深度強化學習中SAC算法:數學原理、網絡架構及其PyTorch實現
深度強化學習是人工智能領域最具挑戰性的研究方向之一,其設計理念源于生物學習系統從經驗中優化決策的機制。在眾多深度強化學習算法中,軟演員-評論家算法(Soft Actor-Critic, SAC)因其在樣本效率、探索效果和訓練穩定性等方面的優異表現而備受關注。
傳統的深度強化學習算法往往在探索-利用權衡、訓練穩定性等方面面臨挑戰。SAC算法通過引入最大熵強化學習框架,在策略優化過程中自動調節探索程度,有效解決了這些問題。其核心創新在于將熵最大化作為策略優化的額外目標,在保證收斂性的同時維持策略的多樣性。
本文將系統闡述SAC算法的技術細節,主要包括:
- 基于最大熵框架的SAC算法數學原理
- 演員網絡與評論家網絡的具體架構設計
- 基于PyTorch的詳細實現方案
- 網絡訓練的關鍵技術要點
SAC算法采用演員-評論家架構,演員網絡負責生成動作策略,評論家網絡評估動作價值。通過兩個網絡的協同優化,實現策略的逐步改進。整個訓練過程中,演員網絡致力于最大化評論家網絡預測的Q值,同時保持適度的策略探索;評論家網絡則不斷優化其Q值估計的準確性。
接下來,我們將從演員網絡的數學原理開始,詳細分析SAC算法的各個技術組件:
演員(策略)網絡
演員是由參數φ確定的策略網絡,表示為:
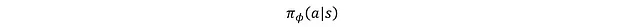
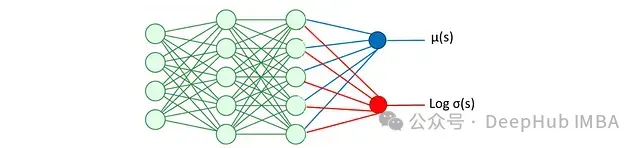
這是一個基于狀態輸出動作的隨機策略。它使用神經網絡估計均值和對數標準差,從而得到給定狀態下動作的分布及其對數概率。對數概率用于熵正則化,即目標函數中包含一個用于最大化概率分布廣度(熵)的項,以促進智能體的探索行為。關于熵正則化的具體內容將在后文詳述。演員網絡的架構如圖所示:
均值μ(s)和對數σ(s)用于動作采樣:
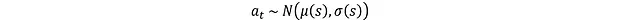
其中N表示正態分布。但這個操作存在梯度不可微的問題,需要通過重參數化技巧來解決。
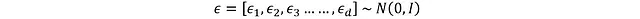
這里d表示動作空間維度,每個分量ε_i從標準正態分布(均值0,標準差1)中采樣。應用重參數化技巧:
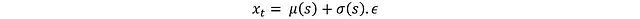
這樣就解決了梯度截斷問題。接下來通過激活函數將x_t轉換為標準化動作:
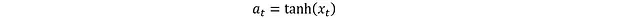
該轉換確保動作被限制在[-1,1]區間內。
動作對數概率計算
完成動作計算后,就可以計算獎勵和預期回報。演員的損失函數中還包含熵正則化項,用于最大化分布的廣度。計算采樣動作??t的對數概率Log(π?)時,從預tanh變換x_t開始分析更為便利。
由于x_t來自均值μ(s)和標準差σ(s)的高斯分布,其概率密度函數(PDF)為:
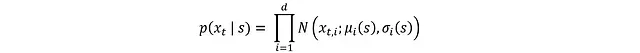
其中各獨立分量x_t,i的分布為:
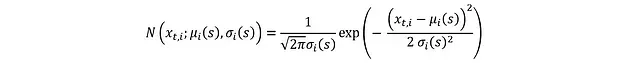
對兩邊取對數可簡化PDF:
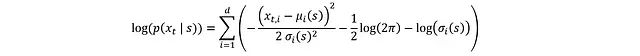
要將其轉換為log(π_?),需要考慮x_t到a_t的tanh變換,這可通過微分鏈式法則實現:
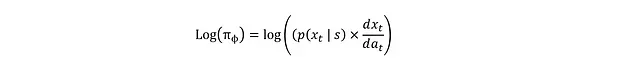
這個關系的推導基于概率守恒原理:兩個變量在給定區間內的概率必須相等:
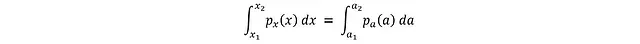
其中a_i = tanh(x_i)。將區間縮小到無窮小的dx和da:
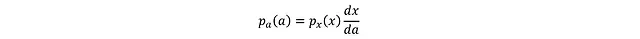
tanh的導數形式為:
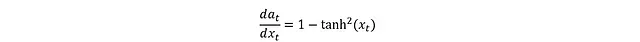
代入得到:
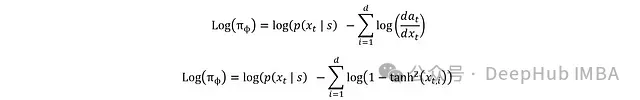
最終可得完整表達式:
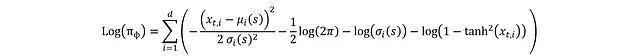
至此完成了演員部分的推導,這里有動作又有對數概率,就可以進行損失函數的計算。下面是這些數學表達式的PyTorch實現:
import gymnasium as gym
from src.utils.logger import logger
from src.models.callback import PolicyGradientLossCallback
from pydantic import Field, BaseModel, ConfigDict
from typing import Dict, List
import numpy as np
import os
from pathlib import Path
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Normal
'''演員網絡:估計均值和對數標準差用于熵正則化計算'''
class Actor(nn.Module):
def __init__(self,state_dim,action_dim):
super(Actor,self).__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, 100),
nn.ReLU(),
nn.Linear(100,100),
nn.ReLU()
)
self.mean_linear = nn.Linear(100, action_dim)
self.log_std_linear = nn.Linear(100, action_dim)
def forward(self, state):
x = self.net(state)
mean = self.mean_linear(x)
log_std =self.log_std_linear(x)
log_std = torch.clamp(log_std, min=-20, max=2)
return mean, log_std
def sample(self, state):
mean, log_std = self.forward(state)
std = log_std.exp()
normal = Normal(mean, std)
x_t = normal.rsample() # 重參數化技巧
y_t = torch.tanh(x_t)
action = y_t
log_prob = normal.log_prob(x_t)
log_prob -= torch.log(1-y_t.pow(2)+1e-6)
log_prob = log_prob.sum(dim=1, keepdim =True)
return action, log_prob在討論損失函數定義和演員網絡的訓練過程之前,需要先介紹評論家網絡的數學原理。
評論家網絡
評論家網絡的核心功能是估計狀態-動作對的預期回報(Q值)。這些估計值在訓練過程中為演員網絡提供指導。評論家網絡采用雙網絡結構,分別提供預期回報的兩個獨立估計,并選取較小值作為最終估計。這種設計可以有效避免過度估計偏差,同時提升訓練穩定性。其結構如圖所示:
需要說明的是,此時的示意圖是簡化版本,主要用于理解演員和評論家網絡的基本角色,暫不考慮訓練穩定性的細節。另外,"智能體"實際上是演員和評論家網絡的統稱而非獨立實體,圖中分開表示只是為了清晰展示結構。假設評論家網絡暫不需要訓練,因為這樣可以專注于如何利用評論家網絡估計的Q值來訓練演員網絡。演員網絡的損失函數表達式為:

更常見的形式是:
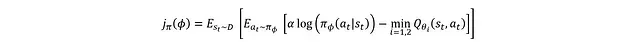
其中ρD表示狀態分布。損失函數通過對所有動作空間和狀態空間的熵項與Q值進行積分得到。但在實際應用中,無法直接獲取完整的狀態分布,因此ρD實際上是基于重放緩沖區樣本的經驗狀態分布,期望其能較好地表征整體狀態分布特征。
基于該損失函數可以通過反向傳播對演員網絡進行訓練。以下是評論家網絡的PyTorch實現:
'''評論家網絡:定義q1和q2'''
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
# Q1網絡架構
self.q1_net = nn.Sequential(
nn.Linear(state_dim + action_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 1),
)
# Q2網絡架構
self.q2_net = nn.Sequential(
nn.Linear(state_dim + action_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 1),
)
def forward(self, state, action):
sa = torch.cat([state, action], dim=1)
q1 = self.q1_net(sa)
q2 = self.q2_net(sa)
return q1, q2前述內容尚未涉及評論家網絡自身的訓練機制。從重放緩沖區采樣的每個數據點包含[s_t, s_{t+1}, a_t, R]。對于狀態-動作對的Q值,我們可以獲得兩種不同的估計。
第一種方法是直接將a_t和s_t輸入評論家網絡:
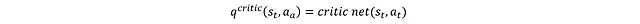
第二種方法是基于貝爾曼方程:
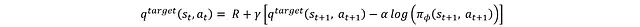
這種方法使用s_t+1、a_t+1以及執行動作a_t獲得的獎勵來重新估計。這里使用目標網絡而非第一種方法中的評論家網絡進行估計。采用目標評論家網絡的主要目的是解決訓練不穩定性問題。如果同一個評論家網絡同時用于生成當前狀態和下一狀態的Q值(用于目標Q值),這種耦合會導致網絡更新在目標計算的兩端產生不一致的傳播,從而引起訓練不穩定。因此引入獨立的目標網絡為下一狀態的Q值提供穩定估計。目標網絡作為評論家網絡的緩慢更新版本,確保目標Q值能夠平穩演化。具體結構如圖所示:
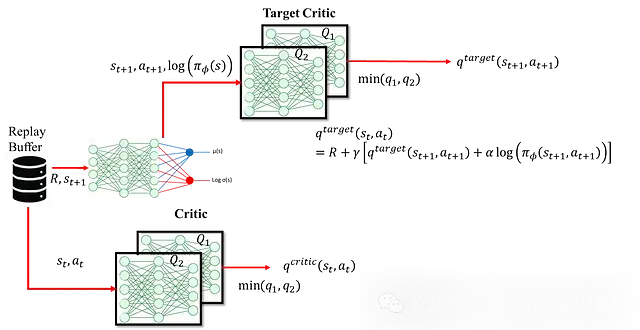
評論家網絡的損失函數定義為:
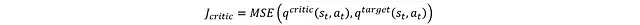
通過該損失函數可以利用反向傳播更新評論家網絡,而目標網絡則采用軟更新機制:
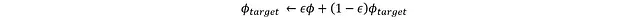
其中ε是一個較小的常數,用于限制目標評論家的更新幅度,從而維持訓練穩定性。
完整流程
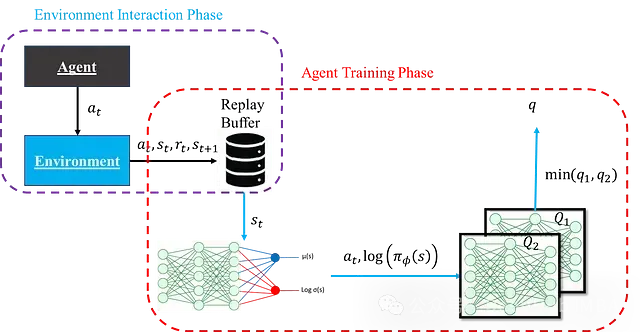
以上內容完整闡述了SAC智能體的各個組件。下圖展示了完整SAC智能體的結構及其計算流程:
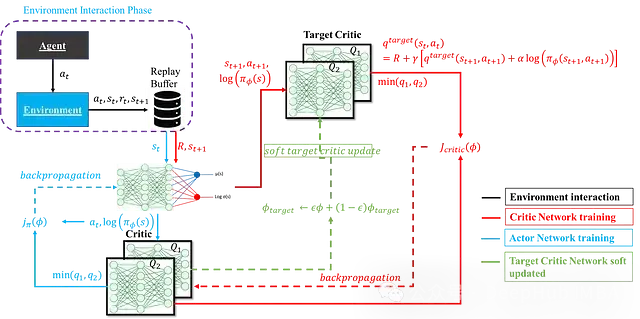
下面是一個綜合了前述演員網絡、評論家網絡及其更新機制的完整SAC智能體實現
'''SAC智能體的實現:整合演員網絡和評論家網絡'''
class SACAgent:
def __init__(self, state_dim, action_dim, learning_rate, device):
self.device = device
self.actor = Actor(state_dim, action_dim).to(device)
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=learning_rate)
self.critic = Critic(state_dim, action_dim).to(device)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=learning_rate)
# 目標網絡初始化
self.critic_target = Critic(state_dim, action_dim).to(device)
self.critic_target.load_state_dict(self.critic.state_dict())
# 熵溫度參數
self.target_entropy = -action_dim
self.log_alpha = torch.zeros(1, requires_grad=True, device=device)
self.alpha_optimizer = optim.Adam([self.log_alpha], lr=learning_rate)
def select_action(self, state, evaluate=False):
state = torch.FloatTensor(state).to(self.device).unsqueeze(0)
if evaluate:
with torch.no_grad():
mean, _ = self.actor(state)
action = torch.tanh(mean)
return action.cpu().numpy().flatten()
else:
with torch.no_grad():
action, _ = self.actor.sample(state)
return action.cpu().numpy().flatten()
def update(self, replay_buffer, batch_size=256, gamma=0.99, tau=0.005):
# 從經驗回放中采樣訓練數據
batch = replay_buffer.sample_batch(batch_size)
state = torch.FloatTensor(batch['state']).to(self.device)
action = torch.FloatTensor(batch['action']).to(self.device)
reward = torch.FloatTensor(batch['reward']).to(self.device)
next_state = torch.FloatTensor(batch['next_state']).to(self.device)
done = torch.FloatTensor(batch['done']).to(self.device)
# 評論家網絡更新
with torch.no_grad():
next_action, next_log_prob = self.actor.sample(next_state)
q1_next, q2_next = self.critic_target(next_state, next_action)
q_next = torch.min(q1_next, q2_next) - torch.exp(self.log_alpha) * next_log_prob
target_q = reward + (1 - done) * gamma * q_next
q1_current, q2_current = self.critic(state, action)
critic_loss = F.mse_loss(q1_current, target_q) + F.mse_loss(q2_current, target_q)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 演員網絡更新
action_new, log_prob = self.actor.sample(state)
q1_new, q2_new = self.critic(state, action_new)
q_new = torch.min(q1_new, q2_new)
actor_loss = (torch.exp(self.log_alpha) * log_prob - q_new).mean()
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 溫度參數更新
alpha_loss = -(self.log_alpha * (log_prob + self.target_entropy).detach()).mean()
self.alpha_optimizer.zero_grad()
alpha_loss.backward()
self.alpha_optimizer.step()
# 目標網絡軟更新
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)總結
本文系統地闡述了SAC算法的數學基礎和實現細節。通過對演員網絡和評論家網絡的深入分析,我們可以看到SAC算法在以下幾個方面具有顯著優勢:
理論框架
- 基于最大熵強化學習的理論基礎保證了算法的收斂性
- 雙Q網絡設計有效降低了值函數估計的過度偏差
- 自適應溫度參數實現了探索-利用的動態平衡
實現特點
- 采用重參數化技巧確保了策略梯度的連續性
- 軟更新機制提升了訓練穩定性
- 基于PyTorch的向量化實現提高了計算效率
實踐價值
- 算法在連續動作空間中表現優異
- 樣本效率高,適合實際應用場景
- 訓練過程穩定,調參難度相對較小
未來研究可以在以下方向繼續深化:
- 探索更高效的策略表達方式
- 研究多智能體場景下的SAC算法擴展
- 結合遷移學習提升算法的泛化能力
- 針對大規模狀態空間優化網絡架構
強化學習作為人工智能的核心研究方向之一,其理論體系和應用場景都在持續發展。深入理解算法的數學原理和實現細節,將有助于我們在這個快速演進的領域中把握技術本質,開發更有效的解決方案。