像生物網(wǎng)絡(luò)一樣「生長」,具備「結(jié)構(gòu)可塑性」的自組織神經(jīng)網(wǎng)絡(luò)來了
生物神經(jīng)網(wǎng)絡(luò)有一個重要的特點是高度可塑性,這使得自然生物體具有卓越的適應(yīng)性,并且這種能力會影響神經(jīng)系統(tǒng)的突觸強度和拓?fù)浣Y(jié)構(gòu)。
然而,人工神經(jīng)網(wǎng)絡(luò)主要被設(shè)計為靜態(tài)的、完全連接的結(jié)構(gòu),在面對不斷變化的環(huán)境和新的輸入時可能非常脆弱。盡管研究人員對在線學(xué)習(xí)和元學(xué)習(xí)進行了大量研究,但目前最先進的神經(jīng)網(wǎng)絡(luò)系統(tǒng)仍然使用離線學(xué)習(xí),因為這與反向傳播結(jié)合使用時更加簡單。
那么,人工神經(jīng)網(wǎng)絡(luò)是否也能擁有類似于高度可塑性的性質(zhì)?
來自哥本哈根信息技術(shù)大學(xué)的研究團隊提出了一種自組織神經(jīng)網(wǎng)絡(luò) ——LNDP,能夠以活動和獎勵依賴的方式實現(xiàn)突觸和結(jié)構(gòu)的可塑性。

- 論文鏈接:https://arxiv.org/pdf/2406.09787
- 項目鏈接:https://github.com/erwanplantec/LNDP
研究簡介
2023 年,Najarro 等人提出了神經(jīng)發(fā)育程序(NDP)模型。但 NDP 在時間上限制在環(huán)境前期階段。因此,哥本哈根信息技術(shù)大學(xué)的研究團隊通過擴展 NDP 框架來解決這一限制。
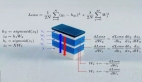
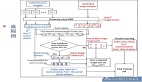
具體而言,研究團隊提出了一種在智能體生命周期內(nèi)能夠?qū)崿F(xiàn)可塑性和結(jié)構(gòu)變化的機制 ——LNDP(Lifelong Neural Developmental programs)。該機制通過執(zhí)行局部計算來實現(xiàn),依賴于人工神經(jīng)網(wǎng)絡(luò)中每個神經(jīng)元的局部活動和環(huán)境的全局獎勵函數(shù)。LNDP 使得人工神經(jīng)網(wǎng)絡(luò)具備可塑性,并橋接了間接發(fā)育編碼(indirect developmental encoding)和元學(xué)習(xí)的可塑性規(guī)則。
LNDP 由一組參數(shù)化組件組成,旨在定義神經(jīng)和突觸動態(tài),并使人工神經(jīng)網(wǎng)絡(luò)具有結(jié)構(gòu)可塑性(即突觸可以動態(tài)添加或移除)。

受生物自發(fā)性活動(spontaneous activity,SA)的啟發(fā),研究團隊進一步擴展了系統(tǒng),引入了一種可實現(xiàn)預(yù)經(jīng)驗(pre-experience)發(fā)展的機制,用感覺神經(jīng)元的簡單可學(xué)習(xí)隨機過程建模 SA,這使得一些組件可以復(fù)用。
研究團隊基于 Graph Transformer 層(Dwivedi and Bresson, 2021)提出了一種 LNDP 實例,并在一組強化學(xué)習(xí)任務(wù)中使用協(xié)方差矩陣自適應(yīng)進化策略(CMA-ES)優(yōu)化了 LNDP。

具體來說,該研究采用了三個經(jīng)典控制任務(wù)(Cartpole、Acrobot、Pendulum)以及一個具有非平穩(wěn)動態(tài)的搜集任務(wù)(Foraging),這些任務(wù)需要智能體具備生命周期適應(yīng)性。
總的來說,研究團隊展示了從隨機連接(或空)神經(jīng)網(wǎng)絡(luò)開始, LNDP 以活動和經(jīng)驗依賴的方式,自組織地形成了功能性網(wǎng)絡(luò),以有效解決控制性任務(wù)。
該研究還表明,在需要快速適應(yīng)或具有非平穩(wěn)動態(tài)、需要持續(xù)適應(yīng)的環(huán)境中,結(jié)構(gòu)可塑性能夠改善結(jié)果。此外,該研究還展示了基于預(yù)環(huán)境自發(fā)性活動驅(qū)動的發(fā)展階段在網(wǎng)絡(luò)自組織形成功能單元方面的有效性。
實驗結(jié)果
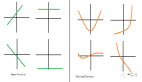
研究團隊在所有任務(wù)上測試了 SP 模型(具有結(jié)構(gòu)可塑性的模型)和非 SP 模型(無結(jié)構(gòu)可塑性的模型)之間的差異,結(jié)果如下圖 2 所示。

在具有非平穩(wěn)動態(tài)的搜集任務(wù)(Foraging)上,研究團隊發(fā)現(xiàn) SP 模型始終比非 SP 模型達(dá)到更高的平均適應(yīng)度,并且兩者達(dá)到相似的最大適應(yīng)度。這表明 SP 在非平穩(wěn)情況下具有更好的適應(yīng)性。

在 CartPole 環(huán)境中,對于沒有 SA 的模型來說,在最開始就達(dá)到良好性能特別困難,而具有 SA 的模型在最初就顯示出解決任務(wù)的固有技能。這展示出模型在非獎勵依賴和自組織的方式下實現(xiàn)目標(biāo)功能網(wǎng)絡(luò)的能力。


更多研究細(xì)節(jié),請參考原論文。