僅用10MB內存,你能從100億個數中找到中位數嗎?
作者:軟件求生
如果文件過大,讀取和寫入操作可能會成為瓶頸。可以考慮使用更高效的IO方式或者利用多線程并發處理來提升性能。此外,對于非常大的數據集,分布式處理也是一種可行的方案。
問題背景
假設我們有一個大文件,里面包含了100億個整數。我們只有10MB的內存,要在其中找到中位數。首先,什么是中位數呢?簡單來說,中位數就是排序后位于中間位置的那個數。對于100億個整數來說,中位數就是第50億個數。
問題的挑戰:
- 數據量巨大:100億個整數可不是小數目,如果每個整數占用4字節,那么100億個整數需要大約400GB的存儲空間。
- 內存限制:僅有10MB的內存,根本無法一次性載入這些數據。
面對如此大數據量和有限的內存,我們該如何找到中位數呢?別慌,我們一起來看看如何應對這兩種情況!
內存夠的情況下
如果你有足夠的內存,那就簡單多了!我們可以一次性將所有數據載入內存,然后進行排序,找到排序后中間位置的那個數即可。哪怕你使用最簡單的冒泡排序也可以解決問題。
 圖片
圖片
這個方法雖然簡單粗暴,但在實際中幾乎不可能,因為面試官不會給你那么多內存!
內存不夠的情況下
當內存不夠時,我們就得動點腦筋了。我們可以通過“分治”的思想將大問題逐步縮小到內存能夠處理的范圍。
思路解析
- 分文件處理:由于我們只關心中位數,所以可以通過二進制的位來將數據分成多個子文件。每次處理一個子文件,縮小范圍,直到我們能夠找到中位數。
- 二進制位劃分:首先,讀取文件中的數據到內存中(不超過10MB),然后根據數字的二進制最高位(第32位,符號位)將數字分成兩個文件。如果最高位為0,表示這個數是非負數,則寫入file_0文件中;如果最高位為1,表示這個數是負數,則寫入file_1文件中。
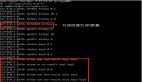
具體實現
以下是這個過程的Java代碼實現:
 圖片
圖片
 圖片
圖片
代碼解析
- 劃分文件:通過divideFile方法,我們可以根據指定的二進制位將文件中的數字分成兩個文件。這里用的是BufferedReader和BufferedWriter來處理文件IO,以確保效率。
- 遞歸查找中位數:findMedianInFile方法中,我們不斷縮小范圍,直到文件中的數據可以直接在內存中處理(通過排序找出中位數)。
進一步優化
如果文件過大,讀取和寫入操作可能會成為瓶頸。可以考慮使用更高效的IO方式或者利用多線程并發處理來提升性能。此外,對于非常大的數據集,分布式處理也是一種可行的方案。
END
在解決大數據問題時,內存的限制是必須要考慮的因素。通過分治法,我們能夠有效地將問題規模逐步縮小,最終在有限的內存內找到答案。這個思路不僅僅適用于尋找中位數的問題,還可以推廣到其他需要處理大數據的場景中。
責任編輯:武曉燕
來源:
軟件求生