ClickHouse在數據平臺中的實踐簡介

Part 01傳統Hadoop生態方案介紹及其缺點
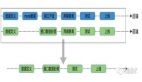
從Hadoop生態出現以來,人們嘗到了大數據技術的甜頭,隨著Hadoop生態的不斷發展,它的大數據處理能力已經被業界充分認可。用戶可以根據自己的業務需要選擇合適的Hadoop生態組件組成自己的大數據處理框架,這里我們以大數據Lambda架構為例對Hadoop生態方案進行說明,其架構圖如下所示。

大數據Lambda架構分為三層,下面分別進行描述。
批處理層(Batch Layer):對不可變數據進行批量處理。因為如果在業務需要查詢時對全量數據集進行在線查詢計算代價會很高,所以可以對查詢事先進行預計算,生成對應的Views,這樣查詢的速度會提高很多。批處理層采用不可變模型對所有數據進行了存儲,并根據不同的業務需求對數據進行了不同的預查詢,生成對應的Batch Views,這些Batch Views提供給上層的Serving Layer進行進一步的查詢。
實時流處理層(Speed Layer):因為批處理層是對全量數據集進行查詢,花費的時間會比較長(通常以小時甚至是天為單位)。新進入系統的數據就無法及時被用戶查詢,導致用戶得到的結果不正確。因此需要實時流處理層來處理增量的實時數據。
服務層(Serving Layer):用于響應用戶的查詢請求,它將批處理層和實時流處理層的結果進行合并,把得到的最終結果返回給用戶。
大數據Lambda不同的層可以根據實際業務選擇合適的Hadoop生態組件,可能的選擇如下圖粗體文字所示:
 圖2 Lambda架構選擇組件
圖2 Lambda架構選擇組件
通過上面我們對傳統Hadoop生態方案的介紹我們可以看到,傳統方案使用的生態組件多,這就會導致所需硬件資源多、維護困難、使用門檻高等各種問題,而ClickHouse方案就沒有上述的各種問題,讓我們接著往下看。
Part 02ClickHouse介紹
ClickHouse是俄羅斯的Yandex于2016年開源的用于在線分析處理查詢(OLAP :Online Analytical Processing)MPP架構的列式存儲數據庫(DBMS:Database Management System),能夠使用 SQL 查詢實時生成分析數據報告。ClickHouse可以做用戶行為分析,流批一體。線性擴展和可靠性保障能夠原生支持 shard + replication。ClickHouse沒有走Hadoop生態,采用Local attached storage作為存儲。
ClickHouse通過向量化執行以及對CPU底層指令集(SIMD)的使用,它可以對海量數據進行并行處理,從而加快數據的處理速度。
2.1 ClickHouse和其他常用數據庫性能對比
 圖片
圖片
 圖片來源https://benchmark.clickhouse.com/
圖片來源https://benchmark.clickhouse.com/
上圖是ClickHouse官方發布的,ClickHouse和MongoDB、MySQL的部分性能評測對比圖。我們可以看到ClickHouse的性能在幾乎所有場景都優于MongoDB和MySQL。
2.2 ClickHouse的特點
那么ClickHouse為什么這么快?這源于它的設計和特點。ClickHouse使用C++開發,可以利用硬件優勢,摒棄了Hadoop生態,數據底層以列式存儲。它利用單節點的多核并行處理,為數據建立索引一級、二級、稀疏索引,使用大量的算法處理數據,并支持向量化處理,分布式處理數據。
2.2.1 ClickHouse為什么采用列式存儲?
行式存儲的好處:想查找某個人所有的屬性時,可以通過一次磁盤查找加順序讀取就可以;但是當想查所有人的年齡時,需要不停的查找,或者全表掃描才行,遍歷的很多數據都是不需要的。
列式存儲的好處:對于列的聚合、計數、求和等統計操作優于行式存儲。由于某一列的數據類型都是相同的,針對于數據存儲更容易進行數據壓縮,每一列選擇更優的數據壓縮算法,大大提高了數據的壓縮比重。數據壓縮比更好,一方面節省了磁盤空間,另一方面對于cache也有了更大的發揮空間。
2.2.2 DBMS功能
ClickHouse幾乎覆蓋了標準 SQL 的大部分語法,包括 DDL 和 DML,以及配套的各種函數;用戶管理及權限管理、數據的備份與恢復。
2.2.3 多樣化引擎
ClickHouse目前提供包括合并樹、日志、接口和其他四大類20多種引擎。
2.2.4 高吞吐寫入能力
ClickHouse采用類LSM Tree的結構,數據寫入后定期在后臺Compaction。通過類 LSM tree的結構, ClickHouse在數據導入時全部是順序append寫,寫入后數據段不可更改,在后臺compaction時也是多個段merge sort后順序寫回磁盤。順序寫的特性,充分利用了磁盤的吞吐能力。
2.2.5 數據分區與線程及并行
ClickHouse將數據劃分為多個partition,每個partition再進一步劃分為多個index granularity(索引粒度),然后通過多個CPU核心分別處理其中的一部分來實現并行數據處理。在這種設計下,單條Query就能利用整機所有CPU。強大的并行處理能力,極大的降低了查詢延時。
所以,ClickHouse即使對于大量數據的查詢也能夠化整為零平行處理。但是有一個弊端就是對于單條查詢使用多CPU,就不利于同時并發多條查詢。所以對于高QPS的查詢業務并不是強項。
ClickHouse像很多OLAP數據庫一樣,單表查詢速度優于關聯查詢,而且ClickHouse的兩者差距更為明顯。在執行關聯查詢時,ClickHouse會將右表加載到內存。
Part 03ClickHouse方案

各種數據源通過Kafka接入到數據平臺層,數據平臺講明細數據存入數據存儲層的ClickHouse中,明細數據的存活時間可以根據業務需求設置。同時可以根據業務報表查詢的不同維度,利用ClickHouse的物化視圖形成預聚合數據,提高數據查詢效率。由數據服務層的定時任務周期性地從ClickHouse的預聚合數據中查詢業務所需的展示數據,把展示數據存入MySQL。由數據服務層的報表服務向數據展示層提供查詢服務,報表服務直接查詢MySQL中的結果數據,保證了查詢效率和并發性。
Part 04 總結
傳統的Hadoop生態方案使用的生態組件多,這就會導致所需硬件資源多、維護困難、使用門檻高等各種問題。而ClickHouse方案不依賴Hadoop生態,根據業務需要使用簡單的幾種組件就可以完成數據接入、數據存儲和數據查詢等功能,節省了系統服務器資源,也降低了使用人員的門檻。