面試官:請使用JS完成一個LRU緩存?

前言
LRU 緩存算法是一個非常經(jīng)典的算法,在很多面試中經(jīng)常問道,不僅僅包括前端面試。
1.什么是 LRU?
LRU 英文全稱是 Least Recently Used,英譯過來就是”最近最少使用“的意思。 它是頁面置換算法中的一種,我們先來看一段百度百科的解釋。
百度百科:
- LRU 是一種常用的頁面置換算法,選擇最近最久未使用的頁面予以淘汰。該算法賦予每個頁面一個訪問字段,用來記錄一個頁面自上次被訪問以來所經(jīng)歷的時間 t,當(dāng)須淘汰一個頁面時,選擇現(xiàn)有頁面中其 t 值最大的,即最近最少使用的頁面予以淘汰。
百度百科解釋的比較窄,它這里只使用了頁面來舉例,我們通俗點來說就是:假如我們最近訪問了很多個頁面,內(nèi)存把我們最近訪問的頁面都緩存了起來,但是隨著時間推移,我們還在不停的訪問新頁面,這個時候為了減少內(nèi)存占用,我們有必要刪除一些頁面,而刪除哪些頁面呢?我們可以通過訪問頁面的時間來決定,或者說是一個標(biāo)準(zhǔn):在最近時間內(nèi),最久未訪問的頁面把它刪掉。
百度百科的解釋只是單純的解釋算法,而我們這里可以結(jié)合我們的前端和實際應(yīng)用場景來給大家解釋一下。
通俗的解釋:
- 假如我們有一塊內(nèi)存,專門用來緩存我們最近發(fā)訪問的網(wǎng)頁,訪問一個新網(wǎng)頁,我們就會往內(nèi)存中添加一個網(wǎng)頁地址,隨著網(wǎng)頁的不斷增加,內(nèi)存存滿了,這個時候我們就需要考慮刪除一些網(wǎng)頁了。這個時候我們找到內(nèi)存中最早訪問的那個網(wǎng)頁地址,然后把它刪掉。
- 這一整個過程就可以稱之為 LRU 算法。
雖然上面的解釋比較好懂了,但是我們還有很多地方?jīng)]有考慮到,比如如下幾點:
- 當(dāng)我們訪問內(nèi)存中已經(jīng)存在了的網(wǎng)址,那么該網(wǎng)址是否需要更新在內(nèi)存中的存儲順序。
- 當(dāng)我們內(nèi)存中還沒有數(shù)據(jù)的時候,是否需要執(zhí)行刪除操作。
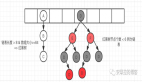
最后我們在上一張圖,大家應(yīng)該就更容易理解了,如下圖:
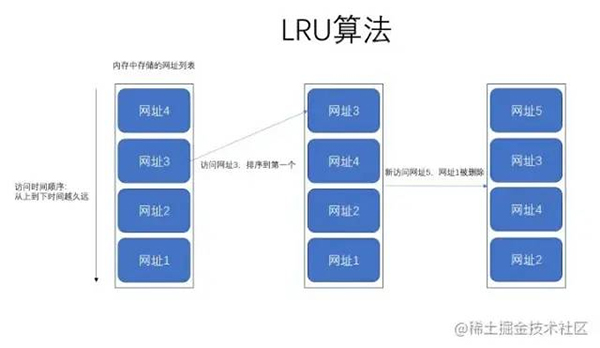
上圖就很好的解釋了 LRU 算法在干嘛了,其實非常簡單,無非就是我們往內(nèi)存里面添加或者刪除元素的時候,遵循最近最少使用原則。
2.使用場景
LRU 算法使用的場景非常多,這里簡單舉幾個例子即可:
- 我們操作系統(tǒng)底層的內(nèi)存管理,其中就包括有 LRU 算法
- 我們常見的緩存服務(wù),比如 redis 等等
- 比如瀏覽器的最近瀏覽記錄存儲,如下圖:
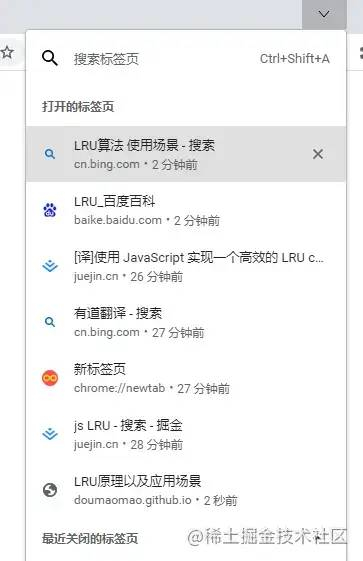
總之 LRU 算法的運用場景還是蠻多的,所以我們很有必要掌握它。
3.梳理實現(xiàn) LRU 思路
我們學(xué)習(xí)了 LRU 算法的基本概念和使用場景之后,那么我們就應(yīng)該考慮如何實現(xiàn)它了。要想實現(xiàn)一個算法,我們很有必要梳理一下思路,這樣才能讓我們更好更快的編寫出代碼。
首先我們來梳理一下 LRU 算法的特點。
特點分析:
- 我們需要一塊有限的存儲空間,因為無限的化就沒必要使用 LRU 算發(fā)刪除數(shù)據(jù)了。
- 我們這塊存儲空間里面存儲的數(shù)據(jù)需要是有序的,因為我們必須要順序來刪除數(shù)據(jù),所以可以考慮使用 Array、Map 數(shù)據(jù)結(jié)構(gòu)來存儲,不能使用 Object,因為它是無序的。
- 我們能夠刪除或者添加以及獲取到這塊存儲空間中的指定數(shù)據(jù)。
- 存儲空間存滿之后,在添加數(shù)據(jù)時,會自動刪除時間最久遠的那條數(shù)據(jù)。
實現(xiàn)需求:
- 實現(xiàn)一個 LRUCache 類型,用來充當(dāng)存儲空間
- 采用 Map 數(shù)據(jù)結(jié)構(gòu)存儲數(shù)據(jù),因為它的存取時間復(fù)雜度為 O(1),數(shù)組為 O(n)
- 實現(xiàn) get 和 set 方法,用來獲取和添加數(shù)據(jù)
- 我們的存儲空間有長度限制,所以無需提供刪除方法,存儲滿之后,自動刪除最久遠的那條數(shù)據(jù)
- 當(dāng)使用 get 獲取數(shù)據(jù)后,該條數(shù)據(jù)需要更新到最前面
現(xiàn)在我們已經(jīng)把 LRU 算法的特點以及實現(xiàn)思路列了出來,那么接下來就然我們一起去實現(xiàn)它吧!
4.具體實現(xiàn)
首先我們定義一個 LRUCache 類,封裝所有的方法和變量。
代碼如下:
<script>
class LRUCache {
constructor(lenght) {
this.length = lenght; // 存儲長度
this.data = new Map(); // 存儲數(shù)據(jù)
}
// 存儲數(shù)據(jù),通過鍵值對的方式
set(key, value) { }
// 獲取數(shù)據(jù)
get(key) { }
}
const lruCache = new LRUCache(5);
</script>
上段代碼只是我們最簡單的一個架子,我們需要去實現(xiàn)具體的 get 和 set 方法。
代碼如下:
<script>
class LRUCache {
constructor(lenght) {
this.length = lenght; // 存儲長度
this.data = new Map(); // 存儲數(shù)據(jù)
}
// 存儲數(shù)據(jù),通過鍵值對的方式
set(key, value) {
const data = this.data;
if (data.has(key)) {
data.delete(key)
}
data.set(key, value);
// 如果超出了容量,則需要刪除最久的數(shù)據(jù)
if (data.size > this.length) {
const delKey = data.keys().next().value;
data.delete(delKey);
}
}
// 獲取數(shù)據(jù)
get(key) {
const data = this.data;
// 未找到
if (!data.has(key)) {
return null;
}
const value = data.get(key); // 獲取元素
data.delete(key); // 刪除元素
data.set(key, value); // 重新插入元素
}
}
const lruCache = new LRUCache(5);
</script>
上段代碼中實現(xiàn)實現(xiàn)了 get 和 set 方法,下面說一下這兩個方法的實現(xiàn)思路:
- set 方法:往 map 里面添加新數(shù)據(jù),如果添加的數(shù)據(jù)存在了,則先刪除該條數(shù)據(jù),然后再添加。如果添加數(shù)據(jù)后超長了,則需要刪除最久遠的一條數(shù)據(jù)。data.keys().next().value 便是獲取最后一條數(shù)據(jù)的意思。
- get 方法:首先從 map 對象中拿出該條數(shù)據(jù),然后刪除該條數(shù)據(jù),最后再重新插入該條數(shù)據(jù),確保將該條數(shù)據(jù)移動到最前面。
接下來我們使用一些測試用例來試試行不行。
存儲數(shù)據(jù) set:
lruCache.set('name', '小豬課堂');
lruCache.set('age', 22);
lruCache.set('sex', '男');
lruCache.set('height', 176);
lruCache.set('weight', '100');
console.log(lruCache);
輸出結(jié)果:

繼續(xù)插入數(shù)據(jù),此時會超長,代碼如下:
lruCache.set('grade', '10000');
console.log(lruCache);
輸出結(jié)果:

此時我們發(fā)現(xiàn)存儲時間最久的 name 已經(jīng)被移除了,新插入的數(shù)據(jù)變?yōu)榱俗钋懊娴囊粋€。
我們使用 get 獲取數(shù)據(jù),代碼如下:
lruCache.get('sex');
console.log(lruCache);
輸出結(jié)果:

我們發(fā)現(xiàn)此時 sex 字段已經(jīng)跑到最前面去了。
總結(jié)
LRU 算法其實邏輯非常的簡單,明白了原理之后實現(xiàn)起來非常的簡單。最主要的是我們需要使用什么數(shù)據(jù)結(jié)構(gòu)來存儲數(shù)據(jù),因為 map 的存取非常快,所以我們采用了它,當(dāng)然數(shù)組其實也可以實現(xiàn)的。還有一些小伙伴使用鏈表來實現(xiàn) LRU,這當(dāng)然也是可以的。