VAD v2端到端SOTA | 遠(yuǎn)超DriveMLM等方法(地平線)
從大規(guī)模駕駛演示中學(xué)習(xí)類(lèi)似人類(lèi)的駕駛策略是很有前途的,但規(guī)劃的不確定性和非確定性本質(zhì)使得這一任務(wù)充滿挑戰(zhàn)。在這項(xiàng)工作中,為了應(yīng)對(duì)不確定性問(wèn)題,作者提出了VADv2,一個(gè)基于概率規(guī)劃的端到端駕駛模型。VADv2以流方式輸入多視角圖像序列,將傳感器數(shù)據(jù)轉(zhuǎn)換為環(huán)境標(biāo)記嵌入,輸出動(dòng)作的概率分布,并從中采樣一個(gè)動(dòng)作來(lái)控制車(chē)輛。僅使用攝像頭傳感器,VADv2在CARLA Town05基準(zhǔn)測(cè)試中實(shí)現(xiàn)了最先進(jìn)的閉環(huán)性能,顯著優(yōu)于所有現(xiàn)有方法。它能夠在完全端到端的方式下穩(wěn)定運(yùn)行,甚至不需要基于規(guī)則的封裝。
閉環(huán)演示可以在https://hgao-cv.github.io/VADv2中找到。
1 Introduction
端到端自動(dòng)駕駛是近期重要且熱門(mén)的領(lǐng)域。大量的人類(lèi)駕駛演示數(shù)據(jù)易于獲取。從大規(guī)模演示中學(xué)習(xí)類(lèi)似人類(lèi)的駕駛策略似乎很有希望。
然而,規(guī)劃的不確定性和非確定性使得從駕駛演示中提取駕駛知識(shí)變得具有挑戰(zhàn)性。

為了展示這種不確定性,圖1中提出了兩種情境:
- 跟隨另一輛車(chē)。人類(lèi)駕駛員有各種合理的駕駛操作,包括保持跟隨或變道超車(chē);
- 與迎面來(lái)車(chē)的交互。
人類(lèi)駕駛員有兩種可能的駕駛操作,即讓行或超車(chē)。從統(tǒng)計(jì)學(xué)的角度來(lái)看,行動(dòng)(包括時(shí)機(jī)和速度)具有高度隨機(jī)性,受到許多無(wú)法建模的潛在因素的影響。
現(xiàn)有的基于學(xué)習(xí)的方法遵循確定性范式直接回歸動(dòng)作。回歸目標(biāo) 是未來(lái)軌跡,在[16, 54]中是控制信號(hào)(加速度和轉(zhuǎn)向)。這種范式假設(shè)環(huán)境和動(dòng)作之間存在確定性的關(guān)系,但這并非實(shí)際情況。人類(lèi)駕駛行為的變化導(dǎo)致了回歸目標(biāo)的不確定性。特別是當(dāng)可行解空間非凸時(shí)(見(jiàn)圖1),確定性建模無(wú)法處理非凸情況,并可能輸出中間動(dòng)作,造成安全問(wèn)題。此外,這種基于確定性回歸的規(guī)劃器傾向于輸出主導(dǎo)軌跡,即在訓(xùn)練數(shù)據(jù)中出現(xiàn)最頻繁的軌跡(例如停止或直行),這會(huì)導(dǎo)致不理想的規(guī)劃性能。
在這項(xiàng)工作中,作者提出了概率性規(guī)劃以應(yīng)對(duì)規(guī)劃的不確定性。據(jù)作者所知,VADv2是第一個(gè)使用概率建模來(lái)擬合連續(xù)規(guī)劃動(dòng)作空間的工作,這與之前使用確定性建模進(jìn)行規(guī)劃的做法不同。作者將規(guī)劃策略建模為一個(gè)環(huán)境條件下的非定常隨機(jī)過(guò)程,表示為,其中是駕駛環(huán)境的歷史和當(dāng)前觀察,是一個(gè)候選的規(guī)劃動(dòng)作。與確定性建模相比,概率建模能更有效地捕捉規(guī)劃中的不確定性,從而實(shí)現(xiàn)更準(zhǔn)確且安全的規(guī)劃性能。
規(guī)劃動(dòng)作空間是一個(gè)高維的連續(xù)時(shí)空空間。作者求助于概率場(chǎng)函數(shù)來(lái)建模從動(dòng)作空間到概率分布的映射。由于直接擬合連續(xù)的規(guī)劃動(dòng)作空間是不可行的,作者將規(guī)劃動(dòng)作空間離散化為一個(gè)大的規(guī)劃詞匯表,并使用大量駕駛演示來(lái)基于規(guī)劃詞匯表學(xué)習(xí)規(guī)劃動(dòng)作的概率分布。對(duì)于離散化,作者收集了所有駕駛演示中的軌跡,并采用最遠(yuǎn)軌跡采樣方法選擇N個(gè)代表性軌跡,這些軌跡作為規(guī)劃詞匯。
概率性規(guī)劃有兩個(gè)其他優(yōu)點(diǎn)。首先,概率性規(guī)劃模型模擬了每個(gè)動(dòng)作與環(huán)境之間的相關(guān)性。與僅為目標(biāo)規(guī)劃動(dòng)作提供稀疏監(jiān)督的確定性建模不同,概率性規(guī)劃不僅能為正樣本提供監(jiān)督,也能為規(guī)劃詞匯中的所有候選提供監(jiān)督,這帶來(lái)了更豐富的監(jiān)督信息。此外,在推理階段,概率性規(guī)劃是靈活的。它輸出多模態(tài)規(guī)劃結(jié)果,并且易于與基于規(guī)則和基于優(yōu)化的規(guī)劃方法結(jié)合。由于作者模擬了整個(gè)動(dòng)作空間上的分布,作者可以靈活地將其他候選規(guī)劃動(dòng)作添加到規(guī)劃詞匯中并進(jìn)行評(píng)估。
基于概率性規(guī)劃,作者提出了VADv2,一個(gè)端到端的駕駛模型,它以流式方式接收環(huán)視圖像序列作為輸入,將傳感器數(shù)據(jù)轉(zhuǎn)換成標(biāo)記嵌入,輸出動(dòng)作的概率分布,并采樣一個(gè)動(dòng)作來(lái)控制車(chē)輛。僅使用攝像頭傳感器,VADv2在CARLA Town05基準(zhǔn)測(cè)試中實(shí)現(xiàn)了最先進(jìn)的閉環(huán)性能,顯著優(yōu)于所有現(xiàn)有方法。豐富的閉環(huán)演示可以在https://hgao-cv.github.io/VADv2上找到。VADv2在完全端到端的方式下穩(wěn)定運(yùn)行,即使沒(méi)有基于規(guī)則的封裝也可以。
作者的貢獻(xiàn)總結(jié)如下:
- 作者提出概率性規(guī)劃以應(yīng)對(duì)規(guī)劃中的不確定性。作者設(shè)計(jì)了一個(gè)概率場(chǎng),將動(dòng)作空間映射到概率分布,并從大規(guī)模駕駛演示中學(xué)習(xí)動(dòng)作的分布。
- 基于概率性規(guī)劃,作者提出了VADv2,一個(gè)端到端的駕駛模型,它將傳感器數(shù)據(jù)轉(zhuǎn)換為環(huán)境標(biāo)記嵌入,輸出動(dòng)作的概率分布,并從中采樣一個(gè)動(dòng)作來(lái)控制車(chē)輛。
- 在CARLA模擬器中,VADv2在Town05基準(zhǔn)測(cè)試上實(shí)現(xiàn)了最先進(jìn)的閉環(huán)性能。閉環(huán)演示表明,它能夠以端到端的方式穩(wěn)定運(yùn)行。
2 Related Work
感知。 感知是實(shí)現(xiàn)自動(dòng)駕駛的第一步,對(duì)駕駛場(chǎng)景的統(tǒng)一表征有利于其輕松整合到下游任務(wù)中。鳥(niǎo)瞰圖(BEV)表示近年來(lái)已成為一種常見(jiàn)策略,它有效支持場(chǎng)景特征編碼和多模態(tài)數(shù)據(jù)融合。LSS 是一項(xiàng)開(kāi)創(chuàng)性工作,通過(guò)顯式預(yù)測(cè)圖像像素的深度來(lái)實(shí)現(xiàn)透視視圖到BEV的轉(zhuǎn)換。
另一方面,BEVFormer 通過(guò)設(shè)計(jì)空間和時(shí)序注意力機(jī)制,避免了顯式的深度預(yù)測(cè),并取得了令人印象深刻的檢測(cè)性能。后續(xù)工作通過(guò)優(yōu)化時(shí)序建模和BEV轉(zhuǎn)換策略,持續(xù)提高了在下游任務(wù)中的性能。在矢量化映射方面,HDMapNet 通過(guò)后處理將車(chē)道線分割轉(zhuǎn)換為矢量地圖。VectorMapNet 以自回歸方式預(yù)測(cè)矢量地圖元素。MapTR 引入了排列等價(jià)和分層匹配策略,顯著提升了映射性能。LaneGAP 引入了針對(duì)車(chē)道圖的路徑建模。
運(yùn)動(dòng)預(yù)測(cè)。 運(yùn)動(dòng)預(yù)測(cè)旨在預(yù)測(cè)駕駛場(chǎng)景中其他交通參與者的未來(lái)軌跡,輔助自車(chē)做出明智的規(guī)劃決策。傳統(tǒng)的運(yùn)動(dòng)預(yù)測(cè)任務(wù)利用歷史軌跡和高清地圖等輸入來(lái)預(yù)測(cè)未來(lái)軌跡。然而,近年來(lái)端到端的運(yùn)動(dòng)預(yù)測(cè)方法將感知和運(yùn)動(dòng)預(yù)測(cè)結(jié)合起來(lái)。在場(chǎng)景表示方面,一些研究采用柵格化的圖像表示并使用卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行預(yù)測(cè)。
其他方法則采用向量化表示,并使用圖神經(jīng)網(wǎng)絡(luò)或Transformer模型進(jìn)行特征提取和運(yùn)動(dòng)預(yù)測(cè)。一些研究將未來(lái)的運(yùn)動(dòng)視為密集占用和流,而不是個(gè)體 Level 的未來(lái)航點(diǎn)。一些運(yùn)動(dòng)預(yù)測(cè)方法采用高斯混合模型(GMM)來(lái)回歸多模態(tài)軌跡。這可以應(yīng)用于規(guī)劃中來(lái)建模不確定性。但模式的數(shù)量是有限的。
規(guī)劃。 基于學(xué)習(xí)的規(guī)劃由于其數(shù)據(jù)驅(qū)動(dòng)性質(zhì)以及隨著數(shù)據(jù)量的增加而帶來(lái)的令人印象深刻的性能,近年來(lái)已顯示出巨大的潛力。早期嘗試采用了完全的黑箱精神,其中傳感器數(shù)據(jù)直接用于預(yù)測(cè)控制信號(hào)。然而,這種策略缺乏可解釋性,且難以優(yōu)化。此外,還有許多研究結(jié)合了強(qiáng)化學(xué)習(xí)和規(guī)劃。通過(guò)在閉環(huán)仿真環(huán)境中自主探索駕駛行為,這些方法實(shí)現(xiàn)了甚至超越人類(lèi)水平的駕駛性能。
然而,在模擬與現(xiàn)實(shí)之間的架橋,以及處理安全問(wèn)題,將強(qiáng)化學(xué)習(xí)策略應(yīng)用于真實(shí)駕駛場(chǎng)景提出了挑戰(zhàn)。模仿學(xué)習(xí)是另一個(gè)研究方向,模型通過(guò)學(xué)習(xí)專(zhuān)家駕駛行為以獲得良好的規(guī)劃性能,并發(fā)展出接近人類(lèi)的駕駛風(fēng)格。近年來(lái),端到端自動(dòng)駕駛技術(shù)已經(jīng)出現(xiàn),將感知、運(yùn)動(dòng)預(yù)測(cè)和規(guī)劃整合到單一模型中,形成了一種完全數(shù)據(jù)驅(qū)動(dòng)的方法,展示了有前景的性能。UniAD巧妙地整合了多個(gè)感知和預(yù)測(cè)任務(wù)以增強(qiáng)規(guī)劃性能。VAD探索了向量化場(chǎng)景表征用于規(guī)劃的潛力,并擺脫了密集地圖的束縛。
自動(dòng)駕駛領(lǐng)域的大型語(yǔ)言模型。大型語(yǔ)言模型(LLM)展示的可解釋性和邏輯推理能力可以在自動(dòng)駕駛領(lǐng)域提供極大的幫助。近期的研究探討了LLM與自動(dòng)駕駛的結(jié)合。一方面,有用LLM通過(guò)問(wèn)答(QA)任務(wù)來(lái)進(jìn)行駕駛場(chǎng)景理解和評(píng)估的工作。
另一方面,還有研究更進(jìn)一步,在基于LLM的場(chǎng)景理解之上加入了規(guī)劃。例如,DriveGPT4接受歷史視頻和文本(包括問(wèn)題及額外的信息,如歷史控制信號(hào))作為輸入。編碼后,這些輸入被送入LLM,預(yù)測(cè)問(wèn)題的答案和控制信號(hào)。而LanguageMPC則接收歷史 GT 感知結(jié)果和以語(yǔ)言描述形式的高清地圖。它采用一種思維鏈分析的方法來(lái)理解場(chǎng)景,最終LLM從預(yù)定義的集合中預(yù)測(cè)規(guī)劃動(dòng)作。每個(gè)動(dòng)作對(duì)應(yīng)一個(gè)具體的執(zhí)行控制信號(hào)。VADv2從GPT中獲得靈感,以解決不確定性問(wèn)題。不確定性同樣存在于語(yǔ)言建模中。
在特定語(yǔ)境下,下一個(gè)詞是非確定性的和概率性的。LLM從大規(guī)模語(yǔ)料庫(kù)中學(xué)習(xí)下一個(gè)詞的條件概率分布,并從這個(gè)分布中抽樣一個(gè)詞。受到LLM的啟發(fā),VADv2將規(guī)劃策略建模為一種環(huán)境條件下的非定常隨機(jī)過(guò)程。VADv2離散化動(dòng)作空間以生成規(guī)劃詞匯表,根據(jù)大規(guī)模駕駛演示近似概率分布,并在每個(gè)時(shí)間步從分布中抽樣一個(gè)動(dòng)作來(lái)控制車(chē)輛。
3 Method
VADv2的總體框架如圖2所示。

VADv2以流方式接收多視角圖像序列作為輸入,將傳感器數(shù)據(jù)轉(zhuǎn)換為環(huán)境標(biāo)記嵌入,輸出動(dòng)作的概率分布,并采樣一個(gè)動(dòng)作來(lái)控制車(chē)輛。使用大規(guī)模駕駛演示和場(chǎng)景約束來(lái)監(jiān)督預(yù)測(cè)的分布。
Scene Encoder
圖像中的信息是稀疏和低級(jí)的。作者使用編碼器將傳感器數(shù)據(jù)轉(zhuǎn)換為實(shí)例級(jí)標(biāo)記嵌入,以明確提取高級(jí)信息。包括四種標(biāo)記:地圖標(biāo)記、代理標(biāo)記、交通元素標(biāo)記和圖像標(biāo)記。VADv2使用一組地圖標(biāo)記來(lái)預(yù)測(cè)地圖的向量表示(包括車(chē)道中心線、車(chē)道分隔線、道路邊界和行人橫道)。
此外,VADv2還使用一組代理標(biāo)記來(lái)預(yù)測(cè)其他交通參與者的運(yùn)動(dòng)信息(包括位置、方向、大小、速度和多模態(tài)未來(lái)軌跡)。交通元素在規(guī)劃中也起著至關(guān)重要的作用。VADv2將傳感器數(shù)據(jù)轉(zhuǎn)換為交通元素標(biāo)記以預(yù)測(cè)交通元素的狀態(tài)。
在CARLA中,作者考慮兩種類(lèi)型的交通信號(hào):交通燈信號(hào)和停車(chē)標(biāo)志。地圖標(biāo)記、代理標(biāo)記和交通元素標(biāo)記都受到相應(yīng)監(jiān)督信號(hào)的監(jiān)督,以確保它們明確編碼相應(yīng)的高級(jí)信息。作者還把圖像標(biāo)記作為規(guī)劃的場(chǎng)景表示,它們包含豐富的信息,并且是對(duì)上述實(shí)例級(jí)標(biāo)記的補(bǔ)充。此外,導(dǎo)航信息和自我狀態(tài)也通過(guò)MLP編碼到嵌入中。
Probabilistic Planning
作者提出概率性規(guī)劃以應(yīng)對(duì)規(guī)劃過(guò)程中的不確定性。作者將規(guī)劃策略建模為一個(gè)條件于環(huán)境的非定常隨機(jī)過(guò)程,表述為。作者基于大規(guī)模駕駛演示近似地估計(jì)規(guī)劃動(dòng)作空間為一個(gè)概率分布,并在每個(gè)時(shí)間步從該分布中采樣一個(gè)動(dòng)作來(lái)控制車(chē)輛。
規(guī)劃動(dòng)作空間是一個(gè)高維連續(xù)時(shí)空空間 。由于直接擬合連續(xù)的規(guī)劃動(dòng)作空間是不可行的,作者將規(guī)劃動(dòng)作空間離散化為一個(gè)大的規(guī)劃詞匯表 。具體來(lái)說(shuō),作者收集了駕駛演示中的所有規(guī)劃動(dòng)作,并采用最遠(yuǎn)軌跡采樣方法選擇 個(gè)代表性動(dòng)作作為規(guī)劃詞匯。 中的每條軌跡都是從駕駛演示中采樣的,因此自然滿足自車(chē)動(dòng)力學(xué)約束,這意味著當(dāng)軌跡轉(zhuǎn)換為控制信號(hào)(轉(zhuǎn)向、油門(mén)和剎車(chē))時(shí),控制信號(hào)值不會(huì)超出可行范圍。默認(rèn)情況下, 設(shè)為4096。
作者將規(guī)劃詞匯中的每個(gè)動(dòng)作表示為航點(diǎn)序列 。每個(gè)航點(diǎn)對(duì)應(yīng)于一個(gè)未來(lái)的時(shí)間戳。假設(shè)概率 關(guān)于 是連續(xù)的,并且對(duì) 的小偏差不敏感,即,。
受到 NeRF 的啟發(fā),該方法在5D空間()上建模連續(xù)輻射場(chǎng),作者采用概率場(chǎng)來(lái)從動(dòng)作空間 到概率分布 的連續(xù)映射。作者將每個(gè)動(dòng)作(軌跡)編碼成高維規(guī)劃 Token 嵌入 ,使用級(jí)聯(lián)Transformer解碼器與環(huán)境信息 進(jìn)行交互,并結(jié)合導(dǎo)航信息 和自我狀態(tài) 來(lái)輸出概率,即,
是一個(gè)編碼函數(shù),它將來(lái)自 的每個(gè)坐標(biāo)映射到一個(gè)高維嵌入空間 ,并且分別應(yīng)用于軌跡 的每個(gè)坐標(biāo)值。 表示位置。作者使用這些函數(shù)將連續(xù)輸入坐標(biāo)映射到一個(gè)更高維的空間,以更好地近似一個(gè)高頻場(chǎng)函數(shù)。
Training
作者使用三種監(jiān)督方式來(lái)訓(xùn)練VADv2,分別是分布損失、沖突損失和場(chǎng)景標(biāo)記損失。
分布損失。作者從大規(guī)模的駕駛演示中學(xué)習(xí)概率分布。使用KL散度來(lái)最小化預(yù)測(cè)分布和數(shù)據(jù)分布之間的差異。
在訓(xùn)練階段,將真實(shí)軌跡作為正樣本添加到規(guī)劃詞匯中。其他軌跡被視為負(fù)樣本。作者對(duì)接近真實(shí)軌跡的負(fù)軌跡分配不同的損失權(quán)重。這樣的軌跡受到的懲罰較少。
沖突損失。 作者利用駕駛場(chǎng)景的約束幫助模型學(xué)習(xí)關(guān)于駕駛的重要先驗(yàn)知識(shí),并進(jìn)一步規(guī)范預(yù)測(cè)的分布。具體來(lái)說(shuō),如果規(guī)劃詞匯中的一個(gè)動(dòng)作與其他代理的未來(lái)運(yùn)動(dòng)或道路邊界發(fā)生沖突,那么這個(gè)動(dòng)作就被視為負(fù)樣本,作者施加一個(gè)顯著的損失權(quán)重以降低此動(dòng)作的概率。
場(chǎng)景標(biāo)記損失。 地圖標(biāo)記、代理標(biāo)記和交通元素標(biāo)記通過(guò)相應(yīng)的監(jiān)督信號(hào)進(jìn)行監(jiān)督,以確保它們明確編碼對(duì)應(yīng)的高級(jí)信息。
地圖 Token 的損失與MapTRv2相同。采用損失來(lái)計(jì)算預(yù)測(cè)地圖點(diǎn)與真實(shí)地圖點(diǎn)之間的回歸損失。Focal Loss用作地圖分類(lèi)損失。
代理標(biāo)記的損失由檢測(cè)損失和運(yùn)動(dòng)預(yù)測(cè)損失組成,這與VAD中的相同。使用損失作為回歸損失來(lái)預(yù)測(cè)代理屬性(位置、方向、大小等),并使用Focal Loss來(lái)預(yù)測(cè)代理類(lèi)別。對(duì)于每個(gè)與 GT 代理匹配的代理,作者預(yù)測(cè)個(gè)未來(lái)軌跡,并使用具有最小最終位移誤差(minFDE)的軌跡作為代表性預(yù)測(cè)。然后,作者計(jì)算此代表性軌跡與 GT 軌跡之間的損失作為運(yùn)動(dòng)回歸損失。此外,采用Focal Loss作為多模態(tài)運(yùn)動(dòng)分類(lèi)損失。
交通元素標(biāo)記由兩部分組成:交通燈標(biāo)記和停車(chē)標(biāo)志標(biāo)記。一方面,作者將交通燈標(biāo)記發(fā)送到多層感知機(jī)(MLP)以預(yù)測(cè)交通燈的狀態(tài)(黃、紅、綠)以及交通燈是否影響本車(chē)。另一方面,停車(chē)標(biāo)志標(biāo)記也被發(fā)送到MLP以預(yù)測(cè)停車(chē)標(biāo)志區(qū)域與本車(chē)之間的重疊。利用Focal Loss(focal loss)來(lái)監(jiān)督這些預(yù)測(cè)。
Inference
在閉環(huán)推理中,作者可以從分布中靈活地獲取駕駛策略 。直觀地說(shuō),作者在每個(gè)時(shí)間步采樣概率最高的動(dòng)作,并使用PID控制器將選定的軌跡轉(zhuǎn)換為控制信號(hào)(轉(zhuǎn)向、油門(mén)和剎車(chē))。
在實(shí)際應(yīng)用中,有更多健壯的策略可以充分利用概率分布。一種好的實(shí)踐是,將top-K動(dòng)作作為 Proposal 進(jìn)行采樣,并采用基于規(guī)則的包裝器來(lái)過(guò)濾 Proposal ,以及基于優(yōu)化的后處理解算器進(jìn)行細(xì)化。此外,動(dòng)作的概率反映了端到端模型有多自信,可以作為在傳統(tǒng)PnC和學(xué)習(xí)型PnC之間切換的判斷條件。
4 Experiments
Experimental Settings
廣泛使用的CARLA 仿真器被采納來(lái)評(píng)估VADv2的性能。按照常見(jiàn)的做法,作者使用Town05長(zhǎng)和Town05短基準(zhǔn)來(lái)進(jìn)行閉環(huán)評(píng)估。具體來(lái)說(shuō),每個(gè)基準(zhǔn)都包含幾個(gè)預(yù)定義的駕駛路線。Town05長(zhǎng)包含10條路線,每條路線大約1公里長(zhǎng)。Town05短包含32條路線,每條路線長(zhǎng)70米。Town05長(zhǎng)驗(yàn)證了模型的綜合能力,而Town05短則專(zhuān)注于評(píng)估模型在特定場(chǎng)景下的性能,例如在交叉路口前變道。
作者使用CARLA官方的自主代理人在Town03、Town04、Town06、Town07和Town10中隨機(jī)生成駕駛路線來(lái)收集訓(xùn)練數(shù)據(jù)。數(shù)據(jù)以2Hz的頻率進(jìn)行采樣,作者收集了大約300萬(wàn)幀用于訓(xùn)練。對(duì)于每一幀,作者保存了6個(gè)攝像頭的環(huán)視圖像、交通信號(hào)、其他交通參與者的信息以及自車(chē)狀態(tài)信息。
此外,通過(guò)預(yù)處理CARLA提供的OpenStreetMap 格式的地圖,作者獲得了用于訓(xùn)練在線地圖模塊的向量地圖。需要注意的是,地圖信息僅在訓(xùn)練期間作為 GT 提供,VADv2在閉環(huán)評(píng)估中并未利用任何高清晰度地圖。
Metrics
對(duì)于閉環(huán)評(píng)估,作者使用了CARLA的官方指標(biāo)。路線完成度表明了代理完成的路線距離的百分比。違規(guī)得分表示沿路線發(fā)生的違規(guī)程度的量化。典型的違規(guī)包括闖紅燈、與行人發(fā)生碰撞等。每種違規(guī)類(lèi)型都有一個(gè)相應(yīng)的懲罰系數(shù),發(fā)生的違規(guī)越多,違規(guī)得分就越低。
駕駛得分是路線完成度與違規(guī)得分的乘積,這是評(píng)估的主要指標(biāo)。在基準(zhǔn)評(píng)估中,大多數(shù)研究采用了基于規(guī)則的包裝器來(lái)減少違規(guī)。為了與其他方法進(jìn)行公平的比較,作者遵循通常的做法,在基于學(xué)習(xí)策略上采用基于規(guī)則的包裝器。
對(duì)于開(kāi)環(huán)評(píng)估,采用L2距離和碰撞率來(lái)展示學(xué)習(xí)到的策略在何種程度上類(lèi)似于專(zhuān)家演示的駕駛。在消融實(shí)驗(yàn)中,作者采用開(kāi)環(huán)指標(biāo)進(jìn)行評(píng)估,因?yàn)殚_(kāi)環(huán)指標(biāo)計(jì)算速度快且更穩(wěn)定。作者使用CARLA官方的自主代理在Town05 Long基準(zhǔn)上生成驗(yàn)證集以進(jìn)行開(kāi)環(huán)評(píng)估,并且將結(jié)果在所有驗(yàn)證樣本上取平均值。
Comparisons with State-of-the-Art Methods
在Town05長(zhǎng)距離基準(zhǔn)測(cè)試中,VADv2取得了85.1的駕駛分?jǐn)?shù),98.4的路程完成度,以及0.87的違規(guī)分?jǐn)?shù),如表1所示。與之前的最先進(jìn)方法相比,VADv2在路程完成度更高的同時(shí),顯著提高了駕駛分?jǐn)?shù),增加了9.0。

值得注意的是,VADv2僅使用攝像頭作為感知輸入,而DriveMLM同時(shí)使用了攝像頭和激光雷達(dá)。此外,與之前僅依賴攝像頭最佳方法相比,VADv2顯示出更大的優(yōu)勢(shì),駕駛分?jǐn)?shù)的顯著提高達(dá)到了16.8。
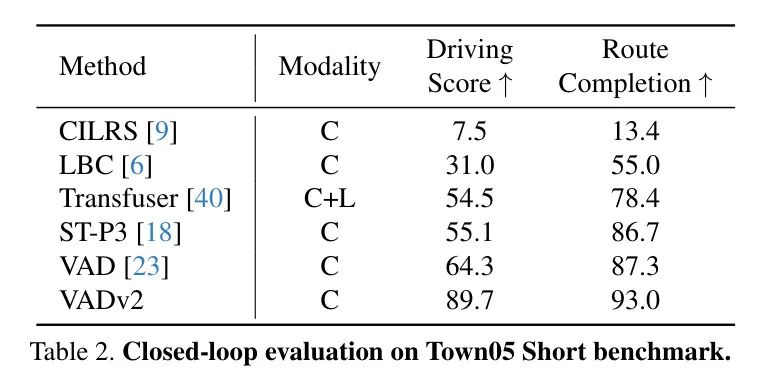
作者在表2中展示了Town05短距離基準(zhǔn)的所有公開(kāi)可用作品的成果。與Town05長(zhǎng)距離基準(zhǔn)相比,Town05短距離基準(zhǔn)更側(cè)重于評(píng)估模型在特定駕駛行為上的能力,例如在擁堵的車(chē)流中變道以及在與交叉口前變道。相較于之前的結(jié)果,VADv2在駕駛得分和路線完成率上分別顯著提升了25.3和5.7,這展示了VADv2在復(fù)雜駕駛場(chǎng)景中的綜合駕駛能力。
Ablation Study
表3展示了在VADv2中的關(guān)鍵模塊的消融實(shí)驗(yàn)。如果沒(méi)有分布損失(ID 1)提供的專(zhuān)家駕駛行為監(jiān)督,模型在規(guī)劃準(zhǔn)確性方面表現(xiàn)不佳。
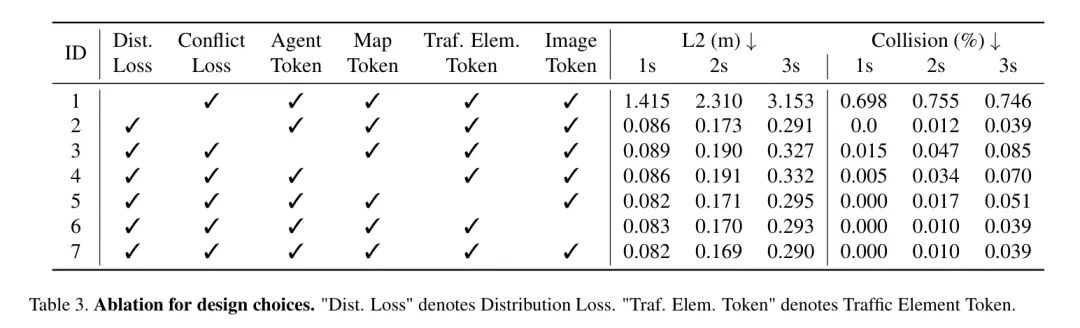
沖突損失提供了關(guān)于駕駛的關(guān)鍵先驗(yàn)信息,因此如果沒(méi)有沖突損失(ID 2),模型的規(guī)劃準(zhǔn)確性也會(huì)受到影響。場(chǎng)景標(biāo)記將重要的場(chǎng)景元素編碼成高維特征,規(guī)劃標(biāo)記與場(chǎng)景標(biāo)記交互,學(xué)習(xí)駕駛場(chǎng)景的動(dòng)態(tài)和靜態(tài)信息。當(dāng)任何類(lèi)型的場(chǎng)景標(biāo)記缺失時(shí),模型的規(guī)劃性能將會(huì)受到影響(ID 3-ID 6)。當(dāng)模型融合了上述所有設(shè)計(jì)時(shí),可以實(shí)現(xiàn)最佳的規(guī)劃性能(ID 7)。
Visualization
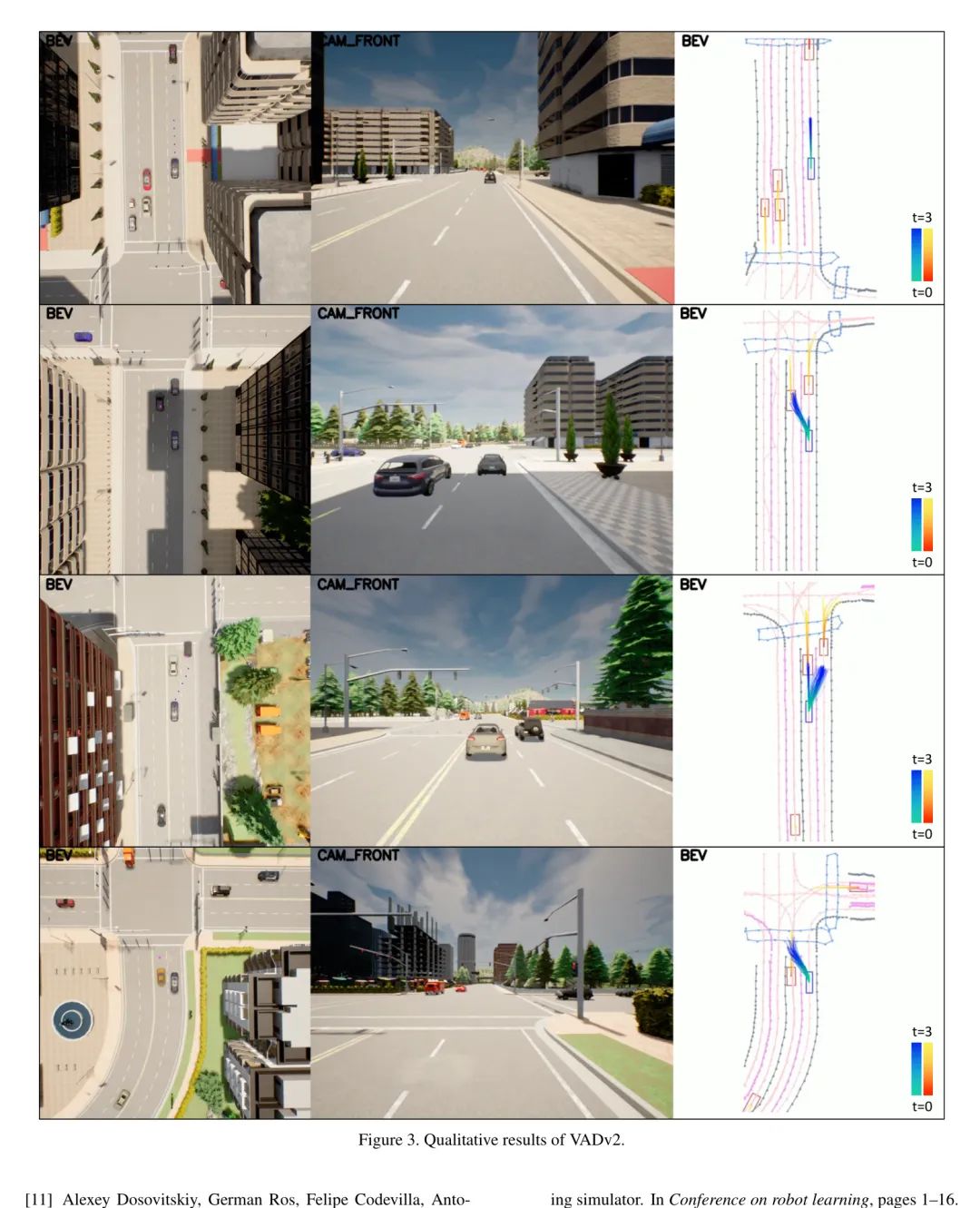
圖3展示了VADv2的一些定性結(jié)果。第一張圖像展示了在不同駕駛速度下,VADv2預(yù)測(cè)的多模態(tài)規(guī)劃軌跡。第二張圖像展示了在換道場(chǎng)景中,VADv2對(duì)向前緩行和多模態(tài)左轉(zhuǎn)軌跡的預(yù)測(cè)。第三張圖像描述了在路口的右換道場(chǎng)景,VADv2為直行和向右換道預(yù)測(cè)了多條軌跡。最后一張圖像展示了一個(gè)換道場(chǎng)景,其中目標(biāo)車(chē)道有一輛車(chē),VADv2預(yù)測(cè)了多條合理的換道軌跡。
5 Conclusion
在這項(xiàng)工作中,作者提出了VADv2,這是一個(gè)基于概率規(guī)劃的端到端駕駛模型。在CARLA模擬器中,VADv2運(yùn)行穩(wěn)定,并取得了目前最先進(jìn)的閉環(huán)性能。這種概率范式的可行性主要得到了驗(yàn)證。然而,其在更復(fù)雜的真實(shí)世界場(chǎng)景中的有效性仍有待探索,這將作為未來(lái)的工作。