聯邦學習——突破隱私障礙,釋放數據價值
一、聯邦學習產生的背景
傳統的機器學習方法需要將數據集中在一個機器或數據中心進行訓練,但隨著移動互聯網、大數據等科技的崛起,個人數據分布在各種機構,包括政府機構、醫療機構、保險機構以及各個互聯網巨頭的平臺等。數據在不同的管理機構之間流通往往充滿泄漏的風險,另外,近年來數據的隱私權越來越受重視,涉及個人隱私的數據很難有效共享,要將所需要的數據集中在一起訓練非常困難,導致許多領域存在著數據孤島問題。

其實在國外大數據應用也同樣面臨這個挑戰。早在2016年,Google就提出了聯邦學習(Federated Learning)的概念,是指多源數據不需要離開自己的設備,而是分別在自己的設備訓練模型,并通過特定的加密機制在云上建立一個共享模型的機制更新模型,通過聯邦學習,所有的訓練數據都仍然保留在各自的設備上,而最終訓練出來的模型又能夠達到想要的效果。
二、什么是聯邦學習?
假設要訓練某種疾病的輔助診斷模型,為了診斷更加準確,我們需要有更大的樣本,因此需要用到三家醫院A、B和C的數據,這些醫院有不同的患者,有相同類型的患者數據(例如:CT、癥狀描述、病史等),醫院為了保護患者隱私和他們各自的病例數據安全,沒辦法全部共享。在數據準備不充分的狀態下其實很難建立一個效果良好的模型。
而聯邦學習的目的,就是希望實現各個醫院用自己的數據來訓練模型,并通過加密的機制建立一個共享的模型,并進行模型的更新,這樣做不僅保護了院方數據安全和患者隱私,還降低大量集中數據傳輸的成本。
聯邦學習是一種帶有隱私保護、安全加密技術的分布式機器學習框架,旨在讓分散的各參與方在不向其他參與者披露隱私數據的前提下,協作進行模型訓練。
三、聯邦學習訓練過程
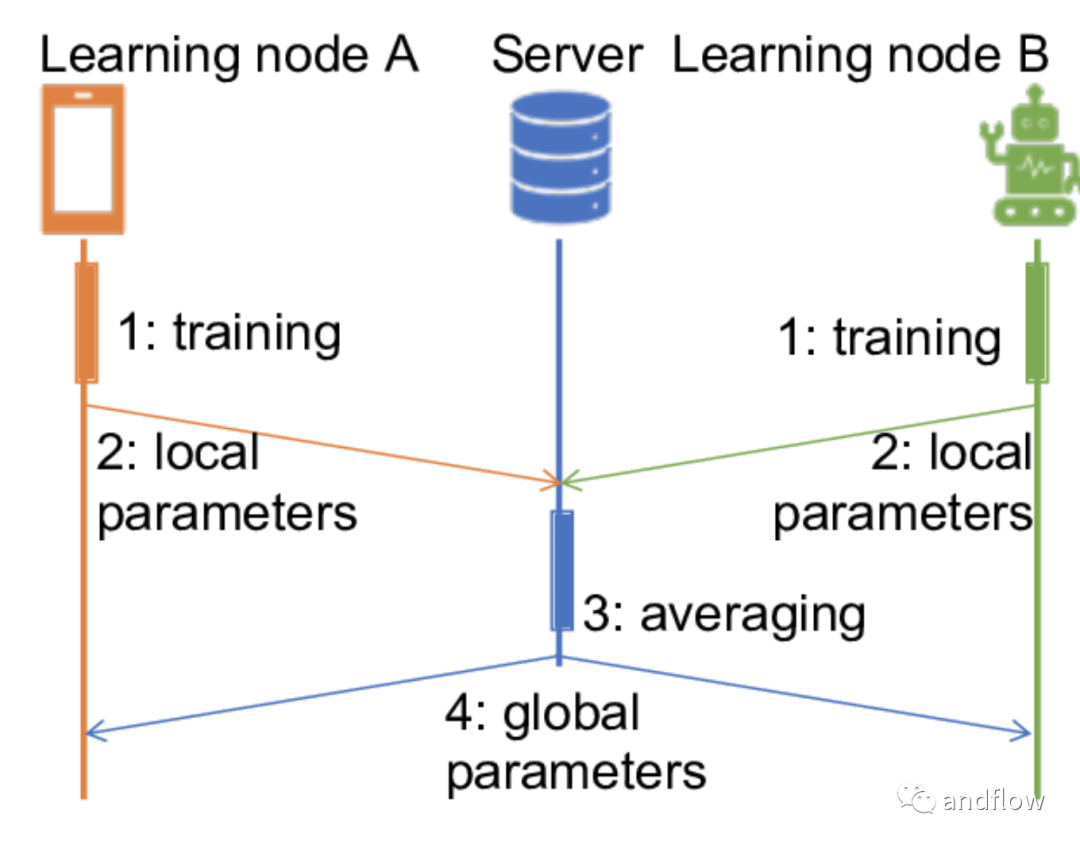
經典聯邦學習框架的訓練過程可以簡單概括為以下幾個步驟:
- 協調方建立基本模型;
- 將模型的基本結構與參數發送各參與方;
- 各參與方利用本地數據進行模型訓練
- 各方將模型參數結果發給協調方;
- 協調方匯總各參與方的模型,構建更精準的全局模型;
- 將全局參數發給各參與方以提升模型性能和效果。
四、聯邦學習核心技術
聯邦學習框架包含多方面的技術,比如:
- 機器學習與模型訓練;
- 參數整合的算法;
- 各方數據傳輸通信技術;
- 隱私保護技術;
此外,在一些聯邦學習框架中還借鑒了區塊鏈思路,使用激勵機制,數據持有方均可參與,收益具有普遍性。
值得一提的是隱私保護技術,如何在數據傳輸中保護數據的隱私安全,一直是密碼學領域的一大研究熱點。
五、聯邦學習隱私保護
聯邦學習當中增強隱私保護和減少威脅的方法,主要包含以下四種:
- Secure multi-party computation(MPC多方安全計算);
- Differential privacy(差分隱私);
- VerifyNet;
- Adversarial training(對抗訓練);
1.多方安全計算
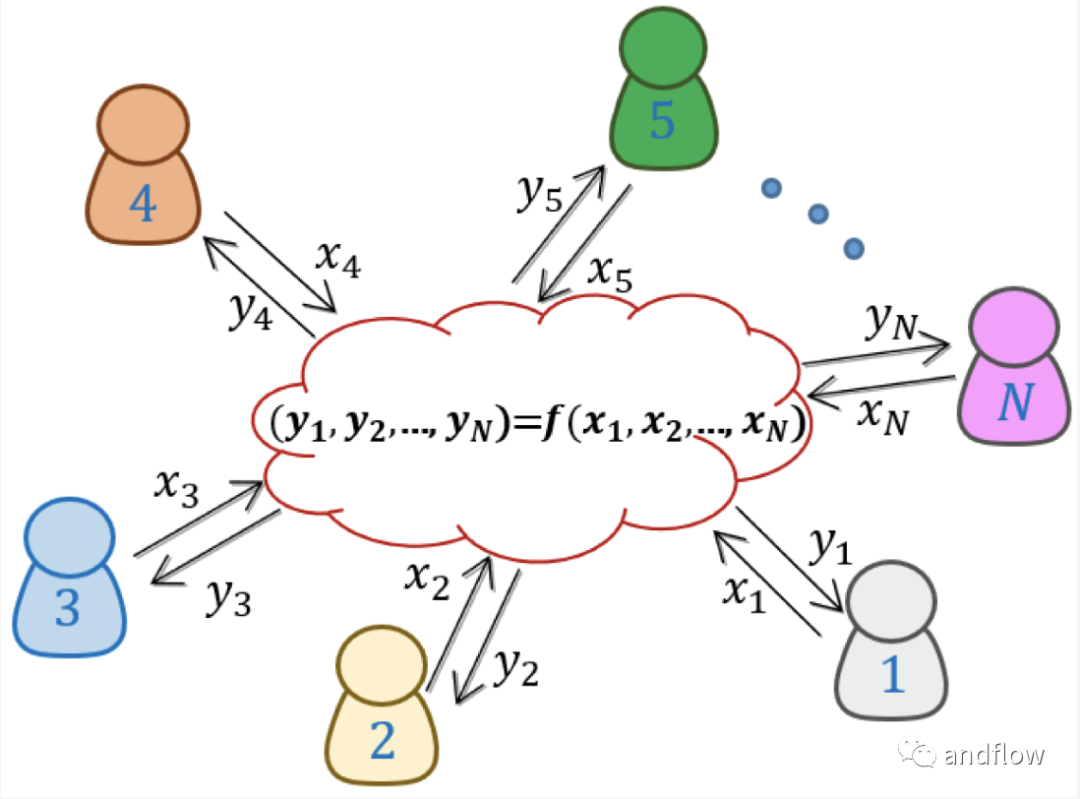
多方安全計算(Secure Multi-Party Computation,SMPC)用于解決一組互不信任的參與方各自持有秘密數據,協同計算一個既定函數的問題。安全多方計算在保證參與方獲得正確計算結果的同時,無法獲得計算結果之外的任何信息。在整個計算過程中,參與方對其所擁有的數據始終擁有絕對的控制權。
例如,在一個分布式網絡中,有n個互不信任的參與方P1,P2,…,Pn,每個參與方Pi持有秘密數據Xi(i=1,2,3,…,n)。這n個參與方協同執行既定函數,f(x1,x2,…,xn) -> (y1,y2,…,yn),其中yi為參與方Pi得到的輸出結果。任意參與方Pi除yi之外無法獲得關于其他參與方Pj(i !=j)的任何輸入信息。如果y1= y2 = … =yn,則可以簡單表示為f:(x1,x2,…,xn) -> y。如下圖所示:
2.差分隱私
差分隱私是為了對抗差分攻擊而引入的一種隱私保護的方案。通過添加噪聲來擾動原本特征清晰的數據,使得單條數據失去其獨特性,隱藏在大量數據當中,防止敏感數據泄漏,DP仍能夠使得數據具備原有的分布式特點。聯邦學習當中,為了避免數據的反向檢索,對客戶端上傳的參數進行差分隱私,這樣可能會給上傳的參數帶來不確定性,影響模型的訓練效果。
例如:有一個包含“非典”疾病信息的數據庫。我們要研究分析這種疾病,但是又怕泄漏個人隱私,有一個方法是把姓名、身份證號從數據庫中脫敏,但是如果這個城市只有少數這種疾病的病人,如果有人知道一個人在數據庫中,這可能會泄漏這個人有“非典”和他的治理情況。我們可以增加一些具有類似該疾病信息的噪音樣本書籍,以防止個人信息被識別出來。
3.VerifyNet
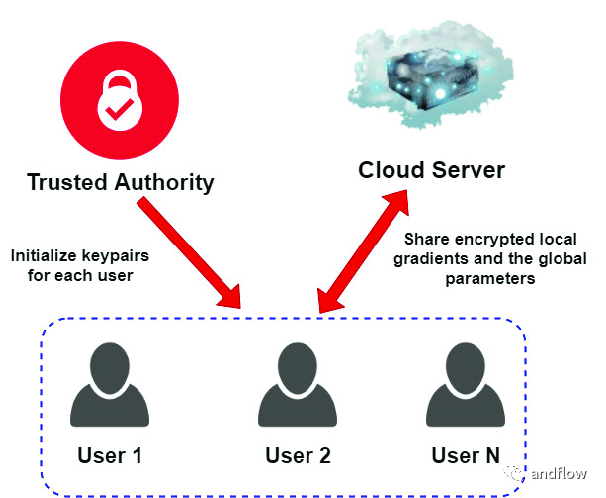
VerifyNet是一個隱私保護和可信驗證的聯邦學習框架。VerifyNet的雙隱蔽協議保證用戶在聯邦學習過程中局部梯度的機密性,另外,中心服務器需要向每個用戶提供關于聚合結果的正確性證明。在VerifyNet中,攻擊者很難偽造證據來欺騙其他用戶。此外VerifyNet還支持用戶在訓練過程中退出,發現威脅迅速回退,多方面保護用戶的隱私安全。
4.對抗訓練
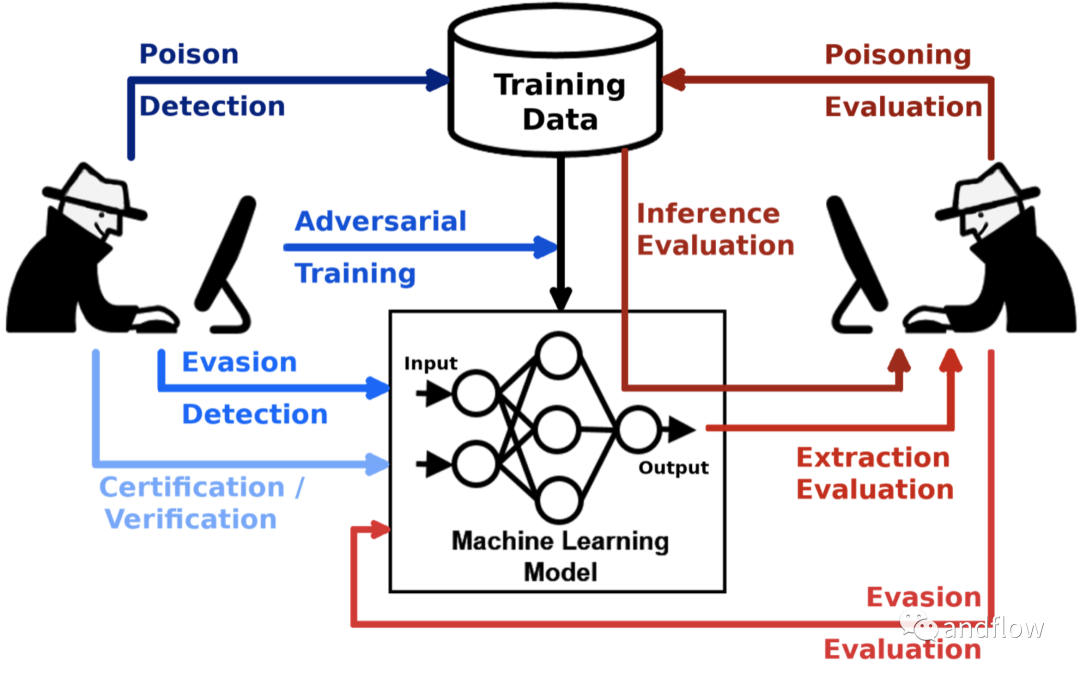
對抗訓練是增強神經網絡魯棒性的重要方式,是一種主動防御技術。在聯邦學習對抗訓練過程中,樣本當中會混合一些微小的擾動(可能導致誤分類),然后使得神經網絡適應這種變換,因此,最終生成的聯邦學習的全局模型對已知的對抗樣本具有魯棒性。
六、聯邦學習的種類
聯邦學習根據數據的類型可以劃分橫向聯邦學習(horizontal federated Learning)、縱向聯邦學習(vertical federated Learning)、聯邦遷移學習(federatedtransfer Learning)。
1.橫向聯邦學習
橫向聯邦學習適用于數據特征重疊性高且樣本重疊少的場景,比如:不同地區的醫院,他們的診療內容相似,但病人不同。
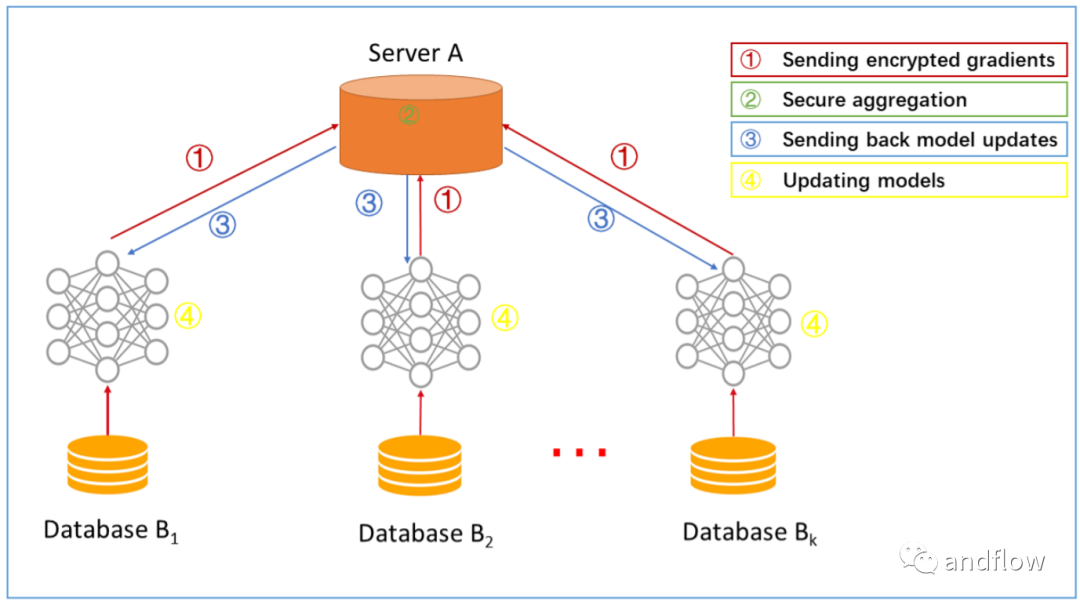
首先,每個參與方都會得到相同的模型定義,并且統一模型的初始化參數。不斷迭代以下步驟訓練模型:
- 每個參與方利用自己的數據訓練模型,分別計算梯度,再將加密過的梯度、參數上傳至協調方服務器。
- 由協調方服務器整合各參與方的梯度參數并更新模型。
- 協調方更新模型將更新后的梯度回傳給各個參與方。
- 參與方更新各自的模型。
目前橫行聯邦學習技術架構相對簡單,落地可行性較高。
2.縱向聯邦學習
縱向聯邦學習適用于樣本重疊多,但是特征重疊少的場景。比如同一地區的醫院、藥店或者保險機構,他們服務的患者大部分居住在該地區,因此樣本相同,但藥店和醫院的業務不同,它們有不同的數據特征。
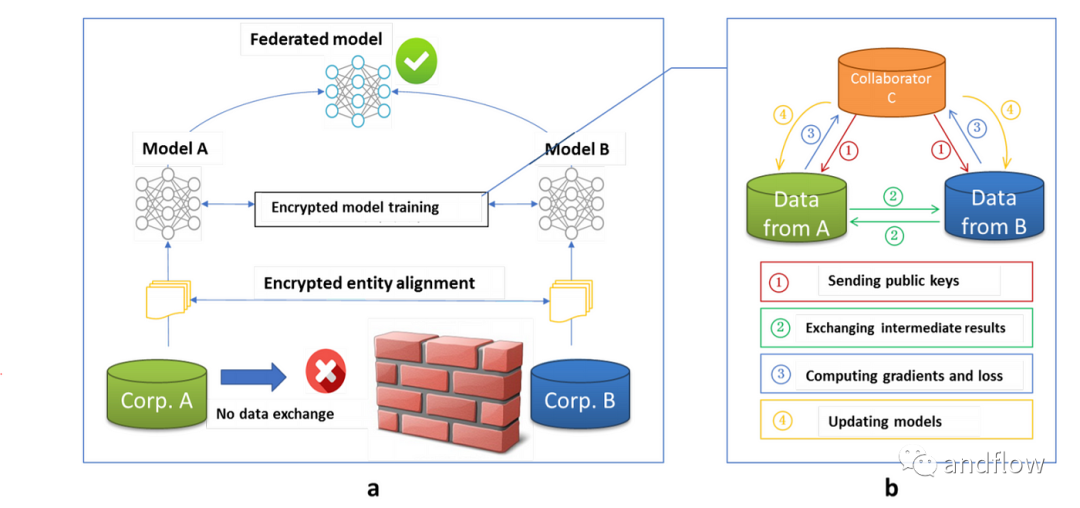
由于隱私保護法規問題,不能直接公開交換數據進行訓練。因此,如上圖所示,A與B需要利用加密對齊技術加密樣本,以確認雙方共享的客戶存在重疊,之后再利用這些數據進行加密。
A:參與方 ;B:參與方;C:協調方
① C 將公鑰發給 A 和 B(用來加密);
② A 和 B 分別計算和自己相關的特征中間結果,并交換結果,用來求得各自的最小值和損失值(loss)。
③ A和B分別將計算后且加密的最小值參數傳送給C,同時B根據標簽計算損失值并將結果匯整給C。
④ C將解密后的參數分別回傳給A和B,更新雙方的模型。
在整個過程中參與方都不知道對方的數據和特征,且訓練結束后參與方也只能得到自己估計的模型參數。
縱向聯邦學習雖然解決了特征重疊少的問題,但是只要參與方越多,計算架構就會越加復雜難以執行,落地難度較大。
3.聯邦遷移學習
當參與方擁有的數據的特征和樣本重疊的情況都很少時,可以利用聯邦遷移學習(transfer Learning)來克服數據與標簽短缺的狀況。

七、聯邦學習、分布式學習、多智能體
1.分布式機器學習
分布式機器學習(distributed machine learning),是指利用多個計算/任務節點(Worker)協同訓練一個全局的機器學習/深度學習模型(由主節點(Master)調度)。需要注意的是,分布式機器學習和傳統的HPC領域不太一樣。傳統的HPC領域主要是計算密集型,以提高加速比為主要目標。而分布式機器學習還兼具數據密集型特性,會面臨訓練數據大(單機存不下)、模型規模大的問題。此外,在分布式機器學習也需要更多地關注通信問題。
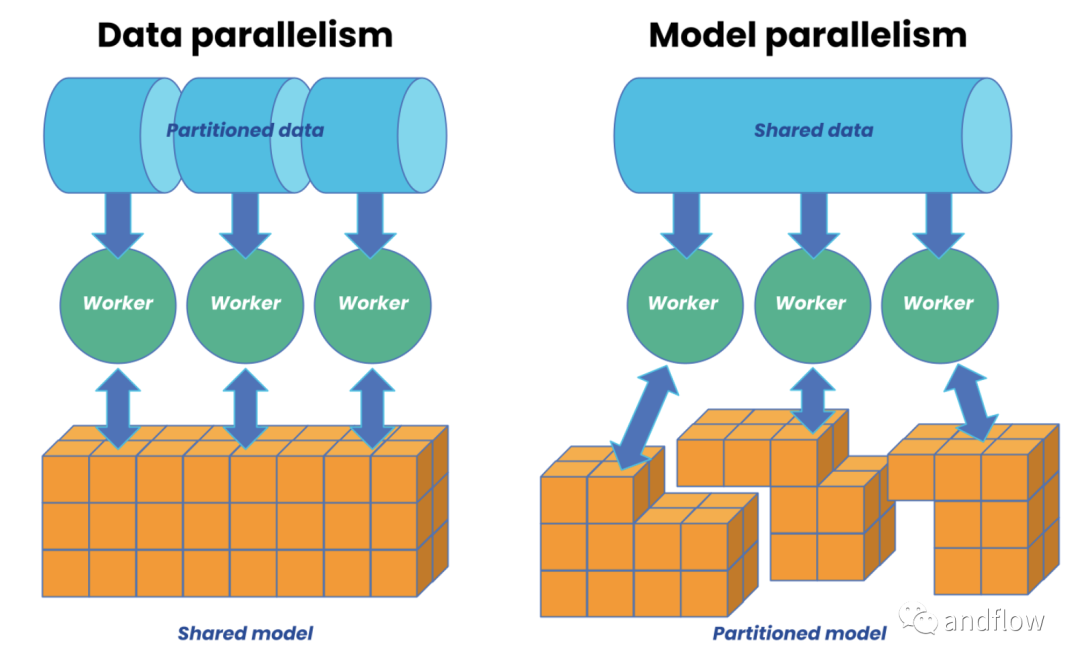
當我們利用多個計算節點并行化訓練模型時,工作負載被劃分到多個處理器或工作器上,以加快訓練過程。并行化主要有兩種類型。數據并行是指我們將訓練數據分配給可用的worker,并在每個worker上運行模型的副本。然后,每個worker在同一個模型上運行不同的數據片段。相比之下,模型(或網絡)并行是指我們將模型劃分為不同的工作者,每個工作者在模型的不同部分上運行相同的數據。
2.多智能體
多智能體系統(multi-agent system) 是一組自主的,相互作用的實體,它們共享一個共同的環境(environment),利用傳感器感知,并利用執行器作動。多智能體系統提供了用分布式來看待問題的方式,可以將控制權限分布在各個智能體上。
3.聯邦學習、分布式學習和多智能體的區別
分布式機器學習 | 聯邦學習 | 多智能體 | |
解決的問題 | 針對運算量大、數據量大等問題使用計算機集群來訓練大規模機器學習模型。 | 針對保護用戶隱私保護,數據安全等問題,通過高效的算法、加密算法等進行機器學習建模,打破數據孤島。 | 主要在多機器人、多無人機協同編隊以及多目標跟蹤與監控中發揮作用。 |
數據處理方案 | 數據并行:先將訓練數據劃分為多個子集(切片),然后將各子集置于多個計算實體中,并行訓練同一個模型。 | 聯邦建模各方,本地數據不出庫,先在本地訓練模型參數(或梯度),然后通過同態加密技術交互其參數,更新模型。 | 可以預先收集好環境數據然后采用經驗回放技術進行訓練,也可以直接采用在線學習的形式,即多個智能體在環境中進行交互學習。 |
訓練方案 | 工業應用中,大部分還是以數據并行為主:各個節點取不同的數據,然后各自完成前向和后向的計算得到梯度用以更新共有的參數,然后把update后的模型再傳回各個節點。 | 各方在本地初始化模型參數,經過訓練獲得梯度(或參數),交由可信第三方進行模型的更新,然后分發到各方本地進行更新,如此反復,獲得做種的模型。 | 每個智能體獨立與環境交互,利用環境反饋的獎勵改進自己的策略,以獲得更高的回報(即累計獎勵)。此外多個智能體是相互影響的,一個智能體的策略不能簡單依賴于自身的觀測、動作,還需要考慮到其他智能體的觀測、動作。常采用中心化訓練+去中心化執行[7][8]這一訓練模式。 |
通信方式 | MPI(常用于超算,底層基于高速網絡如IB網)、NCCL、gRPC(常用于廉價集群,底層基于TCP和以太網) | gRPC(大部分) | 高速網絡 |
數據 | IID(獨立同分布)數據,數據均衡 | 非IID數據,數據不均衡甚至異構 | 多智能體處于統一環境,數據滿足IID |
成本 | 有專用的通信條件,所以通信代價往往較小 | 通信的代價遠高于計算的代價 | 智能體之間常由傳感器高速網絡連接,通信代價小 |
容錯性 | 很少考慮容錯問題 | 容錯性問題非常重要 | 基本不考慮容錯性 |
八、聯邦學習架構
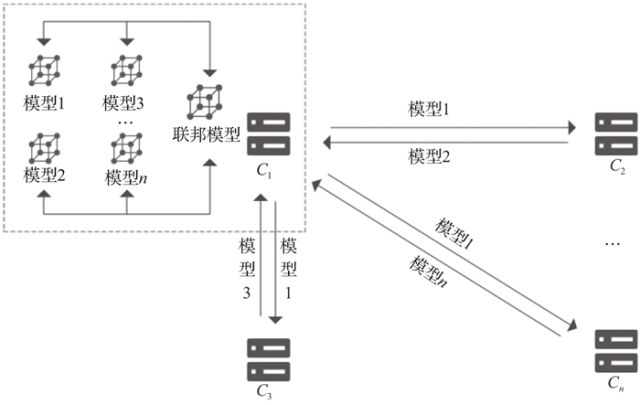
聯邦學習的架構分為兩種,一種是中心化聯邦(客戶端/服務器)架構,一種是去中心化聯邦(對等計算)架構。
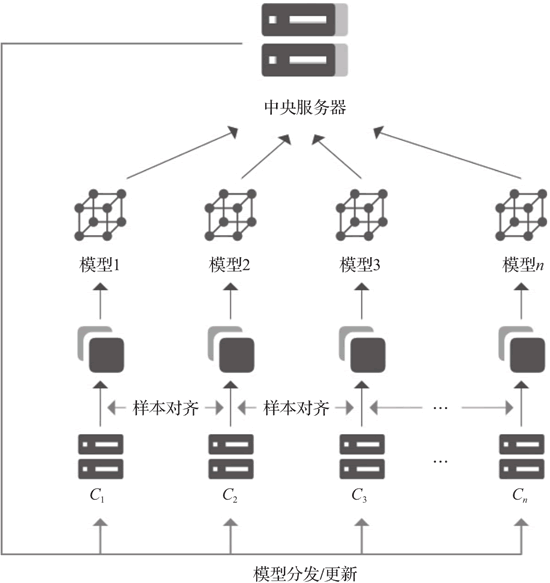
1.中心化聯邦學習架構
中心化聯邦學習架構主要用于需要聯合多方用戶進行聯邦學習場景,協調方機構作為中央服務器,起著協調全局模型的作用。
2.去中心化聯邦學習架構
在多家參與機構面臨數據孤島,又難以從多家機構中選出協調方的場景,一般可以采用去中心化的聯邦學習架構(對等架構)。
九、總結
雖然聯邦學習解決了分布在不同機構的數據在不泄漏隱私的情況下得以應用,突破數據隱私障礙,提升了數據價值。但聯邦學習距離落地仍然存在許多技術難點:
- 通信開銷問題:聯邦學習中的通信開銷問題是影響聯邦學習效率的主要瓶頸之一。
- 數據的非獨立同分布: 通常情況下,機器學習的數據集是獨立同分布的,而聯邦學習的數據集卻常常以非獨立同分 布(Non-Independent Identically Distribution,Non-IID)的方式存在,這就對聯邦學習的實際落地形成了挑戰。
- 系統和數據的異質性:聯邦學習網絡中的客戶端系統通常會有多種類別,系統的異質性以及來自設備的數據的不平衡、不一致分布會顯著影響聯邦學習模型的性能。并且客戶端的龐大數量和不一致性可能會使模型的可靠性下降。經典的 FedAvg 對系統異構性不夠健壯。
另外,除了技術難點之外,參與方的合作機制也需要探索,例如:
- 如何打破同類機構之間的數據競爭?
- 如何說服擁有敏感數據的一方加入?
- 如何維持參與方的穩定,同時,若中途若有參與方退出,如何維持模型的穩定?
總體來說,在數字化不斷發展的今天,可預見未來聯邦學習仍將是一個重要的研究領域。但目前聯邦學習還有待進一步提升相關技術并增加成功落地案例。