工作五年,沒用過分布式鎖,正常嗎?

大家好,我是哪吒。
公司想招聘一個5年開發(fā)經(jīng)驗的后端程序員,看了很多簡歷,發(fā)現(xiàn)一個共性問題,普遍都沒用過分布式鎖,這正常嗎?
下面是已經(jīng)入職的一位小伙伴的個人技能包,乍一看,還行,也沒用過分布式鎖。

午休的時候,和她聊了聊,她之前在一家對日的公司。
- 需求是產(chǎn)品談好的。
- 系統(tǒng)設(shè)計、詳細(xì)設(shè)計是PM做的。
- 接口文檔、數(shù)據(jù)庫設(shè)計書是日本公司提供的。
- 最夸張的是,就連按鈕的顏色,文檔中都有標(biāo)注...
- 她需要做的,就只是照著接口文檔去編碼、測試就ok了。
有的面試者工作了5年,做的都是自家產(chǎn)品,項目只有兩個,翻來覆去的改BUG,加需求,做運維。技術(shù)棧很老,還是SSM那一套,最近在改造,終于用上了SpringBoot... 微服務(wù)、消息中間件、分布式鎖根本沒用過...
還有的面試者,在XX大廠工作,中間做了一年C#,一年Go,一看簡歷很華麗,精通三國語言,其實不然,都處于入門階段,毫無競爭力可言。
一時興起,說多了,言歸正傳,總結(jié)一篇分布式鎖的文章,豐富個人簡歷,提高面試level,給自己增加一點談資,秒變面試小達人,BAT不是夢。
一、分布式鎖的重要性與挑戰(zhàn)
1、分布式系統(tǒng)中的并發(fā)問題
在現(xiàn)代分布式系統(tǒng)中,由于多個節(jié)點同時操作共享資源,常常會引發(fā)各種并發(fā)問題。這些問題包括競態(tài)條件、數(shù)據(jù)不一致、死鎖等,給系統(tǒng)的穩(wěn)定性和可靠性帶來了挑戰(zhàn)。讓我們深入探討在分布式系統(tǒng)中出現(xiàn)的一些并發(fā)問題:
競態(tài)條件
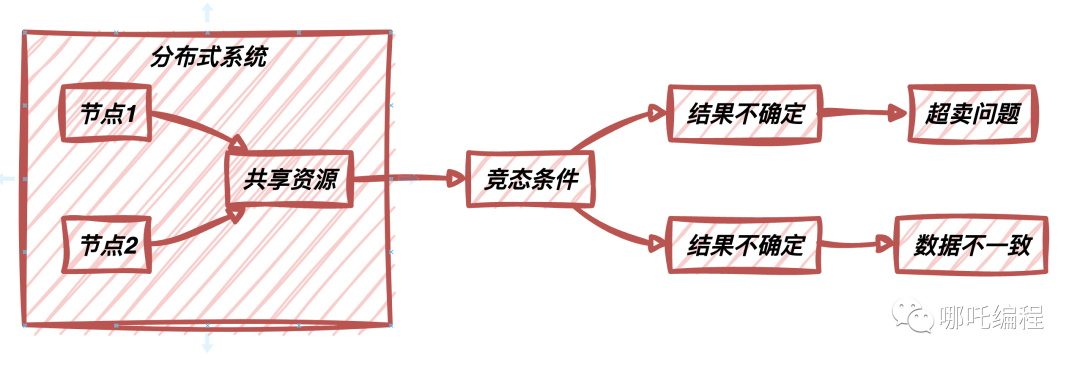
競態(tài)條件指的是多個進程或線程在執(zhí)行順序上產(chǎn)生了不確定性,從而導(dǎo)致程序的行為變得不可預(yù)測。在分布式系統(tǒng)中,多個節(jié)點同時訪問共享資源,如果沒有合適的同步機制,就可能引發(fā)競態(tài)條件。例如,在一個電商平臺中,多個用戶同時嘗試購買一個限量商品,如果沒有良好的同步機制,就可能導(dǎo)致超賣問題。
數(shù)據(jù)不一致
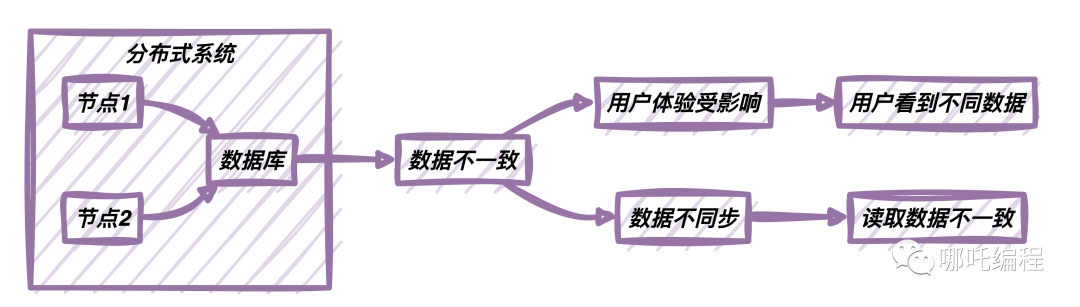
在分布式系統(tǒng)中,由于數(shù)據(jù)的拆分和復(fù)制,數(shù)據(jù)的一致性可能受到影響。多個節(jié)點同時對同一個數(shù)據(jù)進行修改,如果沒有適當(dāng)?shù)耐酱胧涂赡軐?dǎo)致數(shù)據(jù)不一致。例如,在一個社交網(wǎng)絡(luò)應(yīng)用中,用戶在不同的節(jié)點上修改了自己的個人資料,如果沒有同步機制,就可能導(dǎo)致數(shù)據(jù)不一致,影響用戶體驗。
死鎖
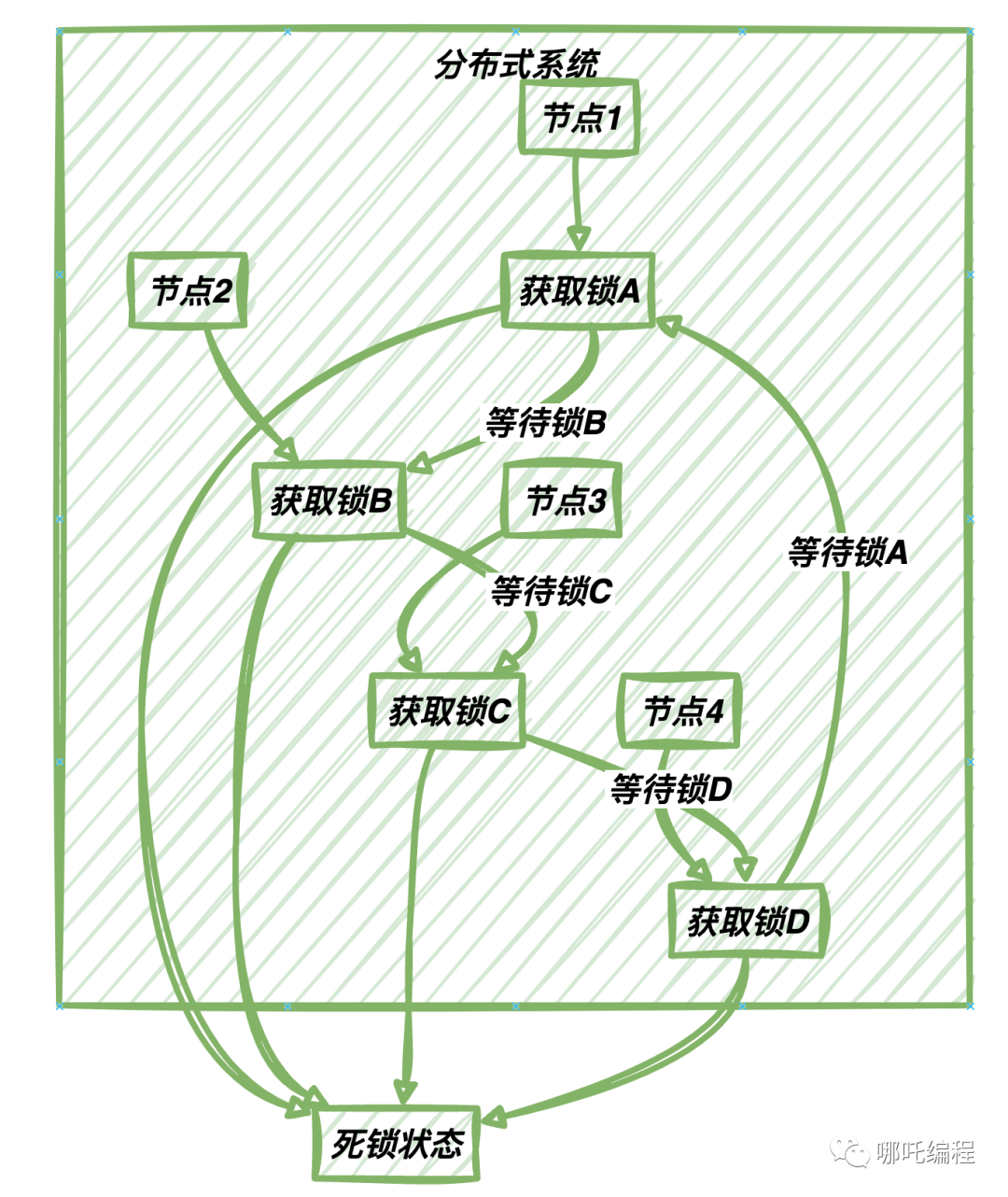
死鎖是指多個進程或線程因相互等待對方釋放資源而陷入無限等待的狀態(tài)。在分布式系統(tǒng)中,多個節(jié)點可能同時競爭資源,如果沒有良好的協(xié)調(diào)機制,就可能出現(xiàn)死鎖情況。例如,多個節(jié)點同時嘗試獲取一組分布式鎖,但由于順序不當(dāng),可能導(dǎo)致死鎖問題。。
二、分布式鎖的基本原理與實現(xiàn)方式
1、分布式鎖的基本概念
分布式鎖是分布式系統(tǒng)中的關(guān)鍵概念,用于解決多個節(jié)點同時訪問共享資源可能引發(fā)的并發(fā)問題。以下是分布式鎖的一些基本概念:
- 鎖(Lock):鎖是一種同步機制,用于確保在任意時刻只有一個節(jié)點(進程或線程)可以訪問共享資源。鎖可以防止競態(tài)條件和數(shù)據(jù)不一致問題。
- 共享資源(Shared Resource):共享資源是多個節(jié)點需要訪問或修改的數(shù)據(jù)、文件、服務(wù)等。在分布式系統(tǒng)中,多個節(jié)點可能同時嘗試訪問這些共享資源,從而引發(fā)問題。
- 鎖的狀態(tài):鎖通常有兩種狀態(tài),即鎖定狀態(tài)和解鎖狀態(tài)。在鎖定狀態(tài)下,只有持有鎖的節(jié)點可以訪問共享資源,其他節(jié)點被阻塞。在解鎖狀態(tài)下,任何節(jié)點都可以嘗試獲取鎖。
- 競態(tài)條件(Race Condition):競態(tài)條件指的是多個節(jié)點在執(zhí)行順序上產(chǎn)生了不確定性,導(dǎo)致程序的行為變得不可預(yù)測。在分布式系統(tǒng)中,競態(tài)條件可能導(dǎo)致多個節(jié)點同時訪問共享資源,破壞了系統(tǒng)的一致性。
- 數(shù)據(jù)不一致(Data Inconsistency):數(shù)據(jù)不一致是指多個節(jié)點對同一個數(shù)據(jù)進行修改,但由于缺乏同步機制,數(shù)據(jù)可能處于不一致的狀態(tài)。這可能導(dǎo)致應(yīng)用程序出現(xiàn)錯誤或異常行為。
- 死鎖(Deadlock):死鎖是多個節(jié)點因相互等待對方釋放資源而陷入無限等待的狀態(tài)。在分布式系統(tǒng)中,多個節(jié)點可能同時競爭資源,如果沒有良好的協(xié)調(diào)機制,就可能出現(xiàn)死鎖情況。
分布式鎖的基本目標(biāo)是解決這些問題,確保多個節(jié)點在訪問共享資源時能夠安全、有序地進行操作,從而保持?jǐn)?shù)據(jù)的一致性和系統(tǒng)的穩(wěn)定性。
2、基于數(shù)據(jù)庫的分布式鎖
原理與實現(xiàn)方式
一種常見的分布式鎖實現(xiàn)方式是基于數(shù)據(jù)庫。在這種方式下,每個節(jié)點在訪問共享資源之前,首先嘗試在數(shù)據(jù)庫中插入一條帶有唯一約束的記錄。如果插入成功,說明節(jié)點成功獲取了鎖;否則,說明鎖已經(jīng)被其他節(jié)點占用。
數(shù)據(jù)庫分布式鎖的原理比較簡單,但實現(xiàn)起來需要考慮一些問題。以下是一些關(guān)鍵點:
- 唯一約束(Unique Constraint):數(shù)據(jù)庫中的唯一約束確保了只有一個節(jié)點可以成功插入鎖記錄。這可以通過數(shù)據(jù)庫的表結(jié)構(gòu)來實現(xiàn),確保鎖記錄的鍵是唯一的。
- 超時時間(Timeout):為了避免節(jié)點在獲取鎖后崩潰導(dǎo)致鎖無法釋放,通常需要設(shè)置鎖的超時時間。如果節(jié)點在超時時間內(nèi)沒有完成操作,鎖將自動釋放,其他節(jié)點可以獲取鎖。
- 事務(wù)(Transaction):數(shù)據(jù)庫事務(wù)機制可以確保數(shù)據(jù)的一致性。在獲取鎖和釋放鎖的過程中,可以使用事務(wù)來包裝操作,確保操作是原子的。
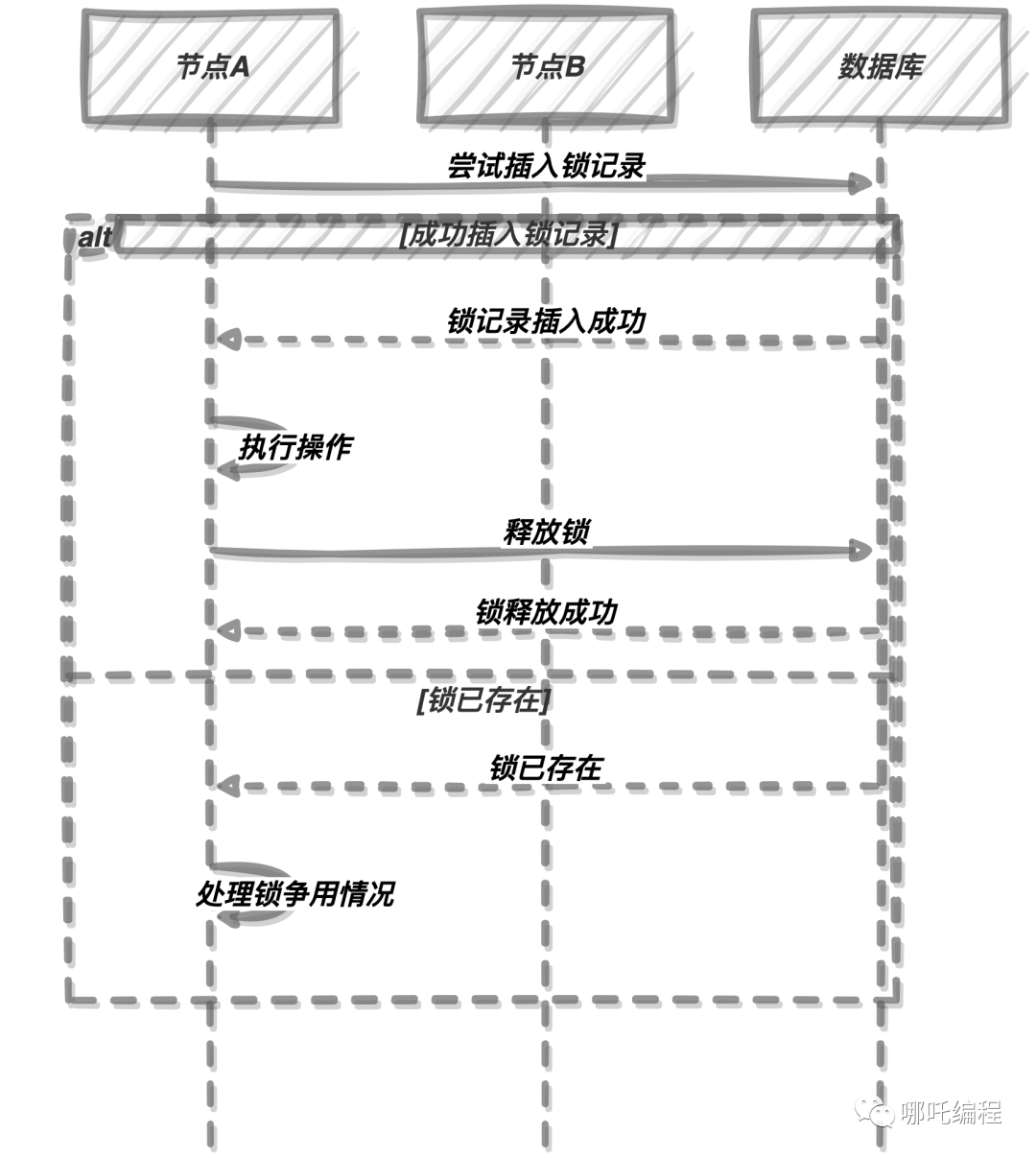
在圖中,節(jié)點A嘗試在數(shù)據(jù)庫中插入鎖記錄,如果插入成功,表示節(jié)點A獲取了鎖,可以執(zhí)行操作。操作完成后,節(jié)點A釋放了鎖。如果插入失敗,表示鎖已經(jīng)被其他節(jié)點占用,節(jié)點A需要處理鎖爭用的情況。
優(yōu)缺點
優(yōu)點 | 缺點 |
實現(xiàn)相對簡單,不需要引入額外的組件。 | 性能相對較差,數(shù)據(jù)庫的IO開銷較大。 |
可以使用數(shù)據(jù)庫的事務(wù)機制確保數(shù)據(jù)的一致性。 | 容易產(chǎn)生死鎖,需要謹(jǐn)慎設(shè)計。 |
不適用于高并發(fā)場景,可能成為系統(tǒng)的瓶頸。 |
這個表格對基于數(shù)據(jù)庫的分布式鎖的優(yōu)缺點進行了簡明的總結(jié)。
3、基于緩存的分布式鎖
原理與實現(xiàn)方式
另一種常見且更為高效的分布式鎖實現(xiàn)方式是基于緩存系統(tǒng),如Redis。在這種方式下,每個節(jié)點嘗試在緩存中設(shè)置一個帶有過期時間的鍵,如果設(shè)置成功,則表示獲取了鎖;否則,表示鎖已經(jīng)被其他節(jié)點占用。
基于緩存的分布式鎖通常使用原子操作來實現(xiàn),確保在并發(fā)環(huán)境下鎖的獲取是安全的。Redis提供了類似SETNX(SET if Not
eXists)的命令來實現(xiàn)這種原子性操作。此外,我們還可以為鎖設(shè)置一個過期時間,避免節(jié)點在獲取鎖后崩潰導(dǎo)致鎖一直無法釋放。
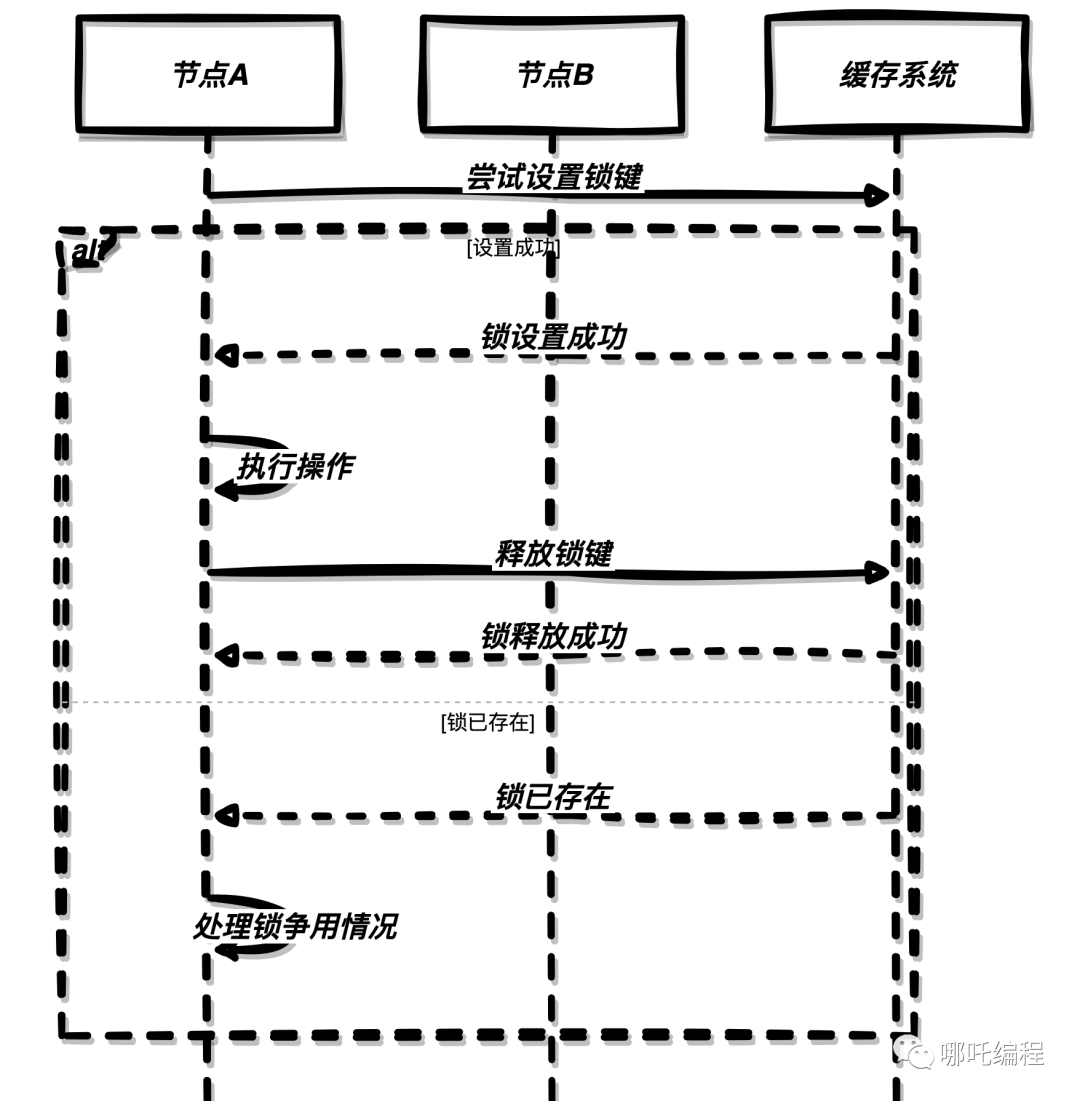
上圖中,節(jié)點A嘗試在緩存系統(tǒng)中設(shè)置一個帶有過期時間的鎖鍵,如果設(shè)置成功,表示節(jié)點A獲取了鎖,可以執(zhí)行操作。操作完成后,節(jié)點A釋放了鎖鍵。如果設(shè)置失敗,表示鎖已經(jīng)被其他節(jié)點占用,節(jié)點A需要處理鎖爭用的情況。
優(yōu)缺點
優(yōu)點 | 缺點 |
性能較高,緩存系統(tǒng)通常在內(nèi)存中操作,IO開銷較小。 | 可能存在緩存失效和節(jié)點崩潰等問題,需要額外處理。 |
可以使用緩存的原子操作確保獲取鎖的安全性。 | 需要依賴外部緩存系統(tǒng),引入了系統(tǒng)的復(fù)雜性。 |
適用于高并發(fā)場景,不易成為系統(tǒng)的瓶頸。 |
通過基于數(shù)據(jù)庫和基于緩存的分布式鎖實現(xiàn)方式,我們可以更好地理解分布式鎖的基本原理以及各自的優(yōu)缺點。根據(jù)實際應(yīng)用場景和性能要求,選擇合適的分布式鎖實現(xiàn)方式非常重要。
三、Redis分布式鎖的實現(xiàn)與使用
1、使用SETNX命令實現(xiàn)分布式鎖
在Redis中,可以使用SETNX(SET if Not eXists)命令來實現(xiàn)基本的分布式鎖。SETNX命令會嘗試在緩存中設(shè)置一個鍵值對,如果鍵不存在,則設(shè)置成功并返回1;如果鍵已存在,則設(shè)置失敗并返回0。通過這一機制,我們可以利用SETNX來創(chuàng)建分布式鎖。
以下是一個使用SETNX命令實現(xiàn)分布式鎖的Java代碼示例:
import redis.clients.jedis.Jedis;
public class DistributedLockExample {
private Jedis jedis;
public DistributedLockExample() {
jedis = new Jedis("localhost", 6379);
}
public boolean acquireLock(String lockKey, String requestId, int expireTime) {
Long result = jedis.setnx(lockKey, requestId);
if (result == 1) {
jedis.expire(lockKey, expireTime);
return true;
}
return false;
}
public void releaseLock(String lockKey, String requestId) {
String storedRequestId = jedis.get(lockKey);
if (storedRequestId != null && storedRequestId.equals(requestId)) {
jedis.del(lockKey);
}
}
public static void main(String[] args) {
DistributedLockExample lockExample = new DistributedLockExample();
String lockKey = "resource:lock";
String requestId = "request123";
int expireTime = 60; // 鎖的過期時間
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
try {
// 執(zhí)行需要加鎖的操作
System.out.println("Lock acquired. Performing critical section.");
Thread.sleep(1000); // 模擬操作耗時
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lockExample.releaseLock(lockKey, requestId);
System.out.println("Lock released.");
}
} else {
System.out.println("Failed to acquire lock.");
}
}
}2、設(shè)置超時與防止死鎖
在上述代碼中,我們通過使用expire命令為鎖設(shè)置了一個過期時間,以防止節(jié)點在獲取鎖后崩潰或異常退出,導(dǎo)致鎖一直無法釋放。設(shè)置合理的過期時間可以避免鎖長時間占用而導(dǎo)致的資源浪費。
3、鎖的可重入性與線程安全性
分布式鎖需要考慮的一個問題是可重入性,即同一個線程是否可以多次獲取同一把鎖而不被阻塞。通常情況下,分布式鎖是不具備可重入性的,因為每次獲取鎖都會生成一個新的標(biāo)識(如requestId),不會與之前的標(biāo)識相同。
為了解決可重入性的問題,我們可以引入一個計數(shù)器,記錄某個線程獲取鎖的次數(shù)。當(dāng)線程再次嘗試獲取鎖時,只有計數(shù)器為0時才會真正獲取鎖,否則只會增加計數(shù)器。釋放鎖時,計數(shù)器減少,直到為0才真正釋放鎖。
需要注意的是,為了保證分布式鎖的線程安全性,我們應(yīng)該使用線程本地變量來存儲requestId,以防止不同線程之間的干擾。
四、分布式鎖的高級應(yīng)用與性能考慮
1、鎖粒度的選擇
在分布式鎖的應(yīng)用中,選擇合適的鎖粒度是非常重要的。鎖粒度的選擇會直接影響系統(tǒng)的性能和并發(fā)能力。一般而言,鎖粒度可以分為粗粒度鎖和細(xì)粒度鎖。
- 粗粒度鎖:將較大范圍的代碼塊加鎖,可能導(dǎo)致并發(fā)性降低,但減少了鎖的開銷。適用于對數(shù)據(jù)一致性要求不高,但對并發(fā)性能要求較低的場景。
- 細(xì)粒度鎖:將較小范圍的代碼塊加鎖,提高了并發(fā)性能,但可能增加了鎖的開銷。適用于對數(shù)據(jù)一致性要求高,但對并發(fā)性能要求較高的場景。
在選擇鎖粒度時,需要根據(jù)具體業(yè)務(wù)場景和性能需求進行權(quán)衡,避免過度加鎖或鎖不足的情況。
2、基于RedLock的多Redis實例鎖
RedLock算法是一種在多個Redis實例上實現(xiàn)分布式鎖的算法,用于提高鎖的可靠性。由于單個Redis實例可能由于故障或網(wǎng)絡(luò)問題而導(dǎo)致分布式鎖的失效,通過使用多個Redis實例,我們可以降低鎖失效的概率。
RedLock算法的基本思想是在多個Redis實例上創(chuàng)建相同的鎖,并使用SETNX命令來嘗試獲取鎖。在獲取鎖時,還需要檢查大部分Redis實例的時間戳,確保鎖在多個實例上的時間戳是一致的。只有當(dāng)大部分實例的時間戳一致時,才認(rèn)為鎖獲取成功。
以下是基于RedLock的分布式鎖的Java代碼示例:
import redis.clients.jedis.Jedis;
public class RedLockExample {
private static final int QUORUM = 3;
private static final int LOCK_TIMEOUT = 500;
private Jedis[] jedisInstances;
public RedLockExample() {
jedisInstances = new Jedis[]{
new Jedis("localhost", 6379),
new Jedis("localhost", 6380),
new Jedis("localhost", 6381)
};
}
public boolean acquireLock(String lockKey, String requestId) {
int votes = 0;
long start = System.currentTimeMillis();
while ((System.currentTimeMillis() - start) < LOCK_TIMEOUT) {
for (Jedis jedis : jedisInstances) {
if (jedis.setnx(lockKey, requestId) == 1) {
jedis.expire(lockKey, LOCK_TIMEOUT / 1000); // 設(shè)置鎖的超時時間
votes++;
}
}
if (votes >= QUORUM) {
return true;
} else {
// 未獲取到足夠的票數(shù),釋放已獲得的鎖
for (Jedis jedis : jedisInstances) {
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
}
}
}
try {
Thread.sleep(50); // 等待一段時間后重試
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
return false;
}
public void releaseLock(String lockKey, String requestId) {
for (Jedis jedis : jedisInstances) {
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
}
}
}
public static void main(String[] args) {
RedLockExample redLockExample = new RedLockExample();
String lockKey = "resource:lock";
String requestId = "request123";
if (redLockExample.acquireLock(lockKey, requestId)) {
try {
// 執(zhí)行需要加鎖的操作
System.out.println("Lock acquired. Performing critical section.");
Thread.sleep(1000); // 模擬操作耗時
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
redLockExample.releaseLock(lockKey, requestId);
System.out.println("Lock released.");
}
} else {
System.out.println("Failed to acquire lock.");
}
}
}3、分布式鎖的性能考慮
分布式鎖的引入會增加系統(tǒng)的復(fù)雜性和性能開銷,因此在使用分布式鎖時需要考慮其對系統(tǒng)性能的影響。
一些性能優(yōu)化的方法包括:
- 減少鎖的持有時間:盡量縮短代碼塊中的加鎖時間,以減少鎖的競爭和阻塞。
- 使用細(xì)粒度鎖:避免一次性加鎖過多的資源,盡量選擇合適的鎖粒度,減小鎖的粒度。
- 選擇高性能的鎖實現(xiàn):比如基于緩存的分布式鎖通常比數(shù)據(jù)庫鎖性能更高。
- 合理設(shè)置鎖的超時時間:避免長時間的鎖占用,導(dǎo)致資源浪費。
- 考慮并發(fā)量和性能需求:根據(jù)系統(tǒng)的并發(fā)量和性能需求,合理設(shè)計鎖的策略和方案。
分布式鎖的高級應(yīng)用需要根據(jù)實際情況來選擇適當(dāng)?shù)牟呗裕员WC系統(tǒng)的性能和一致性。在考慮性能優(yōu)化時,需要綜合考慮鎖的粒度、并發(fā)量、可靠性等因素。
五、常見并發(fā)問題與分布式鎖的解決方案對比
1、高并發(fā)場景下的數(shù)據(jù)一致性問題
在高并發(fā)場景下,數(shù)據(jù)一致性是一個常見的問題。多個并發(fā)請求同時修改相同的數(shù)據(jù),可能導(dǎo)致數(shù)據(jù)不一致的情況。分布式鎖是解決這一問題的有效方案之一,與其他解決方案相比,具有以下優(yōu)勢:
- 原子性保證: 分布式鎖可以保證一組操作的原子性,從而確保多個操作在同一時刻只有一個能夠執(zhí)行,避免了并發(fā)沖突。
- 簡單易用: 分布式鎖的使用相對簡單,通過加鎖和釋放鎖的操作,可以有效地保證數(shù)據(jù)的一致性。
- 廣泛適用: 分布式鎖適用于不同的數(shù)據(jù)存儲系統(tǒng),如關(guān)系型數(shù)據(jù)庫、NoSQL數(shù)據(jù)庫和緩存系統(tǒng)。
相比之下,其他解決方案可能需要更復(fù)雜的邏輯和額外的處理,例如使用樂觀鎖、悲觀鎖、分布式事務(wù)等。雖然這些方案在一些場景下也是有效的,但分布式鎖作為一種通用的解決方案,在大多數(shù)情況下都能夠提供簡單而可靠的數(shù)據(jù)一致性保證。
2、唯一性約束與分布式鎖
唯一性約束是另一個常見的并發(fā)問題,涉及到確保某些操作只能被執(zhí)行一次,避免重復(fù)操作。例如,在分布式環(huán)境中,我們可能需要確保只有一個用戶能夠創(chuàng)建某個資源,或者只能有一個任務(wù)被執(zhí)行。
分布式鎖可以很好地解決唯一性約束的問題。當(dāng)一個請求嘗試獲取分布式鎖時,如果獲取成功,說明該請求獲得了執(zhí)行權(quán),可以執(zhí)行需要唯一性約束的操作。其他請求獲取鎖失敗,意味著已經(jīng)有一個請求在執(zhí)行相同操作了,從而避免了重復(fù)操作。
與其他解決方案相比,分布式鎖的實現(xiàn)相對簡單,不需要修改數(shù)據(jù)表結(jié)構(gòu)或增加額外的約束。而其他方案可能涉及數(shù)據(jù)庫的唯一性約束、隊列的消費者去重等,可能需要更多的處理和調(diào)整。
六、最佳實踐與注意事項
1、分布式鎖的最佳實踐
分布式鎖是一種強大的工具,但在使用時需要遵循一些最佳實踐,以確保系統(tǒng)的可靠性和性能。以下是一些關(guān)鍵的最佳實踐:
選擇合適的場景
分布式鎖適用于需要確保數(shù)據(jù)一致性和控制并發(fā)的場景,但并不是所有情況都需要使用分布式鎖。在設(shè)計中,應(yīng)仔細(xì)評估業(yè)務(wù)需求,選擇合適的場景使用分布式鎖,避免不必要的復(fù)雜性。
例子:適合使用分布式鎖的場景包括:訂單支付、庫存扣減等需要強一致性和避免并發(fā)問題的操作。
反例:對于只讀操作或者數(shù)據(jù)不敏感的操作,可能不需要使用分布式鎖,以避免引入不必要的復(fù)雜性。
鎖粒度的選擇
在使用分布式鎖時,選擇適當(dāng)?shù)逆i粒度至關(guān)重要。鎖粒度過大可能導(dǎo)致性能下降,而鎖粒度過小可能增加鎖爭用的風(fēng)險。需要根據(jù)業(yè)務(wù)場景和數(shù)據(jù)模型選擇恰當(dāng)?shù)逆i粒度。
例子:在訂單系統(tǒng)中,如果需要同時操作多個訂單,可以將鎖粒度設(shè)置為每個訂單的粒度,而不是整個系統(tǒng)的粒度。
反例:如果鎖粒度過大,比如在整個系統(tǒng)級別上加鎖,可能會導(dǎo)致并發(fā)性能下降。
設(shè)置合理的超時時間
為鎖設(shè)置合理的超時時間是防止死鎖和資源浪費的重要步驟。過長的超時時間可能導(dǎo)致鎖長時間占用,而過短的超時時間可能導(dǎo)致鎖被頻繁釋放,增加了鎖爭用的可能性。
例子:如果某個操作的正常執(zhí)行時間不超過5秒,可以設(shè)置鎖的超時時間為10秒,以確保在正常情況下能夠釋放鎖。
反例:設(shè)置過長的超時時間可能導(dǎo)致鎖被長時間占用,造成資源浪費。
2、避免常見陷阱與錯誤
在使用分布式鎖時,還需要注意一些常見的陷阱和錯誤,以避免引入更多問題:
重復(fù)釋放鎖
在釋放鎖時,確保只有獲取鎖的請求才能進行釋放操作。重復(fù)釋放鎖可能導(dǎo)致其他請求獲取到不應(yīng)該獲取的鎖。
例子:
// 錯誤的釋放鎖方式
if (storedRequestId != null) {
jedis.del(lockKey);
}正例:
// 正確的釋放鎖方式
if (storedRequestId != null && storedRequestId.equals(requestId)) {
jedis.del(lockKey);
}鎖的可重入性
在實現(xiàn)分布式鎖時,考慮鎖的可重入性是必要的。某個請求在獲取了鎖后,可能還會在同一個線程內(nèi)再次請求獲取鎖。在實現(xiàn)時需要保證鎖是可重入的。
例子:
// 錯誤的可重入性處理
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
// 執(zhí)行操作
lockExample.acquireLock(lockKey, requestId, expireTime); // 錯誤:再次獲取鎖
lockExample.releaseLock(lockKey, requestId);
}正例:
// 正確的可重入性處理
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
try {
// 執(zhí)行操作
} finally {
lockExample.releaseLock(lockKey, requestId);
}
}鎖的正確釋放。
確保鎖的釋放操作在正確的位置進行,以免在鎖未釋放的情況下就進入了下一個階段,導(dǎo)致數(shù)據(jù)不一致。
例子:
// 錯誤的鎖釋放位置
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
// 執(zhí)行操作
lockExample.releaseLock(lockKey, requestId); // 錯誤:鎖未釋放就執(zhí)行了下一步操作
// 執(zhí)行下一步操作
}正例:
// 正確的鎖釋放位置
if (lockExample.acquireLock(lockKey, requestId, expireTime)) {
try {
// 執(zhí)行操作
} finally {
lockExample.releaseLock(lockKey, requestId);
}
}不應(yīng)濫用鎖
分布式鎖雖然能夠解決并發(fā)問題,但過度使用鎖可能會降低系統(tǒng)性能。在使用分布式鎖時,需要在性能和一致性之間做出權(quán)衡。
例子:不應(yīng)該在整個系統(tǒng)的每個操作都加上分布式鎖,以避免鎖競爭過于頻繁導(dǎo)致性能問題。
正例:只在必要的操作中加入分布式鎖,以保證一致性的同時最大程度地減少鎖競爭。
通過遵循以上最佳實踐和避免常見陷阱與錯誤,可以更好地使用分布式鎖來實現(xiàn)數(shù)據(jù)一致性和并發(fā)控制,確保分布式系統(tǒng)的可靠性和性能。