













告別傳統(tǒng)單目視覺!Depth Anything v2超越10倍的精確深度估計!
在單目深度估計研究中,廣泛使用的標(biāo)記真實圖像具有很多局限性,因此需要借助合成圖像來確保精度。為了解決合成圖像引起的泛化問題,作者團(tuán)隊采用了數(shù)據(jù)驅(qū)動(大規(guī)模偽標(biāo)記真實圖像)和模型驅(qū)動(擴(kuò)大教師模型)的策略。同時在一個現(xiàn)實世界的應(yīng)用場景中,展示了未標(biāo)記真實圖像的不可或缺的作用,證明“精確合成數(shù)據(jù)+偽標(biāo)記真實數(shù)據(jù)”比標(biāo)記的真實數(shù)據(jù)更有前景。最后,研究團(tuán)隊將可轉(zhuǎn)移經(jīng)驗從教師模型中提煉到更小的模型中,這類似于知識蒸餾的核心精神,證明了偽標(biāo)簽蒸餾更加容易和安全。
01 摘要
這項工作展示了Depth Anything V2, 在不追求技巧的情況下,該項研究的目標(biāo)是為建立一個強(qiáng)大的單目深度估計模型奠定基礎(chǔ)。值得注意的是,與V1相比,這個版本通過三個關(guān)鍵實踐產(chǎn)生了更精細(xì),更強(qiáng)大的深度預(yù)測:
●用合成圖像替換所有標(biāo)記的真實圖像;
●擴(kuò)大教師模型的能力;
●通過大規(guī)模偽標(biāo)記真實圖像的橋梁教授學(xué)生模型。
與建立在Stable Diffusion上最新的模型相比,Depth Anything v2的模型效率更高更準(zhǔn)確。作者提供不同規(guī)模的模型(從25M到1.3B參數(shù)),以支持廣泛的場景。得益于強(qiáng)大的泛化能力,研究團(tuán)隊使用度量標(biāo)簽對模型進(jìn)行微調(diào),以獲得度量深度模型。除了模型本身之外,考慮到當(dāng)前測試集的有限多樣性和頻繁的噪聲,研究團(tuán)隊構(gòu)建了一個具有精確注釋和多樣化場景的多功能評估基準(zhǔn),以方便未來的研究。
02 工作概述
單目深度估計(Monocular Depth Estimation,MDE)因其在廣泛的下游任務(wù)中的重要作用而受到越來越多的關(guān)注。精確的深度信息不僅在經(jīng)典應(yīng)用中是有利的,例如3D重建,導(dǎo)航和自動駕駛,而且在其他生成場景中也是可應(yīng)用的。
從模型建構(gòu)方面來看,已有的MDE模型可以分為兩類,一類基于判別模型,另一類基于生成模型,從圖1的比較結(jié)果,Depthing Anything是更高效輕巧的。根據(jù)表1可得,Depth Anything V2可以實現(xiàn)復(fù)雜場景的可靠預(yù)測,包括且不局限于復(fù)雜布局、透明對象、反射表面等;在預(yù)測的深度圖中包含精細(xì)的細(xì)節(jié),包括但不限于薄物體、小孔等;提供不同的模型規(guī)模和推理效率,以支持廣泛的應(yīng)用;具有足夠的可推廣性,可以轉(zhuǎn)移到下游任務(wù)。從Depth Anything v1出發(fā),研究團(tuán)隊推出v2,認(rèn)為最關(guān)鍵的部分仍然是數(shù)據(jù),它利用大規(guī)模未標(biāo)記的數(shù)據(jù)來加速數(shù)據(jù)擴(kuò)展并增加數(shù)據(jù)覆蓋率。研究團(tuán)隊進(jìn)一步構(gòu)建了一個具有精確注釋和多樣化場景的多功能評估基準(zhǔn)。
 ▲圖1|Depthing Anything v2與其他模型比較??【深藍(lán)AI】編譯
▲圖1|Depthing Anything v2與其他模型比較??【深藍(lán)AI】編譯

▲表1|強(qiáng)大的單目深度估計模型的優(yōu)選特性??【深藍(lán)AI】編譯
重新審視Depth Anything V1標(biāo)記數(shù)據(jù)的設(shè)計,如此大量的標(biāo)記圖像真的有利嗎?真實標(biāo)記的數(shù)據(jù)有2個缺點(diǎn):一個是標(biāo)簽噪聲,即深度圖中的標(biāo)簽不準(zhǔn)確。由于各種收集程序固有的局限性,真實標(biāo)記數(shù)據(jù)不可避免地包含不準(zhǔn)確的估計,例如無法捕捉透明物體的深度,立體匹配算法以及SFM算法在處理動態(tài)物體或異常值時受到的影響。另一個是細(xì)節(jié)忽略,一些真實數(shù)據(jù)通常會忽略深度圖中的某些細(xì)節(jié),例如樹和椅子的深度往往表示非常粗糙。為了克服這些問題,研究者決定改變訓(xùn)練數(shù)據(jù),尋找具有最好注釋的圖像,專門利用具有深度信息的合成圖像進(jìn)行訓(xùn)練,廣泛檢查合成圖像的標(biāo)簽質(zhì)量。
合成圖像具有以下優(yōu)勢:
●所有精細(xì)細(xì)節(jié)都會得到正確標(biāo)記,如圖2所示;
●可以獲得具有挑戰(zhàn)性的透明物體和反射表面的實際深度,如圖2中的花瓶。
 ▲圖2|合成數(shù)據(jù)的深度??【深藍(lán)AI】編譯
▲圖2|合成數(shù)據(jù)的深度??【深藍(lán)AI】編譯
但是合成數(shù)據(jù)仍然也具有以下局限性:
●合成圖像與真實圖像之間存在分布偏差。盡管當(dāng)前的圖像引擎力求達(dá)到照片級逼真的效果,但其風(fēng)格和顏色分布與真實圖像仍存在明顯差異。合成圖像的顏色過于“干凈”,布局過于“有序”,而真實圖像則包含更多隨機(jī)性;
●合成圖像的場景覆蓋范圍有限。它們是從具有預(yù)定義固定場景類型的圖形引擎迭代采樣的,例如“客廳”和“街景”。
因此在MDE中,從合成圖像到真實圖像的遷移并非易事。為了緩解泛化問題,一些工作使用真實圖像和合成圖像的組合訓(xùn)練集,但是真實圖像的粗深度圖對細(xì)粒度預(yù)測具有破壞性。另一個潛在的解決方案是收集更多的合成圖像,但是這是不可持續(xù)的。因此,在本文中,研究者提出一個路線圖可以在不進(jìn)行任何權(quán)衡的情況下解決精確性和魯棒性困境,并且適用于任何模型規(guī)模。
 ▲圖3|對不同視覺編碼器在合成到真實轉(zhuǎn)換方面的定性比較??【深藍(lán)AI】編譯
▲圖3|對不同視覺編碼器在合成到真實轉(zhuǎn)換方面的定性比較??【深藍(lán)AI】編譯
研究團(tuán)隊提出的解決方案是整合未標(biāo)記的真實圖像。團(tuán)隊最強(qiáng)大的MDE模型基于DINOV2-G,最初僅使用高質(zhì)量合成圖像進(jìn)行訓(xùn)練,然后它在未標(biāo)記的真實圖像上分配偽深度標(biāo)簽,最后僅使用大規(guī)模且精確的偽標(biāo)記圖像進(jìn)行訓(xùn)練。Depth Anything v1凸顯了大規(guī)模無標(biāo)記真實數(shù)據(jù)的重要性。針對合成標(biāo)記圖像的缺點(diǎn),闡述整合未標(biāo)記真實圖像的作用:
●彌補(bǔ)差距:由于分布偏移,直接從合成訓(xùn)練圖像轉(zhuǎn)移到真實測試圖像具有挑戰(zhàn)性。但是如果可以利用額外的真實圖像作為中間學(xué)習(xí)目標(biāo),這個過程將更加可靠。直觀地講,在對偽標(biāo)記真實圖像進(jìn)行明確訓(xùn)練后,模型可以更熟悉真實世界的數(shù)據(jù)分布。與手動注釋的圖像相比,自動生成的偽標(biāo)簽細(xì)粒度和完整度更高。
●增強(qiáng)場景覆蓋率:合成圖像的多樣性有限,沒有包含足夠的真實場景。然而可以通過合并來自公共數(shù)據(jù)集的大規(guī)模未標(biāo)記圖像輕松覆蓋大量不同的場景。此外,由于合成圖像是從預(yù)定義視頻中重復(fù)采樣的,因此確實非常冗余。相比之下,未標(biāo)記的真實圖像清晰可辨,信息量豐富。通過在足夠的圖像和場景上訓(xùn)練,模型不僅表現(xiàn)出更強(qiáng)的零樣本MDE能力,而且還可以作為下游相關(guān)任務(wù)更好的訓(xùn)練源。
●將經(jīng)驗從最強(qiáng)大的模型轉(zhuǎn)移到較小的模型:如圖5所示,較小的模型本身無法直接從合成到真實的遷移中受益。然而,有了大規(guī)模未標(biāo)記的真實圖像,可以學(xué)習(xí)模仿更強(qiáng)大的模型的高質(zhì)量預(yù)測,類似于知識蒸餾。
03 關(guān)鍵技術(shù)
 ▲圖4|Depth Anything v2??【深藍(lán)AI】編譯
▲圖4|Depth Anything v2??【深藍(lán)AI】編譯
3.1 整體框架
基于以上分析,訓(xùn)練Depth Anything v2的流程如下:
●基于高質(zhì)量合成圖像訓(xùn)練基于DINOv2-G的可靠教師模型;
●在大規(guī)模未標(biāo)記的真實圖像上產(chǎn)生精確的偽深度;
●在偽標(biāo)記的真實圖像上訓(xùn)練最終的學(xué)生模型,實現(xiàn)穩(wěn)健的泛化。
研究團(tuán)隊發(fā)布4種學(xué)生模型,分別基于DINOv2的小型,基礎(chǔ),大型和巨型模型。
3.2 細(xì)節(jié)
如表2所示,使用5個精確合成的數(shù)據(jù)集和8個大規(guī)模偽標(biāo)記真實數(shù)據(jù)集進(jìn)行訓(xùn)練。與V1相同,對于每個偽標(biāo)記樣本,忽略top-n-largest-loss最大區(qū)域,n設(shè)為10%。同時,模型可以產(chǎn)生仿射不變的逆深度,因為模型使用2個損失項對標(biāo)記圖像進(jìn)行優(yōu)化,分別是平移不變損失和梯度匹配損失。其中梯度匹配損失在使用合成圖像時,對深度清晰度優(yōu)化非常有效。在偽標(biāo)記圖像上,遵循V1添加額外的特征對齊損失,以保留來自預(yù)訓(xùn)練的DINOv2編碼器的信息語義。
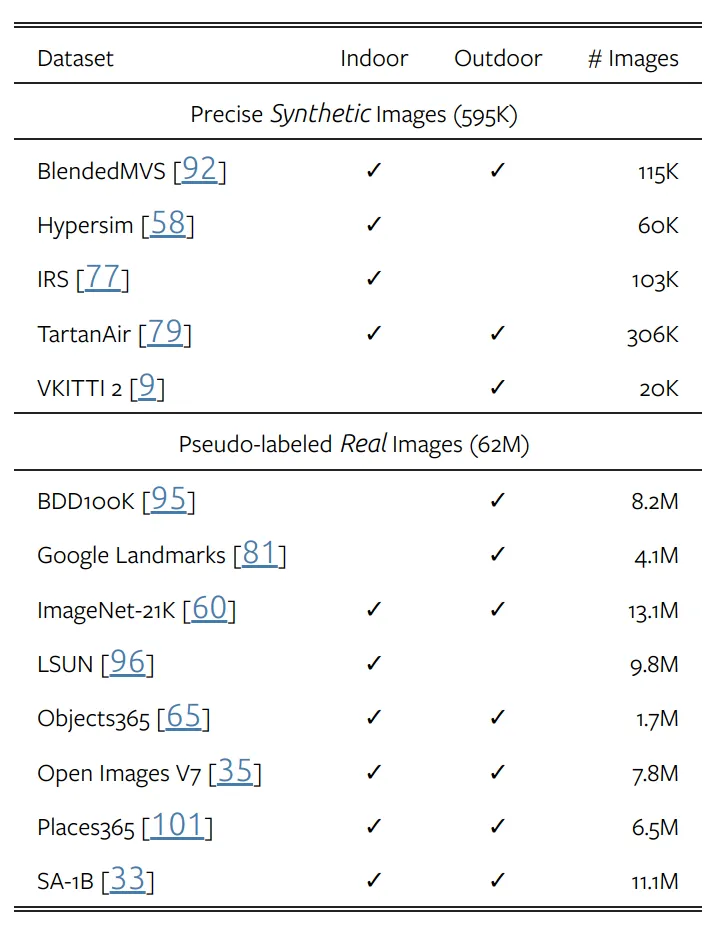
▲表2|訓(xùn)練數(shù)據(jù)集??【深藍(lán)AI】編譯
3.3 DA-2K
考慮到已有噪聲數(shù)據(jù)的限制,該研究的目標(biāo)是構(gòu)建一個通用的相對單目深度估計評估基準(zhǔn)。該基準(zhǔn)可以:
●提供精確的深度關(guān)系;
●覆蓋廣泛的場景;
●包含大多數(shù)適合現(xiàn)代使用的高分辨率圖像。
事實上,人類很難標(biāo)注每個像素的深度,尤其是對于自然圖像,因此研究員為每個圖像標(biāo)注稀疏深度。通常,給定一幅圖像,可以選擇其中的2個像素,并確定它們之間的相對深度。
 ▲圖5|DA-2K??【深藍(lán)AI】編譯
▲圖5|DA-2K??【深藍(lán)AI】編譯
具體來說,可以采用2個不同的管道來選擇像素對。在第一個管道中,如圖5(a)所示,使用SAM自動預(yù)測對象掩碼。但是可能存在模型預(yù)測的情況,引入第二個管道,仔細(xì)分析圖像并手動識別具有挑戰(zhàn)性的像素對。DA-2K并不能取代當(dāng)前的基準(zhǔn),它只是作為準(zhǔn)確密集深度的先決條件。
04 實驗
與Depth Anything v1一樣,使用DPT作為深度解碼器,并且基于DINO v2編碼器構(gòu)造。所有圖像均裁剪到518進(jìn)行訓(xùn)練,在合成圖像上訓(xùn)練教師模型時,使用64的批處理大小進(jìn)行160k次迭代。在偽標(biāo)記真實圖像上訓(xùn)練的第三階段,該模型使用192的批處理大小進(jìn)行480k次迭代。使用Adam優(yōu)化器,分別將編碼器和解碼器的學(xué)習(xí)率設(shè)置為5e-5和5e-6。
 ▲表3|零樣本深度估計??【深藍(lán)AI】編譯
▲表3|零樣本深度估計??【深藍(lán)AI】編譯
 ▲表4|DA-2K評估基準(zhǔn)上的性能??【深藍(lán)AI】編譯
▲表4|DA-2K評估基準(zhǔn)上的性能??【深藍(lán)AI】編譯
如表3所示,結(jié)果優(yōu)于MiDaS,稍遜于V1。然而,v2本身是針對薄結(jié)構(gòu)進(jìn)行細(xì)粒度預(yù)測,對復(fù)雜場景和透明物體進(jìn)行穩(wěn)健預(yù)測。這些維度的改進(jìn)無法正確反映在當(dāng)前的基準(zhǔn)測試中。而在DA-2K的測試上,即使是最小的模型也明顯優(yōu)于其他基于SD的大模型。提出的最大模型在相對深度辨別方面的準(zhǔn)確率比Margold高出10.6%.
 ▲表5|將Depth Anything V2預(yù)訓(xùn)練編碼器微調(diào)至域內(nèi)度量深度估計,即訓(xùn)練和測試圖像共享同一域。所有比較方法都使用接近ViT-L的編碼器大小??【深藍(lán)AI】編譯
▲表5|將Depth Anything V2預(yù)訓(xùn)練編碼器微調(diào)至域內(nèi)度量深度估計,即訓(xùn)練和測試圖像共享同一域。所有比較方法都使用接近ViT-L的編碼器大小??【深藍(lán)AI】編譯
如表5所示,將編碼器轉(zhuǎn)移到下游的度量深度估計任務(wù)上,在NYU-D和KITTI數(shù)據(jù)集上都比之前的方法取得了顯著改進(jìn),值得注意的是,即使是最輕量級的基于ViT-S的模型。
 ▲表6|偽標(biāo)記真實圖像上的重要性??【深藍(lán)AI】編譯
▲表6|偽標(biāo)記真實圖像上的重要性??【深藍(lán)AI】編譯
如表6所示,消融實驗證明了大規(guī)模偽標(biāo)記真實圖像的重要性。與僅使用合成圖像進(jìn)行訓(xùn)練相比,模型通過結(jié)合偽標(biāo)記真實圖像得到了極大的增強(qiáng)。
05 總結(jié)與未來展望
在本研究中,作者提出了Depth Anything v2,一種更強(qiáng)大的單目深度估計基礎(chǔ)模型。它能夠:
●提供穩(wěn)健且細(xì)粒度更大的深度預(yù)測;
●支持具有各種模型大小(從25M到1.3B參數(shù))的廣泛應(yīng)用;
●可輕松微調(diào)到下游任務(wù),可以作為有效的模型初始化。
研究團(tuán)隊揭示了這項關(guān)鍵發(fā)現(xiàn),此外,考慮到現(xiàn)有測試集中多樣性弱,噪聲強(qiáng)的特點(diǎn),團(tuán)隊構(gòu)建了一個多功能評估基準(zhǔn)DA-2K,涵蓋具有精確且具有挑戰(zhàn)性的稀疏深度標(biāo)簽的各種高分辨率圖像。

























