給一個詞就能模仿你的筆跡,Facebook這個AI強大到不敢開源代碼
Facebook 近日公布了一項新的圖像 AI——TextStyleBrush,該技術可以復制和再現圖像中的文本風格。
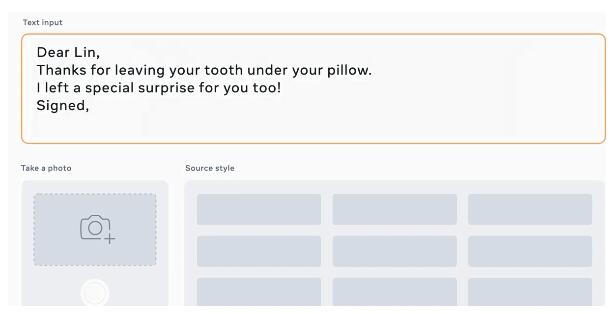
借助該技術,你只需要輸入一個詞作為「標準」,AI 就能全篇模仿你的書寫風格,一鍵執行,效果可謂驚艷。
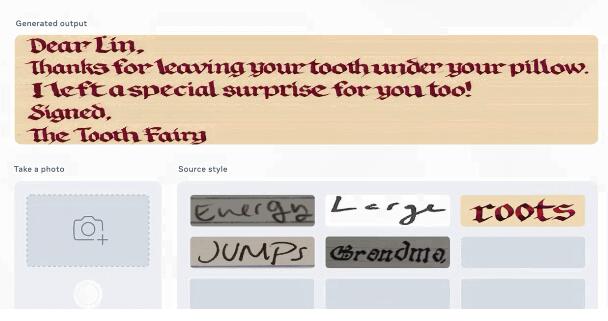
此外,你還可以用它替換不同場景中的文字(比如海報、垃圾桶、路標等)。下圖中左側為原始場景圖像,單詞顯示在藍色矩形中;右側為文本替換后的圖像。

從圖中可以看出,各種風格的字體 AI 幾乎都能 hold 住。下圖中每個圖像對在左邊顯示輸入源樣式,在右邊顯示新內容(字符串),左右兩端字體看起來風格完全相同。與源圖像相比,輸出的圖像在外觀上似乎都有些模糊,但我們可以看到,在大多數情況下,該技術似乎工作得很好。

與其他字跡模仿 AI 相比,TextStyleBrush 功能更強大,可以從更細微的角度分析文字樣式,從而做到在各種角度和背景下進行字跡模仿。
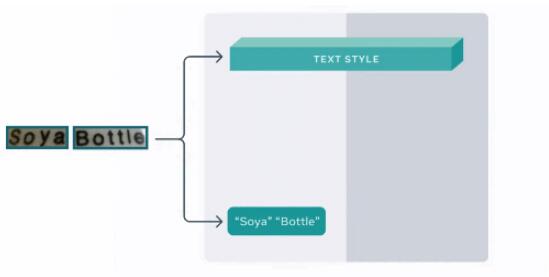
下圖是醬油瓶(Soya)替換為茶瓶(Tea)的實現過程:
這款強大的模仿神器正是 Facebook AI 推出的「TextStyleBrush」,只需輸入一個單詞,就能完美復現筆跡。這項技術的原理類似于文字處理 APP 中的樣式筆刷工具,可以將文字和風格分開。

- 論文地址:https://scontent-sjc3-1.xx.fbcdn.net/v/t39.8562-6/10000000_944085403038430_3779849959048683283_n.pdf?_nc_cat=108&ccb=1-3&_nc_sid=ae5e01&_nc_ohc=Jcq0m5jBvK8AX--fG2A&_nc_ht=scontent-sjc3-1.xx&oh=8b7e8221bba5aba6b6331c643764dec5&oe=60EF2B81
- 數據集地址:https://github.com/facebookresearch/IMGUR5K-Handwriting-Dataset
它具有以下特點:
- 只需要一個單詞,就能復制照片中的文字風格。使用該 AI 模型,你可以編輯和替換圖像中的文本。
- 與大多數 AI 系統不同的是,TextStyleBrush 是首個自監督的 AI 模型,使用單個示例詞一次性替換手寫和圖像中的文本。
- 將來它會在個性化信息和字幕等領域釋放新的潛力,比如在增強現實 (AR) 中實現逼真的語言翻譯。
- 通過公布這項研究所具有的能力、方法和結果,研究者希望推動對話和研究,以發現這類技術的潛在應用,如深度假文本攻擊——這是人工智能領域的一大挑戰。
由于 TextStyleBrush 也可能被用來制作誤導性的圖像,所以 Facebook 的 CTO 在個人社交網站表示,他們只發布了論文和數據集,但沒有公開代碼。并表示正如我們對 deepfakes 的方法一樣,我們認為共享研究和數據集將有助于構建檢測系統并提前預防攻擊。
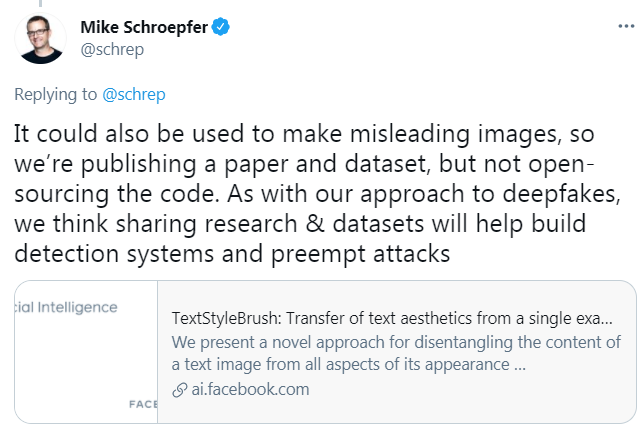
可以學習文本風格表征的 TextStyleBrush
用 AI 生成圖像一直在以驚人的速度發展,這種生成技術能夠重現歷史場景,或者將照片變成梵高等繪畫風格。現在,Facebook AI 已經建立了一個可以替換場景和手寫文本風格的 AI,只需要一個單詞作為輸入。
雖然大多數 AI 系統都可以完成定義明確的、專門的任務,但構建一個足夠靈活的 AI 系統,以理解現實場景中文本和手寫體的細微差別,具有很大的挑戰。這意味著需要了解眾多的文本樣式,不僅包括不同的字體和書寫風格,而且也包括不同的轉換,如旋轉、彎曲的文字以及圖像噪聲等問題。
Facebook AI 提出了 TSB(TextStyleBrush)架構。該架構以自監督的方法進行訓練,沒有使用目標風格監督,只使用了原始風格圖像。該框架可以自動地尋找圖片真實風格。在訓練時,它假設每個詞框有真實值(出現在框中的文本);推理時,它采用單一源樣式圖像和新內容(字符串),并生成帶有目標內容的源樣式的新圖像。
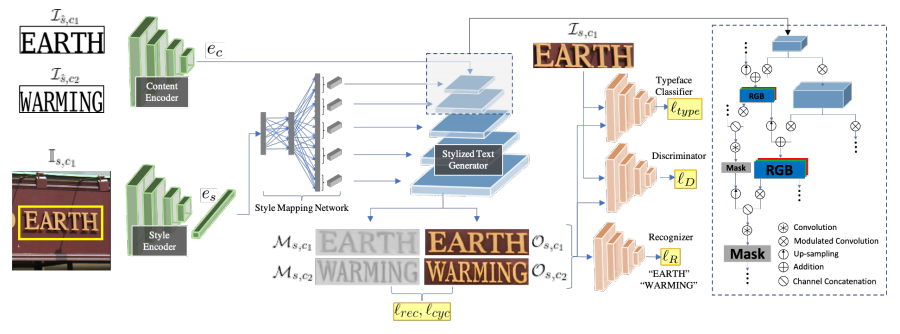
該生成器架構是基于 StyleGAN2 模型。然而,它有兩個重要的限制:
首先,StyleGAN2 是一個無條件模型,這意味著它通過對一個隨機的潛在向量進行采樣來生成圖像。但 TextStyleBrush 必須要生成指定文本的圖像。
其次,TextStyleBrush 生成的文本圖像風格不受控制。文本風格涉及全局信息(例如調色板和空間變換),以及精細的比例信息組合(例如單個筆跡的細微變化。
研究者通過內容和風格表征來調節生成器以解決上述限制。通過提取特定于層的風格信息并將其注入到生成器的每一層來處理文本風格的多尺度特性。除了以期望的風格生成目標圖像外,生成器還生成表示前景像素 (文本區域) 的軟蒙版圖像。通過這種方式,生成器可以控制文本的低分辨率和高分辨率細節,以匹配所需的輸入風格。
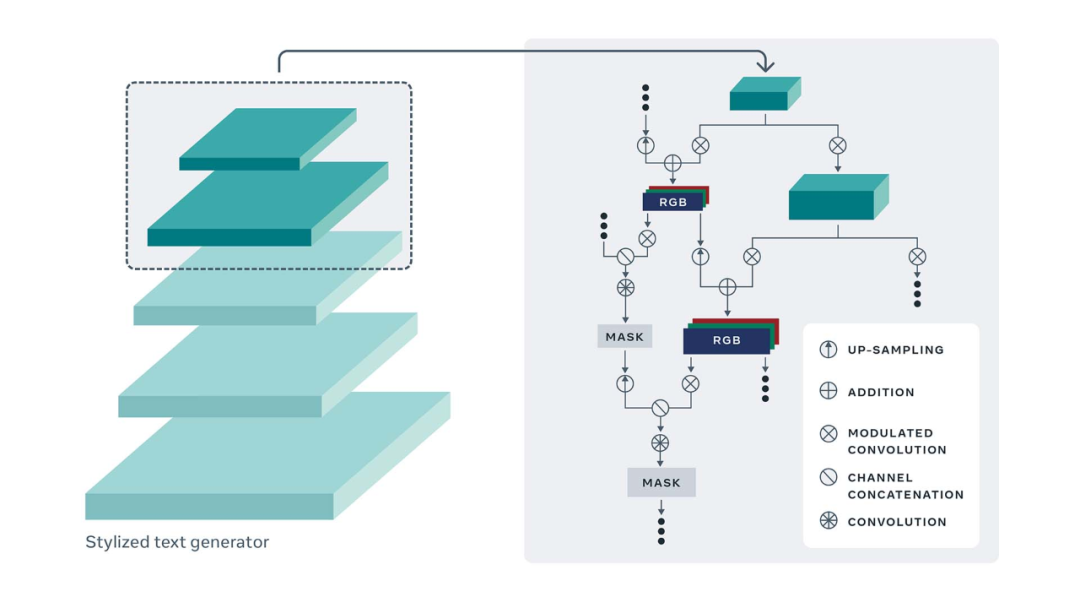
該研究還引入了一種新的自監督訓練準則,該準則使用字體(typeface)分類器、文本識別器和對抗式鑒別器來保留源風格和目標內容。首先,研究者通過使用預訓練的字體分類網絡來評估生成器捕獲輸入文本風格的能力。另外,他們使用預訓練文本識別網絡來評估生成圖像的內容,以反映生成器捕獲目標內容的效果。總而言之,這種方法能夠對訓練進行有效的自監督。
實驗
表 2 提供了評估不同損失函數、風格特征擴展以及訓練 TSB 時 mask 的作用消融實驗結果。實驗結果顯示,TextStyleBrush 生成的圖片在 MSE(合成誤差)上大幅降低,PSNR(峰值信噪比)、SSIM(結構相似性)均獲得了提高。
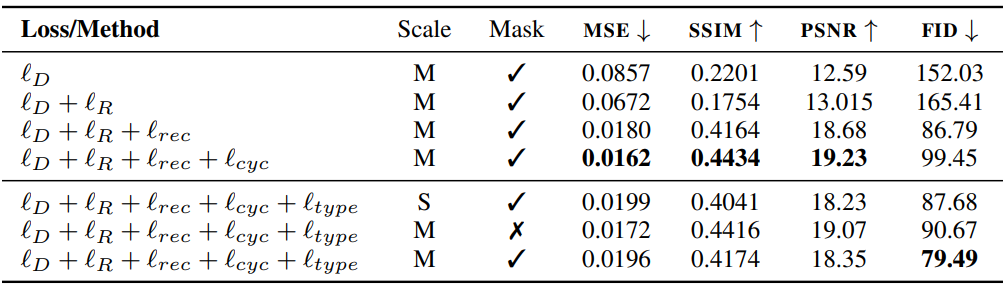
表 3 是在三種數據集圖像上測得的文本識別準確率。實驗結果顯示,TSB 的識別效果最好,在 IC13 上的識別準確率為 97.2%,IC15 上的識別準確率為 97.6%,TextVQA 上的識別準確率為 95.0%。
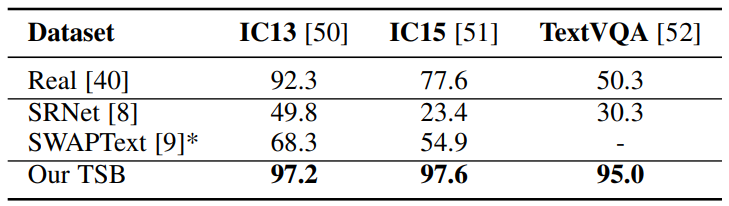
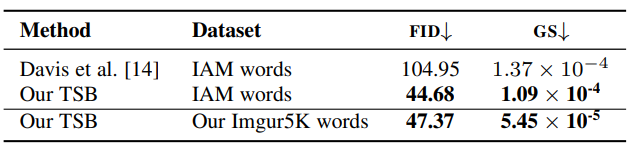
表 4 提供了生成的手寫文本的定量比較,將 TSB 方法與 Davis 等人 [14] 專門為生成手寫文本而設計的 SotA 方法進行了比較。FID 分數越低,生成質量越好。顯然,TSB 方法優于以前的工作。
TextStyleBrush 證明了 AI 在文字上面可以比過去更加靈活、準確地識別,但這項技術仍然存在許多問題,如無法模仿金屬表面的字符或彩色字符等, Facebook 希望這項研究能繼續擴展,突破翻譯、自主表達和 deepfake 研究之間的障礙等。

失敗案例