













聊聊蘋果極致的LLM端側(cè)方案
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
端側(cè)LLM毫無疑問會成為各手機(jī)廠商在2024年的主戰(zhàn)場。從國內(nèi)各手機(jī)廠透露的信息來看,大家?guī)缀醵及严M耐性诹诵酒瑥S身上,自身能做的、會做的工作太少。希望蘋果的工作對國內(nèi)廠商們有啟發(fā)、借鑒意義。
論文鏈接:LLM in a flash: Efficient Large Language Model Inference with Limited Memory
1. Flash Memory and DRAM
在移動端設(shè)備中(如手機(jī)),DRAM可理解為“運(yùn)行時(shí)內(nèi)存”,F(xiàn)lash Memory可理解為“存儲空間”。做一個(gè)簡單的類比,在PC中,DRAM對應(yīng)于內(nèi)存;Flash Memory對應(yīng)于硬盤存儲(注意:僅僅是對應(yīng)于,實(shí)現(xiàn)方案并不一樣)。
在通常的LLM推理階段,LLM都是直接加載到DRAM中的。一個(gè)7B半精度LLM,完全加載進(jìn)DRAM所需的存儲空間超過14GB。考慮到目前主流手機(jī)的DRAM最高也就16GB的水平,在端側(cè)直接使用DRAM來加載7B LLM面臨巨大挑戰(zhàn)。
圖1給出了一個(gè)移動端標(biāo)準(zhǔn)的存儲結(jié)構(gòu)示意圖。
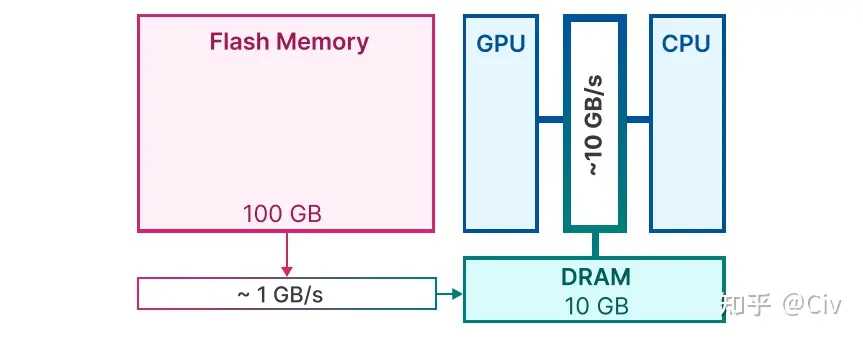
圖1 移動端存儲結(jié)構(gòu)示意圖
Flash Memory的特點(diǎn)是大存儲,低帶寬。也就是說,F(xiàn)lash Memory可存儲的內(nèi)容多(圖中的100GB),但數(shù)據(jù)傳輸速率低(圖中的1GB/s)。而DRAM的特點(diǎn)是小存儲,高帶寬。
現(xiàn)在的問題是:模型大小 > DRAM,所以無法將模型全部加載進(jìn)DRAM。
蘋果的解決方案是將LLM放在Flash Memory中,在每次需要進(jìn)行推理時(shí),僅僅將部分必要參數(shù)加載到DRAM中。
蘋果的整個(gè)方案重點(diǎn)解決兩個(gè)問題:
- 如何快速識別出哪些模型參數(shù)是必要的
- 考慮到由Flash memory到DRAM的帶寬較低,如何加快由Flash memory到DRAM的傳輸效率
論文中從三個(gè)不同方面做了嘗試,下面分別介紹。
2. 減少數(shù)據(jù)傳輸量
這部分介紹論文中采用的三種降低數(shù)據(jù)傳輸量的方法。
2.1 方法一:Selective Persistence Strategy
對于常見的LLM而言,它的模型參數(shù)主要由Attention參數(shù)和MLP參數(shù)兩部分構(gòu)成,其中Attention參數(shù)占比約為1/3,MLP參數(shù)占比約為2/3。除此,還有參數(shù)量級可忽略不計(jì)的Embedding層的參數(shù)。
因?yàn)锳ttention參數(shù)量相對較少,所以蘋果的方案是將Attention參數(shù)和Embedding層的參數(shù)直接加載到DRAM中。
這就是所謂的Selective Persistence Strategy,其意為:有選擇性地把部分參數(shù)常駐在DRAM中。而這部分常駐的參數(shù)就是Attention參數(shù)和Embedding參數(shù)。原因是因?yàn)樗鼈冋急容^小。
2.2 方法二:Anticipating ReLU Sparsity
這里主要借鑒了DejaVu的思路:MLP層的輸出只有不到10%的值是激活狀態(tài)(不為0)。一般把這種現(xiàn)象稱為稀疏性。稀疏性越強(qiáng),則非激活狀態(tài)的值就越多。
所以我們也可把這句話“MLP層的輸出只有不到10%的值是激活狀態(tài)”簡寫作“MLP層的稀疏性超過90%”。
要注意,此處的稀疏性一般稱為“Contextual Sparsity”。也就是說,MLP層的哪些神經(jīng)元會激活,與當(dāng)前的輸入相關(guān)。
蘋果照搬了DejaVu的方法,使用一個(gè)兩層MLP來預(yù)測哪些神經(jīng)元會激活。方法也很簡單,假設(shè)神經(jīng)元個(gè)數(shù)為4096,只需要將MLP的輸出層的大小設(shè)為4096,并為每一個(gè)輸出使用sigmoid來做一個(gè)二分類即可(“選擇”or“不選擇”)。
注意1:不同Transformer層使用的預(yù)測模型不同。
注意2:同一個(gè)Transformer層中的MLP一般有兩層。它們的激活神經(jīng)元始終保持相同。
在能夠準(zhǔn)確預(yù)測的前提下,每次在推理時(shí)動態(tài)加載預(yù)測為激活神經(jīng)元對應(yīng)的參數(shù)即可。
這里有對DejaVu詳細(xì)介紹的文章:[ICML'23] DejaVu:LLM中的動態(tài)剪枝
2.3 方法三:Sliding Window
根據(jù)2.2小節(jié)中介紹的稀疏性可知,在每一次LLM進(jìn)行前向推理時(shí),它都需要使用模型預(yù)測每一個(gè)MLP層中激活神經(jīng)元的編號,并將所需的神經(jīng)元所對應(yīng)的權(quán)重由Flash memory加載到DRAM中。
因?yàn)長LM的推理階段是逐token進(jìn)行的,這意味著在生成不同token的時(shí)候,需要加載到DRAM中的MLP的參數(shù)也不同。
用一個(gè)簡單的例子來說明這個(gè)基礎(chǔ)概念,只考慮第 層的Transformer模塊。在處理當(dāng)前token 時(shí),該層使用模型預(yù)測MLP會激活的神經(jīng)元編號,假設(shè)為{0, 1, 3, 5},并將其對應(yīng)的參數(shù)從Flash memory加載到DRAM中,然后進(jìn)行推理。
在處理下一個(gè)token 時(shí),將 從DRAM中刪除,再使用模型預(yù)測MLP會激活的神經(jīng)元編號,假設(shè)為{0, 2, 3, 6},并將其對應(yīng)的參數(shù)從Flash memory加載到DRAM中,然后進(jìn)行推理。
注意到在我們的例子中,兩次前向推理時(shí),第 層的Transformer結(jié)構(gòu)中MLP有部分被預(yù)測為激活的神經(jīng)元是重疊的:{0, 3}。所以實(shí)際上在進(jìn)行第二次前向推理時(shí),沒有必要把完全從DRAM中刪除,而是將其中編號為{1, 5}神經(jīng)元對應(yīng)的參數(shù)刪除,再將編號為{2, 6}的神經(jīng)元對應(yīng)的參數(shù)讀入即可。這樣可以減少I/O的總開銷。
這就是Sliding Window的核心思想:保留處理過去k個(gè)token時(shí)的激活神經(jīng)元所對應(yīng)的參數(shù)在DRAM中,并在處理當(dāng)前token時(shí)只對:1)部分多余的參數(shù)進(jìn)行刪除;2)缺少的參數(shù)進(jìn)行加載。圖2是原文中的示意圖。
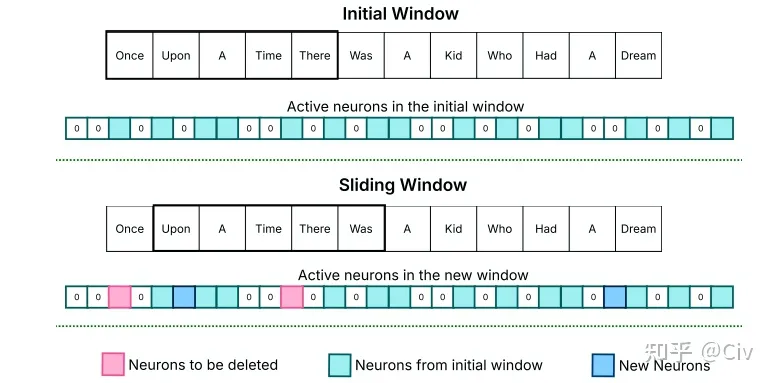
圖2 Sliding Window示意圖
圖中上圖表示在處理當(dāng)前token “Was”之前,前5個(gè)token(k=5)的激活神經(jīng)元(淡藍(lán)色偏綠部分)。圖中下圖表示在處理當(dāng)前token “Was”之時(shí),需要新加入的神經(jīng)元(藍(lán)色部分)和需要刪除的神經(jīng)元(分紅部分)。
Sliding Window的核心假設(shè)是LLM在處理相鄰token時(shí)產(chǎn)生的稀疏性具有相似性。原文沒有仔細(xì)分析和論證這個(gè)假設(shè)。
3 提高傳輸吞吐量
3.1 Bundling Columns and Rows
通常LLM中的MLP層包含兩個(gè)全連層。在忽略激活函數(shù)的情況下,這兩個(gè)全連層可以寫為:
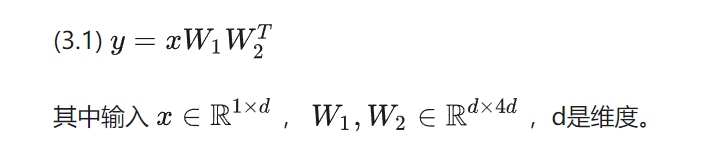
在2.2小節(jié)中曾經(jīng)提到,稀疏性預(yù)測是對MLP中兩個(gè)全連層同時(shí)進(jìn)行的。也就是說,如果我們預(yù)測結(jié)果是第一個(gè)全連層中0號神經(jīng)元不會被激活,那么該預(yù)測結(jié)果同樣也適用于第二個(gè)全連層:第二個(gè)全連層的0號神經(jīng)元也不會被激活。
對于第一個(gè)全連層的參數(shù)矩陣,第i個(gè)神經(jīng)元對應(yīng)于它的第i列;對于第二個(gè)全連層的參數(shù)矩陣,第i個(gè)神經(jīng)元對應(yīng)于它的第i行。
當(dāng)?shù)趇個(gè)神經(jīng)元被預(yù)測為激活時(shí),需要同時(shí)讀取的第i列和的第i行。所以為了提高讀取速度,可以將的每一列和的對應(yīng)行拼接起來存儲,如下圖所示:
 圖3 將兩個(gè)全連層的列與行拼接存儲
圖3 將兩個(gè)全連層的列與行拼接存儲
圖3中的Up Proj指的是第一個(gè)全連層,對應(yīng)于上文參數(shù)矩陣;Down Proj指第二個(gè)全連層,對應(yīng)于上文參數(shù)矩陣。
這樣做的好處是原本需要兩次I/O,現(xiàn)在只需要一次了。雖然總的數(shù)據(jù)讀取量并沒有變,但讀取大塊、連續(xù)的數(shù)據(jù)會比讀取大量小塊、非連續(xù)數(shù)據(jù)更加高效,因此整體傳輸吞吐量提升了。
3.2 Bundling Based on Co-activation
這是一個(gè)原文嘗試過,但被驗(yàn)證為無效的策略。既然原文提到了,所以這里也羅列出來。
原文中猜測某些神經(jīng)元之間可能存在一些緊密聯(lián)系。比如對于兩個(gè)神經(jīng)元a和b,當(dāng)a激活時(shí),b也會激活(或者當(dāng)b激活時(shí),a也會激活)。
因此可以通過分析來找到每個(gè)神經(jīng)元的“closest friend”(與該神經(jīng)元同時(shí)激活頻率最高的其它某個(gè)神經(jīng)元)。然后在存儲Flash memory中存儲時(shí),也將它們的參數(shù)拼接存在一起。這樣的讀取效率更高。
但該方法之所以無效,主要原因是可能會存在某個(gè)神經(jīng)元i,它是其它很多神經(jīng)元的“closest friend”。這樣導(dǎo)致的問題則是神經(jīng)元i被額外傳輸了太多次,導(dǎo)致實(shí)際的I/O成本增加了。
4 Optimized Data Management in DRAM
雖然DRAM的數(shù)據(jù)讀取速度比Flash memory快很多,但當(dāng)需要對其中數(shù)據(jù)進(jìn)行大量、高頻讀寫時(shí),它的時(shí)耗仍然不可忽略。在本文介紹的內(nèi)容中,對DRAM的讀寫主要發(fā)生在對MLP層中所需神經(jīng)元對應(yīng)參數(shù)的刪除與新增(參考圖2)。
為此,論文中設(shè)計(jì)了一種特殊的數(shù)據(jù)結(jié)構(gòu)來對DRAM中的數(shù)據(jù)做精細(xì)化管理。該數(shù)據(jù)結(jié)構(gòu)的核心變量如下:
- Matrix:按照“Bundling Columns and Rows”的方法存儲激活神經(jīng)元所對應(yīng)的參數(shù)
- bias:激活神經(jīng)元所對應(yīng)的bias參數(shù)
- num_used:激活神經(jīng)元的個(gè)數(shù)
- last_k_active:過去k個(gè)token所對應(yīng)的激活神經(jīng)元編號
- Pointer:當(dāng)前行參數(shù)對應(yīng)的神經(jīng)元編號
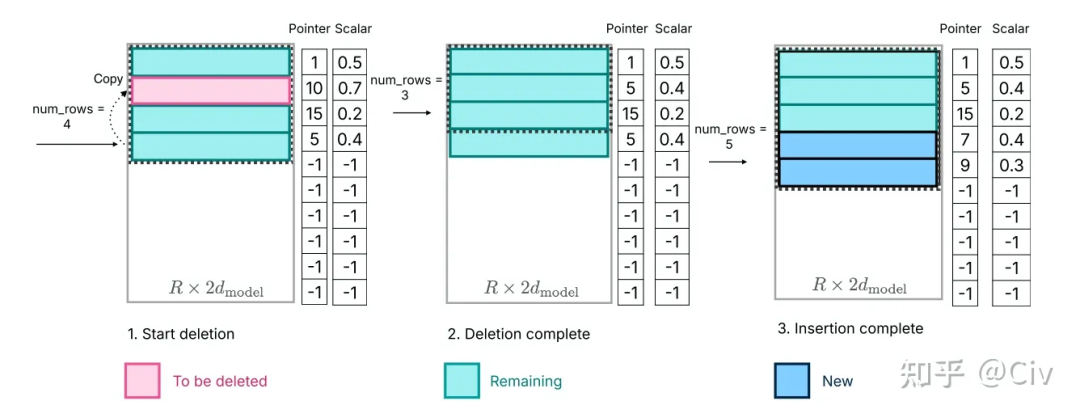
圖4 Optimized Data Management in DRAM
通過預(yù)分配一個(gè)足夠大的空間,可以避免因反復(fù)分配而導(dǎo)致的額外開銷。下面來說明基于該數(shù)據(jù)結(jié)構(gòu)的一些操作的高效實(shí)現(xiàn)方法。
該矩陣中的行對應(yīng)的是當(dāng)前存儲在DRAM中激活神經(jīng)元的參數(shù)。前文提到(2.3小節(jié)),當(dāng)處理新的token時(shí),需要將不會被激活的神經(jīng)元刪除,并添加新的會被激活的神經(jīng)元。所以最重要的兩個(gè)操作是“刪除”和“新增”。
當(dāng)需要刪除某個(gè)神經(jīng)元時(shí)(如圖4中左圖標(biāo)紅部分,對應(yīng)的是編號為10的神經(jīng)元),只需將num_rows的數(shù)量減1,并將最后一行Copy至被刪除行,結(jié)果如圖4的中圖所示。虛線框表示當(dāng)前有效的數(shù)據(jù)。
當(dāng)需要“新增”時(shí),直接將其對應(yīng)的參數(shù)由Flash memory中copy至該矩陣中即可,無需額外分配存儲空間。
5. 實(shí)驗(yàn)結(jié)果
蘋果這篇paper的主要關(guān)注點(diǎn)在于:讓LLM在運(yùn)行時(shí)內(nèi)存受限的情況下能高效地跑起來。所以論文的實(shí)驗(yàn)主要對比了各種情況下I/O導(dǎo)致的時(shí)耗,如下圖所示。
 圖5 實(shí)驗(yàn)結(jié)果
圖5 實(shí)驗(yàn)結(jié)果
圖5中的實(shí)驗(yàn)使用的是OPT 6.7B模型,半精度。表中第一行和第二行都是基準(zhǔn)baseline。第一行假設(shè)初始模型全部在Flash memory中,那么為了完成一次完整的推理,需要將模型全部加載一遍,整個(gè)I/O耗時(shí)2130ms。
第二行對應(yīng)于假設(shè)模型有一半?yún)?shù)提前在DRAM中的整個(gè)加載耗時(shí)。
第三行到第五行對應(yīng)于應(yīng)用了Predictor(2.2小節(jié))、Windowing(2.3小節(jié))和Bundling(3.1小節(jié))后對應(yīng)的耗時(shí)。
效率提升非常明顯。
























