













作者 | 羅子健
背景
飛書智能問答應(yīng)用于員工服務(wù)場景,致力于減少客服人力消耗的同時,以卡片的形式高效解決用戶知識探索性需求。飛書智能問答整合了服務(wù)臺、wiki 中的問答對,形成問答知識庫,在綜合搜索、服務(wù)臺中以一問一答的方式將知識提供給用戶。
作為企業(yè)級 SaaS 應(yīng)用,飛書對數(shù)據(jù)安全和服務(wù)穩(wěn)定性都有極高的要求,這就導(dǎo)致了訓(xùn)練數(shù)據(jù)存在嚴(yán)重的不足,且極大的依賴于公開數(shù)據(jù)而無法使用業(yè)務(wù)數(shù)據(jù)。在模型迭代過程中,依賴公開數(shù)據(jù)也導(dǎo)致模型訓(xùn)練數(shù)據(jù)存在與業(yè)務(wù)數(shù)據(jù)分布不一致的情況。通過和多個試點(diǎn)服務(wù)臺的合作,在得到用戶充分授權(quán)后,以不接觸數(shù)據(jù)的方式進(jìn)行訓(xùn)練。即模型可見數(shù)據(jù),但人工無法以任何方式獲取明文數(shù)據(jù)。
基于以上原因,我們的離線測試數(shù)據(jù)均為人工構(gòu)造。因此在計算 AUC(Area Under Curve)值進(jìn)行評估,會存在與業(yè)務(wù)數(shù)據(jù)分布不一致的情況,只能作為參考驗(yàn)證模型的性能,但不能作為技術(shù)指標(biāo)進(jìn)行優(yōu)化迭代。因此轉(zhuǎn)而采用用戶點(diǎn)擊行為去佐證模型效果的是否出現(xiàn)提升。
在業(yè)務(wù)落地的過程中,是否展示答案由模型計算的相似度決定。控制展示答案的 Threshold,會同時對點(diǎn)擊率和展示率產(chǎn)生重大影響。因此為了避免 Threshold 的值對指標(biāo)的干擾,飛書問答采用 SSR(Session Success Rate)作為決定性指標(biāo)去評估模型的效果。其計算方式如下,其中 total_search_number 會記錄用戶的每一次提問,search_click_number 會記錄用戶每一次提問后是否點(diǎn)擊、及點(diǎn)擊了第幾個答案。
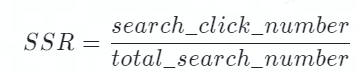
bot_solve_rate(BSR):用來評估機(jī)器人攔截的效果,機(jī)器人攔截越多的工單則會消耗越少的人力。
飛書智能問答模型技術(shù)
原始的 1.0 版本模型
問答服務(wù)最早采用的模型是 SBERT(Sentence Embeddings using Siamese BERT) 模型(1),也是業(yè)內(nèi)普遍使用的模型。其模型結(jié)構(gòu)如下所示:
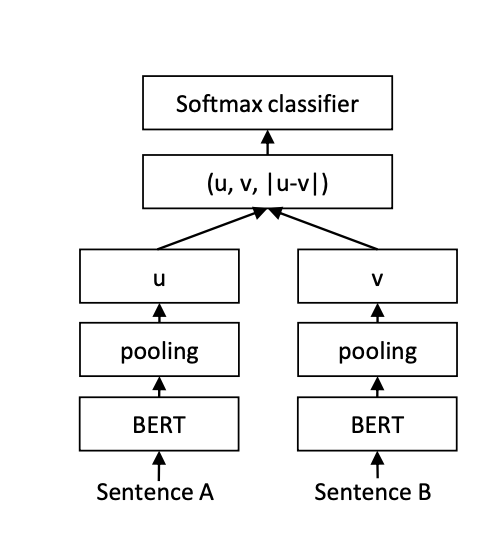
通過將 Query 和 FAQ 的 Question 輸入孿生 BERT 中進(jìn)行訓(xùn)練,并通過二分類對 BERT 的參數(shù)進(jìn)行調(diào)整。我們可以離線的將所有的 question 轉(zhuǎn)換為向量存在索引庫中。在推理時,將用戶的 Query 轉(zhuǎn)換為 Embedding,并在索引庫中進(jìn)行召回。向量的相似度均采用余弦相似度進(jìn)行計算,下文簡稱為相似度。
此方案相對于交互式模型,最大的優(yōu)點(diǎn)在于文本相似度的計算時間與 Faq 的數(shù)量脫鉤,不會線性增加。
改進(jìn)的 2.0 版本模型
1.0 版本的模型在表示學(xué)習(xí)上的表現(xiàn)依然不夠好,主要體現(xiàn)在即使是不那么相似的兩句話,模型依舊會給出相對較高的分?jǐn)?shù),導(dǎo)致整體的區(qū)分度很低。2.0 版本的模型考慮通過增加兩句話的交互,進(jìn)而獲得更多的信息,能夠更好的區(qū)分兩句話是否相似。并且引入了人臉識別的思想,讓相似的內(nèi)容分布更加緊湊,不相似的內(nèi)容類間距更大,進(jìn)而提高模型的區(qū)分度。其結(jié)構(gòu)如下所示:
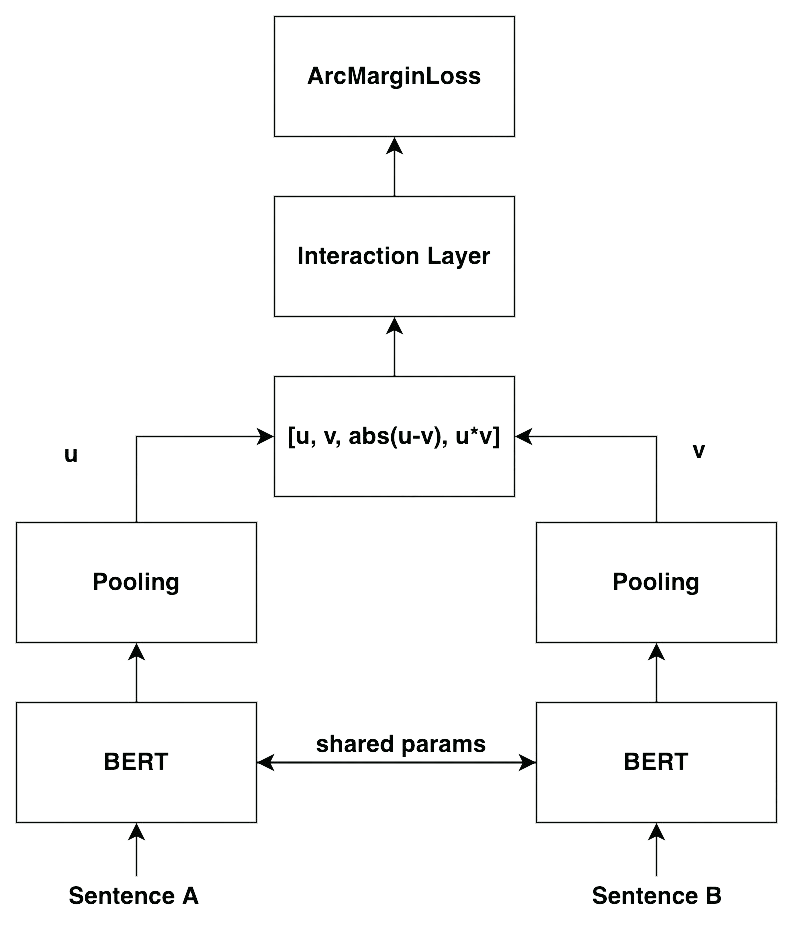
相對于 1.0 版本的模型,2.0 版本更加強(qiáng)調(diào)交互的重要性。在原先 concat 的基礎(chǔ)上,新增了 u*v 作為特征,并增加了 interaction layer(本質(zhì)上是 MLP layer)去進(jìn)一步增強(qiáng)交互。除此之外,引入了 CosineAnnealingLR(2)和 ArcMarinLoss(3)去優(yōu)化訓(xùn)練過程。除此以外,根據(jù) Bert-Whitening(3)的實(shí)驗(yàn)啟示,在 pooling 的時候采用了多種 pooling 的方法,去尋找最優(yōu)的結(jié)果。
CosineAnnealingLR
余弦退火學(xué)習(xí)率通過緩慢下降+突然增大的方法,在模型即將到達(dá)局部最優(yōu)的時候,可以“逃離”局部最優(yōu)空間,并且進(jìn)一步檢索到更好的局部最優(yōu)解。下圖源自 CosineAnnealingLR 的 paper,其中 default 是 StepLR 的衰減,其他則為余弦周期性衰減,并在衰減為 0 時恢復(fù)最大值。
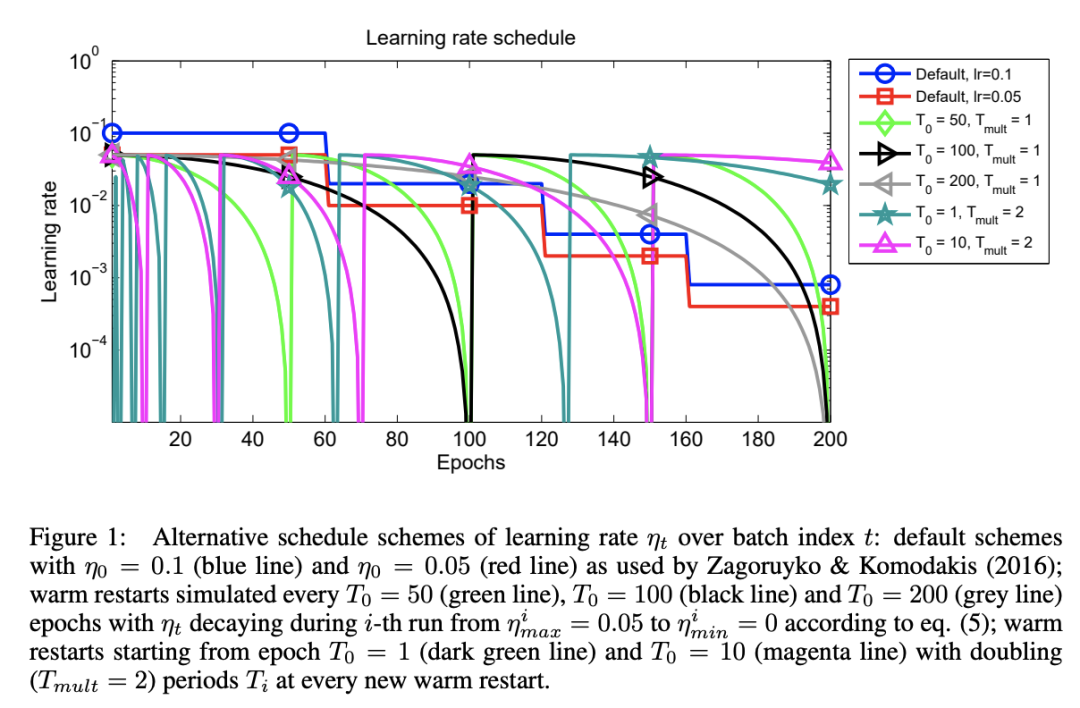
相比于傳統(tǒng)的 StepLR 衰減,余弦退火的衰減方法,可以讓模型更容易找到更好的局部最優(yōu)解,下圖模擬了 StepLR 和 CosineAnnealingLR 梯度下降過程(4):
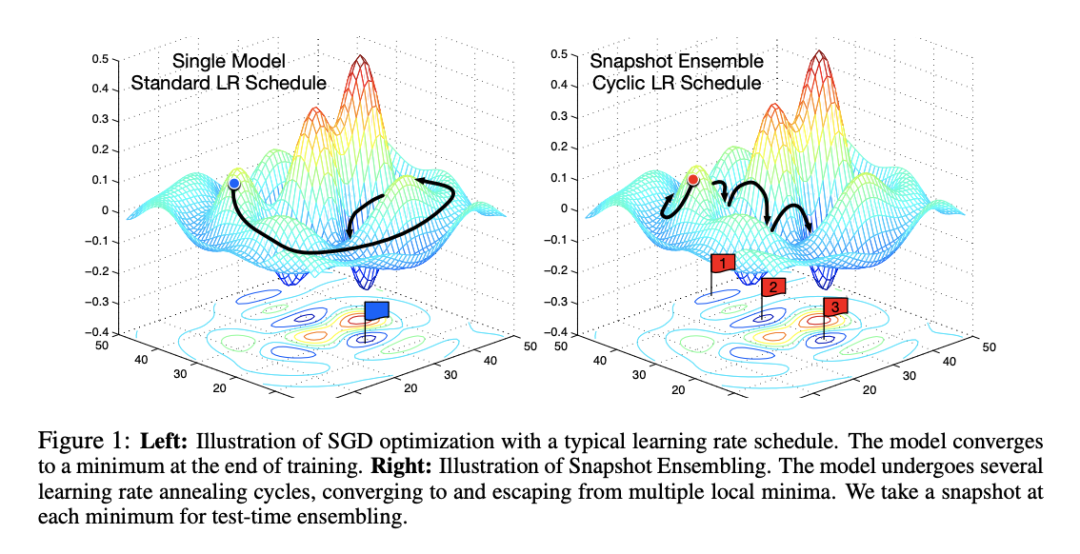
同樣的,由于余弦退火模型會找到多個局部最優(yōu),因此訓(xùn)練時間也會長于傳統(tǒng)的 StepLR 衰減。另一方面,由于學(xué)習(xí)率的突然增大,會導(dǎo)致 loss 的上升,因此在訓(xùn)練過程中 Early Stopping 的控制可以根據(jù) Steps 而不是 Epoches。
在服務(wù)臺落地場景中,不同的服務(wù)臺的語義空間明顯不同,不同的服務(wù)臺數(shù)據(jù)量(包括正負(fù)例比例)也存在較大的差異,模型不可避免的存在 bias,余弦退火可以一定程度解決這個問題。
ArcMarinLoss
采用 Arcface 損失函數(shù)的靈感來自 SBERT 論文中的 TripletLoss,其最早被用于人臉識別中。然而,TripletLoss 依賴于三元組輸入,構(gòu)建模型的當(dāng)時不存在這樣的條件去獲取數(shù)據(jù),因此沿著思路找到了 ArcMarginLoss:最新用于人臉識別的損失函數(shù),在人臉識別領(lǐng)域達(dá)到了 SOTA,在 Softmax 基礎(chǔ)上在對各類間距離進(jìn)行了加強(qiáng)。
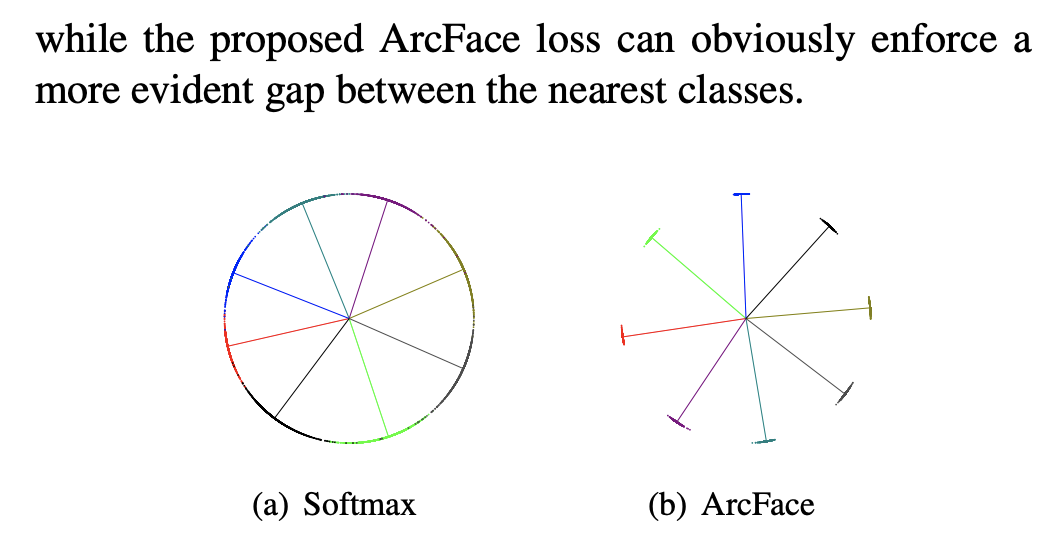
然而,我們無法像人臉識別那樣,將語義分成 Group,并對 Group 進(jìn)行 N 分類。NLP 相關(guān)問題遠(yuǎn)比人臉識別要復(fù)雜得多,訓(xùn)練數(shù)據(jù)也難以像人臉識別那樣獲得。但我們?nèi)匀豢梢酝ㄟ^二分類,將相關(guān)/不相關(guān)這兩類拆分的更開。
實(shí)驗(yàn)結(jié)果
根據(jù) AB 實(shí)驗(yàn)的結(jié)果,1.0 版本模型和 2.0 版本模型的指標(biāo)如下所示:
Top1 SSR | Top10 SSR | Top1 Click Rate | BSR | |
相對提高 | +7.75% | +6.43% | +1.24% | +3.55% |
其中 Top1 SSR 只是只考慮點(diǎn)擊第一位的 SSR,而 Top10 SSR 則是點(diǎn)擊前 10 位的 SSR。由于對于用戶的一次請求,最多只會召回 10 個相似的結(jié)果,因此 Top10 SSR 就是整體的 SSR。
Top1 Click Rate 是指在點(diǎn)擊的條件下,點(diǎn)擊第一條信息的概率是多少,即 Top1SSR/Top10SSR。
由上表可以看出,整體的 SSR 出現(xiàn)了明顯的上升,且 Top1 的點(diǎn)擊占比也出現(xiàn)了小幅提高。因此從業(yè)務(wù)指標(biāo)來推測 2.0 版本的模型明顯好于 1.0 版本的模型。BSR 作為業(yè)務(wù)側(cè)最關(guān)心的指標(biāo),受到用戶行為和產(chǎn)品策略的影響很大,但通過 AB 實(shí)驗(yàn)也可以看出,新的模型通過機(jī)器人攔截的工單數(shù)明顯上升,可以減少下游客服人力的消耗。
消融實(shí)驗(yàn)
針對 ArcMarginLoss 的效果進(jìn)行消融實(shí)驗(yàn),在其他條件都不變的情況下,采用相同的人造測試集,分別采用 ArcMarginLoss 和 CrossEntropyLoss 進(jìn)行模型訓(xùn)練。
在這里采用 AUC 的原因,是為了觀測:
ArcMarginLoss | CrossEntropyLoss | |
AUC 的值 | 0.925 | 0.919 |
因此通過消融實(shí)驗(yàn)可以看出,ArcMarginLoss 雖然在測試集上有少許提升,但提升并不明顯。原因可能是用于人臉識別訓(xùn)練模型的 ArcMarginLoss 通常以海量相似圖片作為一個 label 去進(jìn)行訓(xùn)練,而在此任務(wù)的數(shù)據(jù)為兩句間關(guān)系的 0/1 分類,導(dǎo)致其和人臉識別目標(biāo)并不相同,無法產(chǎn)生較好的效果。
基于 Contrastive Learning 的 3.0 版本
2.0 版本的模型雖然緩解了分?jǐn)?shù)相對集中的問題,但依然無法解決數(shù)據(jù)整體分布不均勻的問題(正負(fù)樣本 1:10),即正樣本的數(shù)量遠(yuǎn)小于負(fù)樣本,導(dǎo)致模型更傾向于學(xué)習(xí)負(fù)樣本的內(nèi)容。3.0 版本的模型借鑒了 Contrastive Learning 的思想,將二分類問題轉(zhuǎn)化為 N 分類問題,負(fù)樣本不再是多個 Item 進(jìn)而保證模型會更好的學(xué)習(xí)到正樣本的內(nèi)容。
Contrastive Learning
在 3.0 版本的模型中,參考了最新的論文 SimCSE(5),將 Contrastive Learning 的思想引入了模型中并進(jìn)行訓(xùn)練。其思想利用兩次 dropout 得到同一句話的不同表示,并進(jìn)行訓(xùn)練。如下圖所示:
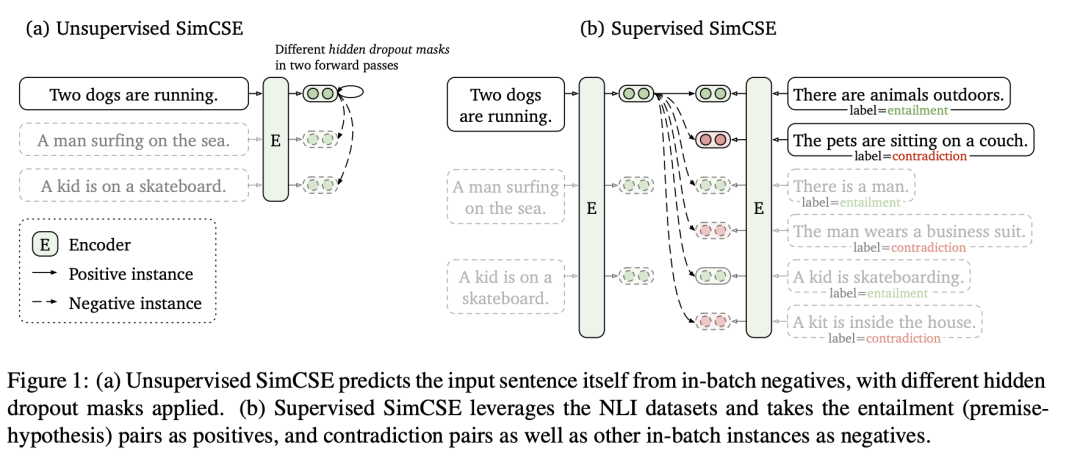
在實(shí)際訓(xùn)練中,采用了 Supervised SimCSE 的思想,將<query_i,question_i>作為正樣本的 Pair 輸入到模型中。每一個 query 都與其他的 question 作為負(fù)樣本進(jìn)行訓(xùn)練,但不與其他的 query 交互(原文不同的 query 間也是負(fù)例)。一個例子如下所示,假設(shè)輸入 3 個 pair,則 label 如下:
query1 | query2 | query3 | |
question1 | 1 | 0 | 0 |
question2 | 0 | 1 | 0 |
question3 | 0 | 0 | 1 |
通過 BERT 可以將文本轉(zhuǎn)換為 embedding,并計算相似度。根據(jù)上述構(gòu)造 label 的方法,使用 CrossEntropyLoss 計算并更新參數(shù)。
因此,Contrastive Learning 的目標(biāo)函數(shù)可以用以下表達(dá):
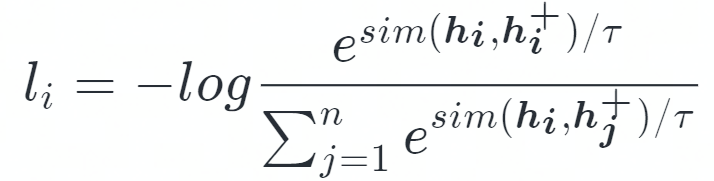
其中 sim 是余弦相似度計算,<hi,hi+>為一個 Sentence Pair。
從 Momentum contrastive 而來的 trick
原始的 SimCSE 采用 CrossEntropyLoss 直接得到 loss 的值,然而由于超參數(shù) T 的存在,導(dǎo)致余弦相似度的值被放大,最終在 softmax 后概率分布更加集中傾向于相似度高的值,而相似度低的值概率會趨近于 0。因此,超參數(shù) T 的值會嚴(yán)重影響反向傳播的時候梯度的大小,并且隨著 T 的縮小梯度不斷增大,使得實(shí)際的 lr 遠(yuǎn)大于 CrossEntropyLoss 中定義的 lr,導(dǎo)致模型訓(xùn)練收斂速度變慢。為了緩解這個問題,在 Momentum contrastive(6)中采用了 loss_i = 2 * T * l_i 的方法,本文應(yīng)用了該方法作為 loss 進(jìn)行訓(xùn)練。
實(shí)驗(yàn)結(jié)果
根據(jù) AB 實(shí)驗(yàn)的結(jié)果,2.0 版本和 3.0 版本的模型業(yè)務(wù)指標(biāo)如下:
Top1 SSR | Top8 SSR | Top1 Click Rate | BSR | |
相對變化 | +7.10% | +5.88% | +1.19% | +4.07% |
首先由于不同時期的業(yè)務(wù)數(shù)據(jù)存在波動,因此 2.0 版本的 top1 SSR 與前文的數(shù)據(jù)存在一定的偏差。且業(yè)務(wù)側(cè)進(jìn)行了改動,總展示數(shù)量從 10 個變成了 8 個,因此 Top10 SSR 修改為了 Top8 SSR。
最后,BSR 在該 AB 實(shí)驗(yàn)中的表現(xiàn)與上文的 AB 實(shí)驗(yàn)中 1.0 版本模型相似,是因?yàn)樾薷牧诉M(jìn)入機(jī)器人工單的統(tǒng)計口徑。原先搜索中展示了問題,會直接跳轉(zhuǎn)進(jìn)入機(jī)器人并記錄為機(jī)器人解決問題,現(xiàn)在搜索會直接展示答案而無需進(jìn)入服務(wù)臺。因此,搜索側(cè)攔截了一部分的工單,且未被記入機(jī)器人攔截,導(dǎo)致了 BSR 的下降,而非數(shù)據(jù)波動導(dǎo)致。但對比 AB 實(shí)驗(yàn)的結(jié)果,新模型的 BSR 仍然提高了 4.07%,提升顯著。
綜上所屬,很顯然模型在核心技術(shù)指標(biāo)上均有明顯提高。不僅在用戶需求的滿足率上提高了 5.88%,答案排名在第一位的比例也提高了 1.19%,模型效果有了全面的提高。
模型提高的原因
- 數(shù)據(jù)的組織方式不同。Contrastive Learning 僅使用數(shù)據(jù)集中正例,采用同一個 batch 內(nèi)的其他 Question 作為負(fù)例,這意味著對于同一個 query 負(fù)例的數(shù)量遠(yuǎn)大于原始數(shù)據(jù)集。相比于 2.0 版本的模型,對于所有的正例模型都有更多的負(fù)例去更好的識別真正相似的句子。
- 損失函數(shù)決定了訓(xùn)練目標(biāo)不同。2.0 版本的損失函數(shù)僅需要考慮兩句話之間的關(guān)系,而 3.0 版本模型需要同時考慮一個 batch 內(nèi)的所有句子間的關(guān)系,進(jìn)行 batch_size = N 的 N 個句子中找到正例。
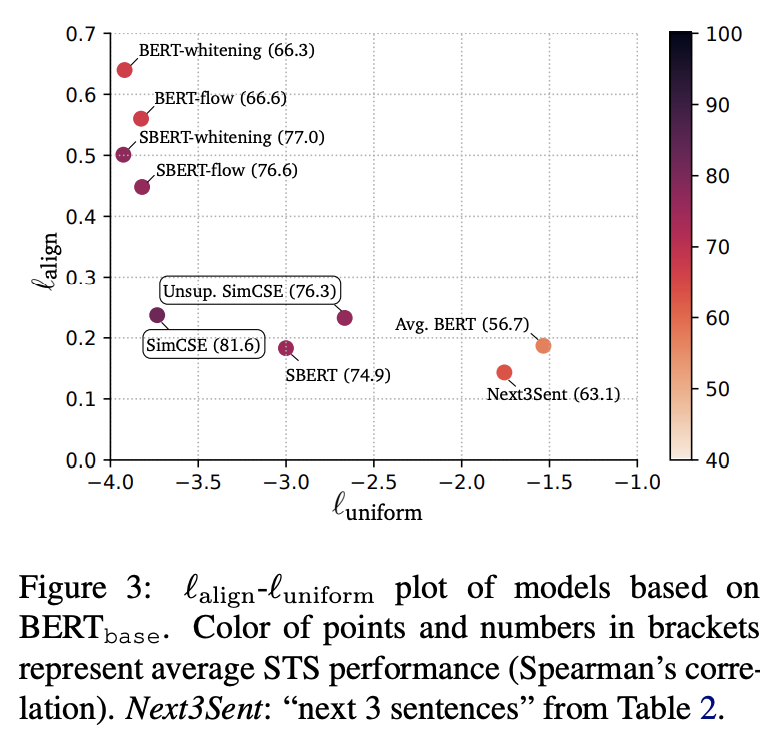
- 根據(jù)論文,通過 Contrastive Learning 可以消除 BERT 的各向異性(Anisotropy)。具體體現(xiàn)在 BERT 的語義空間集中在一個狹窄的錐形區(qū)域,導(dǎo)致余弦相似度的值會顯著偏大,即使完全不相關(guān)的兩句話也能得到比較高的分?jǐn)?shù)。該觀點(diǎn)在 Ethayarajh(6)和 Bohan Li(7)對預(yù)訓(xùn)練模型的 embedding 研究中得到了證明。而使用 Contrastive Learning 或各種 postprocessing(如 whitening(8), flow(9))可以消除這一問題。
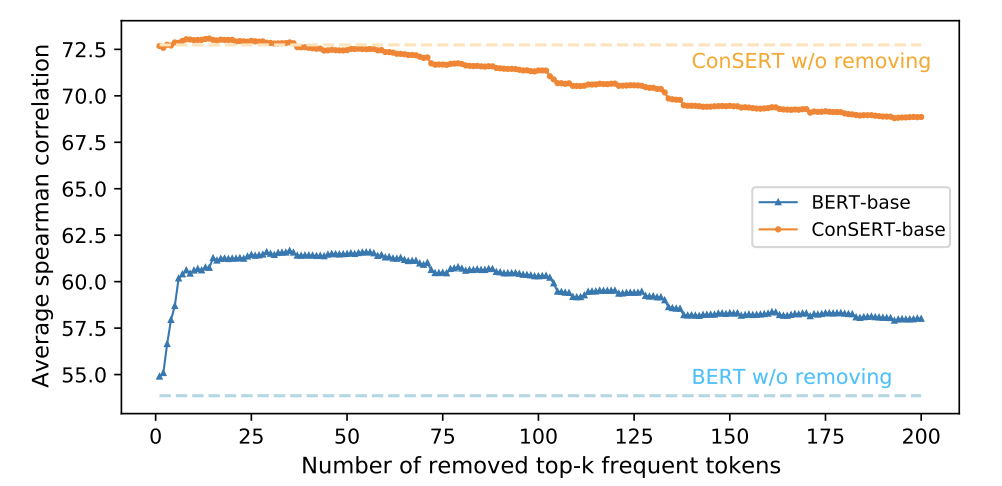
- 高頻的詞匯嚴(yán)重影響了 BERT 中句子的 embedding,少量的高頻詞匯決定了 embedding 的分布,導(dǎo)致 BERT 模型的表達(dá)能力變差,Contrastive Learning 可以消除此影響。根據(jù)論文 ConSERT(10)的實(shí)驗(yàn),證明了高頻詞確實(shí)會嚴(yán)重影響 embedding 的表達(dá),如圖所示:
消融實(shí)驗(yàn)
為了探索 Loss 和數(shù)據(jù)對模型的影響,該消解實(shí)驗(yàn)采用與 Contrastive Learning 一樣的正負(fù)樣本及比例進(jìn)行訓(xùn)練,其訓(xùn)練方法如下:
- 令 batch_size = 32, 則根據(jù) Contrastive Learning 的思想得到余弦相似度矩陣,維度為[32,32]。
- 根據(jù) Contrastive Learning 生成 label 矩陣,即[32,32]的單位矩陣。
- 將余弦矩陣和 label 矩陣,均轉(zhuǎn)換為[32*32,1]的矩陣,在此條件下數(shù)據(jù)組織模式完全相同,只有損失函數(shù)和訓(xùn)練方式不同。用以上方式進(jìn)行訓(xùn)練,并在離線測試集上進(jìn)行 AUC 計算。
簡單來說,Contrastive Learning 從 32 個句子中找到了最相似的 1 個,而 CrossEntropyLoss 則是進(jìn)行了 32 次二分類。通過上述方法,分別對 Contrastive Learning 和 CrossEntropyLoss 的二分類進(jìn)行訓(xùn)練,結(jié)果如下:
Contrastive LearningN 分類 | CrossEntropyLoss 二分類 | |
AUC 的值 | 0.935 | 0.861 |
通過進(jìn)一步研究發(fā)現(xiàn),CrossEntropyLoss 的二分類會傾向于將文本的相似度標(biāo)為 0,因此過量的負(fù)樣本使得模型忽略了對正樣本的學(xué)習(xí),僅通過判斷 label = 0 的情況即可在訓(xùn)練集上達(dá)到 98%的準(zhǔn)確率。
通過消解實(shí)驗(yàn)也證明了損失函數(shù)對該模型的訓(xùn)練存在顯著的影響,當(dāng)負(fù)樣本足夠多,在相同數(shù)據(jù)組織方式的條件下,Contrastive Learning 的效果要優(yōu)于 CrossEntropyLoss。由于在真實(shí)業(yè)務(wù)中,正樣本的數(shù)量遠(yuǎn)小于負(fù)樣本,因此基于 Contrastive Learning 的訓(xùn)練方法更適合應(yīng)用于業(yè)務(wù)中。



























