














http://www.jxzklqfsx.com/aigc/
背景
當今社會,人們使用大量數(shù)據(jù)訓練包含數(shù)百萬和數(shù)十億模型參數(shù)的大型語言模型(LLM),目標是生成文本,如文本完成、文本摘要、語言翻譯和回答問題。雖然LLM都是從給定的訓練數(shù)據(jù)源開始來開發(fā)知識庫本身,但是其中總有一個截止訓練日期的問題,這導致了LLM不會知道在以后的新日期內(nèi)的任何新生成的數(shù)據(jù)。
例如,訓練OpenAI的GPT-3.5-turbo-instruct LLM的截止日期為2021年9月(參考:https://platform.openai.com/docs/models/gpt-3-5-turbo);因此,GPT-3.5-turbo-instruct LLM可能無法準確回答與2022年、2023年或2024年中發(fā)生的事件有關的問題。這種不是LLM的原始訓練數(shù)據(jù)的部分數(shù)據(jù)被稱為外部數(shù)據(jù)。
正是在這種情況下出現(xiàn)了檢索增強生成(RAG)技術,這種技術能夠通過從授權的外部來源中檢索與輸入提示相關的適當信息,并能夠增強輸入,從而使LLM能夠生成準確和相關的響應。實際上,RAG形成了LLM和外部數(shù)據(jù)之間的一個網(wǎng)關。這種增強消除了對LLM模型進行再訓練或進一步微調(diào)的需要。
LLM的典型實現(xiàn)方案
LLM是自回歸的,基于標記為標記序列的輸入提示,從而生成新的標記。下一個最佳標記的生成是基于概率的,并且可以表示如下:
P( Yn∣X0, X1, ... Xn-1, θ )
本質(zhì)上,新生成的第n個標記Yn的概率取決于n-1個先前標記序列X和學習的模型參數(shù)θ的出現(xiàn)概率。這里應該注意的是,標記化的輸入序列X在生成下一個標記中起著至關重要的作用。此外,自注意機制補充了有效的自回歸,其中序列中的每個輸入標記通過關注和權衡序列中其他標記的重要性來計算其表示。
序列中的標記之間的這種復雜關系和依賴性也使LLM能夠破譯與輸入序列中的標記“很好地結合”的最可能的次優(yōu)標記。LLM將新的標記附加到先前的標記以形成新的輸入序列,并重復自回歸過程,直到滿足完成條件,例如達到最大標記計數(shù)。
這種自關注驅動的自回歸意味著,LLM主要依賴于輸入序列來生成次優(yōu)標記。只要輸入序列有助于通過自我關注來確定下一個最佳標記,LLM就會繼續(xù)處于“良性”循環(huán)中,從而產(chǎn)生連貫、可理解和相關的輸出。相反,如果提示輸入無助于確定下一個最佳標記,則LLM將開始依賴于模型參數(shù)。在這種情況下,如果模型已被訓練為包含足夠的輸入提示上下文的“知識”,則該模型可能成功生成下一個最佳標記。相反,如果提示輸入與LLM從未訓練過的“外部數(shù)據(jù)”有關,則模型可能會進入“惡性循環(huán)”,導致產(chǎn)生不連貫、不可理解且可能不相關的輸出。
當前人們已經(jīng)研究出多種技術來解決這個問題。提示工程就是其中之一,其目標是通過調(diào)整提示來增強上下文,從而使LLM能夠生成相關輸出,從而解決“缺失的上下文”。RAG則是另一種技術,其目標是通過以自動化的方式從外部數(shù)據(jù)源檢索與輸入提示相關的最合適的信息并增強提示,來專門解決“由于外部數(shù)據(jù)而丟失的上下文”。
RAG面臨的挑戰(zhàn)
RAG的主要職責是從外部數(shù)據(jù)源(如信息數(shù)據(jù)庫、API和維基百科等其他文檔庫)中搜索和檢索與輸入提示上下文相關的數(shù)據(jù)。一個簡單的關鍵詞搜索并不能解決這個問題。相反,RAG需要一個語義搜索。為了便于語義搜索,從外部來源檢索的文本信息被轉換為數(shù)字表示或向量,通常稱為文本嵌入,并存儲在向量數(shù)據(jù)庫中。已經(jīng)存在多種模型或算法,用于從文本創(chuàng)建這些嵌入。首先,提示被轉換為其向量表示,以搜索和檢索最匹配的外部數(shù)據(jù)向量。然后,計算提示向量和先前存儲的外部數(shù)據(jù)向量之間的向量相似性(或向量距離)。使用閾值對最相似或最接近的向量進行排序和過濾,并檢索它們對應的文本信息以增強提示的上下文。下面的概念圖展示了啟用RAG的不同組件之間的典型交互:
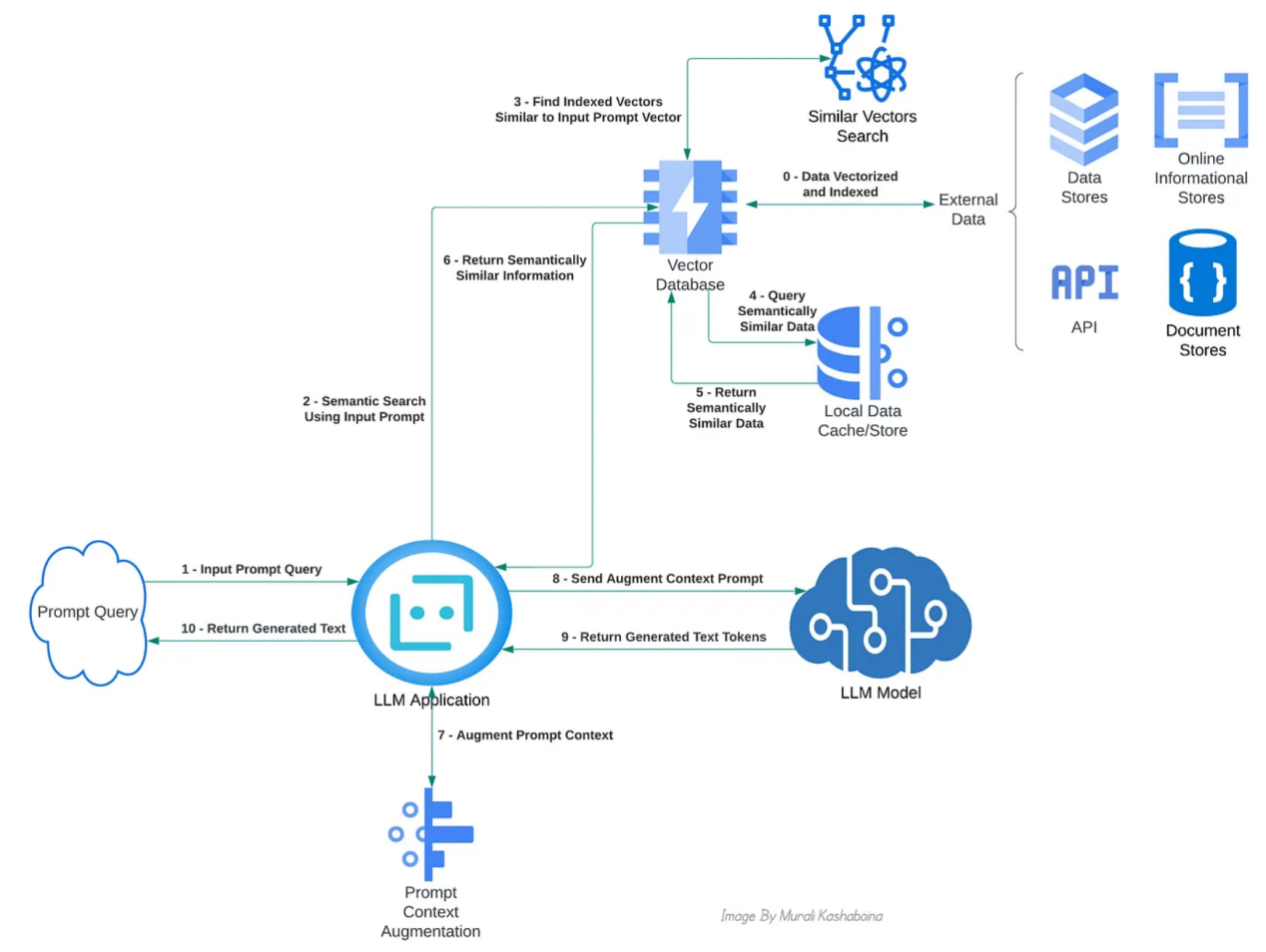
實現(xiàn)RAG的主要系統(tǒng)組件交互的概念視圖(作者本人圖片)
RAG面臨的挑戰(zhàn)是,進行向量驅動的語義搜索并不簡單,需要大量的計算資源,因為它涉及到針對數(shù)據(jù)庫中潛在的大量向量計算向量相似性或距離。對于每個輸入提示,從龐大的向量數(shù)據(jù)庫中計算每個存儲向量的相似性或距離指標將變得不可行。此外,語義匹配質(zhì)量越低,LLM的生成輸出質(zhì)量就越低。因此,找到一種有效地進行語義搜索的方法變得至關重要。
解決方案
當前,可以采用幾種算法解決方案來進行高效的語義搜索。這些算法的典型思路是,將外部數(shù)據(jù)向量分組或聚類為最近鄰居,并通過映射到這樣的聚類來對它們進行索引。大多數(shù)向量數(shù)據(jù)庫都提供這種索引作為內(nèi)置功能。在語義搜索期間,首先針對輸入提示向量來評估匹配的聚類。對于每個評估的簇,都會選擇索引向量。然后計算輸入提示向量和所選向量之間的相似性。這里的期望是,找到“最近的鄰居”作為中間步驟,可以顯著減少相似性計算的數(shù)量。最后,檢索與通過閾值濾波的最相似或最接近的向量相對應的文本信息。諸如k-最近鄰、半徑球-R、位置敏感哈希、DBSCAN聚類、類樹層次結構和類圖層次結構之類的算法通常由向量數(shù)據(jù)庫實現(xiàn),以便于語義搜索。
當然,不存在一刀切的解決方案,因為不同的算法族在內(nèi)存效率、計算效率、延遲、準確性、向量維度、數(shù)據(jù)集大小等方面有不同的權衡。例如,聚類方法通過縮小語義搜索的向量空間來提高速度,而類樹或類圖方法則提高了低維向量數(shù)據(jù)的準確性。
自組織映射
自組織映射(SOM)是芬蘭神經(jīng)網(wǎng)絡專家Teuvo Kohonen在20世紀80年代開發(fā)的一種基于神經(jīng)網(wǎng)絡的降維算法。它通常用于將高維特征向量減少為低維(通常是二維)特征向量。SOM背后的核心思想是,將高維數(shù)據(jù)向量表示為低維空間中的特定節(jié)點,同時保留向量在原始空間中的拓撲結構。低維空間中的節(jié)點數(shù)(SOM節(jié)點)是固定的(超參數(shù))。通過多個訓練時期來評估SOM節(jié)點的確切位置。迭代訓練的目標是調(diào)整低維空間中SOM節(jié)點的位置,以便將它們映射到高維特征空間中最近的相鄰向量。換言之,目標是將高維空間中的最近鄰向量映射到也是低維空間中最近鄰的SOM節(jié)點。
RAG的SOM
在這篇文章中,我想分享我用SOM作為一種可能的算法來推動RAG的語義搜索的實驗筆記和有關發(fā)現(xiàn)。與其他算法相比,SOM可能更為理想一些,這基于以下三個關鍵原因:
- 向量的高維度可能會成為大多數(shù)其他算法的瓶頸,如樹和圖,即所謂的維度詛咒。相反,SOM是為降維而構建的;因此,它可以有效地應用于高維和低維場景。
- SOM對可能滲入原始高維向量空間的隨機變化不太敏感,從而導致噪聲。其他算法可能對這種噪聲敏感,影響它們將高維向量聚類或分組為最近鄰的方式。由于SOM在低維向量空間中使用中間SOM節(jié)點,這些節(jié)點被評估為來自高維空間的映射向量的局部平均值,因此它有效地減少了噪聲。
- 外部數(shù)據(jù)集的大尺寸可能會約束其他算法來創(chuàng)建語義向量空間,這可能會影響語義匹配的延遲和準確性。另一方面,SOM可以處理海量數(shù)據(jù)集,因為低維空間中的SOM節(jié)點數(shù)量可以通過與底層數(shù)據(jù)集大小成比例的超參數(shù)進行微調(diào)。雖然使用大型數(shù)據(jù)集訓練SOM可能需要更長的時間,但一旦訓練完成,查詢時間映射仍然更快。
對此,我展示了一個簡單的例子。在這個例子中,使用SOM進行RAG的語義搜索,以使用OpenAI的GPT-3.5-turbo-instruct LLM來增加問答的上下文。使用OpenAI的GPT-3.5-turbo-instruct LLM的主要原因是,訓練OpenAI的GPT-3.5-turbo-instruct LLM的截止日期是2021年9月(參考:https://platform.openai.com/docs/models/gpt-3-5-turbo);因此,GPT-3.5-turbo-instruct LLM可能無法準確回答2022年、2023年或2024年發(fā)生的事件相關的問題。因此,關于2022年、2023年或2024年發(fā)生的事件的信息可以成為OpenAI的GPT-3.5-turbo-instruct LLM的“外部數(shù)據(jù)”。我使用維基百科API作為這種“外部數(shù)據(jù)”的來源來獲取事件的信息。以下展示我用來開發(fā)和訓練示例的步驟,以及示例代碼。
步驟1:基于PyTorch的Kohonen的SOM實現(xiàn)
示例中,我利用PyTorch張量來表示向量,并使用PyTorch實現(xiàn)了Kohonen的SOM。該算法使用了一個二維晶格,其大小變?yōu)槌瑓?shù)。該算法的數(shù)學方面是從精心設計的角度得出的,并在以下文章中進行了清晰的解釋:
下面的代碼片段顯示了Kohonen的SOM的Python類。完整的代碼可在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/kohonen_som.py)獲得。值得注意的是,這個實現(xiàn)是獨立的,所以它可以在RAG示例之外使用。
class KohonenSOM():
"""
該代碼是基于以下文章開發(fā)的:
http://www.ai-junkie.com/ann/som/som1.html
向量和矩陣運算是使用PyTorch張量進行的。
"""
def __init__( ... )
...
def find_topk_best_matching_units( self, data_points : torch.Tensor, topk : int = 1 ) -> List[ List[ int ] ] :
if len( data_points.size() ) == 1:
#batching
data_points = data_points.view( 1, data_points.shape[0] )
topk = int( topk )
distances = self.dist_evaluator( data_points, self.lattice_node_weights )
topk_best_matching_unit_indexes = torch.topk( distances, topk, dim=1, largest=False ).indices
topk_best_matching_units = []
for i in range( data_points.shape[0] ):
best_matching_unit_indexes = topk_best_matching_unit_indexes[i]
best_matching_units = [ self.lattice_coordinates[ bmu_index.item() ].tolist() for bmu_index in best_matching_unit_indexes ]
topk_best_matching_units.append( best_matching_units )
return topk_best_matching_units步驟2:基于SOM的向量索引器實現(xiàn)
向量索引器是一種實用程序,它使用Kohonen的SOM來使用外部數(shù)據(jù)集的數(shù)據(jù)向量訓練SOM節(jié)點。它的主要目的是將每個數(shù)據(jù)向量映射到最近的top-k SOM節(jié)點,從而實現(xiàn)數(shù)據(jù)向量的高效索引。下面的代碼片段顯示了向量索引器Python類的train和索引函數(shù)。它的完整代碼可在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/vector_indexer.py)獲得。盡管它的實現(xiàn)目前僅限于示例的需要,但它可以擴展以滿足其他要求。
class SOMBasedVectorIndexer():
...
def train_n_gen_indexes(
self, input_vectors : torch.Tensor,
train_epochs : int = 100
):
if self.generated_indexes:
print( "WARNING: Indexes were already generated. Ignoring the request..." )
return
self.som.train( input_vectors, train_epochs )
topk_bmu_indexes = self.som.find_topk_best_matching_units( input_vectors, topk = self.topk_bmu_for_indexing )
for idx in tqdm( range( len( topk_bmu_indexes ) ), desc="SOM-Based Indexed Vectors" ):
bmu_indexes = topk_bmu_indexes[ idx ]
for bmu_index in bmu_indexes:
bmu_index_key = tuple( bmu_index )
idx_set = self.som_node_idx_map.get( bmu_index_key, set() )
idx_set.add( idx )
self.som_node_idx_map[ bmu_index_key ] = idx_set
self.generated_indexes = True步驟3:基于OpenAI嵌入的文本到向量編碼器
編碼器的主要功能是使用OpenAI的文本嵌入API將文本轉換為向量表示。值得注意的是,使用嵌入API需要一個OpenAI帳戶和API密鑰。首次開立賬戶后,OpenAI提供補充信貸,足以訪問API進行測試。下面是一個代碼片段,展示了OpenAI編碼器Python類的批處理編碼功能。完整的代碼也可在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/openai_vector_encoder.py)獲得。
import openai
from openai.embeddings_utils import get_embedding
...
from vector_encoder_parent import VectorEncoder
...
class OpenAIEmbeddingsVectorEncoder( VectorEncoder ):
def __init__( ... )
...
def encode_batch( self, list_of_text : List[ str ] ) -> torch.Tensor :
if list_of_text == None or len( list_of_text ) == 0:
raise ValueError( "ERROR: Required list_of_text is None or empty" )
list_of_text = [ str( text ) for text in list_of_text ]
openai.api_key = self.openai_key
response = openai.Embedding.create(
input = list_of_text,
engine = self.vector_encoder_id
)
embeddings = [ data["embedding"] for data in response["data"] ]
vectors = torch.tensor( embeddings, dtype=torch.float )
return vectors請注意,OpenAI向量編碼器類擴展了一個通用父類“VectorEncoder”,該類定義了要通過繼承實現(xiàn)的抽象編碼函數(shù)。通過從這個父類繼承其他編碼方案的可插入性,可以實現(xiàn)其他類型的向量編碼器。父向量編碼器類的完整代碼可以在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/vector_encoder_parent.py)找到。
步驟4:Wikipedia API驅動的數(shù)據(jù)源實現(xiàn)
該實用程序類旨在封裝與Wikipedia API集成的數(shù)據(jù)檢索邏輯。它的主要功能是獲取一個指定的日歷年數(shù)組中的事件,格式化檢索到的事件,并將它們加載到Pandas數(shù)據(jù)幀中。下面的代碼片段捕獲了實用程序類的主要函數(shù),完整的代碼也可在同上一致的GitHub位置獲得。
import requests
import pandas as pd
from dateutil.parser import parse
...
class WikiEventsDataSource():
...
def fetch_n_prepare_data( self ):
if self.fetched:
print( "WARNING: Wiki events for the specified years already fetched. Ignoring the request..." )
return
main_df = pd.DataFrame()
for year in self.event_years_to_fetch:
wiki_api_params = {
"action": "query",
"prop": "extracts",
"exlimit": 1,
"titles": year,
"explaintext": 1,
"formatversion": 2,
"format": "json"
}
response = requests.get( "https://en.wikipedia.org/w/api.php", params=wiki_api_params )
response_dict = response.json()
df = pd.DataFrame()
df[ "text" ] = response_dict["query"]["pages"][0]["extract"].split("\n")
df = self.__clean_df__( df, year )
main_df = pd.concat( [ main_df, df ] )
self.df = main_df.reset_index(drop=True)
self.fetched = True步驟5:基于SOM的RAG實用程序實現(xiàn)
基于SOM的RAG實用程序是示例實現(xiàn)的關鍵環(huán)節(jié)。它利用向量編碼器、索引器和數(shù)據(jù)源來實現(xiàn)底層語義搜索的核心邏輯。基于SOM的RAG實用程序的完整代碼可在同上一致的GitHub位置獲得。
該實用程序實現(xiàn)三個主要函數(shù)。第一個函數(shù)是從外部數(shù)據(jù)源加載數(shù)據(jù),并將其編碼為向量,如下面的代碼片段所示。
...
from vector_encoder_parent import VectorEncoder
from vector_indexer import SOMBasedVectorIndexer
class SOM_Based_RAG_Util():
...
def load_n_vectorize_data( self, data_source ):
if self.data_loaded_n_vectorized:
print( "WARNING: Data already loaded and vectorized. Ignoring the request..." )
return
data_source.fetch_n_prepare_data()
self.df = data_source.get_data()
vectors = None
for i in tqdm( range(0, len(self.df), self.vectorize_batch_size ), desc="Vectorized Data Batch" ):
list_of_text = self.df.iloc[ i:i+self.vectorize_batch_size ]["text"].tolist()
batch_encoded_vectors = self.vector_encoder.encode_batch( list_of_text )
if vectors == None:
vectors = batch_encoded_vectors
else:
vectors = torch.cat( [ vectors, batch_encoded_vectors], dim=0 )
self.vectors = vectors.to( self.device )
self.data_loaded_n_vectorized = True第二個函數(shù)是訓練基于SOM的索引器來構造Kohonen的SOM節(jié)點,然后對數(shù)據(jù)向量進行索引,如下面的代碼片段所示。
def train_n_index_data_vectors( self, train_epochs : int = 100 ):
if not self.data_loaded_n_vectorized:
raise ValueError( "ERROR: Data not loaded and vectorized." )
if self.data_vectors_indexed:
print( "WARNING: Data vectors already indexed. Ignoring the request..." )
return
self.vector_indexer.train_n_gen_indexes( self.vectors, train_epochs )
self.data_vectors_indexed = True第三個函數(shù)是基于查詢文本從先前存儲的外部數(shù)據(jù)集中查找類似信息。此函數(shù)使用編碼器將查詢文本轉換為向量,然后在基于SOM的索引器中搜索最可能的匹配項。然后,該函數(shù)使用余弦相似性或另一個指定的相似性評估器來計算查詢向量和所發(fā)現(xiàn)的數(shù)據(jù)向量之間的相似性。最后,該函數(shù)對相似度大于或等于指定相似度閾值的數(shù)據(jù)向量進行濾波。下面的代碼片段捕獲了函數(shù)實現(xiàn)。
def find_semantically_similar_data( self, query: str, sim_evaluator = None, sim_threshold : float = 0.8 ):
if not self.data_vectors_indexed:
raise ValueError( "ERROR: Data vectors not indexed." )
if query == None or len( query.strip() ) == 0:
raise ValueError( "ERROR: Required query text is not specified." )
sim_threshold = float( sim_threshold )
if sim_evaluator == None:
sim_evaluator = nn.CosineSimilarity(dim=0, eps=1e-6)
query_vector = self.vector_encoder.encode( query )
query_vector = query_vector.view( self.vector_encoder.get_encoded_vector_dimensions() )
query_vector = query_vector.to( self.device )
nearest_indexes = self.vector_indexer.find_nearest_indexes( query_vector )
nearest_indexes = nearest_indexes[0]
sim_scores = []
for idx in nearest_indexes:
data_vector = self.vectors[ idx ]
data_vector = data_vector.view( self.vector_encoder.get_encoded_vector_dimensions() )
sim_score = sim_evaluator( query_vector, data_vector )
if sim_score >= sim_threshold:
sim_score_tuple = (idx, sim_score.item() )
sim_scores.append( sim_score_tuple )
sim_scores.sort( key = lambda x: x[1], reverse=True )
semantically_similar_data = [
{
'text': self.df[ 'text' ][ idx ],
'sim_score' : sim_score
} for idx, sim_score in sim_scores
]
return semantically_similar_data基于SOM的RAG實用函數(shù)的語義搜索的示例輸出如下所示:

一個示例語義搜索輸出(作者本人圖像)
步驟6:抽象問答/聊天機器人及其基于OpenAI的實現(xiàn)
我開發(fā)了一個抽象的“QuestionAnswerChatBot”Python類,以便加快類聊天機器人的實現(xiàn)。這個類通過使用標準指令模板并使用從RAG實用程序檢索到的上下文相似信息來填充提示問題。
指定的新標記的最大數(shù)量限制了上下文增強的文本大小,而標記計數(shù)則推遲到底層實現(xiàn)。在LLM經(jīng)濟學中,標記就像貨幣。模型處理的每個標記都需要計算資源——內(nèi)存、處理能力和時間。因此,LLM必須處理的標記越多,計算成本就越大。
最后,一旦提供了QA指令,這個類就將LLM模型的提示委托給底層實現(xiàn)。下面的代碼片段給出了關鍵部分的函數(shù)實現(xiàn)代碼;完整的代碼可在同上面代碼相同的GitHub位置獲得。
from abc import ABC, abstractmethod
import torch
import math
class QuestionAnswerChatBot( ABC ):
...
def find_answer_to_question( self, question : str, sim_threshold = 0.68, max_new_tokens : int = 5 ):
if question == None or len( question.strip() ) == 0:
raise ValueError( "ERROR: Required question is not specified" )
sim_threshold = float( sim_threshold )
max_new_tokens = int( max_new_tokens )
qa_instruction = self.get_qa_instruction( question, sim_threshold = sim_threshold )
answer_text = self.__get_answer_text__( qa_instruction, max_new_tokens = max_new_tokens )
answer_text = self.__clean_answer_text__( qa_instruction, answer_text )
return answer_text
...
def __qa_template__( self ):
qa_template = """Context:
{}
---
Question: {}
Answer:"""
return qa_templatePython類“OpenAIQuestionAnswerChatBot”擴展了抽象類“QuestionAnnswerChatbot”,并使用OpenAI LLM API實現(xiàn)聊天機器人功能。下面的代碼片段顯示了該類的關鍵函數(shù)代碼。完整的代碼也可在上面GitHub位置獲得。
import openai
import tiktoken
from qa_chatbot import QuestionAnswerChatBot
class OpenAIQuestionAnswerChatBot( QuestionAnswerChatBot ):
...
def __get_answer_text__( self, qa_instruction : str, max_new_tokens : int = 5 ) -> str :
openai.api_key = self.openai_key
basic_answer = openai.Completion.create(
model = self.openai_model_name,
prompt = qa_instruction,
)
answer_text = basic_answer[ "choices" ][0][ "text" ]
return answer_text
def __token_count__( self, text : str ):
return len( self.tokenizer.encode( text ) )以下是如何使用通過語義搜索檢索到的類似信息來增強提示問題的上下文的示例:
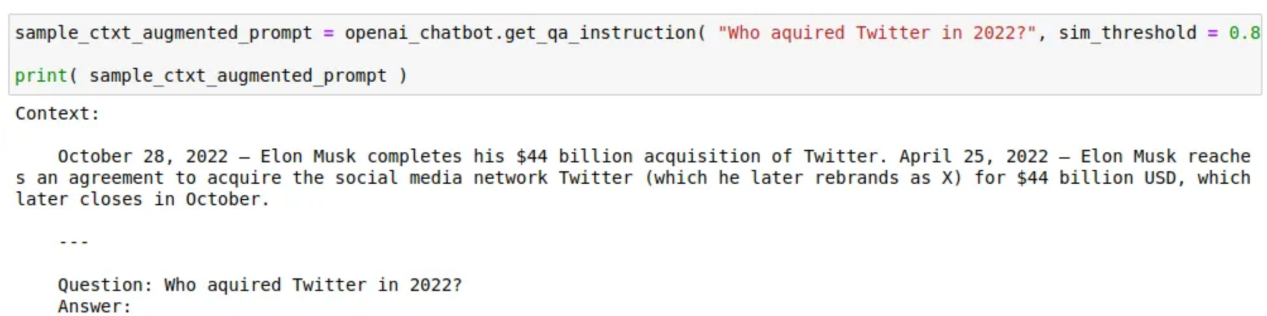
一個樣本版本的上下文增強的問題提示(作者圖片)
步驟7:測試中使用的示例問題
以下是使用OpenAI的GPT-3.5-turbo-instruct LLM測試RAG的示例問題。指定這些示例的目的,是為了確保它們的答案與2022年、2023年和2024年發(fā)生的事件有關。
sample_questions = [
"Who won the 2022 soccer world cup?",
"When did Sweden join NATO?",
"Who joined NATO in 2023?",
"Who joined NATO in 2024?",
"Which is the 31st member of NATO?",
"Which is the 32nd member of NATO?",
"Who won the Cricket World Cup in 2023?",
"Who defeated India in Cricket World Cup final in 2023?",
"Name the former prime minister of Japan that was assassinated in 2022?",
"When did Chandrayaan-3 land near the south pole of the Moon?",
"Where did Chandrayaan-3 land on the Moon?",
"Who acquired Twitter in 2022?",
"Who owns Twitter?",
"Who acquired Activision Blizzard in 2023?"
]第8步:把所有內(nèi)容組合起來
將所有組件整合在一起的完整Jupyter筆記本可以在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/OpenAI_Based_SOM_GPT2_Bot.ipynb)找到。以下代碼片段顯示了主要的基于OpenAI的QA聊天機器人的啟動過程。請注意,OpenAI的文本嵌入算法“text-embedding-ada-002”用于向量編碼。同樣,聊天機器人使用OpenAI的標記器“cl100k_base”來計數(shù)標記,以限制上下文文本,從而通過利用TikToken Python庫的內(nèi)置功能來增強問題提示。
openai_vector_encoder_id = "text-embedding-ada-002"
openai_encoded_vector_dimensions = 1536
openai_tokenizer_name = "cl100k_base"
openai_model_name = "gpt-3.5-turbo-instruct"
vector_encoder = OpenAIEmbeddingsVectorEncoder( openai_encoded_vector_dimensions, openai_vector_encoder_id, openai_key )
event_years_to_fetch = [ 2022, 2023, 2024 ]
data_source = WikiEventsDataSource( event_years_to_fetch )
...
som_driven_rag_util = SOM_Based_RAG_Util(
vector_encoder = vector_encoder,
som_lattice_height = 20,
som_lattice_width = 30,
learning_rate = 0.3,
topk_bmu_for_indexing = 10,
device = device
)
...
openai_chatbot = OpenAIQuestionAnswerChatBot(
vector_db_util = som_driven_rag_util,
openai_tokenizer_name = openai_tokenizer_name,
openai_model_name = openai_model_name,
openai_key = openai_key,
question_input_max_token_count = 100,
context_trim_percent = 0.1,
device = device
)以下序列圖有助于可視化初始化和實際問答階段的所有組件交互。
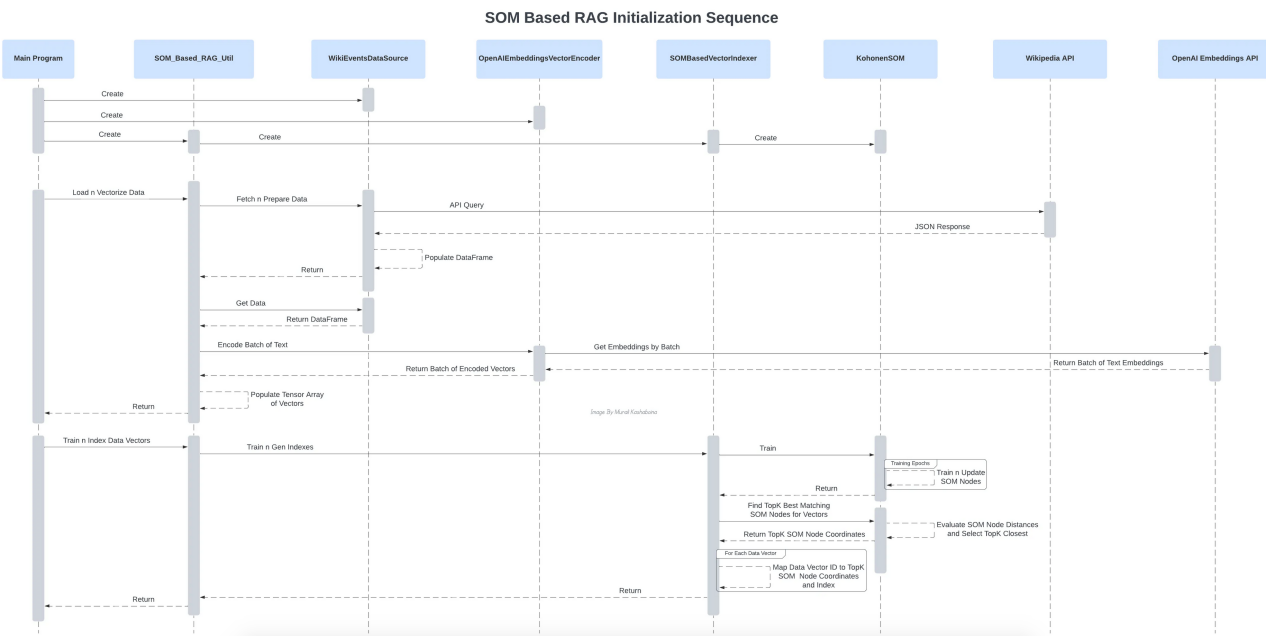
初始化過程中各種組件的相互作用(作者本人圖片)
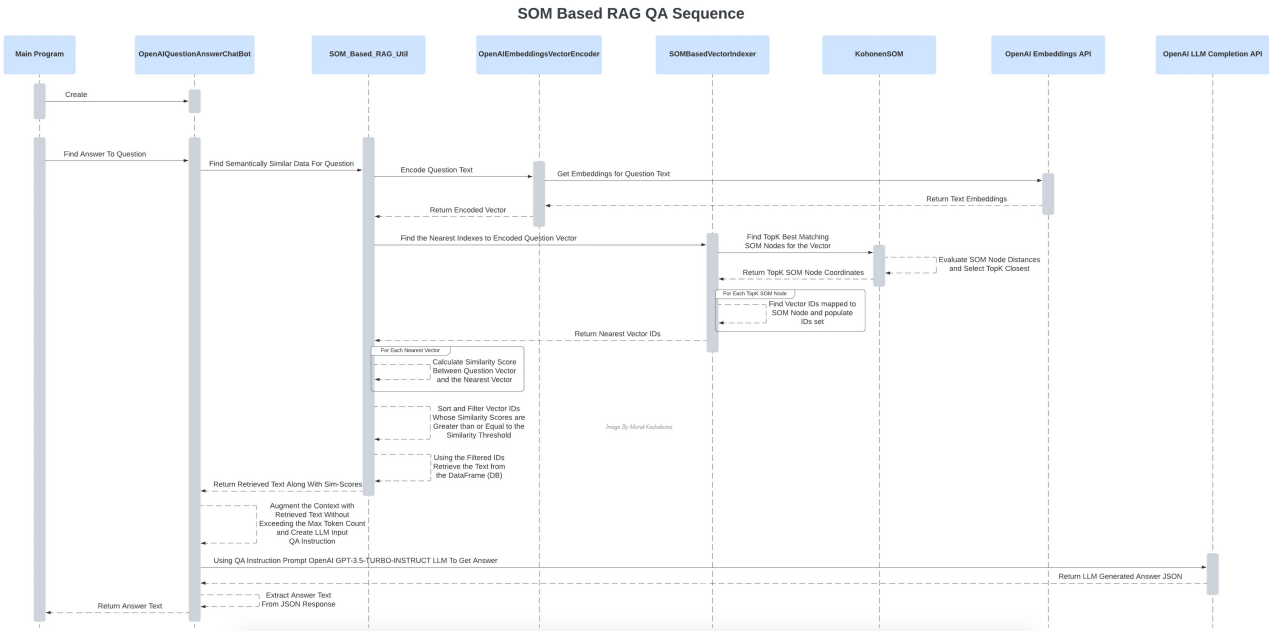
問答過程中各種組件的相互作用(作者本人圖片)
調(diào)查結果
下圖展示了OpenAI的GPT-3.5-turbo-instruct LLM中的問題/答案,分別相應于包括上下文增強和不包括上下文增強的情形。

OpenAI的GPT-3.5-turbo-instruct LLM在有和沒有上下文增強的情況下給出的答案(作者本人圖片)
可以理解的是,LLM發(fā)現(xiàn)回答有關2021年9月截止日期后發(fā)生的事件的問題很有挑戰(zhàn)性。在大多數(shù)情況下,它清楚地回答說,這些問題來自與其訓練截止日期相關的未來時間。相反,當提示問題的上下文被從維基百科檢索到的2022年、2023年和2024年的相關信息所擴充時,相同的LLM準確地完美地回答了所有問題。這里真正值得稱贊的是SOM,它構成了RAG語義搜索的基礎,以檢索并用相關信息增強提示問題的上下文。
下一步行動建議
雖然上述例子是評估自組織圖是否適合LLM進行文本檢索增強生成的概念驗證,但與使用更大外部數(shù)據(jù)集的其他算法相比,建議使用更全面的基準測試來評估其性能,其中性能是根據(jù)LLM輸出的質(zhì)量來衡量的(有點像困惑+準確性)。此外,由于當前示例支持可插入框架,因此建議使用其他開源和免費的QA LLM來進行此類基準測試,以最大限度地減少LLM的使用費用。
為了幫助在本地環(huán)境中運行該示例,我示例中包含了一個“requirements.txt”文件,其中包含我在環(huán)境中用于運行和測試上述示例的各種版本的Python庫。此文件可在GitHub(https://github.com/kbmurali/som-driven-qa-rag/blob/main/requirements.txt)找到。
參考文獻
- 《SOM教程1》,簡明英語神經(jīng)網(wǎng)絡教程:www.ai-junkie.com
- 《用Python代碼理解自組織映射神經(jīng)網(wǎng)絡》,通過競爭、合作和適應實現(xiàn)大腦啟發(fā)的無監(jiān)督機器學習:https://towardsdatascience.com/understanding-self-organising-map-neural-network-with-python-code-7a77f501e985?source=post_page-----5d739ce21e9c--------------------------------
- 《知識密集型NLP任務的檢索增強生成》,大型預先訓練的語言模型已被證明可以將事實知識存儲在其參數(shù)中與具體實現(xiàn):https://arxiv.org/abs/2005.11401?source=post_page-----5d739ce21e9c--------------------------------
- 《什么是檢索增強生成(RAG)?》,檢索增強生成(RAG)是一種提高生成人工智能模型準確性和可靠性的技術:https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/?source=post_page-----5d739ce21e9c--------------------------------
- https://www.sciencedirect.com/topics/engineering/self-organizing-map
- https://platform.openai.com/docs/models/gpt-3-5-turbo
- https://platform.openai.com/docs/guides/text-generation/chat-completions-api
譯者介紹
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Using Self-Organizing Map To Bolster Retrieval-Augmented Generation In Large Language Models,作者:Murali Kashaboina
鏈接:https://towardsdatascience.com/using-self-organizing-map-to-bolster-retrieval-augmented-generation-in-large-language-models-5d739ce21e9c。





























