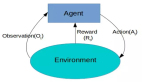
強化學習的起源:從老鼠走迷宮到AlphaGo戰勝人類
?談到強化學習,很多研究人員的腎上腺素便不受控制地飆升!它在游戲AI系統、現代機器人、芯片設計系統和其他應用中發揮著十分重要的作用。
強化學習算法有很多不同的類型,但主要分為兩類:「基于模型的」和「無模型的」。
在與TechTalks的對話中,神經科學家、 「智能的誕生」一書的作者Daeyeol Lee分別討論了人類和動物強化學習的不同模式、人工智能和自然智能,以及未來的研究方向。?

無模型的強化學習
19世紀后期,心理學家Edward Thorndike提出的「效應定律」成為了無模型強化學習的基礎。 Thorndike提出,在特定情境中具有積極影響的行為,在該情境中更有可能再次發生,而產生負面影響的行為則不太可能再發生。
Thorndike在一個實驗中探索了這一「效應定律」。 他把一只貓放在一個迷宮盒子中,并測量貓從盒中逃脫所需的時間。為了逃脫,貓必須操作一系列小工具,如繩子和杠桿。Thorndike觀察到,當貓與謎盒互動時,它學會了有助于逃跑的行為。隨著時間的推移,貓逃離盒子的速度越來越快。 Thorndike的結論是,貓可以從其行為提供的獎勵和懲罰中進行學習。 「效應定律」后來為行為主義鋪平了道路。行為主義是心理學的一個分支,試圖從刺激和反應的角度來解釋人類和動物的行為。 「效應定律」也是無模型強化學習的基礎。在無模型強化學習中,通過主體感知世界,然后采取行動,同時衡量獎勵。
在無模型強化學習中,并不存在直接的知識或世界模型。RL代理必須通過反復試驗,直接去體驗每個動作的結果。
基于模型的強化學習
Thorndike的「效應定律」一直流行到20世紀30年代。當時另一位心理學家Edward Tolman在探索老鼠如何快速學會走迷宮時發現了一個重要的見解。在他的實驗中,Tolman意識到動物可以在沒有強化的情況下了解他們的環境。
例如,當一只老鼠在迷宮中被放出來時,它會自由地探索隧道,并逐漸了解環境的結構。如果隨后將這只老鼠重新放進相同的環境,并提供強化信號,如尋找食物或尋找出口,那么它可以比沒有探索過迷宮的動物更快地到達目標。 Tolman稱之為「潛在學習」,這成為基于模型的強化學習的基礎。 「潛在學習」使動物和人類對他們的世界形成一種心理表征,在他們的頭腦中模擬假設的場景,并預測結果。

基于模型的強化學習的優點是它消除了agent在環境中進行試錯的需要。 值得強調的一點是:基于模型的強化學習在開發能夠掌握國際象棋和圍棋等棋盤游戲的人工智能系統方面尤其成功,可能的原因是這些游戲的環境是確定的。

基于模型 VS 無模型
通常來說,基于模型的強化學習會非常耗時,在對時間極度敏感的時候,可能會發生致命的危險。 Lee說:「在計算上,基于模型的強化學習要復雜得多。首先你必須獲得模型,進行心理模擬,然后你必須找到神經過程的軌跡,再采取行動。不過,基于模型的強化學習不一定就比無模型的RL復雜。」 當環境十分復雜時,倘若可以用一個相對簡單的模型(該模型可以快速獲得)進行建模,那么模擬就會簡單得多,而且具有成本效益。?
多種學習模式
其實,無論是基于模型的強化學習還是無模型的強化學習都不是一個完美的解決方案。無論你在哪里看到一個強化學習系統解決一個復雜的問題,它都有可能是同時使用基于模型和無模型的強化學習,甚至可能更多形式的學習。 神經科學的研究表明,人類和動物都有多種學習方式,而大腦在任何特定時刻都在這些模式之間不斷切換。 ?最近幾年,人們對創造結合多種強化學習模式的人工智能系統越來越感興趣。 加州大學圣地亞哥分校的科學家最近的研究表明,將無模型強化學習和基于模型的強化學習結合起來,可以在控制任務中取得卓越的表現。 Lee表示:「如果你看看像AlphaGo這樣復雜的算法,它既有無模型的RL元素,也有基于模型的RL元素,它根據棋盤配置學習狀態值,這基本上是無模型的 RL,但它同時也進行基于模型的前向搜索。」
盡管取得了顯著的成就,強化學習的進展仍然緩慢。一旦RL模型面臨復雜且不可預測的環境,其性能就會開始下降。?
Lee說:「我認為我們的大腦是一個學習算法的復雜世界,它們已經進化到可以處理許多不同的情況。」
除了在這些學習模式之間不斷切換之外,大腦還設法一直保持和更新它們,即使是在它們沒有積極參與決策的情況下。
心理學家Daniel Kahneman表示:「維護不同的學習模塊并同時更新它們是有助于提高人工智能系統的效率和準確性。」
我們還需要清楚另一件事——如何在AI系統中應用正確的歸納偏置,以確保它們以具有成本效益的方式學習正確的東西。 數十億年的進化為人類和動物提供了有效學習所需的歸納偏置,同時使用盡可能少的數據。 歸納偏置可以理解為,從現實生活觀察到的現象中,總結出規則,然后對模型做一定的約束,從而可以起到模型選擇的作用,即從假設空間中選擇出更符合現實規則的模型。 Lee說:「我們從環境中獲得的信息非常少。使用這些信息,我們必須進行概括。原因是大腦存在歸納偏置,并且存在可以從一小組示例中概括出來的偏置。這是進化的產物,越來越多的神經科學家對此感興趣。」 然而,雖然歸納偏置在物體識別任務中很容易理解,但在構建社會關系等抽象問題中就變得晦澀難懂。 未來,需要我們了解的還有很多~~~?
參考資料:
https://thenextweb.com/news/everything-you-need-to-know-about-model-free-and-model-based-reinforcement-learning?