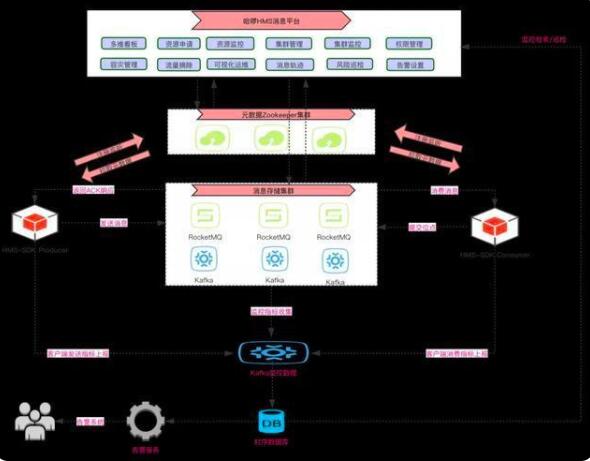
旨在屏蔽底層各個(gè)中間件( RocketMQ / Kafka )的復(fù)雜性,通過唯一標(biāo)識(shí)動(dòng)態(tài)路由消息。同時(shí)打造集資源管控、檢索、監(jiān)控、告警、巡檢、容災(zāi)、可視化運(yùn)維等一體化的消息治理平臺(tái),保障消息中間件平穩(wěn)健康運(yùn)行。
消息治理平臺(tái)設(shè)計(jì)需要考慮的點(diǎn)
提供簡(jiǎn)單易用 API
有哪些關(guān)鍵點(diǎn)能衡量客戶端的使用沒有安全隱患
有哪些關(guān)鍵指標(biāo)能衡量集群健康不健康
有哪些常用的用戶/運(yùn)維操作將其可視化
有哪些措施應(yīng)對(duì)這些不健康
盡可能簡(jiǎn)單易用
設(shè)計(jì)指南
把復(fù)雜的問題搞簡(jiǎn)單,那是能耐。
極簡(jiǎn)統(tǒng)一 API
提供統(tǒng)一的 SDK 封裝了( Kafka / RocketMQ )兩種消息中間件。
一次申請(qǐng)
主題消費(fèi)組自動(dòng)創(chuàng)建不適合生產(chǎn)環(huán)境,自動(dòng)創(chuàng)建會(huì)導(dǎo)致失控,不利于整個(gè)生命周期管理和集群穩(wěn)定。需要對(duì)申請(qǐng)流程進(jìn)行控制,但是應(yīng)盡可能簡(jiǎn)單。例如:一次申請(qǐng)各個(gè)環(huán)境均生效、生成關(guān)聯(lián)告警規(guī)則等。

客戶端治理
設(shè)計(jì)指南
監(jiān)控客戶端使用是否規(guī)范,找到合適的措施治理
場(chǎng)景回放
場(chǎng)景一 瞬時(shí)流量與集群的流控
假設(shè)現(xiàn)在集群 Tps 有 1 萬(wàn),瞬時(shí)翻到 2 萬(wàn)甚至更多,這種過度陡增的流量極有可能引發(fā)集群流控。針對(duì)這類場(chǎng)景需監(jiān)控客戶端的發(fā)送速度,在滿足速度和陡增幅度閾值后將發(fā)送變的平緩一些。
場(chǎng)景二 大消息與集群抖動(dòng)
當(dāng)客戶端發(fā)送大消息時(shí),例如:發(fā)送幾百KB甚至幾兆的消息,可能造成 IO 時(shí)間過長(zhǎng)與集群抖動(dòng)。針對(duì)這類場(chǎng)景治理需監(jiān)控發(fā)送消息的大小,我們采取通過事后巡檢的方式識(shí)別出大消息的服務(wù),推動(dòng)使用同學(xué)壓縮或重構(gòu),消息控制在 10KB 以內(nèi)。
場(chǎng)景三 過低客戶端版本
隨著功能的迭代 SDK 的版本也會(huì)升級(jí),變更除了功能外還有可能引入風(fēng)險(xiǎn)。當(dāng)使用過低的版本時(shí)一個(gè)是功能不能得到支持,另外一個(gè)是也可能存在安全隱患。為了解 SDK 使用情況,可以采取將 SDK 版本上報(bào),通過巡檢的方式推動(dòng)使用同學(xué)升級(jí)。
場(chǎng)景四 消費(fèi)流量摘除和恢復(fù)
消費(fèi)流量摘除和恢復(fù)通常有以下使用場(chǎng)景,第一個(gè)是發(fā)布應(yīng)用時(shí)需要先摘流量,另外一個(gè)是問題定位時(shí)希望先把流量摘除掉再去排查。為了支持這種場(chǎng)景,需要在客戶端監(jiān)聽摘除/恢復(fù)事件,將消費(fèi)暫停和恢復(fù)。
場(chǎng)景五 發(fā)送/消費(fèi)耗時(shí)檢測(cè)
發(fā)送/消費(fèi)一條消息用了多久,通過監(jiān)控耗時(shí)情況,巡檢摸排出性能過低的應(yīng)用,針對(duì)性推動(dòng)改造達(dá)到提升性能的目的。
場(chǎng)景六 提升排查定位效率
在排查問題時(shí),往往需要檢索發(fā)了什么消息、存在哪里、什么時(shí)候消費(fèi)的等消息生命周期相關(guān)的內(nèi)容。這部分可以通過 msgId 在消息內(nèi)部將生命周期串聯(lián)起來。另外是通過在消息頭部埋入 rpcId / traceId 類似鏈路標(biāo)識(shí),在一次請(qǐng)求中將消息串起來。
治理措施提煉
需要的監(jiān)控信息
發(fā)送/消費(fèi)速度
發(fā)送/消費(fèi)耗時(shí)
消息大小
節(jié)點(diǎn)信息
鏈路標(biāo)識(shí)
版本信息
常用治理措施
定期巡檢:有了埋點(diǎn)信息可以通過巡檢將有風(fēng)險(xiǎn)的應(yīng)用找出來。例如發(fā)送/消費(fèi)耗時(shí)大于 800 ms、消息大小大于 10 KB、版本小于特定版本等。
發(fā)送平滑:例如檢測(cè)到瞬時(shí)流量滿足 1 萬(wàn)而且陡增了 2 倍以上,可以通過預(yù)熱的方式將瞬時(shí)流量變的平滑一些。
消費(fèi)限流:當(dāng)?shù)谌浇涌谛枰蘖鲿r(shí),可以對(duì)消費(fèi)的流量進(jìn)行限流,這部分可以結(jié)合高可用框架實(shí)現(xiàn)。
消費(fèi)摘除:通過監(jiān)聽摘除事件將消費(fèi)客戶端關(guān)閉和恢復(fù)。
主題/消費(fèi)組治理
設(shè)計(jì)指南
監(jiān)控主題消費(fèi)組資源使用情況
場(chǎng)景回放
場(chǎng)景一 消費(fèi)積壓對(duì)業(yè)務(wù)的影響
有些業(yè)務(wù)場(chǎng)景對(duì)消費(fèi)堆積很敏感,有些業(yè)務(wù)對(duì)積壓不敏感,只要后面追上來消費(fèi)掉即可。例如單車開鎖是秒級(jí)的事情,而信息匯總相關(guān)的批處理場(chǎng)景對(duì)積壓不敏感。通過采集消費(fèi)積壓指標(biāo),對(duì)滿足閾值的應(yīng)用采取實(shí)時(shí)告警的方式通知到應(yīng)用負(fù)責(zé)的同學(xué),讓他們實(shí)時(shí)掌握消費(fèi)情況。
場(chǎng)景二 消費(fèi)/發(fā)送速度的影響
發(fā)送/消費(fèi)速度跌零告警?有些場(chǎng)景速度不能跌零,如果跌零意味著業(yè)務(wù)出現(xiàn)異常。通過采集速度指標(biāo),對(duì)滿足閾值的應(yīng)用實(shí)時(shí)告警。
場(chǎng)景三 消費(fèi)節(jié)點(diǎn)掉線
消費(fèi)節(jié)點(diǎn)掉線需要通知給應(yīng)用負(fù)責(zé)的同學(xué),這類需要采集注冊(cè)節(jié)點(diǎn)信息,當(dāng)?shù)艟€時(shí)能實(shí)時(shí)觸發(fā)告警通知。
場(chǎng)景四 發(fā)送/消費(fèi)不均衡
發(fā)送/消費(fèi)的不均衡往往影響其性能。記得有一次咨詢時(shí)有同學(xué)將發(fā)送消息的key設(shè)置成常量,默認(rèn)按照 key 進(jìn)行 hash 選擇分區(qū),所有的消息進(jìn)入了一個(gè)分區(qū)里,這個(gè)性能是無(wú)論如何也上不來的。另外還要檢測(cè)各個(gè)分區(qū)的消費(fèi)積壓情況,出現(xiàn)過度不均衡時(shí)觸發(fā)實(shí)時(shí)告警通知。
治理措施提煉
需要的監(jiān)控信息
發(fā)送/消費(fèi)速度
發(fā)送分區(qū)詳情
消費(fèi)各分區(qū)積壓
消費(fèi)組積壓
注冊(cè)節(jié)點(diǎn)信息
常用治理措施
實(shí)時(shí)告警:對(duì)消費(fèi)積壓、發(fā)送/消費(fèi)速度、節(jié)點(diǎn)掉線、分區(qū)不均衡進(jìn)行實(shí)時(shí)告警通知。
提升性能:對(duì)于有消費(fèi)積壓不能滿足需求,可以通過增加拉取線程、消費(fèi)線程、增加分區(qū)數(shù)量等措施加以提升。
自助排查:提供多維度檢索工具,例如通過時(shí)間范圍、msgId 檢索、鏈路系統(tǒng)等多維度檢索消息生命周期。
集群健康治理
設(shè)計(jì)指南
度量集群健康的核心指標(biāo)有哪些?
場(chǎng)景回放
場(chǎng)景一 集群健康檢測(cè)
集群健康檢測(cè)回答一個(gè)問題:這個(gè)集群是不是好的。通過檢測(cè)集群節(jié)點(diǎn)數(shù)量、集群中每個(gè)節(jié)點(diǎn)心跳、集群寫入Tps水位、集群消費(fèi)Tps水位都是在解決這個(gè)問題。
場(chǎng)景二 集群的穩(wěn)定性
集群流控往往體現(xiàn)出集群性能的不足,集群抖動(dòng)也會(huì)引發(fā)客戶端發(fā)送超時(shí)。通過采集集群中每個(gè)節(jié)點(diǎn)心跳耗時(shí)情況、集群寫入Tps水位的變化率來掌握集群是否穩(wěn)定。
場(chǎng)景三 集群的高可用
高可用主要針對(duì)極端場(chǎng)景中導(dǎo)致某個(gè)可用區(qū)不可用、或者集群上某些主題和消費(fèi)組異常需要有一些針對(duì)性的措施。例如:MQ 可以通過同城跨可用區(qū)主從交叉部署、動(dòng)態(tài)將主題和消費(fèi)組遷移到災(zāi)備集群、多活等方式進(jìn)行解決。
治理措施提煉
需要的監(jiān)控信息
集群節(jié)點(diǎn)數(shù)量采集
集群節(jié)點(diǎn)心跳耗時(shí)
集群寫入 Tps 的水位
集群消費(fèi) Tps 的水位
集群寫入 Tps 的變化率
常用治理措施
定期巡檢:對(duì)集群 Tps 水位、硬件水位定期巡檢。
容災(zāi)措施:同城跨可用區(qū)主從交叉部署、容災(zāi)動(dòng)態(tài)遷移到災(zāi)備集群、異地多活。
集群調(diào)優(yōu):系統(tǒng)版本/參數(shù)、集群參數(shù)調(diào)優(yōu)。
集群分類:按業(yè)務(wù)線分類、按核心/非核心服務(wù)分類。
最核心指標(biāo)聚焦
如果說這些關(guān)鍵指標(biāo)中哪一個(gè)最重要?我會(huì)選擇集群中每個(gè)節(jié)點(diǎn)的心跳檢測(cè),即:響應(yīng)時(shí)間( RT ),下面看看影響 RT 可能哪些原因。
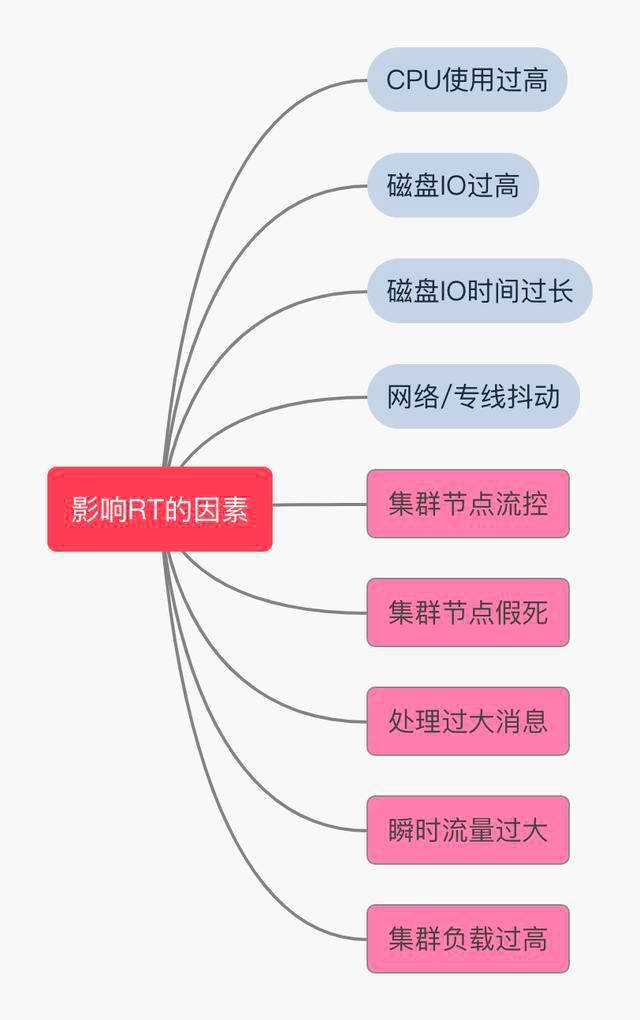
關(guān)于告警
監(jiān)控指標(biāo)大多是秒級(jí)探測(cè)
觸發(fā)閾值的告警推送到公司統(tǒng)一告警系統(tǒng)、實(shí)時(shí)通知
巡檢的風(fēng)險(xiǎn)通知推送到公司巡檢系統(tǒng)、每周匯總通知
消息平臺(tái)圖示
架構(gòu)圖
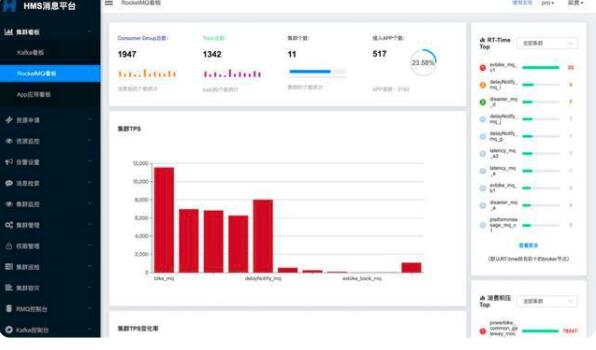
看板圖示
多維度:集群維度、應(yīng)用維度
全聚合:關(guān)鍵指標(biāo)全聚合
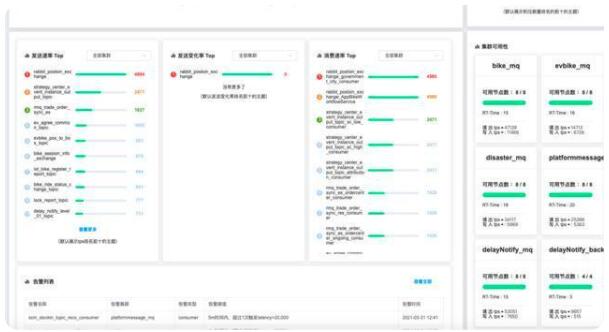
RocketMQ 實(shí)戰(zhàn)中踩過的坑和解決方案
行動(dòng)指南
我們總會(huì)遇到坑,遇到就把它填了。
1. RocketMQ 集群 CPU 毛刺
問題描述
RocketMQ 從節(jié)點(diǎn)、主節(jié)點(diǎn)頻繁 CPU 飆高,很明顯的毛刺,很多次從節(jié)點(diǎn)直接掛掉了。
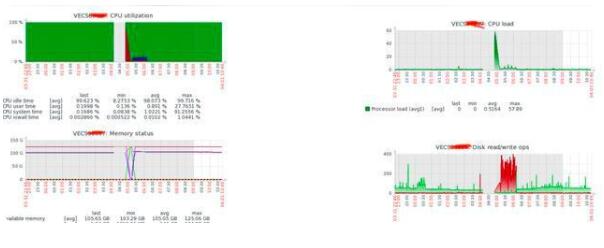
只有系統(tǒng)日志有錯(cuò)誤提示
2020-03-16T17:56:07.505715+08:00 VECS0xxxx kernel:[] ? __alloc_pages_nodemask+0x7e1/0x9602020-03-16T17:56:07.505717+08:00 VECS0xxxx kernel: java: page allocation failure. order:0, mode:0x202020-03-16T17:56:07.505719+08:00 VECS0xxxx kernel: Pid: 12845, comm: java Not tainted 2.6.32-754.17.1.el6.x86_64 #12020-03-16T17:56:07.505721+08:00 VECS0xxxx kernel: Call Trace:2020-03-16T17:56:07.505724+08:00 VECS0xxxx kernel:[] ? __alloc_pages_nodemask+0x7e1/0x9602020-03-16T17:56:07.505726+08:00 VECS0xxxx kernel: [] ? dev_queue_xmit+0xd0/0x3602020-03-16T17:56:07.505729+08:00 VECS0xxxx kernel: [] ? ip_finish_output+0x192/0x3802020-03-16T17:56:07.505732+08:00 VECS0xxxx kernel: [] ?
各種調(diào)試系統(tǒng)參數(shù)只能減緩但是不能根除,依然毛刺超過 50%
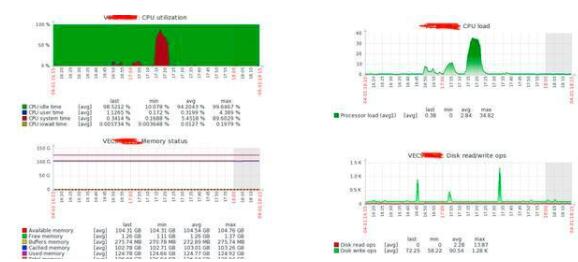
解決方案
將集群所有系統(tǒng)升級(jí)從 centos 6 升級(jí)到 centos 7 ,內(nèi)核版本也從從 2.6 升級(jí)到 3.10 ,CPU 毛刺消失。
2. RocketMQ 集群線上延遲消息失效
問題描述
RocketMQ 社區(qū)版默認(rèn)本支持 18 個(gè)延遲級(jí)別,每個(gè)級(jí)別在設(shè)定的時(shí)間都被會(huì)消費(fèi)者準(zhǔn)確消費(fèi)到。為此也專門測(cè)試過消費(fèi)的間隔是不是準(zhǔn)確,測(cè)試結(jié)果顯示很準(zhǔn)確。然而,如此準(zhǔn)確的特性居然出問題了,接到業(yè)務(wù)同學(xué)報(bào)告線上某個(gè)集群延遲消息消費(fèi)不到,詭異!
解決方案
將" delayOffset.json "和" consumequeue / SCHEDULE_TOPIC_XXXX "移到其他目錄,相當(dāng)于刪除;逐臺(tái)重啟 broker 節(jié)點(diǎn)。重啟結(jié)束后,經(jīng)過驗(yàn)證,延遲消息功能正常發(fā)送和消費(fèi)。
打造微服務(wù)高可用治理平臺(tái)
設(shè)計(jì)指南
哪些是我們的核心服務(wù),哪些是我們的非核心服務(wù),這是服務(wù)治理的首要問題
設(shè)計(jì)目標(biāo)
服務(wù)能應(yīng)對(duì)突如其來的陡增流量,尤其保障核心服務(wù)的平穩(wěn)運(yùn)行。
應(yīng)用分級(jí)和分組部署
應(yīng)用分級(jí)
根據(jù)用戶和業(yè)務(wù)影響兩個(gè)緯度來進(jìn)行評(píng)估設(shè)定的,將應(yīng)用分成了四個(gè)等級(jí)。
業(yè)務(wù)影響:應(yīng)用故障時(shí)影響的業(yè)務(wù)范圍
用戶影響:應(yīng)用故障時(shí)影響的用戶數(shù)量
S1:核心產(chǎn)品,產(chǎn)生故障會(huì)引起外部用戶無(wú)法使用或造成較大資損,比如主營(yíng)業(yè)務(wù)核心鏈路,如單車、助力車開關(guān)鎖、順風(fēng)車的發(fā)單和接單核心鏈路,以及其核心鏈路強(qiáng)依賴的應(yīng)用。
S2: 不直接影響交易,但關(guān)系到前臺(tái)業(yè)務(wù)重要配置的管理與維護(hù)或業(yè)務(wù)后臺(tái)處理的功能。
S3: 服務(wù)故障對(duì)用戶或核心產(chǎn)品邏輯影響非常小,且對(duì)主要業(yè)務(wù)沒影響,或量較小的新業(yè)務(wù);面向內(nèi)部用戶使用的重要工具,不直接影響業(yè)務(wù),但相關(guān)管理功能對(duì)前臺(tái)業(yè)務(wù)影響也較小。
S4: 面向內(nèi)部用戶使用,不直接影響業(yè)務(wù),或后續(xù)需要推動(dòng)下線的系統(tǒng)。
分組部署
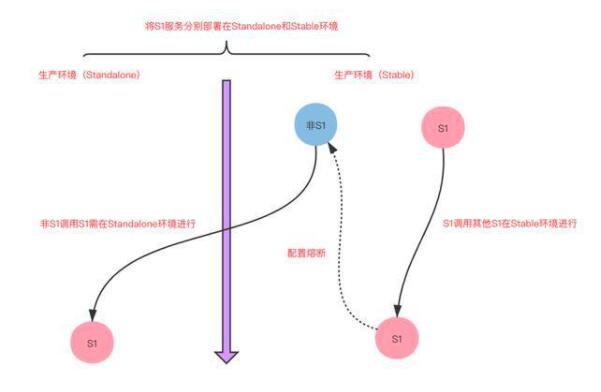
S1 服務(wù)是公司的核心服務(wù),是重點(diǎn)保障的對(duì)象,需保障其不被非核心服務(wù)流量意外沖擊。
S1 服務(wù)分組部署,分為 Stable 和 Standalone 兩套環(huán)境
非核心服務(wù)調(diào)用 S1 服務(wù)流量路由到 Standalone 環(huán)境
S1 服務(wù)調(diào)用非核心服務(wù)需配置熔斷策略
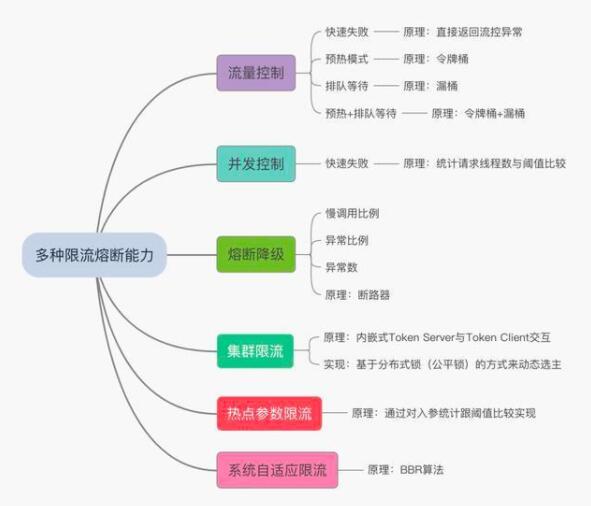
多種限流熔斷能力建設(shè)
我們建設(shè)的高可用平臺(tái)能力
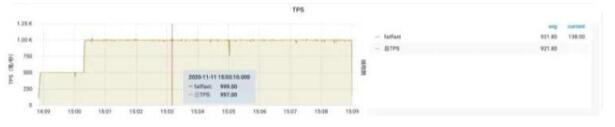
部分限流效果圖
預(yù)熱圖示

排隊(duì)等待
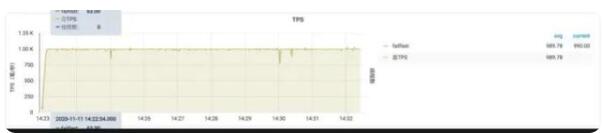
預(yù)熱+排隊(duì)
高可用平臺(tái)圖示
中間件全部接入
動(dòng)態(tài)配置實(shí)時(shí)生效
每個(gè)資源和 IP 節(jié)點(diǎn)詳細(xì)流量
總結(jié)
哪些是我們的關(guān)鍵指標(biāo),哪些是我們的次要指標(biāo),這是消息治理的首要問題
哪些是我們的核心服務(wù),哪些是我們的非核心服務(wù),這是服務(wù)治理的首要問題
源碼&實(shí)戰(zhàn) 是一種比較好的工作學(xué)習(xí)方法。