













網(wǎng)易數(shù)帆開源Arctic:推動湖倉一體落地,驅(qū)動業(yè)務價值
原創(chuàng)數(shù)字時代,數(shù)據(jù)呈現(xiàn)出了大規(guī)模、多樣性、極速增長的態(tài)勢,同時,企業(yè)對數(shù)據(jù)處理分析的實時性和融合性提出了更高的要求,數(shù)據(jù)應用場景正在向復雜化、多元化轉(zhuǎn)變,從最初的交易場景,到分析場景,再到混合場景、復雜分析場景,再到如今的實時混合場景,隨之而來的是大數(shù)據(jù)架構在一直不斷地演進。從數(shù)據(jù)庫、數(shù)據(jù)倉庫、數(shù)據(jù)湖,到現(xiàn)在 “湖倉一體(Lake House)”的概念應運而生。
根據(jù)DataBricks公司的定義,湖倉一體是一種結(jié)合了數(shù)據(jù)湖和數(shù)據(jù)倉庫優(yōu)勢的新范式,在用于數(shù)據(jù)湖的低成本存儲上,實現(xiàn)與數(shù)據(jù)倉庫中類似的數(shù)據(jù)結(jié)構和數(shù)據(jù)管理功能。湖倉一體是一種更開放的新型架構,它打通了數(shù)據(jù)倉庫和數(shù)據(jù)湖,將數(shù)據(jù)倉庫的高性能及管理能力與數(shù)據(jù)湖的靈活性融合了起來,底層支持多種數(shù)據(jù)類型并存,能實現(xiàn)數(shù)據(jù)間的相互共享,上層可以通過統(tǒng)一封裝的接口進行訪問,可同時支持實時查詢和分析,為企業(yè)進行數(shù)據(jù)治理帶來了更多的便利性。
目前國內(nèi)外同行將 delta、iceberg 和hudi 作為數(shù)據(jù)湖 table format 的對標方案。delta的推出是為了解決傳統(tǒng)數(shù)據(jù)湖在事務處理、流計算、BI 分析上的不足。從功能上看,iceberg和delta幾乎一樣,但是iceberg似乎更加符合一個開源項目的氣質(zhì)。早期這個項目更多是為了應對 Netflix 對大體量數(shù)據(jù)分析的需求。hudi 開源和孵化的時間線與 iceberg 比較相近,核心功能是在 hadoop 上支持 upsert 和 incremental process。hudi 在三個項目中最早提供 stream upsert 能力 ,如果不做二次開發(fā),hudi 是開箱即用的數(shù)據(jù)湖 upsert 方案,并且 hudi 社區(qū)對開發(fā)者非常開放。
企業(yè)需要怎樣的數(shù)據(jù)湖?
面對眾多的數(shù)據(jù)湖,企業(yè)究竟需要怎樣的產(chǎn)品?這個問題可以從Delta的身上看出端倪。“ Delta用一套數(shù)據(jù)湖存儲,將批計算和流計算融合,將傳統(tǒng)數(shù)倉在數(shù)據(jù)分析上的優(yōu)勢,數(shù)據(jù)湖在 AI,數(shù)據(jù)科學上的優(yōu)勢結(jié)合起來,基于 Lakehouse 這個存儲底座,實現(xiàn)數(shù)據(jù)業(yè)務的全場景覆蓋。總結(jié)起來就是,Delta 給 Databricks 帶來的價值是用一套基礎數(shù)據(jù)湖軟件,實現(xiàn)全場景覆蓋。”網(wǎng)易數(shù)帆大數(shù)據(jù)實時計算技術專家、湖倉一體項目負責人馬進表示。
另一方面,國內(nèi)實時計算基本在用 Flink,而絕大多數(shù)企業(yè)不會綁定一個計算引擎,所以引擎平權對數(shù)據(jù)湖極為重要。不同引擎的應用可以吸收各家優(yōu)勢,但會帶來產(chǎn)品割裂的問題,產(chǎn)品割裂在大數(shù)據(jù)方法論的迭代中被更加放大,比如在數(shù)據(jù)中臺中,指標系統(tǒng),數(shù)據(jù)模型,數(shù)據(jù)質(zhì)量,數(shù)據(jù)資產(chǎn)這一套中臺模塊基本是圍繞離線場景打造,而在強調(diào) CI/CD 的 Dataops 中,流計算的需求和場景因為存儲和計算的不統(tǒng)一更加難以被納入考量。
應對之策就是實時數(shù)倉--流計算對應的場景和需求在大數(shù)據(jù)平臺的方法論迭代中被邊緣化,用戶無法在實時場景下體驗到數(shù)據(jù)安全,數(shù)據(jù)質(zhì)量,數(shù)據(jù)治理帶來的收益,很多既需要實時也需要離線的場景下,用戶需要維護流表和批表兩套模型,兩套代碼,并且時刻警惕語義和模型的二義性。
立足于開源數(shù)據(jù)湖 Format之上,打造Arctic
過去兩年,網(wǎng)易數(shù)帆的團隊開發(fā)了 Arctic項目,并且在今年7月底開源。“我們的工作不是另起爐灶,做一個跟 delta/iceberg 競爭的產(chǎn)品,這不符合企業(yè)的需求,Arctic 是立足于開源數(shù)據(jù)湖 Format之上的服務,基于 iceberg的產(chǎn)品。”馬進表示。“我們的目標要將 Dataops 的邊界拓展到流計算,所以 Arctic 會為用戶提供更加優(yōu)化的流的能力,包括 stream upsert、生產(chǎn)可用的讀時合并技術、提供分鐘級別新鮮度的數(shù)據(jù)分析能力。”簡而言之,Arctic 是適配多引擎的流式湖倉服務。
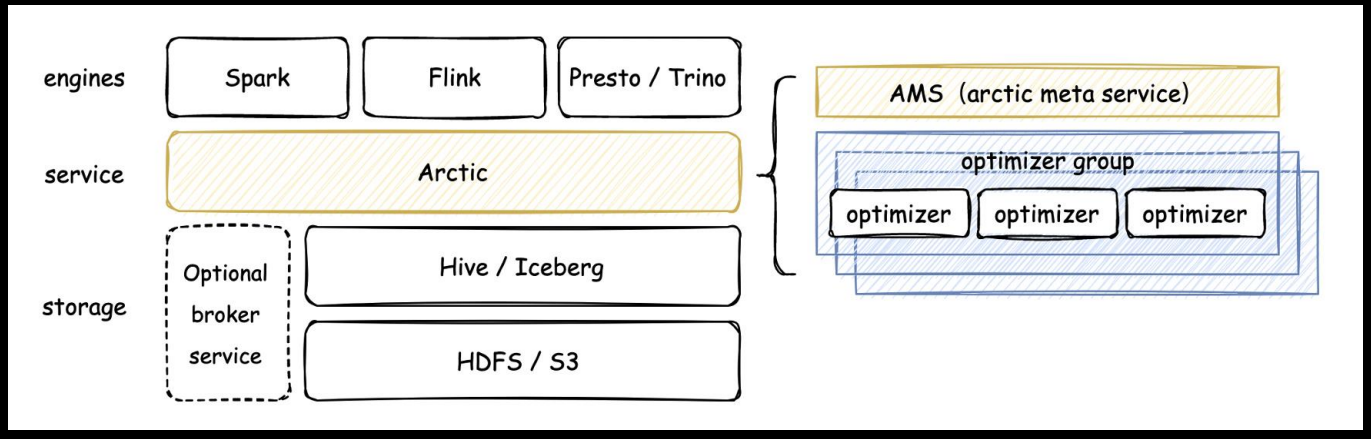
Arctic作為服務可以適配不同的數(shù)據(jù)湖格式,企業(yè)無需擔心數(shù)據(jù)湖技術的選型問題,持續(xù)優(yōu)化數(shù)據(jù)分析能力,也讓數(shù)據(jù)流管理變得簡單;在能力上,Arctic不僅提供了基于主鍵高效地流式更新,數(shù)據(jù)自動分桶、結(jié)構自優(yōu)化的特性,還支持將數(shù)據(jù)湖和消息隊列封裝成統(tǒng)一的表,實現(xiàn)比傳統(tǒng)方案更低延遲的流批一體,從根本上優(yōu)雅地解決性能問題。另一方面,Arctic還提供流式數(shù)倉標準化的度量,dashboard 和相關管理工具,并為流批并發(fā)寫入提供事務性保障;在架構上,Arctic設計簡潔,只有AMS、optimizer和dashboard三個組件,在數(shù)據(jù)湖和計算引擎之間提供湖倉一體落地所需的能力,但卻支持Spark和Flink讀寫、Trino查詢,百分百兼容Iceberg/Hive的表格式和語法,這使得它的使用成本很低。
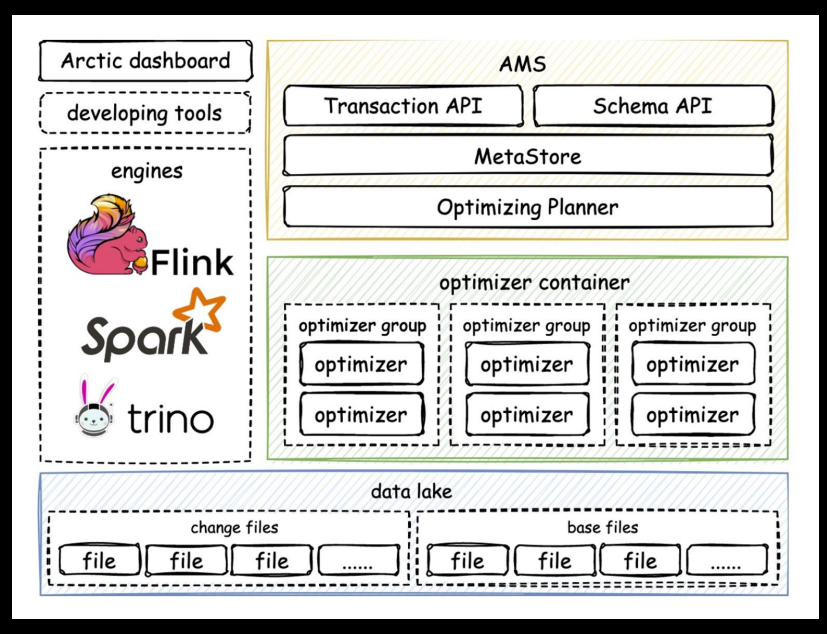
“當我們將數(shù)據(jù)湖的能力拓展到實時場景,成本、性能和數(shù)據(jù)新鮮度三者的關系將呈現(xiàn)更為復雜和微妙的狀態(tài),Arctic的服務和管理功能,將為用戶和上層平臺理清這個三角關系。”馬進強調(diào)。
打造成熟的湖倉管理系統(tǒng)
馬進認為,流式湖倉未來最終是要在產(chǎn)品上體現(xiàn),和整個產(chǎn)品上層的方法論結(jié)合在一起。如果只是把流式湖倉當成另外一種分析平臺,或者是對標像Kudu、Doris對標的方案,意義不大,或收益有限,其最終收益應該結(jié)合數(shù)據(jù)建設方法論來看。
對于Arctic的發(fā)展方向,網(wǎng)易數(shù)帆團隊希望其向一個成熟的湖倉管理系統(tǒng)過渡。就像在數(shù)據(jù)庫領域的Oracle、MySQL、DB2等系統(tǒng),它們不光是數(shù)據(jù)庫,還是一套管理系統(tǒng),包括information schema、各種各樣標準化管理和度量的工具,共同為上層工具和用戶服務。比如上層要做數(shù)據(jù)庫的工具,就會用標準化的命令或者SQL,與數(shù)據(jù)庫交互就可以了。“我認為這是一個成熟的管理系統(tǒng)需要具備的能力。”馬進表示。
總之,Arctic的未來一方面要補足底層的短板,包括性能和可靠性,以及持續(xù)優(yōu)化的能力。另一方面,是要提高它在管理上的標準化能力,比如table service能力,optimizing過程管理能力,進而形成一個成熟的管理系統(tǒng)。


























