













用多模態(tài)世界模型預(yù)測(cè)未來!UC伯克利全新AI智能體,精確理解人類語(yǔ)言,刷新SOTA
現(xiàn)在,基于強(qiáng)化學(xué)習(xí)的智能體已經(jīng)可以輕松地執(zhí)行諸如「撿起藍(lán)色積木」這類的指令。
但人類大部分時(shí)間的語(yǔ)言表達(dá),卻遠(yuǎn)遠(yuǎn)超出了指令的范圍。比如:「我們好像沒有牛奶了」......
而智能體想要學(xué)習(xí)這類語(yǔ)言在世界中的含義,是非常困難的。
對(duì)此,來自UC伯克利的研究團(tuán)隊(duì)認(rèn)為,我們實(shí)際上可以利用這些語(yǔ)言,來幫助智能體更好地對(duì)未來進(jìn)行預(yù)測(cè)。

論文地址:https://arxiv.org/pdf/2308.01399.pdf
具體來說,研究人員提出了一種全新的智能體——Dynalang。
與僅用語(yǔ)言預(yù)測(cè)動(dòng)作的傳統(tǒng)智能體不同,Dynalang通過使用過去的語(yǔ)言來預(yù)測(cè)未來的語(yǔ)言、視頻和獎(jiǎng)勵(lì),從而獲得豐富的語(yǔ)言理解。
除了在環(huán)境中的在線交互中學(xué)習(xí)外,Dynalang還可以在沒有動(dòng)作或獎(jiǎng)勵(lì)的情況下在文本、視頻或兩者的數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練。
也就是說,新的智能體這時(shí)再聽到「我們沒有牛奶了」,就能get到這句話意思是「冰箱里的牛奶喝完了」。
工作原理
使用語(yǔ)言來理解世界自然而然地適合于世界建模范式。
Dynalang以基于模型的RL智能體DreamerV3為基礎(chǔ),并可利用其在環(huán)境中動(dòng)作時(shí)所收集到的經(jīng)驗(yàn)數(shù)據(jù),不斷地進(jìn)行學(xué)習(xí)。
左:世界模型在每個(gè)時(shí)間步將文本和圖像壓縮為潛在表征。在這個(gè)表征中,模型被訓(xùn)練以重構(gòu)原始觀察結(jié)果,預(yù)測(cè)獎(jiǎng)勵(lì),并預(yù)測(cè)下一個(gè)時(shí)間步的表征。直觀地說,世界模型學(xué)會(huì)了在給定文本中所讀內(nèi)容的情況下,應(yīng)該期望在世界中看到什么。
右:Dynalang通過在壓縮的世界模型表征基礎(chǔ)上訓(xùn)練策略網(wǎng)絡(luò)來選擇動(dòng)作。它在世界模型的想象中反復(fù)進(jìn)行訓(xùn)練,從而學(xué)會(huì)采取最大化預(yù)測(cè)獎(jiǎng)勵(lì)的動(dòng)作。

與之前一次處理一個(gè)句子或段落的多模態(tài)模型不同,Dynalang將視頻和文本作為一個(gè)統(tǒng)一的序列進(jìn)行建模,一次處理一個(gè)圖像幀和一個(gè)文本token。
直觀地說,這更像是人類在現(xiàn)實(shí)世界中接收輸入的方式。
將所有內(nèi)容都建模為一個(gè)序列,就可以像語(yǔ)言模型一樣在文本數(shù)據(jù)上進(jìn)行預(yù)訓(xùn)練,從而提高強(qiáng)化學(xué)習(xí)的性能。
語(yǔ)言提示
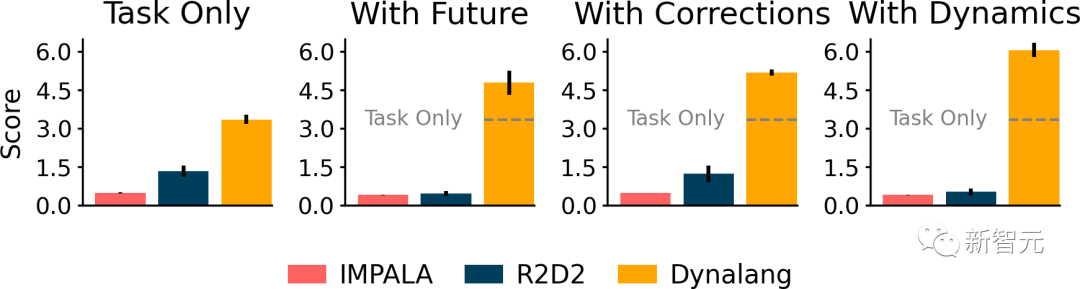
為了評(píng)估智能體在環(huán)境中的表現(xiàn),研究人員引入了HomeGrid。其中,智能體除了任務(wù)指令外,還會(huì)收到語(yǔ)言提示。
HomeGrid中的提示,不僅模擬了智能體可能從人類那里學(xué)到的知識(shí)或從文本中讀到的信息,而且還提供了有用但不是解決任務(wù)所必需的信息:
- 「未來觀察」:描述智能體在未來可能觀察到的情況,例如「盤子在廚房里」。
- 「糾正」:根據(jù)智能體正在執(zhí)行的任務(wù)的提供交互式反饋,例如「轉(zhuǎn)過身去」。
- 「動(dòng)態(tài)」:描述環(huán)境的動(dòng)態(tài),例如「踩踏板打開堆肥箱」。

雖然智能體并未接受過明確的指導(dǎo)來分辨觀察結(jié)果和文本的對(duì)應(yīng)關(guān)系。但Dynalang仍能通過未來的預(yù)測(cè)目標(biāo),學(xué)會(huì)將各種類型的語(yǔ)言與環(huán)境聯(lián)系起來。
結(jié)果顯示,Dynalang要明顯優(yōu)于以語(yǔ)言為條件的IMPALA和R2D2。
后者不僅在使用不同類型的語(yǔ)言時(shí)非常吃力,而且在使用指令以外的語(yǔ)言時(shí)表現(xiàn)得更差。
游戲評(píng)估
在Messenger游戲環(huán)境中,研究人員測(cè)試了智能體是如何從較長(zhǎng)且更復(fù)雜的文本中學(xué)習(xí)的,這需要在文本和視覺觀察之間進(jìn)行多跳推理。
智能體必須對(duì)描述每個(gè)情節(jié)動(dòng)態(tài)的文本說明進(jìn)行推理,并將其與環(huán)境中的實(shí)體觀察結(jié)合起來,以確定從哪些實(shí)體獲取消息和避開哪些實(shí)體。
結(jié)果顯示,Dynalang的表現(xiàn)要明顯優(yōu)于IMPALA和R2D2,以及使用專門架構(gòu)對(duì)文本和觀察結(jié)果進(jìn)行推理任務(wù)優(yōu)化的EMMA基準(zhǔn),尤其是在最困難的第3階段。


指令跟隨
Habitat的測(cè)試結(jié)果表明,Dynalang能夠處理逼真的視覺觀察并執(zhí)行指令。
也就是,智能體需要按照自然語(yǔ)言的指令,導(dǎo)航到家中的目標(biāo)位置。
在Dynalang中,指令跟隨可以通過將其視為未來獎(jiǎng)勵(lì)預(yù)測(cè),來在相同的預(yù)測(cè)框架中統(tǒng)一處理。


語(yǔ)言生成
就像語(yǔ)言會(huì)影響智能體對(duì)所見事物的預(yù)測(cè)一樣,智能體觀察到的事物也會(huì)影響它期望聽到的語(yǔ)言(例如,關(guān)于所見事物的真實(shí)陳述)。
通過在LangRoom中將語(yǔ)言輸出到動(dòng)作空間中,Dynalang可以生成與環(huán)境相關(guān)聯(lián)的語(yǔ)言,從而執(zhí)行具體的問題回答。


文本預(yù)訓(xùn)練
由于使用語(yǔ)言建立世界模型與使用世界模型學(xué)習(xí)動(dòng)作是分開的,因此Dynalang可以在沒有動(dòng)作或獎(jiǎng)勵(lì)標(biāo)簽的情況下使用離線數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練。
這種能力使Dynalang能夠從大規(guī)模的離線數(shù)據(jù)集中受益,所有這些數(shù)據(jù)集都在單一模型架構(gòu)內(nèi)。
研究人員使用純文本數(shù)據(jù)對(duì)Dynalang進(jìn)行預(yù)訓(xùn)練,并從頭開始學(xué)習(xí)token嵌入。
模型在通用文本數(shù)據(jù)(TinyStories,200萬個(gè)短故事)上進(jìn)行預(yù)訓(xùn)練之后,可以提高M(jìn)essenger下游RL任務(wù)的表現(xiàn),甚至超過了使用預(yù)訓(xùn)練的T5嵌入。

盡管這項(xiàng)工作的重點(diǎn)是讓智能體能夠理解語(yǔ)言并采取行動(dòng),但其實(shí)也可以像純文本語(yǔ)言模型一樣生成文本。
研究人員在潛空間中對(duì)預(yù)訓(xùn)練的TinyStories模型進(jìn)行了抽樣推演,并在每個(gè)時(shí)間步驟從表征中解碼出token觀察。
結(jié)果顯示,模型生成的結(jié)果具有令人驚訝的一致性,不過在質(zhì)量上仍然低于SOTA的語(yǔ)言模型。
不過由此也可以看出,將語(yǔ)言生成和行動(dòng)統(tǒng)一到單一的智能體架構(gòu)中,是一個(gè)很有趣的研究方向。

作者介紹
Jessy Lin

論文一作Jessy Lin,是加州大學(xué)伯克利分校人工智能研究院(Berkeley AI Research)的三年級(jí)博士生,由Anca Dragan和Dan Klein指導(dǎo)。
她的研究方向是構(gòu)建能與人類合作和互動(dòng)并以語(yǔ)言為媒介的智能體。此外,她還對(duì)對(duì)話以及語(yǔ)言+強(qiáng)化學(xué)習(xí)非常感興趣。目前,她的研究得到了蘋果人工智能獎(jiǎng)學(xué)金的支持。
她在麻省理工學(xué)院獲得了計(jì)算機(jī)科學(xué)和哲學(xué)雙學(xué)位。在那里,她與計(jì)算認(rèn)知科學(xué)小組合作,在Kelsey Allen和Josh Tenenbaum的指導(dǎo)下進(jìn)行人類啟發(fā)式人工智能研究,同時(shí)作為labsix的創(chuàng)始成員從事機(jī)器學(xué)習(xí)安全研究。
此外,她還曾在Lilt從事人機(jī)協(xié)作機(jī)器翻譯/專家翻譯的Copilot研究和產(chǎn)品開發(fā)。






























