YOLO、SSD 和 Faster R-CNN 三種方案實現物體識別的對比
本文旨在開發一個能夠準確檢測和分割視頻中物體的計算機視覺系統。我將使用最先進的三種SoA(State-of-the-Art)方法:YOLO、SSD和Faster R-CNN,并評估它們的性能。然后,我通過視覺分析結果,突出它們的優缺點。接下來,我根據評估和分析確定表現最佳的方法。我將提供一個鏈接,展示最佳方法在視頻中的表現。

1. YOLO(You Only Look Once)
YOLOv8等深度學習模型在機器人、自動駕駛和視頻監控等多個行業中變得至關重要。這些模型能夠實時檢測物體,并對安全和決策過程產生影響。YOLOv8(You Only Look Once)利用計算機視覺技術和機器學習算法,以高速度和準確性識別圖像和視頻中的物體。這使得高效且準確的物體檢測成為可能,這在許多應用中至關重要(Keylabs, 2023)。
實現細節
我創建了一個run_model函數來實現物體檢測和分割。該函數接收三個參數作為輸入:模型、輸入視頻和輸出視頻。它逐幀讀取視頻,并將輸入視頻的結果可視化到幀上。然后,注釋后的幀被保存到輸出視頻文件中,直到所有幀都被處理完畢或用戶按下“q”鍵停止處理。
我使用YOLO模型(yolov8n.pt,“v8”)進行物體檢測,該模型顯示帶有檢測到的邊界框的視頻。同樣,對于物體分割,使用具有分割特定權重的YOLO模型(yolov8n-seg.pt)生成帶有分割物體的視頻。
def run_model(model, video, output_video):
model = model
cap = cv2.VideoCapture(video)
# Create a VideoWriter object
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# Get frame width and height
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
out = cv2.VideoWriter(output_video, fourcc, 20.0, (frame_width, frame_height))
if not cap.isOpened():
print("Cannot open camera")
exit()
while True:
# Capture frame-by-frame
ret, frame = cap.read()
if not ret:
print("No frame...")
break
# Predict on image
results = model.track(source=frame, persist=True, tracker='bytetrack.yaml')
frame = results[0].plot()
# Write the frame to the output video file
out.write(frame)
# Display the resulting frame
cv2.imshow("ObjectDetection", frame)
# Terminate run when "Q" pressed
if cv2.waitKey(1) == ord("q"):
break
# When everything done, release the capture
cap.release()
# Release the video recording
# out.release()
cv2.destroyAllWindows()
# Object Detection
run_model(model=YOLO('yolov8n.pt', "v8"), video=VIDEO, output_video=OUTPUT_VIDEO_YOLO_DET)
# Object Segmentation
run_model(model=YOLO('yolov8n-seg.pt', "v8"), video=VIDEO, output_video=OUTPUT_VIDEO_YOLO_SEG)2. Faster R-CNN(基于區域的卷積神經網絡)
Faster R-CNN是一種最先進的物體檢測模型。它有兩個主要組件:一個深度全卷積區域提議網絡和一個Fast R-CNN物體檢測器。它使用區域提議網絡(RPN),該網絡與檢測網絡共享全圖像卷積特征(Ren等,2015)。RPN是一個全卷積神經網絡,生成高質量的提議。然后,Fast R-CNN使用這些提議進行物體檢測。這兩個模型被組合成一個單一的網絡,RPN指導在哪里尋找物體(Ren等,2015)。
(1) 使用Faster R-CNN進行物體檢測
為了實現物體檢測,我創建了兩個函數:get_model和detect_and_draw_boxes。get_model函數加載一個預訓練的Faster R-CNN模型,該模型是torchvision庫的一部分,并在COCO數據集上使用ResNet-50-FPN骨干網絡進行預訓練。我將模型設置為評估模式。然后,detect_and_draw_boxes函數對單個視頻幀進行物體檢測,并在檢測到的物體周圍繪制邊界框。它將幀轉換為張量并傳遞給模型。該模型返回預測結果,包括檢測到的物體的邊界框、標簽和分數。置信度分數高于0.9的邊界框,以及指示類別和置信度分數的標簽被添加。
def get_model():
# Load a pre-trained Faster R-CNN model
weights = FasterRCNN_ResNet50_FPN_Weights.DEFAULT
model = fasterrcnn_resnet50_fpn(weights=weights, pretrained=True)
model.eval()
return model
def faster_rcnn_object_detection(model, frame):
# Transform frame to tensor and add batch dimension
transform = T.Compose([T.ToTensor()])
frame_tensor = transform(frame).unsqueeze(0)
with torch.no_grad():
prediction = model(frame_tensor)
bboxes, labels, scores = prediction[0]["boxes"], prediction[0]["labels"], prediction[0]["scores"]
# num = torch.argwhere(scores > 0.9).shape[0]
# Draw boxes and labels on the frame
for i in range(len(prediction[0]['boxes'])):
xmin, ymin, xmax, ymax = bboxes[i].numpy().astype('int')
class_name = COCO_NAMES[labels.numpy()[i] -1]
if scores[i] > 0.9: # Only draw boxes for confident predictions
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), (0, 255, 0), 3)
# Put label
label = f"{class_name}: {scores[i]:.2f}"
cv2.putText(frame, label, (xmin, ymin - 10), FONT, 0.5, (255, 0, 0), 2, cv2.LINE_AA)
return frame
# Set up the model
model = get_model()
# Video capture setup
cap = cv2.VideoCapture(VIDEO)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# Get frame width and height
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
out = cv2.VideoWriter(OUTPUT_VIDEO_FASTER_RCNN_DET, fourcc, 20.0, (frame_width, frame_height))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("No frame...")
break
# Process frame
processed_frame = faster_rcnn_object_detection(model, frame)
# Write the processed frame to output
out.write(processed_frame)
# Display the frame
cv2.imshow('Frame', processed_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release everything is finished
cap.release()
out.release()
cv2.destroyAllWindows()(2) 使用Faster R-CNN進行物體分割
為了實現物體分割,我創建了函數來加載預訓練的Mask R-CNN模型、預處理視頻幀、應用分割并將掩碼覆蓋在幀上。首先,我使用從torchvision庫加載的預訓練Mask R-CNN模型,該模型具有ResNet-50-FPN骨干網絡,并將其設置為評估模式。我在COCO數據集上訓練了該模型。然后,preprocess_frame函數對每個視頻幀進行預處理并將其轉換為張量。接下來,apply_segmentation函數對預處理后的幀應用分割過程,overlay_masks函數將分割掩碼覆蓋在幀上,繪制邊界框,并為置信度較高的檢測添加標簽。這涉及通過置信度閾值過濾檢測結果、覆蓋掩碼、繪制矩形和添加文本標簽。
# Load the pre-trained Mask R-CNN model
model = maskrcnn_resnet50_fpn(pretrained=True)
model.eval()
# Function to overlay masks and draw rectangles and labels on the frame
def faster_rcnn_object_segmentation(frame, threshold=0.9):
# Function to preprocess the frame
transform = T.Compose([T.ToTensor()])
frame_tensor = transform(frame).unsqueeze(0)
with torch.no_grad():
predictions = model(frame_tensor)
labels = predictions[0]['labels'].cpu().numpy()
masks = predictions[0]['masks'].cpu().numpy()
scores = predictions[0]['scores'].cpu().numpy()
boxes = predictions[0]['boxes'].cpu().numpy()
overlay = frame.copy()
for i in range(len(masks)):
if scores[i] > threshold:
mask = masks[i, 0]
mask = (mask > 0.6).astype(np.uint8)
color = np.random.randint(0, 255, (3,), dtype=np.uint8)
overlay[mask == 1] = frame[mask == 1] * 0.5 + color * 0.5
xmin, ymin, xmax, ymax = boxes[i].astype('int')
class_name = COCO_NAMES[labels[i] - 1]
# Draw rectangle
cv2.rectangle(overlay, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)
# Put label
label = f"{class_name}: {scores[i]:.2f}"
cv2.putText(overlay, label, (xmin, ymin - 10), FONT, 0.5, (255, 0, 0), 2, cv2.LINE_AA)
return overlay
# Capture video
cap = cv2.VideoCapture(VIDEO)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# Get frame width and height
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
out = cv2.VideoWriter(OUTPUT_VIDEO_FASTER_RCNN_SEG, fourcc, 20.0, (frame_width, frame_height))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("No frame...")
break
# Overlay masks
processed_frame = faster_rcnn_object_segmentation(frame)
# Write the processed frame to output
out.write(processed_frame)
# Display the frame
cv2.imshow('Frame', processed_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release everything is finished
cap.release()
out.release()
cv2.destroyAllWindows()3. SSD(單次多框檢測器)
SSD,即單次多框檢測器,是一種使用單一深度神經網絡在圖像中進行物體檢測的方法。它將邊界框的輸出空間離散化為每個特征圖位置上具有不同縱橫比和尺度的一組默認框。在預測過程中,網絡為每個默認框中每個物體類別的存在生成分數,并調整框以更好地匹配物體形狀。SSD結合了來自不同分辨率的多個特征圖的預測,以有效處理各種大小的物體,消除了提議生成和重采樣階段的需要,從而簡化了訓練過程并集成到檢測系統中(Liu等,2016)。
(1) 使用SSD進行物體檢測
我創建了一個ssd_object_detection函數,該函數使用預訓練的SSD模型,處理視頻幀,應用檢測并在檢測到的物體周圍繪制邊界框,以實現使用SSD(單次多框檢測器)模型的物體檢測。
# Load the pre-trained SSD model
model = ssd300_vgg16(pretrained=True)
model.eval()
def ssd_object_detection(frame, threshold=0.5):
# Function to preprocess the frame
transform = T.Compose([T.ToTensor()])
frame_tensor = transform(frame).unsqueeze(0)
with torch.no_grad():
predictions = model(frame_tensor)
labels = predictions[0]['labels'].cpu().numpy()
scores = predictions[0]['scores'].cpu().numpy()
boxes = predictions[0]['boxes'].cpu().numpy()
for i in range(len(boxes)):
if scores[i] > threshold:
xmin, ymin, xmax, ymax = boxes[i].astype('int')
class_name = COCO_NAMES[labels[i] - 1]
# Draw rectangle
cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), (0, 255, 0), 2)
# Put label
label = f"{class_name}: {scores[i]:.2f}"
cv2.putText(frame, label, (xmin, ymin - 10), FONT, 0.5, (255, 0, 0), 2, cv2.LINE_AA)
return frame
# Capture video
cap = cv2.VideoCapture(VIDEO)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# Get frame width and height
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
out = cv2.VideoWriter(OUTPUT_VIDEO_SSD_DET, fourcc, 20.0, (frame_width, frame_height))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("No frame...")
break
# Overlay masks
processed_frame = ssd_object_detection(frame)
# Write the processed frame to output
out.write(processed_frame)
# Display the frame
cv2.imshow('Frame', processed_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release everything is finished
cap.release()
out.release()
cv2.destroyAllWindows()(2) 使用SSD進行物體分割
同樣,我創建了ssd_object_segmentation函數,該函數加載預訓練模型,處理視頻幀,應用分割并在檢測到的物體上繪制掩碼和標簽,以實現物體分割。
# Load the pre-trained SSD model
model = ssd300_vgg16(pretrained=True)
model.eval()
def ssd_object_segmentation(frame, threshold=0.5):
# Function to preprocess the frame
transform = T.Compose([T.ToTensor()])
frame_tensor = transform(frame).unsqueeze(0)
with torch.no_grad():
predictions = model(frame_tensor)
labels = predictions[0]['labels'].cpu().numpy()
scores = predictions[0]['scores'].cpu().numpy()
boxes = predictions[0]['boxes'].cpu().numpy()
for i in range(len(boxes)):
if scores[i] > threshold:
xmin, ymin, xmax, ymax = boxes[i].astype('int')
class_name = COCO_NAMES[labels[i] - 1]
# Extract the detected object from the frame
object_segment = frame[ymin:ymax, xmin:xmax]
# Convert to grayscale and threshold to create a mask
gray = cv2.cvtColor(object_segment, cv2.COLOR_BGR2GRAY)
_, mask = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)
# Find contours
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Draw the contours on the original frame
cv2.drawContours(frame[ymin:ymax, xmin:xmax], contours, -1, (0, 255, 0), thickness=cv2.FILLED)
# Put label above the box
label = f"{class_name}: {scores[i]:.2f}"
cv2.putText(frame, label, (xmin, ymin - 10), FONT, 0.5, (255, 0, 0), 2, cv2.LINE_AA)
return frame
# Capture video
cap = cv2.VideoCapture(VIDEO) # replace with actual video file path
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
# Get frame width and height
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
out = cv2.VideoWriter(OUTPUT_VIDEO_SSD_SEG, fourcc, 20.0, (frame_width, frame_height))
while cap.isOpened():
ret, frame = cap.read()
if not ret:
print("No frame...")
break
# Overlay segmentation masks
processed_frame = ssd_object_segmentation(frame)
# Write the processed frame to output
out.write(processed_frame)
# Display the frame
cv2.imshow('Frame', processed_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release everything once finished
cap.release()
out.release()
cv2.destroyAllWindows()4.評估
在本節中,我將評估并比較三種流行的物體檢測模型:YOLO(You Only Look Once)、Faster R-CNN(基于區域的卷積神經網絡)和SSD(單次多框檢測器)。我在CPU設備上工作,而不是CUDA。評估階段包括:
- 每秒幀數(FPS):FPS衡量每個模型每秒處理的幀數。
- 推理時間:推理時間表示每個模型檢測幀中物體所需的時間。
- 模型大小:模型大小表示每個模型占用的磁盤空間。
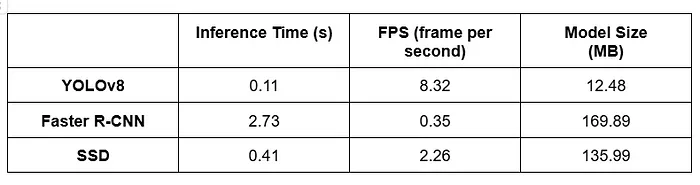
(1) 性能差異討論
從評估結果中,我觀察到以下內容:
- 速度:YOLO在FPS和推理時間方面優于Faster R-CNN和SSD。這表明它適用于實時應用。
- 準確性:Faster R-CNN在準確性上往往優于YOLO和SSD,表明在物體檢測任務中具有更好的準確性。
- 模型大小:YOLO的模型大小最小,這使得它在存儲容量有限的設備上具有優勢。
(2) 最佳表現方法
根據評估結果和定性分析,YOLO8v是視頻序列中物體檢測和分割的最佳SoA方法。其卓越的速度、緊湊的模型大小和強大的性能使其成為在實際應用中準確性和效率至關重要的理想選擇。
完整項目代碼和視頻:https://github.com/fatimagulomova/iu-projects/blob/main/DLBAIPCV01/MainProject.ipynb