一文揭開 NVIDIA CUDA 神秘面紗
Hello folks,我是 Luga,今天我們繼續(xù)來聊一下人工智能生態(tài)相關(guān)技術(shù) - 用于加速構(gòu)建 AI 核心算力的 GPU 編程框架 - CUDA 。
CUDA,作為現(xiàn)代圖形處理器(GPU)的計算單元,在高性能計算領(lǐng)域扮演著日益重要的角色。通過將復(fù)雜的計算任務(wù)分解為數(shù)千個線程并行執(zhí)行,CUDA 顯著提升了計算速度,為人工智能、科學(xué)計算、高性能計算等領(lǐng)域帶來了革命性的變革。

CUDA 到底是什么 ?
毋庸置疑,你一定聽說過 CUDA,并了解這玩意與 NVIDIA GPU 密切相關(guān)。然而,關(guān)于 CUDA 的具體定義和功能,許多人仍然心存疑惑,一臉懵逼。CUDA 是一個與 GPU 進(jìn)行通信的庫嗎?
如果是,它屬于 C++ 還是 Python 庫?或者,CUDA 實(shí)際上是一個用于 GPU 的編譯器?了解這些問題有助于更好地掌握 CUDA 的核心特性及其在 GPU 加速中的作用。
CUDA,全稱為 “ Compute Unified Device Architecture ”,即“計算統(tǒng)一設(shè)備架構(gòu)”,是 NVIDIA 推出的一套強(qiáng)大并行計算平臺和編程模型框架,為開發(fā)人員提供了加速計算密集型應(yīng)用的完整解決方案。CUDA 包含運(yùn)行時內(nèi)核、設(shè)備驅(qū)動程序、優(yōu)化庫、開發(fā)工具和豐富的 API 組合,使得開發(fā)人員能夠在支持 CUDA 的 GPU 上運(yùn)行代碼,大幅提升應(yīng)用程序的性能。這一平臺尤為適合用于處理大規(guī)模并行任務(wù),如深度學(xué)習(xí)、科學(xué)計算以及圖像處理等領(lǐng)域。
通常而言,“CUDA” 不僅指平臺本身,也可指為充分利用 NVIDIA GPU 的計算能力而編寫的代碼,這些代碼多采用 C++ 和 Python 等語言編寫,以充分發(fā)揮 GPU 加速的優(yōu)勢。借助 CUDA,開發(fā)人員能夠更加輕松地將復(fù)雜的計算任務(wù)轉(zhuǎn)移至 GPU 運(yùn)行,極大提升應(yīng)用程序的運(yùn)行效率。
因此,總結(jié)起來,我們可以得出如下結(jié)論:
CUDA 不僅僅是一個簡單的庫,它是一個完整的平臺,為開發(fā)者提供了利用 GPU 進(jìn)行高效并行計算的全方位支持。這個平臺的核心組件包括:
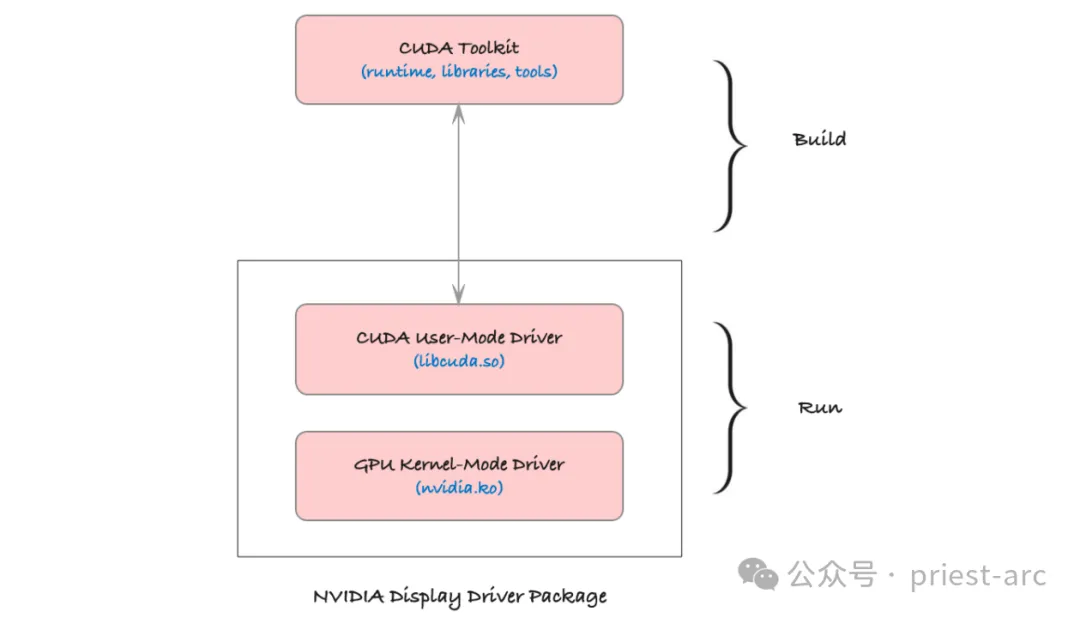
- CUDA C/C++:這是 CUDA 為并行編程所擴(kuò)展的 C++ 語言,專為在 GPU 上編寫并行代碼而設(shè)計。開發(fā)者可以使用熟悉的 C++ 語法結(jié)構(gòu),通過特定的編程模型定義 GPU 任務(wù),讓代碼更高效地在多線程環(huán)境中執(zhí)行。
- CUDA 驅(qū)動程序:這一組件連接操作系統(tǒng)與 GPU,提供底層硬件訪問接口。驅(qū)動程序的主要作用是管理 CPU 與 GPU 之間的數(shù)據(jù)傳輸,并協(xié)調(diào)它們的計算資源。它確保了硬件和操作系統(tǒng)的兼容性,是 CUDA 代碼高效運(yùn)行的基礎(chǔ)。
- CUDA 運(yùn)行時庫(cudart):運(yùn)行時庫為開發(fā)者提供了豐富的 API,便于管理 GPU 內(nèi)存、啟動 GPU 內(nèi)核(即并行任務(wù))、同步線程等。它簡化了開發(fā)者的工作流程,使得在 GPU 上運(yùn)行并行程序的流程更加流暢和高效。
- CUDA 工具鏈(ctk):包括編譯器、鏈接器、調(diào)試器等工具,這些工具用于將 CUDA 代碼編譯成 GPU 可執(zhí)行的二進(jìn)制指令。工具鏈中的編譯器將 C++ 代碼和 CUDA 內(nèi)核代碼一同處理,使其適應(yīng) GPU 的架構(gòu);而調(diào)試器和分析工具幫助開發(fā)者優(yōu)化性能和排查問題。
相關(guān)的環(huán)境變量可參考如下:
- $CUDA_HOME是系統(tǒng)CUDA的路徑,看起來像/usr/local/cuda,它可能鏈接到特定版本/usr/local/cuda-X.X。
- $LD_LIBRARY_PATH是一個幫助應(yīng)用程序查找鏈接庫的變量。您可能想要包含$CUDA_HOME/lib的路徑。
- $PATH應(yīng)該包含一個通往$CUDA_HOME/bin的路徑。
借助這一完整的開發(fā)平臺,開發(fā)者能夠充分挖掘 NVIDIA GPU 的計算潛力,將復(fù)雜的并行計算任務(wù)高效地分配至 GPU 上執(zhí)行,從而實(shí)現(xiàn)應(yīng)用程序性能的極大提升。
CUDA 是如何工作的 ?
現(xiàn)代 GPU 由數(shù)千個小型計算單元組成,這些單元被稱為 CUDA 核心。CUDA 核心能夠高效并行工作,使 GPU 能夠快速處理那些可以分解為多個小型獨(dú)立操作的任務(wù)。這種架構(gòu)使得 GPU 不僅適用于圖形渲染任務(wù),也適用于計算密集型的科學(xué)計算和機(jī)器學(xué)習(xí)等非圖形任務(wù)。
作為 NVIDIA 提供的一個計算平臺和編程模型,CUDA 專門為 GPU 開放了這些強(qiáng)大的并行處理能力。通過 CUDA,開發(fā)者可以編寫代碼,將復(fù)雜的計算任務(wù)移交給 GPU。以下是 CUDA 的工作原理:
(1) 并行處理
CUDA 將計算任務(wù)分解為多個可以獨(dú)立運(yùn)行的小任務(wù),并將這些任務(wù)分配到多個 CUDA 核心上并行執(zhí)行。這樣一來,與傳統(tǒng) CPU 順序執(zhí)行的模式相比,GPU 可以在相同時間內(nèi)完成更多的計算,從而極大地提升計算效率。
(2) 線程和塊的架構(gòu)
在 CUDA 編程模型中,計算任務(wù)被進(jìn)一步劃分為線程,每個線程獨(dú)立處理一部分?jǐn)?shù)據(jù)。這些線程被組織成塊,每個塊中包含一定數(shù)量的線程。這種層次化結(jié)構(gòu)不僅便于管理海量線程,還提高了執(zhí)行效率。多個線程塊可以同時運(yùn)行,使得整個任務(wù)可以快速并行完成。
(3) SIMD 架構(gòu)
CUDA 核心采用單指令多數(shù)據(jù)(Single Instruction, Multiple Data,簡稱 SIMD)架構(gòu)。這意味著單條指令可以對多個數(shù)據(jù)元素同時執(zhí)行操作。例如,可以用一條指令對大量數(shù)據(jù)元素進(jìn)行相同的計算,從而加快數(shù)值計算的速度。這種架構(gòu)對矩陣運(yùn)算、向量處理等高并行任務(wù)極為高效,特別適用于深度學(xué)習(xí)模型訓(xùn)練、圖像處理和模擬仿真等領(lǐng)域。
基于這些特性,CUDA 不僅為高性能并行計算提供了直接途徑,也將 NVIDIA GPU 的強(qiáng)大計算潛力拓展至科學(xué)計算、人工智能、圖像識別等領(lǐng)域,為開發(fā)者實(shí)現(xiàn)復(fù)雜計算任務(wù)的加速提供了強(qiáng)有力的支持。
CUDA 編程模型
在 CUDA 編程中,開發(fā)者通常需要編寫兩部分代碼:主機(jī)代碼(Host Code)和設(shè)備代碼(Device Code)。
主機(jī)代碼在 CPU 上運(yùn)行,負(fù)責(zé)與 GPU 進(jìn)行交互,包括數(shù)據(jù)傳輸和資源管理;而設(shè)備代碼則在 GPU 上執(zhí)行,承擔(dān)主要計算任務(wù)。二者相互配合,充分利用 CPU 和 GPU 的協(xié)同處理能力,以達(dá)到高效并行計算的目的。
(1) 主機(jī)代碼:主機(jī)代碼運(yùn)行在 CPU 上,負(fù)責(zé)控制整個程序的邏輯流程。它管理 CPU 和 GPU 之間的數(shù)據(jù)傳輸,分配和釋放 GPU 資源,并配置 GPU 內(nèi)核參數(shù)。這部分代碼不僅定義了如何組織數(shù)據(jù)并將其發(fā)送到 GPU,還包含了啟動設(shè)備代碼的指令,從而讓 GPU 接管計算密集的任務(wù)。主機(jī)代碼起到管理和協(xié)調(diào)的作用,確保 CPU 與 GPU 之間的高效協(xié)作。
此部分包括數(shù)據(jù)傳輸、內(nèi)存管理、以及啟動 GPU 內(nèi)核等,具體功能可參考如下所示:
- 數(shù)據(jù)傳輸管理:主機(jī)代碼負(fù)責(zé)在 CPU 和 GPU 之間傳輸數(shù)據(jù)。由于 CPU 和 GPU 通常使用不同的內(nèi)存系統(tǒng),主機(jī)代碼需要在兩者之間復(fù)制數(shù)據(jù)。例如,將需要處理的數(shù)據(jù)從主機(jī)內(nèi)存(CPU 內(nèi)存)傳輸?shù)皆O(shè)備內(nèi)存(GPU 內(nèi)存),并在處理完成后將結(jié)果從 GPU 內(nèi)存?zhèn)骰?CPU 內(nèi)存。這種數(shù)據(jù)傳輸是耗時的,因此在實(shí)際應(yīng)用中需要盡量減少傳輸頻率,并優(yōu)化數(shù)據(jù)大小,以降低延遲。
- 內(nèi)存分配與管理:主機(jī)代碼分配 GPU 內(nèi)存空間,為后續(xù)的計算提供儲存資源。CUDA API 提供了多種內(nèi)存管理函數(shù)(如 cudaMalloc 和 cudaFree),允許開發(fā)者在 GPU 上動態(tài)分配和釋放內(nèi)存。合理的內(nèi)存分配策略可以有效提高內(nèi)存使用效率,防止 GPU 內(nèi)存溢出。
- 內(nèi)核配置與調(diào)度:在主機(jī)代碼中,開發(fā)者可以配置內(nèi)核啟動參數(shù)(如線程數(shù)和線程塊數(shù))并決定內(nèi)核在 GPU 上的執(zhí)行方式。通過優(yōu)化這些參數(shù),主機(jī)代碼能夠顯著提升程序的執(zhí)行效率
(2) 設(shè)備代碼:設(shè)備代碼編寫的核心部分是在 GPU 上執(zhí)行的計算函數(shù),通常被稱為內(nèi)核(Kernel)。每個內(nèi)核函數(shù)在 GPU 的眾多 CUDA 核心上并行執(zhí)行,能夠快速處理大量數(shù)據(jù)。設(shè)備代碼專注于數(shù)據(jù)密集型的計算任務(wù),在執(zhí)行過程中充分利用 GPU 的并行計算能力,使得計算速度比傳統(tǒng)的串行處理有顯著提升。
設(shè)備代碼定義了 GPU 的計算邏輯,使用 CUDA 內(nèi)核來并行處理大量數(shù)據(jù)。
- 內(nèi)核函數(shù)(Kernel Function):設(shè)備代碼的核心是內(nèi)核函數(shù),即在 GPU 的多個線程上同時執(zhí)行的函數(shù)。內(nèi)核函數(shù)由 __global__ 關(guān)鍵字標(biāo)識,表示該函數(shù)將在設(shè)備端(GPU)執(zhí)行。內(nèi)核函數(shù)與普通的 C/C++ 函數(shù)不同,它必須是無返回值的,因為所有輸出結(jié)果都要通過修改傳入的指針或 GPU 內(nèi)存來傳遞。
- 線程和線程塊的組織:在設(shè)備代碼中,計算任務(wù)被分解為多個線程,這些線程組成線程塊(Block),多個線程塊組成一個線程網(wǎng)格(Grid)。CUDA 提供了 threadIdx、blockIdx 等內(nèi)置變量來獲取線程的索引,從而讓每個線程在數(shù)據(jù)中找到屬于自己的計算任務(wù)。這種方式使得設(shè)備代碼可以非常高效地并行處理數(shù)據(jù)集中的每個元素。
- 并行算法優(yōu)化:在設(shè)備代碼中,CUDA 編程可以實(shí)現(xiàn)多個并行優(yōu)化技術(shù),例如減少分支、優(yōu)化內(nèi)存訪問模式(如減少全局內(nèi)存訪問和提高共享內(nèi)存利用率),這些優(yōu)化有助于最大化利用 GPU 計算資源,提高設(shè)備代碼的執(zhí)行速度。
(3) 內(nèi)核啟動:內(nèi)核啟動是 CUDA 編程的關(guān)鍵步驟,由主機(jī)代碼啟動設(shè)備代碼內(nèi)核,在 GPU 上觸發(fā)執(zhí)行。內(nèi)核啟動參數(shù)指定了 GPU 上線程的數(shù)量和分布方式,使內(nèi)核函數(shù)可以通過大量線程并行運(yùn)行,從而加快數(shù)據(jù)處理速度。通過適當(dāng)配置內(nèi)核,CUDA 編程能以更優(yōu)的方式利用 GPU 資源,提高應(yīng)用的計算效率。
在整個體系中,這一步驟至關(guān)重要,它控制了設(shè)備代碼的并行性、效率及運(yùn)行行為。具體可參考如下:
- 內(nèi)核啟動語法:CUDA 使用特殊的語法 <<<Grid, Block>>> 啟動內(nèi)核函數(shù)。例如:kernel<<<numBlocks, threadsPerBlock>>>(parameters);,其中 numBlocks 表示線程塊的數(shù)量,threadsPerBlock 表示每個線程塊中包含的線程數(shù)。開發(fā)者可以根據(jù)數(shù)據(jù)集的大小和 GPU 的計算能力選擇合適的線程塊和線程數(shù)量。
- 并行化控制:通過指定線程塊數(shù)和線程數(shù),內(nèi)核啟動控制了 GPU 的并行粒度。較大的數(shù)據(jù)集通常需要更多的線程和線程塊來充分利用 GPU 的并行能力。合理配置內(nèi)核啟動參數(shù),可以平衡 GPU 的并行工作負(fù)載,避免資源浪費(fèi)或過載現(xiàn)象。
- 同步與異步執(zhí)行:內(nèi)核啟動后,GPU 可以異步執(zhí)行任務(wù),CPU 繼續(xù)進(jìn)行其他操作,直至需要等待 GPU 完成。開發(fā)者可以利用這種異步特性,使程序在 CPU 和 GPU 間并行執(zhí)行,達(dá)到更高的并行效率。此外,CUDA 提供了同步函數(shù)(如 cudaDeviceSynchronize),確保 CPU 在需要時等待 GPU 完成所有操作,避免數(shù)據(jù)不一致的問題。
通過有效協(xié)調(diào)這三者,CUDA 編程能夠?qū)崿F(xiàn)對數(shù)據(jù)密集型任務(wù)的高速并行處理,為高性能計算提供了一個極具擴(kuò)展性的解決方案。
CUDA 內(nèi)存層次結(jié)構(gòu)體系
在 CUDA 編程中,GPU 內(nèi)存的結(jié)構(gòu)是多層次的,具有不同的速度和容量特性。CUDA 提供了多種內(nèi)存類型,用于不同的數(shù)據(jù)存儲需求。合理利用這些內(nèi)存可以顯著提升計算效率。以下是各類內(nèi)存的詳細(xì)描述:
(1) 全局內(nèi)存(Global Memory)
全局內(nèi)存是 GPU 上容量最大的存儲空間,通常為幾 GB,并且是 GPU 的主要數(shù)據(jù)存儲區(qū)。全局內(nèi)存可以被所有線程訪問,也可以與 CPU 共享數(shù)據(jù),但其訪問速度相對較慢(相對于其他 GPU 內(nèi)存類型而言),因此需要避免頻繁訪問。數(shù)據(jù)傳輸操作也較耗時,因此全局內(nèi)存常用于存儲較大的數(shù)據(jù)集,但會優(yōu)先考慮數(shù)據(jù)訪問的批處理或其他緩存策略來減少其頻繁調(diào)用。
通常而言,全局內(nèi)存主要適用于存儲程序的大部分輸入輸出數(shù)據(jù),尤其是需要 GPU 和 CPU 共享的大容量數(shù)據(jù)。
示例:在矩陣乘法中,兩個矩陣的元素可以存儲在全局內(nèi)存中,以便所有線程都可以訪問。
__global__ void matrixMultiplication(float *A, float *B, float *C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0;
for (int i = 0; i < N; ++i) {
sum += A[row * N + i] * B[i * N + col];
}
C[row * N + col] = sum;
}(2) 共享內(nèi)存(Shared Memory)
共享內(nèi)存是分配在 GPU 每個線程塊內(nèi)部的高速緩存,其訪問速度遠(yuǎn)高于全局內(nèi)存,但容量較小(通常為每塊 48 KB 或更少)。共享內(nèi)存是線程塊內(nèi)線程共享的,適合存儲需要在一個線程塊內(nèi)頻繁訪問的數(shù)據(jù)。由于它存儲在各自的塊內(nèi),每個塊內(nèi)的線程可以在共享內(nèi)存中快速讀寫數(shù)據(jù),從而減少對全局內(nèi)存的訪問。
相對于全局內(nèi)存,共享內(nèi)存更多適用于多線程間的數(shù)據(jù)交換,尤其是需在一個線程塊內(nèi)反復(fù)使用的數(shù)據(jù)。
示例:在矩陣乘法中,A 和 B 的子塊可以加載到共享內(nèi)存中,以便線程塊中的所有線程都可以快速訪問。
__shared__ float sharedA[TILE_SIZE][TILE_SIZE];
__shared__ float sharedB[TILE_SIZE][TILE_SIZE];(3) 本地內(nèi)存(Local Memory)
本地內(nèi)存是分配給每個線程的私有內(nèi)存,主要用于存儲線程的私有變量。盡管稱為“本地”,它實(shí)際上是分配在全局內(nèi)存中,因此訪問速度較慢,接近全局內(nèi)存的訪問速度。由于本地內(nèi)存容量有限且其訪問開銷較高,建議只在必要時使用。
通常情況下,本地內(nèi)存適用于存儲線程的臨時變量、私有數(shù)據(jù)或不適合在寄存器中保存的數(shù)據(jù)。
示例:對于復(fù)雜計算中的中間變量,可以放置在本地內(nèi)存中,以便線程之間不發(fā)生沖突。
int localVariable = 0; // 本地內(nèi)存中的變量(4) 常量和紋理內(nèi)存(Constant and Texture Memory)
常量內(nèi)存和紋理內(nèi)存分別是 CUDA 提供的專用于只讀數(shù)據(jù)的內(nèi)存類型,具有特殊的緩存機(jī)制,能夠在特定訪問模式下加快數(shù)據(jù)讀取。常量內(nèi)存用于存儲不會更改的常量數(shù)據(jù),而紋理內(nèi)存適合存儲二維或三維數(shù)據(jù),通過紋理緩存可以提高訪問速度。
常量內(nèi)存(Constant Memory):僅可由 CPU 寫入,但可被所有 GPU 線程讀取。適合存儲小規(guī)模的、不變的數(shù)據(jù)(如配置信息、系數(shù)等)。
紋理內(nèi)存(Texture Memory):專門優(yōu)化以支持二維或三維數(shù)據(jù)的讀取,對于非順序或稀疏訪問模式的數(shù)據(jù)(如圖像數(shù)據(jù))具有較高的訪問效率。
示例:在圖像處理應(yīng)用中,將像素數(shù)據(jù)加載到紋理內(nèi)存中,讓 GPU 利用其特定的緩存機(jī)制來優(yōu)化訪問效率。
__constant__ float constData[256]; // 常量內(nèi)存
cudaArray* texArray;
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
cudaMallocArray(&texArray, &channelDesc, width, height); // 紋理內(nèi)存CUDA平臺為開發(fā)人員提供了對CUDA GPU并行計算資源的深度訪問,允許直接操作GPU的虛擬指令集和內(nèi)存。通過使用CUDA,GPU可以高效地處理數(shù)學(xué)密集型任務(wù),從而釋放CPU的計算資源,使其能夠?qū)W⒂谄渌蝿?wù)。這種架構(gòu)與傳統(tǒng)GPU的3D圖形渲染功能有著本質(zhì)的區(qū)別,開創(chuàng)了GPU在計算領(lǐng)域的新用途。
在CUDA平臺的架構(gòu)中,CUDA核心是其核心組成部分。每個CUDA核心都是一個獨(dú)立的并行處理單元,負(fù)責(zé)執(zhí)行各種計算任務(wù)。GPU中的CUDA核心數(shù)量越多,它能夠并行處理的任務(wù)就越多,從而顯著提升計算性能。通過這種并行計算,CUDA平臺能夠在復(fù)雜的計算過程中實(shí)現(xiàn)大規(guī)模任務(wù)的并行處理,提供卓越的性能和高效性。
Reference :
- [1] https://acecloud.ai/resources/blog/why-gpus-for-deep-learning/
- [2] https://www.weka.io/learn/glossary/ai-ml/cpu-vs-gpu/