













蘋果創新大模型壓縮技術,大模型有機會塞進手機里了
大型語言模型(LLM),尤其是生成式預訓練 Transformer(GPT)模型在許多復雜的語言任務上表現出了出色的性能。這一突破使人們希望在移動設備上本地運行這些 LLM,以保護用戶隱私。可是,即使是小型 LLM 也太大,無法在這些設備上運行。
舉例來說,小型 LLaMA 有 7B 參數,其 FP16 版本大小為 14GB,而移動設備只有 18GB 的 DRAM。因此,通過訓練時間優化(如稀疏化、量化或權重聚類)來壓縮 LLM 是設備上 LLM 部署的關鍵步驟。然而,由于模型大小和計算資源開銷,LLM 的訓練時間優化非常昂貴。權重聚類 SOTA 算法之一 DKM,由于需要分析所有權重和所有可能的聚類選項之間的相互作用,其訓練時間可變權重聚類對計算資源的需求過高。
因此,許多現有的 LLM 壓縮技術,如 GTPQ 和 AWQ,都依賴于訓練后的優化。在本文中,研究者提出了內存優化技術,以實現訓練時間權重聚類及其在 DKM 中的應用,也就是 eDKM。
本文使用的技術包括跨設備張量編排和權重矩陣唯一化及分片。在使用 eDKM 對 LLaMA 7B 模型進行微調并將其壓縮為每個權重因子占位 3bit 時,研究者實現了解碼器堆棧約 130 倍的內存占用減少,優于現有的 3bit 壓縮技術。
提高 DKM 的內存效率
如圖 1 所示,剪枝、量化和歸一化都是較為流行的權重優化技術,這些方法將原始權重 W,優化后得到權重  ,以優化推理延遲、精度或模型大小。在這些技術中,本文研究者主要關注的是權重聚類,特別權重聚類算法 DKM 。
,以優化推理延遲、精度或模型大小。在這些技術中,本文研究者主要關注的是權重聚類,特別權重聚類算法 DKM 。
權重聚類是一種非線性權重離散化,權重矩陣被壓縮成一個查找表和查找表的低精度索引列表,現代推理加速器可以處理這些索引。DKM 通過分析權重(以 W 表示)和中心點(以 C 表示)之間的相互作用來執行可微權重聚類,并在壓縮比和準確性之間做出權衡。
因此,使用 DKM 進行 LLM 壓縮會產生高質量的結果。然而,DKM 計算過程中產生的注意力圖較大,前向 / 后向傳遞的內存復雜度為 O (|W||C|)(即圖 1 中的矩陣),這對 LLM 壓縮來說尤其困難。舉例來說,一個 LLaMA 7B 模型僅計算 4 bit 權重聚類的注意力圖就需要至少 224GB 的內存。

圖 1:權重優化系統概覽。DKM 中,系統內部創建了一個可微分權重聚類的注意力圖譜。
因此,研究者需要利用 CPU 內存來處理如此大的內存需求,也就是先將信息存儲至到 CPU 內存,然后在需要時再復制回 GPU。然而,這將在 GPU 和 CPU 之間產生大量的流量(會因此減慢訓練速度),并需要巨大的 CPU 內存容量。這意味著減少 CPU 和 GPU 之間的事務數量并最大限度地降低每次事務的流量至關重要。為了應對這些難題,研究者在 PyTorch 中引入了兩種新型內存優化技術。
- 跨設備的張量編排:跟蹤跨設備復制的張量,避免冗余復制,從而減少內存占用,加快訓練速度。
- 權重唯一化及分片處理:利用 16 bit 權重僅有 216 個唯一值這一事實來減少注意力圖(如圖 1 所示)的表示,并進一步將其分割給多個學習模型。
跨設備張量編排
PyTorch 用數據存儲來表示張量,數據存儲鏈接到實際的數據布局和元數據,元數據用于保存張量的形狀、類型等。這種張量架構讓 PyTorch 可以盡可能地重復使用數據存儲,并有效減少內存占用。然而,當一個張量移動到另一個設備上時(如從 GPU 到 CPU),數據存儲就不能重復使用,需要創建一個新的張量。
表 1 舉例說明了張量在 PyTorch 設備間移動時的內存占用情況。在第 0 行分配的張量 x0 在 GPU 上消耗了 4MB。當其視圖在第 1 行中改變時,由于底層數據存儲可以重復使用(即 x0 和 x1 實際上是相同的),因此不需要額外的 GPU 內存。然而,當 x0 和 x1 如第 2 行和第 3 行那樣移動到 CPU 時,盡管 y0 和 y1 可以在 CPU 上共享相同的數據存儲,但 CPU 內存消耗卻變成了 8MB,這導致 CPU 內存冗余,并增加了 GPU 到 CPU 的流量。

表 1:LLM 微調可能需要使用 CPU 內存來卸載 GPU 上的內存占用。缺乏跨設備的張量管理會導致跨設備的冗余拷貝(尤其是當計算圖很復雜時),這對于 LLM 的訓練時間優化尤為不利。例如,雖然 x0 和 x1 是相同的張量,只是視圖不同,但當復制到 CPU 時,生成的張量 y0 和 y1 并不共享數據存儲,而在 GPU 上 x0 和 x1 共享數據存儲。
為了解決這種低效問題,研究者在圖 2 (b) 中放置了一個編排層,其中黑色代表實際數據存儲和元數據,灰色僅表示元數據。圖 2 (a) 展示了表 1 中的示例,其中 x1 與 x0 共享數據布局,但 y0 和 y1 在 CPU 上擁有重復的數據存儲。如圖 2 (b) 所示,通過插入編排層,研究者避免了這種冗余,并減少了 GPU 傳至 CPU 的流量。研究者使用 PyTorch 中的 save-tensor-hook 來實現這樣的交換方案,檢查相同的數據存儲是否已經被復制。
然而,使用這樣的方案來檢查目標設備上是否存在相同的張量是很昂貴的。在圖 2 (b) 的示例中,研究者并沒有將 x1 復制到 CPU,而是簡單地返回了 y0 的引用以及 x1 和 y0 之間的視圖操作。

圖 2:將跨設備張量編排應用于表 1 中的情況時,可以避免 CPU 端的重復,從而節省內存及流量。
瀏覽計算圖會增加額外的計算周期,節省不必要的復制可以彌補此類開銷。研究者發現,4 hop 內的搜索足以檢測原始 DKM 實現中計算圖中的所有合格的案例。
權重唯一化及分片處理
在大多數 LLM 的訓練中,權重普遍使用 16 bit 存儲(如 BF16 或 FP16),這意味著雖然 LLM 中有數十億個參數,但由于位寬的原因,只有 216 個唯一系數。這就為大幅壓縮權重和中心點之間的注意力圖提供了機會,如圖 3 所示。
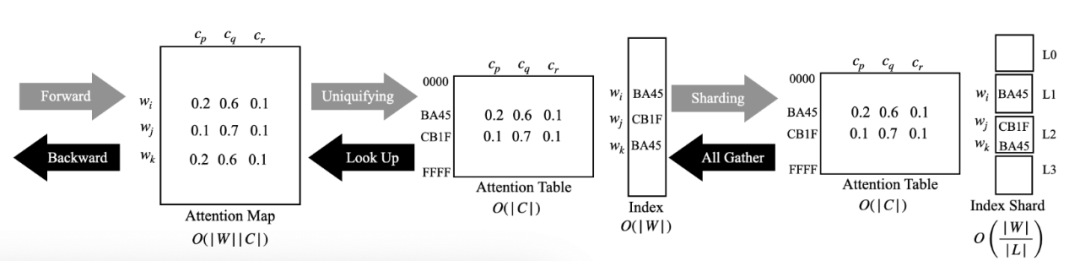
圖 3:權重唯一化及分片
實驗結果
LLM 準確率
本文將 eDKM 與其他基于量化的壓縮方案進行了比較,包括:RTN、SmoothQuant、GPTQ 、AWQ 和 LLM-QAT 。對于 eDKM,研究者還對嵌入層進行了 8 bit 壓縮。最終得出如下結論:
- eDKM 使 3 bit 壓縮 LLaMA 7B 模型優于所有其他 3 bit 壓縮方案。
- eDKM 在 3 bit 和 4 bit 配置的 ARC-e 基準測試中具有最佳精度。
- 在使用 4 bit 壓縮模型的 PIQA 和 MMLU 基準測試中,eDKM 的性能極具競爭力。

消融實驗
在消融實驗中,研究者以 LLaMA 7B 解碼器棧中的一個注意層為例,測量了內存占用與 3 bit 壓縮的前向后向速度之間的權衡。單是跨設備張量編排就減少了 2.9 倍的內存占用,運行時開銷很小,而分片和唯一化模塊則分別節省了 23.5 倍和 16.4 倍。當所有技術相結合時,eDKM 可節省約 130 倍。雖然這些步驟需要額外的計算和通信開銷,但由于 GPU 和 CPU 之間的流量大幅減少,因此運行時的開銷微不足道。
更多詳細內容,請參閱原文。





























