













蘋(píng)果AI放大招?新設(shè)備端模型超過(guò)GPT-4,有望拯救Siri
在最近的一篇論文中,蘋(píng)果的研究人員宣稱(chēng),他們提出了一個(gè)可以在設(shè)備端運(yùn)行的模型,這個(gè)模型在某些方面可以超過(guò) GPT-4。

具體來(lái)說(shuō),他們研究的是 NLP 中的指代消解(Reference Resolution)問(wèn)題,即讓 AI 識(shí)別文本中提到的各種實(shí)體(如人名、地點(diǎn)、組織等)之間的指代關(guān)系的過(guò)程。簡(jiǎn)而言之,它涉及到確定一個(gè)詞或短語(yǔ)所指的具體對(duì)象。這個(gè)過(guò)程對(duì)于理解句子的意思至關(guān)重要,因?yàn)槿藗冊(cè)诮涣鲿r(shí)經(jīng)常使用代詞或其他指示詞(如「他」、「那里」)來(lái)指代之前提到的名詞或名詞短語(yǔ),避免重復(fù)。
不過(guò),論文中提到的「實(shí)體」更多得與手機(jī)、平板電腦等設(shè)備有關(guān),包括:
- 屏幕實(shí)體(On-screen Entities):用戶(hù)在與設(shè)備交互時(shí),屏幕上顯示的實(shí)體或信息。
- 對(duì)話(huà)實(shí)體(Conversational Entities):與對(duì)話(huà)相關(guān)的實(shí)體。這些實(shí)體可能來(lái)自用戶(hù)之前的發(fā)言(例如,當(dāng)用戶(hù)說(shuō)「給媽媽打電話(huà)」時(shí),「媽媽」的聯(lián)系方式就是相關(guān)的實(shí)體),或者來(lái)自虛擬助手(例如,當(dāng)助手為用戶(hù)提供一系列地點(diǎn)或鬧鐘供選擇時(shí))。
- 后臺(tái)實(shí)體(Background Entities):這些是與用戶(hù)當(dāng)前與設(shè)備交互的上下文相關(guān)的實(shí)體,但不一定是用戶(hù)直接與虛擬助手互動(dòng)產(chǎn)生的對(duì)話(huà)歷史的一部分;例如,開(kāi)始響起的鬧鐘或在背景中播放的音樂(lè)。
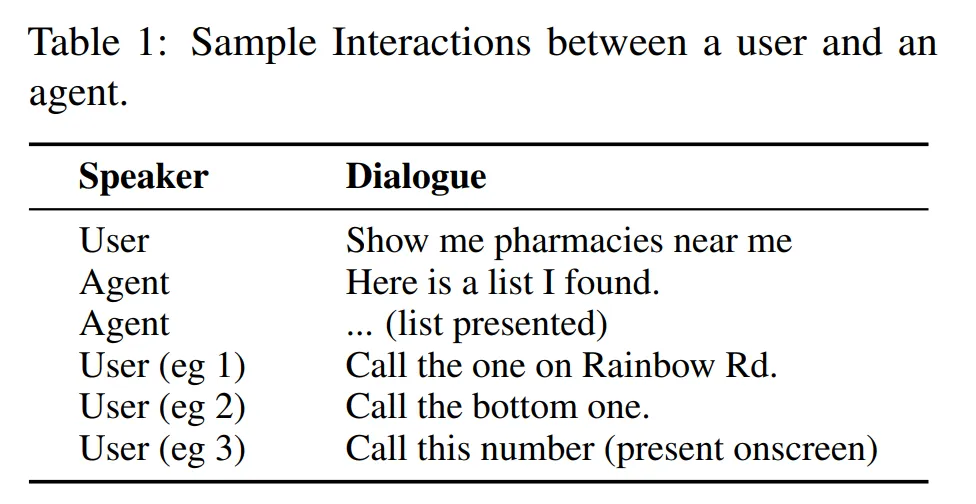
蘋(píng)果的研究在論文中表示,盡管大型語(yǔ)言模型(LLM)已經(jīng)證明在多種任務(wù)上具有極強(qiáng)的能力,但在用于解決非對(duì)話(huà)實(shí)體(如屏幕實(shí)體、后臺(tái)實(shí)體)的指代問(wèn)題時(shí),它們的潛力還沒(méi)有得到充分利用。
在論文中,蘋(píng)果的研究者提出了一種新的方法 —— 使用已解析的實(shí)體及其位置來(lái)重建屏幕,并生成一個(gè)純文本的屏幕表示,這個(gè)表示在視覺(jué)上代表了屏幕內(nèi)容。然后,他們對(duì)屏幕中作為實(shí)體的部分進(jìn)行標(biāo)記,這樣模型就有了實(shí)體出現(xiàn)位置的上下文,以及圍繞它們的文本是什么的信息(例如:呼叫業(yè)務(wù)號(hào)碼)。據(jù)作者所知,這是第一個(gè)使用大型語(yǔ)言模型對(duì)屏幕上下文進(jìn)行編碼的工作。
具體來(lái)說(shuō),他們提出的模型名叫 ReALM,參數(shù)量分別為 80M、250M、1B 和 3B,體積都非常小,適合在手機(jī)、平板電腦等設(shè)備端運(yùn)行。
研究結(jié)果顯示,相比于具有類(lèi)似功能的現(xiàn)有系統(tǒng),該系統(tǒng)在不同類(lèi)型的指代上取得了大幅度的改進(jìn),其中最小的模型在處理屏幕上的指代時(shí)獲得了超過(guò) 5% 的絕對(duì)增益。
此外,論文還將其性能與 GPT-3.5 和 GPT-4 進(jìn)行了對(duì)比,結(jié)果顯示最小模型的性能與 GPT-4 相當(dāng),而更大的模型則顯著超過(guò)了 GPT-4。這表明通過(guò)將指代消解問(wèn)題轉(zhuǎn)換為語(yǔ)言建模問(wèn)題,可以有效利用大型語(yǔ)言模型解決涉及多種類(lèi)型指代的問(wèn)題,包括那些傳統(tǒng)上難以?xún)H用文本處理的非對(duì)話(huà)實(shí)體指代。
這項(xiàng)研究有望用來(lái)改進(jìn)蘋(píng)果設(shè)備上的 Siri 智能助手,幫助 Siri 更好地理解和處理用戶(hù)詢(xún)問(wèn)中的上下文,尤其是涉及屏幕上內(nèi)容或后臺(tái)應(yīng)用的復(fù)雜指代,在在線(xiàn)搜索、操作應(yīng)用、讀取通知或與智能家居設(shè)備交互時(shí)都更加智能。
蘋(píng)果將于太平洋時(shí)間 2024 年 6 月 10 日至 14 日在線(xiàn)舉辦全球開(kāi)發(fā)者大會(huì)「WWDC 2024」,并推出全面的人工智能戰(zhàn)略。有人預(yù)計(jì),上述改變可能會(huì)出現(xiàn)在即將到來(lái)的 iOS 18 和 macOS 15 中,這將代表用戶(hù)與 Apple 設(shè)備之間交互的重大進(jìn)步。
論文介紹

論文地址:https://arxiv.org/pdf/2403.20329.pdf
論文標(biāo)題:ReALM: Reference Resolution As Language Modeling
本文任務(wù)制定如下:給定相關(guān)實(shí)體和用戶(hù)想要執(zhí)行的任務(wù),研究者希望提取出與當(dāng)前用戶(hù)查詢(xún)相關(guān)的實(shí)體(或多個(gè)實(shí)體)。相關(guān)實(shí)體有 3 種不同類(lèi)型:屏幕實(shí)體、對(duì)話(huà)實(shí)體以及后臺(tái)實(shí)體(具體內(nèi)容如上文所述)。
在數(shù)據(jù)集方面,本文采用的數(shù)據(jù)集包含綜合創(chuàng)建的數(shù)據(jù)或在注釋器的幫助下創(chuàng)建的數(shù)據(jù)。數(shù)據(jù)集的信息如表 2 所示。
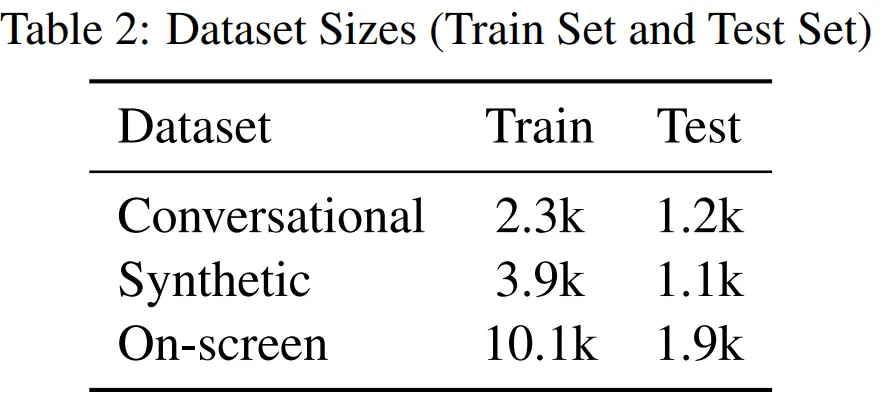
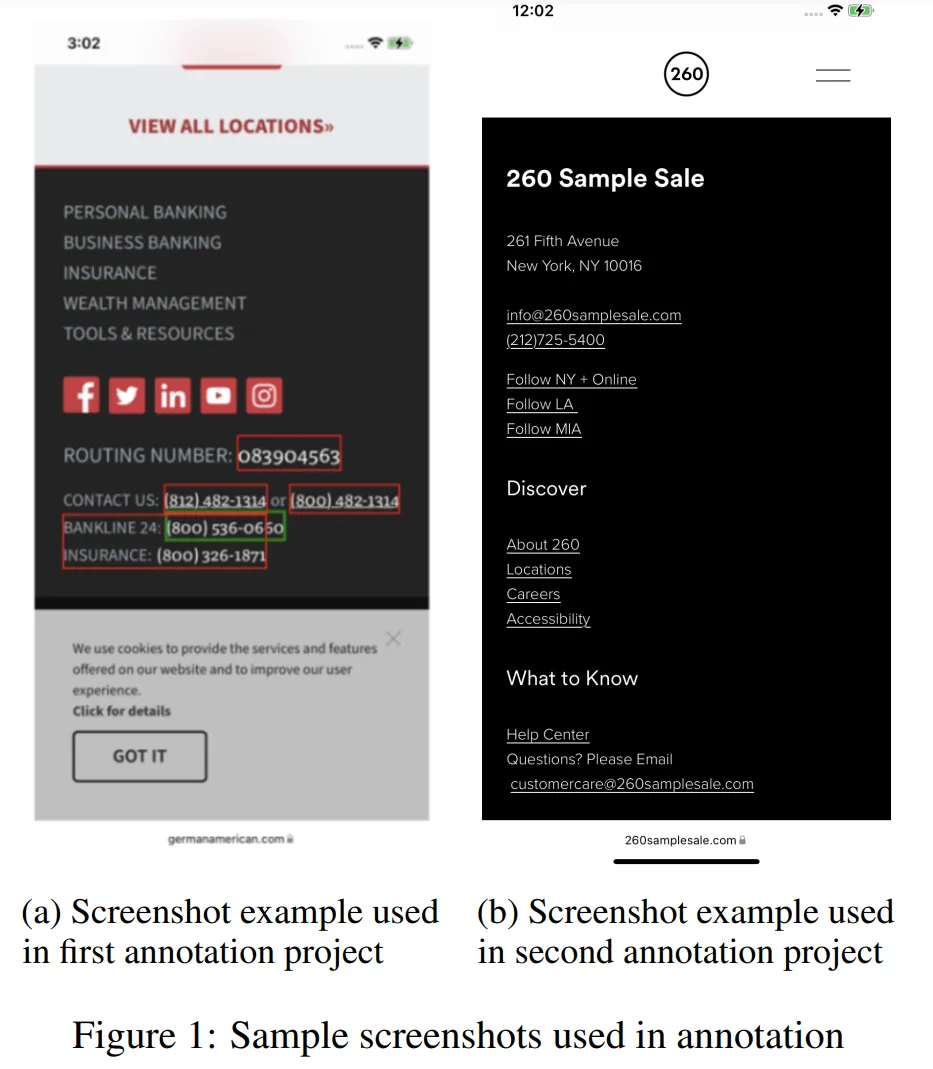
其中,對(duì)話(huà)數(shù)據(jù)是用戶(hù)與智能體交互相關(guān)的實(shí)體數(shù)據(jù);合成數(shù)據(jù)顧名思義就是根據(jù)模板合成的數(shù)據(jù);屏幕數(shù)據(jù)(如下圖所示)是從各種網(wǎng)頁(yè)上收集的數(shù)據(jù),包括電話(huà)號(hào)碼、電子郵件等。
模型
研究團(tuán)隊(duì)將 ReALM 模型與兩種基線(xiàn)方法進(jìn)行了比較:MARRS(不基于 LLM)、ChatGPT。
該研究使用以下 pipeline 來(lái)微調(diào) LLM(FLAN-T5 模型):首先向模型提供解析后的輸入,并對(duì)其進(jìn)行微調(diào)。請(qǐng)注意,與基線(xiàn)方法不同,ReALM 不會(huì)在 FLAN-T5 模型上運(yùn)行廣泛的超參數(shù)搜索,而是使用默認(rèn)的微調(diào)參數(shù)。對(duì)于由用戶(hù)查詢(xún)和相應(yīng)實(shí)體組成的每個(gè)數(shù)據(jù)點(diǎn),研究團(tuán)隊(duì)將其轉(zhuǎn)換為句子格式,然后將其提供給 LLM 進(jìn)行訓(xùn)練。
1.會(huì)話(huà)指代
在這項(xiàng)研究中,研究團(tuán)隊(duì)假設(shè)會(huì)話(huà)指代有兩種類(lèi)型:
- 基于類(lèi)型的;
- 描述性的。
基于類(lèi)型的指代嚴(yán)重依賴(lài)于將用戶(hù)查詢(xún)與實(shí)體類(lèi)型結(jié)合使用來(lái)識(shí)別(一組實(shí)體中)哪個(gè)實(shí)體與所討論的用戶(hù)查詢(xún)最相關(guān):例如,用戶(hù)說(shuō)「play this」,我們知道「this」指的是歌曲或電影等實(shí)體,而不是電話(huà)號(hào)碼或地址;「call him」則指的是電話(huà)號(hào)碼或聯(lián)系人,而不是鬧鐘。
描述性指代傾向于使用實(shí)體的屬性來(lái)唯一地標(biāo)識(shí)它:例如「時(shí)代廣場(chǎng)的那個(gè)」,這種指代可能有助于唯一地指代一組中的一個(gè)。
請(qǐng)注意,通常情況下,指代可能同時(shí)依賴(lài)類(lèi)型和描述來(lái)明確指代單個(gè)對(duì)象。蘋(píng)果的研究團(tuán)隊(duì)簡(jiǎn)單地對(duì)實(shí)體的類(lèi)型和各種屬性進(jìn)行了編碼。
2.屏幕指代
對(duì)于屏幕指代,研究團(tuán)隊(duì)假設(shè)存在能夠解析屏幕文本以提取實(shí)體的上游數(shù)據(jù)檢測(cè)器。然后,這些實(shí)體及其類(lèi)型、邊界框以及圍繞相關(guān)實(shí)體的非實(shí)體文本元素列表都可用。為了以?xún)H涉及文本的方式將這些實(shí)體(以及屏幕的相關(guān)部分)編碼到 LM 中,該研究采用了算法 2。

直觀地講,該研究假設(shè)所有實(shí)體及其周?chē)鷮?duì)象的位置由它們各自的邊界框的中心來(lái)表示,然后從上到下(即垂直、沿 y 軸)對(duì)這些中心(以及相關(guān)對(duì)象)進(jìn)行排序,并從左到右(即水平、沿 x 軸)使用穩(wěn)定排序。所有位于邊緣(margin)內(nèi)的對(duì)象都被視為在同一行上,并通過(guò)制表符將彼此分隔開(kāi);邊緣之外更下方的對(duì)象被放置在下一行,這個(gè)過(guò)程重復(fù)進(jìn)行,有效地從左到右、從上到下以純文本的方式對(duì)屏幕進(jìn)行編碼。
實(shí)驗(yàn)
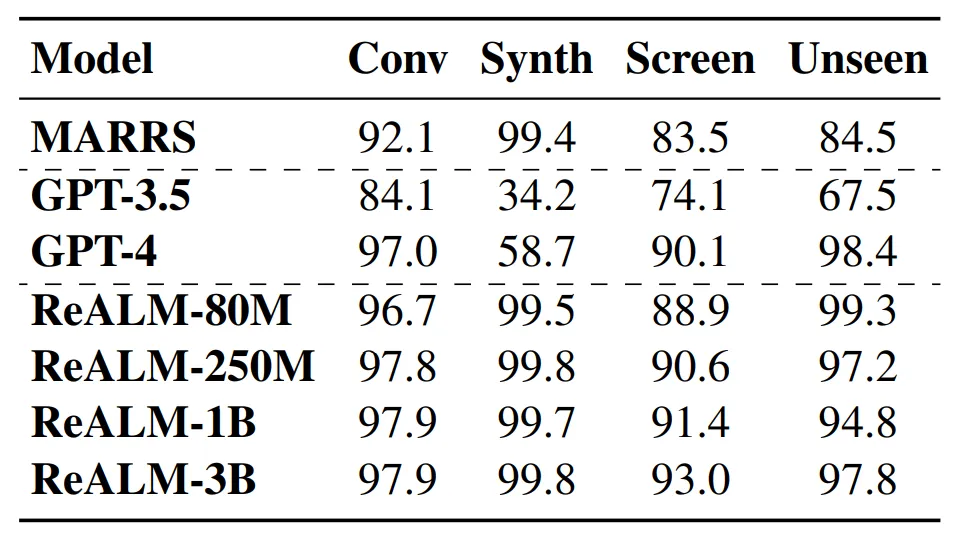
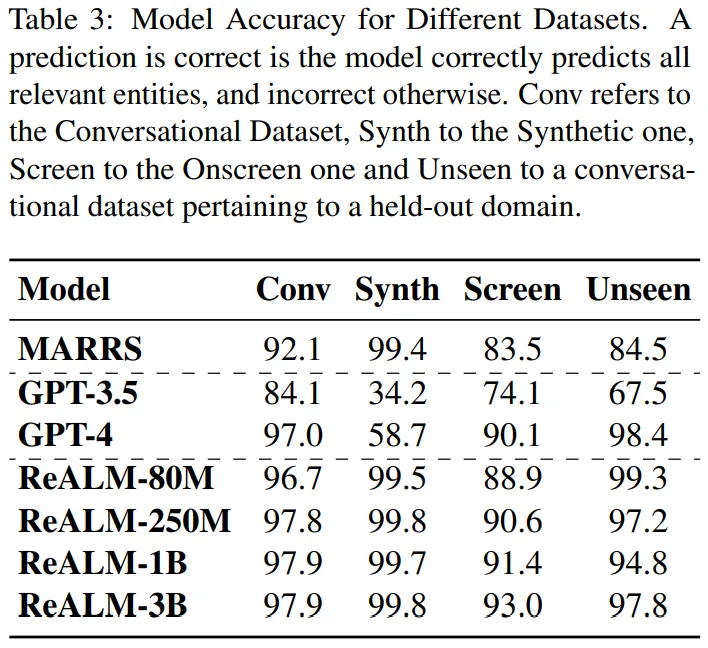
表 3 為實(shí)驗(yàn)結(jié)果:本文方法在所有類(lèi)型的數(shù)據(jù)集中都優(yōu)于 MARRS 模型。此外,研究者還發(fā)現(xiàn)該方法優(yōu)于 GPT-3.5,盡管后者的參數(shù)數(shù)量比 ReALM 模型多出幾個(gè)數(shù)量級(jí)。
在與 GPT-4 進(jìn)行對(duì)比時(shí),盡管 ReALM 更簡(jiǎn)潔,但其性能與最新的 GPT-4 大致相同。此外,本文特別強(qiáng)調(diào)了模型在屏幕數(shù)據(jù)集上的收益,并發(fā)現(xiàn)采用文本編碼的模型幾乎能夠與 GPT-4 一樣執(zhí)行任務(wù),盡管后者提供了屏幕截圖(screenshots)。最后,研究者還嘗試了不同尺寸的模型。
分析
GPT-4 ≈ ReaLM ? MARRS 用于新用例。作為案例研究,本文探討了模型在未見(jiàn)過(guò)領(lǐng)域上的零樣本性能:Alarms(附錄表 11 中顯示了一個(gè)樣本數(shù)據(jù)點(diǎn))。

表 3 結(jié)果表明,所有基于 LLM 的方法都優(yōu)于 FT 模型。本文還發(fā)現(xiàn) ReaLM 和 GPT-4 在未見(jiàn)過(guò)領(lǐng)域上的性能非常相似。
ReaLM > GPT-4 用于特定領(lǐng)域的查詢(xún)。由于對(duì)用戶(hù)請(qǐng)求進(jìn)行了微調(diào),ReaLM 能夠理解更多特定于領(lǐng)域的問(wèn)題。例如表 4 對(duì)于用戶(hù)請(qǐng)求,GPT-4 錯(cuò)誤地假設(shè)指代僅與設(shè)置有關(guān),而真實(shí)情況也包含后臺(tái)的家庭自動(dòng)化設(shè)備,并且 GPT-4 缺乏識(shí)別領(lǐng)域知識(shí)的能力。相比之下,ReaLM 由于接受了特定領(lǐng)域數(shù)據(jù)的訓(xùn)練,因此不會(huì)出現(xiàn)這種情況。






























