作者 | Jialin Liu, Mengyuan Chao, Jian Li, Wei Peng, Sixiang Ma, Wei Xu, Run Yang, Xin Chen
RayRTC 是字節基礎架構組與字節 AML 組共同合作,在內部 RTC(Realtime Text Classification)文本訓練平臺上基于 Ray 進行的下一代 Serverless ML 的探索。RTC 文本分類平臺是一個一站式的 NLP 服務平臺,包括了數據預處理,標注,模型訓練,打分,評估,AutoML 以及模型推理等機器學習全流程。目前字節內各大產品,包括抖音,TikTok,頭條,西瓜,番茄等都有使用該平臺提供的相關自然語言能力。RayRTC 通過算法與系統的協同設計及 Serverless 等技術為 RTC 提供了性能和資源利用率的極致優化,并由此抽象出一套通用的 Serverless ML 框架,目前已在字節內部機器學習平臺上部署上線。
RayRTC 的核心計算引擎是 Ray,最早是 UC Berkeley 的一個針對強化學習所設計的大規模分布式計算框架。Ray 的作者 Robert Nishihara 和 Philipp Moritz 在此基礎上成立了 Anyscale 這家公司。開源項目千千萬,能成功商業化并在硅谷乃至整個 IT 屆產生顛覆性影響的鳳毛麟角。Anyscale 的創始人中包括 Ion Stoica,這位羅馬尼亞籍教授上一家公司是跟他的學生 Matei Zaharia 以 Spark 技術為基礎成立的 Databricks 。Spark 和 Ray 分別誕生于大數據和機器學習時代,前者已經在工業界得到廣泛應用,后者也逐漸引起越來越多的公司在不同業務場景進行探索。字節美研計算團隊自 2020 年末開始接觸 Ray,2021 年開始在不同場景小范圍試驗。RTC 文本分類平臺是第一個大規模上線的 Ray 應用場景,在 RayRTC 的設計過程中,有不少第一手的經驗值得分享。本文從 RayRTC 所遇到的實際問題出發,對 Ray 在字節的實踐進行介紹。
第一次接觸 Ray 的讀者可能會問,除了明星創始人團隊,深度貼近當前 ML 需求的產學研支持,Ray 這套框架到底有哪些吸引人的地方?
首先是以 Ray 為底座可以非常輕松構建完整機器學習完整生態,如下圖所示:
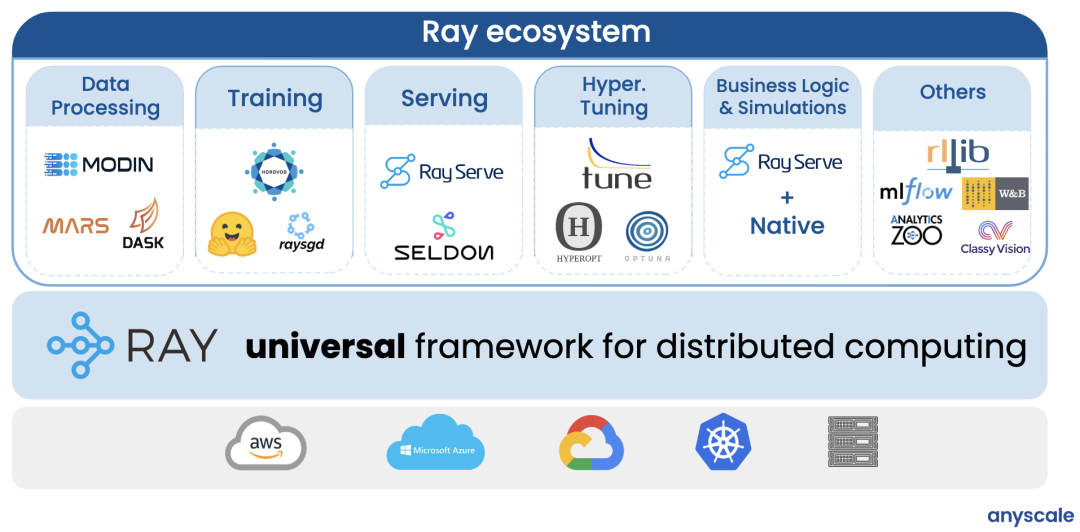
機器學習的研發人員往往不僅需要關注算法本身,在實際的生產環境中,各個環節所涉及的工程量和運維量也不容小覷。不少研究表明,工程師們有 80-90%的時間和精力投入在了算法之外的數據處理,全流程打通等。Ray 社區在近幾年的演進中,不斷吸收業界領先的理念,積極地與其他開源社區和各大廠商進行合作交流。以 Ray 為計算引擎的上層生態的豐富度是別的開源生態中不常見的。比如大數據處理方面,有 Intel 設計的 RayDP,將 Spark 無縫集成到 Ray 中,通過 Ray 的 Actor 拉起 Spark 的 executor,利用 Ray 的分布式調度實現資源細粒度的調控。這樣做的好處在于以 Spark 為大數據引擎的機器學習應用中,通過 Ray 可以將 Spark 產生的 dataframe 以 ML Dataset 的形式直接從內存傳給下游的機器學習框架,比如 PyTorch。而 Ray 的生態里的其他組件,比如超參訓練(Ray Tune)和推理服務(Ray Serve),則進一步補足了訓練階段后續的一系列工程需求。研發人員可以拋開繁瑣的上線部署流程,實現一鍵分布式以及一鍵部署。
Ray 的另一個顯著優勢是其簡單通用的 API ,只需在一段函數上加入ray.remote 的裝飾器,便可將一個單機程序變成分布式執行單元,如下所示:
#declare a Ray task
@ray.remote
def fun(a):
return a + 1
#submit and execute a Ray task
fun.remote()
#declare a Ray actor
@ray.remote
class Actor():
def fun(slef, a):
return a+1
actor = Actor.remote()
#execute an actor method
actor.fun.remote()
Ray 中最基礎的概念包括 Task 和 Actor,分別對應函數和類。函數一般是無狀態的,在 Ray 里被封裝成 Task,從而被 Ray 的分布式系統進行調度;類一般是有狀態的,在 Ray 里被映射成一個 Actor。Actor 的表達性更強,能覆蓋大多數的應用程序子模塊。基于 Actor 和 Task,Ray 對用戶暴露了資源的概念,即每個 actor 或 task 都可以指定運行所需要的資源,這對異構的支持從開發人員的角度變得非常便利。比如:
@ray.remote(num_cpus=1, num_gpus=0.2):
def infer(data):
return model(data)
當 task 在被提交執行的時候,Ray 的調度器會去找到一個滿足指定資源需求的節點。在此同時 Ray 會考慮數據的 locality。比如上述例子中的“data”,實際運行中可能會分布在任意一個遠端的節點的內存里,如果 task 不在數據所在的節點上執行,跨節點的數據傳輸就無法避免。而 Ray 可以讓這一類的優化變得透明。框架開發人員也可以利用 Ray 的 API 集成更豐富調度策略,最終提供給用戶的是非常簡單的 API。Ray 對 Actor 和 Task 還有很多高級的細粒度控制特性,比如支持 gang-scheduling 的 placement group 等,在此不一一贅述。
Ray 另外的優勢在于:
高效的數據傳遞和存儲:Ray 通過共享內存實現了一個輕量級的 plasma 分布式 object store。數據通過 Apache Arrow 格式存儲。
分布式調度:Ray 的調度是 decentralized,每個節點上的 raylet 都可以進行調度;raylet 通過向 gcs 發送 heart beat 獲取全局信息,在本地優先調度不能滿足的情況下,快速讓位給周邊 raylet 進行調度。
多語言的支持:目前已經支持的語言包括:Python, Java, C++。后續 go 的支持以及更通用的多語言架構設計也在進行中。
下圖是 RayRTC 的一個早期設計規劃圖和階段一核心部分(DP+Training)的 Actor 封裝流程圖。本文著重講解階段一,二的設計和實現。其中在階段一中所用到的核心組件包括 Ray Actor Pool 和 RaySGD 等。
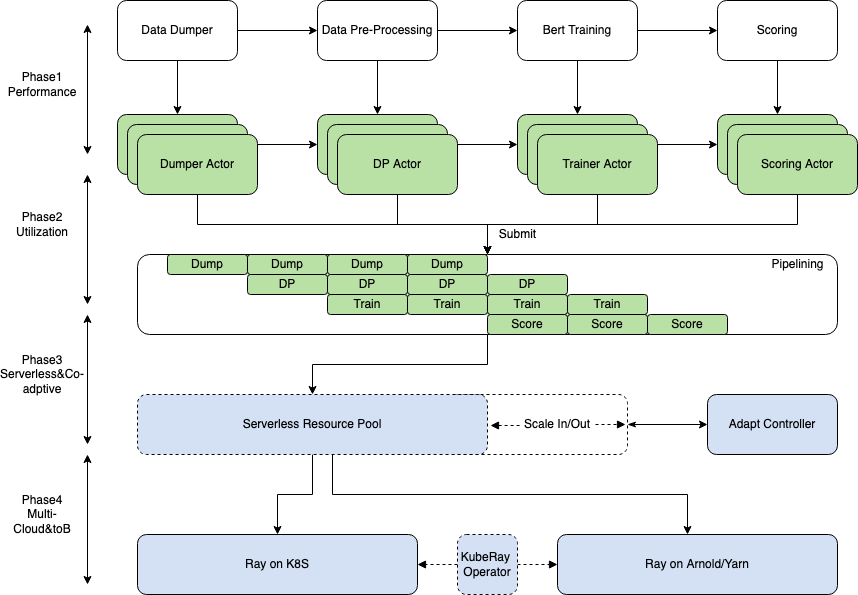
“DP+Training” Actor 化流程圖:

其中主要包括 DataProcessing 和 Training 兩個 Stage。每一部分的核心計算邏輯都用 Ray 的 API 封裝成為 Actor 或 Task。Actor 提交運行后通過 Ray 的調度被放置到合適的節點上執行。Ray 的集群資源可以通過改造后的 Autoscaler 在字節內的 Yarn/K8S 集群上實現動態擴縮容。
DP 實現過程中,我們利用 Ray 的 ActorPool 解決了一個因為創建 Actor 數目過多而導致的 OOM 問題。Actorpool 本身相當于一個線程池,但 Ray 的 Actorpool 可以被開發者拓展為更高階的彈性線程池。在 RayRTC 中,給定一組數據,我們需要解決的核心問題之一是使用多少 Ray 的 actor 是比較高效的。這里的高效指:資源使用高效,性能較優且穩定性較好(不能 oom)等。最簡單的設計方式是 1 對 1,即對于每一個 HDFS 路徑, 都指定一個單獨的 DP Actor 來進行處理。但當數據量線性增長時,由于缺少內存管控而很容易出現 OOM。最極端的方式是 n 對 1,即用一個 actor,順序處理所有數據,這樣做顯然無法發揮 Ray 的分布式能力。比較理想的方式是 n 對 m,即 m 個 actor 處理 n 組數據。作為對比,1 對 1 的情況如下:
ray_preprocessor_ret_refs = []
for hdfs_file_path in hdfs_file_path_list:
my_dp = ray.remote(DP).remote(hdfs_file_path)
ray_preprocessor_ret_refs.append(my_dp.__call__.remote())
n 對 m 的情況:
num_cpus = 10
actors = [ray.remote(DP).remote() for _ in range(num_cpus)]
actor_pool = ray.util.ActorPool(actors)
for hdfs_file_path in hdfs_file_path_list:
actor_pool.submit(lambda actor, info: actor.__call__.remote(**info),
hdfs_file_path)
在生產實踐中,通過對 m 取一個定值,比如 m=10,可以有效控制內存使用并實現 I/O 并行。如前所述,給定一個動態的 workload,我們也可以對 m 的進行彈性支持,類似于 K8S 的 HPA 或 Spark 的 dynamic allocation。不同的是,在 Ray 里,開發者通過可編程的方式實現定制化的 dynamic allocation,比較簡單的實現任意粒度的自動擴縮。這一部分的代碼可以參考最新版本的 Ray dataset 中的類似實現(https://github.com/ray-project/ray/blob/master/python/ray/data/impl/compute.py)。
Training 部分的邏輯由于歷史原因,在字節的內部場景有比較復雜的深度定制。對此,我們采用了 Ray 社區第一版的 Ray SGD(最新的版本中,這一模塊為 Ray Train)對已有訓練模塊進行封裝。RaySGD 是一個輕量級的分布式訓練框架,支持 PyTorch 和 TensorFlow。底層直接集成了 PyTorch 的 DDP 和 Tensorflow 的 MirroredStrategy 來進行數據并行。RaySGD 通過把訓練 worker 用 actor 進行封裝,不僅實現了更靈活的分布式統一調度,而且與整個 Ray 生態打通。比如可以與 Ray Tune(超參)和 Ray Serve(推理)直接在 actor 這一粒度上進行通信和數據傳輸。
數據并行的分布式訓練相比模型并行和混合并行的模式都要相對簡單。但把一個復雜的單機版 NLP 訓練框架通過 Ray 封裝為分布式框架,并做到對原代碼侵入性最小,需要處理好以下幾個問題:
- 單節點的訓練邏輯,如何設置模型,如何在 CPU 和 GPU 之間傳遞數據
- 如何設置 dataloader 以及 sampler,實現分布式數據讀取
- 如何控制一個 epoch 里的 batch 循環
- 分布式訓練邏輯,如何設置 worker 數量
- 如何使用 Ray 拉起 worker,并能在 worker 間通信
對于前 3 個問題,RayRTC 實現了 RayRTCTrainoperator,繼承自 ray.util.sgd.torch 中的 TrainingOperator,把單節點上的訓練邏輯全部抽象到一個類。
class RayRTCTrainOperator(TrainingOperator):
def setup(self, config):
# Setup data
self.train_loader = DataLoader(self.train_data,...)
self.valid_loader = DataLoader(self.valid_data,...)
# Register data loader
self.register_data(
train_loader=self.train_loader,
validation_loader=self.valid_loader)
...
# Register model, optimizer
self.model, self.optimizer = \
self.register(models=model, optimizers=optimizer,...)
在 RayRTCTrainOperator 這個類中,首先設置好訓練所需要的模型和數據,并將 optimizer,scheduler 等參數傳入。這些數據會隨著 RayRTCTrainOperator 這個類被 Ray 封裝為 actor,從而分布到不同的節點上,從而使得每個節點上都有一份完全一樣的模型的拷貝和參數的初始狀態。
數據格式的不同:
除了模型和數據的 setup,具體的訓練邏輯需要根據 RTC 的場景進行定制。比如,每一個 epoch 的訓練,以及一個 epoch 中每一個 batch 的訓練。由于 RaySGD 對于 input 有一定的格式假設,導致在 RayRTCTrainOperator 中,需要重定義 train_epoch 和 train_batch 這兩個函數以便正確處理數據和 metrics。舉例而言,在 RaySGD 中,batch input 需要符合以下格式:
*features, target = batch
(https://github.com/ray-project/ray/blob/ray-1.3.0/python/ray/util/sgd/torch/training_operator.py#L536)
而實際的場景中,用戶往往對數據格式有自己的定義。比如 RTC 中,batch 被定義為 Dict:
TensorDict = Dict[str, Union[torch.Tensor, Dict[str, torch.Tensor]]]
使用 RaySGD 中默認的 train_batch 函數,會在數據 unpack 時候發生錯誤。在 RayRTC 中,重寫的 train_batch 把處理后 batch 以正確的格式傳給 forward 函數。
訓練指標的自定義問題:
在 train_epoch 中,同樣有需要特殊處理的地方。RaySGD 默認支持的 metrics 只包括 loss 等。RTC 中,用戶主要關心的指標包括 accuracy, precision, recall 以及 f1 measure 等。這些指標如何在 RaySGD 中加入是 RayRTC 實現過程中遇到的一個不小的挑戰。一方面由于 RTC 本身已經實現了豐富的 metrics 計算模塊,一方面 RaySGD 對訓練過程中 metrics 的處理有固定的假設和且封裝在比較底層。RayRTC 最終采取的方法是把 RTC 中的 metrics 計算模塊復用到 RaySGD 的 train_epoch 中。另外遇到的一個問題是 RTC 的 metrics 計算需要把 model 作為參數傳入,而 RaySGD 中的 model 已經被 DDP 封裝,直接傳入會導致出錯。最后,train_epoch 需要加入如下改動:
if hasattr(model, 'module'):
metrics = rtc.get_metrics(model.module, ... reset=True)
else:
metrics = rtc.get_metrics(model, ... reset=True)
改動之后同時兼容了分布式和單機(沒有被 DDP 封裝)的情況。
RayRTCTrainOperator 可以理解為單機的訓練模塊,到了分布式環境下,可以通過 TorchTrainer 這個類。如下所示:
trainer = TorchTrainer(
training_operator_cls=RayRTCTrainOperator,
num_workers=self.num_workers,
use_fp16=self.use_fp16,
use_gpu=self.use_gpu,
...
num_cpus_per_worker=self.cpu_worker
)
Trainer 的主要功能是設置 training worker 的數量,混合精度,以及 worker 的 cpu 和 gpu。應用程序通過 trainer 可以非常簡單地控制整個分布式訓練的邏輯:
for epoch in epochs:
metrics['train'] = trainer.train()
metrics['validate'] = trainer.validate()
return metrics
Trainer 的底層邏輯中包括了拉起 worker group(https://github.com/ray-project/ray/blob/8ce01ea2cc7eddd40c2415904fa94198c0fe1e44/python/ray/util/sgd/torch/worker_group.py#L195),每一個worker用actor表達,從而形成一個actor group。RaySGD 也會處理 communication group 的 setup,以及 actor 的失敗重啟。經過這些封裝,用戶只需要關注跟訓練最直接相關的邏輯,而不需要花過多時間在底層通訊,調度等分布式邏輯,極大提高了編程效率。
Checkpoint 的問題:
在改造基本完成后,我們用抖音的數據進行測試,發現模型在多卡時,沒有任何調參的情況下,性能已經可以與單機持平,符合上線要求。但第一次上線測試后,發現 RayRTC 訓練出來的模型連基線模型都打不過,準確率甚至低到 30%。在把所有控制變量固定仍然沒有沒有找到原因后,第一反應是 RayRTC 訓練出來的模型可能并沒有真正保存下來,以致線上打分用到的實際是 pre-trained 的 bert 模型。事實證明確實如此,而導致這個原因是因為 RaySGD 中的 training worker 是在遠端運行,driver 端所初始的數據結構隨著訓練進行會與之逐漸不同步。checkpointing 之前需要取得更新后的模型參數,代碼如下所示:
for epoch in epochs:
metrics['train'] = trainer.train()
metrics['validate'] = trainer.validate()
self.model = trainer.get_model()
self.save_checkpoint()
return metrics
與之前比較,增加了第 4 行,通過 trainer 獲得更新后的 model,并通過 checkpoint 將模型持久化。
改造侵入性問題:
Anyscale 在一篇博客[https://www.anyscale.com/blog/ray-distributed-library-patterns]中總結了使用 Ray 的幾種 pattern。其中大致可以分為三類,RayRTC 屬于第三類。
- 用 Ray 做調度,比如 RayDP
- 用 Ray 做調度和通信,比如螞蟻的在線資源分配
- 用 Ray 做調度,通信,數據內存存儲
從第一類到第三類,用 Ray 的層次加深,但并不意味著改造成本線性增加。具體的應用需要具體分析。單純從代碼改動量上分析,RayRTC 第一階段改了大概 2000 行代碼,占原應用總代碼量的 1%不到。
同時,RayRTC 把訓練模塊單獨抽象出來,與原有代碼保持松耦合關系。用戶使用的時候,只需要載入相關 RayRTC 的模塊,即可啟動 Ray 進行分布式訓練。
實驗效果:
RayRTC 第一階段在 1 到 8 卡(NVIDIA V100)上進行 scaling 測試,如下圖所示:
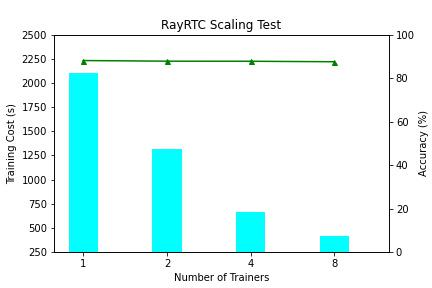
訓練速度上,RayRTC 的性能隨卡數呈現線性增加。訓練準確度上,RayRTC 沒有因為 global batch size 的增加而顯著降低。8 卡訓練中,單個 epoch 時間降到了 6 分鐘以內。以往研發人員往往需要等待幾個小時才能拿到訓練結果,導致大家都習慣在下班前大量提交作業,第二天再來查看效果。整體集群 quota 資源利用率在白天不高,在晚上排隊高峰。經過 RayRTC 提速后,研發人員會越來越多的進行接近交互式的開發迭代。
RayRTC pipeline
RayRTC 在字節內部運行在 Arnold 機器學習平臺。用戶在提交一個 RayRTC 任務時,對應在 Arnold 平臺上拉起一個 Trial。一個 Trial 里,用戶配置一個或多個 container 以及每個 container 所需的 CPU/GPU/Mem 資源。在一個 RayRTC 任務的整個生命周期中,對應 Trial 的資源是一直占用的。下圖展示了某 RTC 任務運行期間的 GPU 資源使用情況。

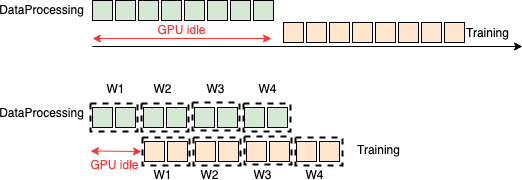
如圖所示,在 Data Processing(DP)階段,GPU 資源完全處于 idle 狀態。造成這個現象的主要原因是當前的 RayRTC 階段一方案雖然在 DP 和 Training 階段都充分利用 Ray 的并行能力進行加速,但是這兩個 stage 之間本質還是串行執行:Training 階段必須等到 DP 結束了才開始。對于 DP 時間長的 RayRTC 任務,這將帶來很大的 GPU 資源浪費。為了提高 GPU 資源使用率,我們結合 Ray Datasets 提供的 pipeline 功能, 提出并實現了 RayRTC 的流水并行方案 RayRTC pipeline。
Ray Datasets 是在 Ray1.6+版本引入的在 Ray 的 libraries 和應用之間加載和交換數據標準化方法,其本身提供了一定的基本分布式數據處理能力,如 map, filter, repartition 等。如下圖所示,數據經過 ETL 后,進入 ML Training 系統前,可以先通過 Ray Datasets 的 API 進行 last mile 的預處理。換言之,RayRTC 中的 DP 部分,完全可以用 Ray Datasets APIs 這種 Ray 標準化的方式重構,并與后面的 RaySGD(現 Ray Train)打通。
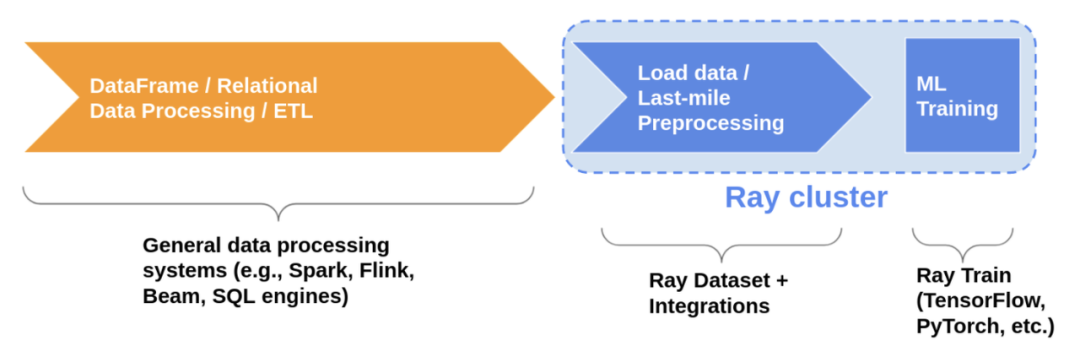
除了提供 last mile 預處理標準化 APIs, Ray Dataset s 還提供了一組非常重要的 pipeline 接口,使得 DP 部分和 Training 部分的流水并行執行成為可能。所謂流水并行執行,如下圖所示,Training 執行并不會等到 DP 全部結束后才開始,而是一旦 DP 完成了一小部分就會把處理后的數據直接傳入 Training 部分。流水處理有效減少 GPU idle 時間并縮短整個端到端 RTC 訓練時間。
基于 Ray Datasets 的 RayRTC pipeline 實現
RayRTC pipeline 版本一:把 DP 部分當做黑盒
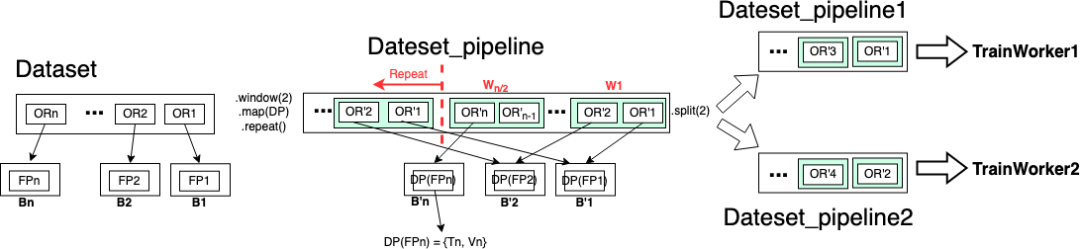
考慮到 RTC 中 DP 的復雜邏輯,在 RayRTC pipeline 版本一中,我們把 DP 當作黑盒處理。改造需求如下:
- DP(含 IO, trasforms, 數據集 split 等邏輯)與 Training 需要以 window 粒度流水并行,其中 DP 的 input 是文件路徑 fp_i,output 是訓練和驗證數據集{'T':Ti, 'V':Vi}。
- DP 中的 split 邏輯要保證多 epoch 訓練中每個 epoch 拿到的訓練/驗證數據集都相同,否則會導致數據泄露。多 epoch 訓練中,只有第一個 epoch 拿到的訓練/驗證數據集真正經歷 DP,其余 epoch 都復用之前已經處理分割好的數據集。
為滿足以上需求,我們利用 Ray Datasets 的 API 實現如下:
dsp= ray.data.from_items([fp1, fp2, …., fpn],parallelism=n)
.window(blocks_per_window=2).map(dp).repeat().split(2)
但是,以上改造無法滿足“每個訓練 worker 拿到相同數目的 training instances”這個需求,因為該改造中的 split 的粒度其實還是“文件”而非“training instances”,而每個文件中包含的 training instances 數很可能不一樣。為了滿足這個需求,我們更新實現如下:
dsp_train= ray.data.from_items([fp1, fp2, …., fpn],parallelism=n)
.window(blocks_per_window=2).map(dp).flat_map(takeT).repeat()
.split(2, equal=True)
dsp_valid= ray.data.from_items([fp1, fp2, …., fpn],parallelism=n)
.window(blocks_per_window=2).map(dp).flat_map(takeV).repeat()
.split(2, equal=True)
其中:
def takeT(row):
train_data = row['T'].iter_rows()
for data in train_data:
yield data.as_pydict()
def takeV(row):
train_data = row['V'].iter_rows()
for data in train_data:
yield data.as_pydict()
但是更新后的實現帶來了新問題:dsp_train 和 dsp_valid 實際對應兩次不同的 DP split 邏輯,從而導致了數據泄露。我們需要類似如下實現來解決:
dsp_train,dsp_valid = ray.data.from_items([fp1, fp2, …., fpn],parallelism=n)
.window(blocks_per_window=2).map(dp).unzip_and_flat_map('T', 'V')
.repeat().split(2, equal=True)
其中, unzip_and_flat_map 既有類似 unzip 功能,把原數據集分割成兩個數據集,原來數據集的 Row={'T':Ti, 'V':Vi} 變成兩個新數據集的 Row1=Ti,Row2=Vi;又有 flat_map 功能,把數據集的 Row1=Ti 真正展開成 Row=Training Instance。考慮到這個 API 實現復雜且不具通用性,我們放棄了該版本改造,轉向了 RayRTC pipeline 的版本二實現,把 DP 中的數據集分割邏輯抽取出來并提前,從開始就構造獨立的訓練/驗證 pipeline,其余剩下的 DP 邏輯保留。
RayRTC pipeline 版本二:把 DP 中的數據集 Split 邏輯抽取出來并提前

在 RayRTC pipeline 版本二實現中,我們將數據集 scaling 和 split 邏輯抽取出來往前移,先構造訓練和驗證數據集。然后,分別從這兩個數據集構造相應的訓練/驗證 pipelines。具體實現如下:
train_dataset, valid_dataset = self.get_datasets()
train_dataset_pipeline = train_dataset.window(blocks_per_window=2)
.flat_map(dp).repeat()
.random_shuffle_each_window().split(2, equal=True) # 2 is #trainWorkers
valid_dataset_pipeline = valid_dataset.window(blocks_per_window=2)
.flat_map(dp).repeat().split(2, equal=True) # 2 is #trainWorkers
其中:
def get_datasets(self):
# read dataset from hdfs
new_dataset = ray.data.read_api.read_json(partition_info_list)
# scale dataset up
scaled_dataset = new_dataset.flat_map(scale)
# shuffle dataset
shuffled_dataset = scaled_dataset.random_shuffle()
# split dataset into training and validation datasets
train_valid_ratio = 0.9
return shuffled_dataset.split_at_indices([int(shuffled_dataset.count() * train_valid_ratio)])
接著,train_dataset_pipeline 和 valid_dataset_pipeline 被傳入 trainer:在每個 training worker 的 setup() 中,根據自己的 rank 得到相應的子 pipeline。
self.train_dataset_pipeline = self.train_pipeline[self.world_rank]
self.train_dataset_pipeline_epoch = self.train_dataset_pipeline.iter_epochs()
self.valid_dataset_pipeline = self.valid_pipeline[self.world_rank]
self.valid_dataset_pipeline_epoch = self.valid_dataset_pipeline.iter_epochs()
在 training worker 的 train_epoch() 中,從子 training pipeline 中獲取 training instances 訓練。
def train_epoch():
dataset_for_this_epoch = next(self.train_dataset_pipeline_epoch)
train_dataset = self.data_parser.parse(dataset_for_this_epoch)
train_loader = DataLoader(train_dataset)
for batch_idx, batch in enumerate(train_loader):
metrics = self.train_batch(batch, batch_info)
在 training worker 的 validate() 中, 從子 validation pipeline 中獲取 validation instances 驗證。
def validate():
dataset_for_this_epoch = next(self.valid_dataset_pipeline_epoch)
valid_dataset = self.data_parser.parse(dataset_for_this_epoch)
valid_loader = DataLoader(valid_dataset)
for batch_idx, batch in enumerate(valid_loader):
metrics = self.validate_batch(batch, batch_info)
實驗效果:
為驗證 RayRTC-pipeline 效果,我們隨機選擇中等規模 RTC training job (約 168 萬條 instance),使用同等計算資源(2CPUs, 2GPUs)簡單做了如下對比實驗。結果顯示,使用 pipeline 后,GPU idle 時間從原來的 245s 減少到了 102s,約 2.5 倍降低。端到端時間也比原來減少了 158s。除此之外,相比于階段一實現,我們不但在初始階段對整個數據集進行 random_shuffle,在每個 window 的訓練數據從 pipeline 出來時,也通過 random shuffle 對 window 中的訓練數據再次進行 shuffle。結果顯示,充分的全局和局部 shuffle 有效提高模型精度。
Version | Accuracy | Precision | Recall | f1-measure | GPU idle time | E2E time |
RayRTC-phase1 | 0.804 | 0.637 | 0.571 | 0.602 | 245s | 2296s |
RayRTC-pipeline | 0.821 | 0.715 | 0.556 | 0.625 | 102s | 2138s |
Improve | +0.017 | +0.078 | -0.015 | +0.023 | -143s | -158s |
總結
RayRTC 以 Ray 為分布式計算學習引擎,對字節 RTC NLP 框架的全面改造升級不僅實現了性能的極致優化(5 小時到 30 分鐘),同時通過流水并行極大降低了 GPU 資源的 idle 時間(60% reduction)。RayRTC 以松耦合的形式對現有業務的侵入極小(<1% loc),同時為后續可插拔 low-level 優化和 serverless autoscaling 提供了 API 支持。可以預見,后續 RayRTC 在更大規模上進行超參以及與推理打通,將會形成更高效的端到端 Serverless NLP Pipeline。