知乎直答:AI 搜索產(chǎn)品從 0 到 1 實(shí)踐探索
一、知乎直答產(chǎn)品介紹
知乎直答是具有強(qiáng)社區(qū)屬性的通用 AI 搜索產(chǎn)品,但并非社區(qū)版 AI 搜索。

知乎直答具有以下幾大優(yōu)勢:
- 認(rèn)真專業(yè):與知乎專注專業(yè)內(nèi)容生產(chǎn)的調(diào)性相符,嚴(yán)格把控參考來源與質(zhì)量,確保回答認(rèn)真且專業(yè)。
- 連接創(chuàng)作者:可在使用中關(guān)注、與創(chuàng)作者交流互動(dòng)獲取專業(yè)見解。
- 真實(shí)可信:依托知乎經(jīng)用戶校驗(yàn)的內(nèi)容,有更高的公信力。
- 多元數(shù)據(jù)源:除自身圖文數(shù)據(jù),還引入了公開英文文獻(xiàn)、維普等專業(yè)論文庫及全網(wǎng)數(shù)據(jù)以補(bǔ)充知識。
二、實(shí)踐經(jīng)驗(yàn)分享
在這一章節(jié)中,將分別對 query、retrieval、chunk、rerank、generation 和 evaluation 這些環(huán)節(jié)展開介紹,并分享性能優(yōu)化實(shí)踐。
1. 檢索增強(qiáng)生成(RAG)框架
檢索增強(qiáng)生成(RAG)是一種將檢索系統(tǒng)與大語言模型相結(jié)合的 AI 框架。用戶提問時(shí)先檢索知識庫,將結(jié)果作為大模型上下文生成答案。這種方法可以很好地減少 AI 幻覺問題,確保答案的準(zhǔn)確性,并且具備溯源性與更好的可解釋性。

對比直接用大模型構(gòu)建 AI 系統(tǒng),RAG 在知識更新、時(shí)效性、可解釋性等多方面優(yōu)勢顯著,因此搭建 AI 問答系統(tǒng)首選 RAG 方案。

2. Query 理解相關(guān)實(shí)踐
生產(chǎn)環(huán)境中,query 常常存在表述不完整、多重語義混雜、意圖不明確等問題。針對 query 表述不完整的問題,需要進(jìn)行語義補(bǔ)全。對于意圖混雜的問題,會(huì)基于上下文對 query 進(jìn)行改寫。而對于 query 過于簡短、意圖不明確的情況,則通過多輪問答對 query 進(jìn)行擴(kuò)展。

知乎直答的初始版本僅支持單輪搜索,每次查詢都是一個(gè)獨(dú)立的交互過程。在用戶反饋階段,我們收到了大量關(guān)于上下文理解不足的反饋。因此我們快速迭代,實(shí)現(xiàn)了基于多輪問答上下文的 query 理解。我們專門微調(diào)了一個(gè)模型進(jìn)行 query 改寫。

我們將 query 擴(kuò)展與搜索引擎進(jìn)行了深度結(jié)合,從而降低了成本,并且增強(qiáng)了可控性。因?yàn)?query 擴(kuò)展放到了搜索引擎內(nèi)執(zhí)行,所以可以避免多次調(diào)用搜索引擎,這樣既減少了資源消耗,又可以更好地控制相關(guān)性、多樣性等關(guān)鍵指標(biāo),以提高檢索準(zhǔn)確率。我們定向訓(xùn)練了一個(gè)模型來完成 query 擴(kuò)展任務(wù)。

3. 召回方案
知乎直答采用了多策略召回方案,包括語義召回、標(biāo)簽召回,以及在語義召回基礎(chǔ)上的向量空間對齊。
語義召回方面,基于知乎問答場景數(shù)據(jù)深度調(diào)優(yōu) BGE Embedding 模型,以提升檢索質(zhì)量。針對不同任務(wù)(如檢索、語義相關(guān)性、聚類分類等)調(diào)優(yōu)損失函數(shù),采用不同損失函數(shù)并調(diào)整負(fù)采樣策略等提升效果。

通過模型融合解決長文、短文語料混合訓(xùn)練效果不佳問題。下圖中給出了一個(gè)示例,最左邊是 base 模型,在此基礎(chǔ)上基于長文語料微調(diào)了一個(gè)長文模型,同樣微調(diào)了一個(gè)短文模型,再將三者融合,得到最終的模型。

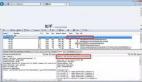
下圖給出了一組評測數(shù)據(jù),其中五列為五個(gè)不同的評測任務(wù),包括短文到長文的檢索、短文到短文的檢索等。可以看到 TextBgeFTQuery2Long 模型在長文檢索上有顯著優(yōu)勢,TextBgeFTQuery2Short 模型在短文檢索上優(yōu)于其它模型,而融合后的 TextBgeFTMixed 在幾乎所有任務(wù)上都有著非常好的表現(xiàn),這充分說明了模型融合的有效性。

除此之外,還有其他一些語義召回方面的經(jīng)驗(yàn),比如 Matryoshka 表征學(xué)習(xí),一次訓(xùn)練讓模型具備多維度輸出能力;BGE-M3 的 dense+sparse 混合檢索長文表現(xiàn)好且能降低索引壓力;ColBERT 的延遲交互方式召回精度高但成本高,適用于高精度要求場景;1bit 量化能提升性能且召回效果損失小,具研發(fā)潛力。

標(biāo)簽召回方面,我們搭建了組合式標(biāo)簽提取方案。將大語言模型的推理能力與傳統(tǒng)召回技術(shù)相結(jié)合,采用兩階段策略進(jìn)行標(biāo)簽抽取。首先通過召回模型獲取內(nèi)容候選標(biāo)簽,再利用 LLM 進(jìn)行深度語義分析和標(biāo)簽生成,確保更全面和準(zhǔn)確的內(nèi)容標(biāo)簽抽取。
標(biāo)簽召回是一種極短文本匹配場景,我們基于特定場景訓(xùn)練了輕量級模型,專門用于從海量標(biāo)簽庫中快速識別和提取相關(guān)標(biāo)簽。該模塊具有高效召回、強(qiáng)語義理解、高可擴(kuò)展性及零樣本新增標(biāo)簽等優(yōu)勢。

在召回模型獲得初步標(biāo)簽候選后,可以依托大模型的語義理解和生成能力,進(jìn)一步選擇更加符合輸入文本語義的最終標(biāo)簽,提高標(biāo)簽抽取的準(zhǔn)確性。這種二階段的方式具有更強(qiáng)的自適應(yīng)性和靈活性,當(dāng)需要新增標(biāo)簽時(shí),可以顯著提升處理效率。

向量空間對齊的工作旨在解決非對稱索引問題,通過對文檔理解構(gòu)建合成標(biāo)題索引,實(shí)現(xiàn) query 到 query 的檢索使訓(xùn)練空間對齊,提升檢索準(zhǔn)確率。

下圖中給出了一個(gè)示例:

4. Chunk 相關(guān)實(shí)踐
之所以做 chunk,主要目的是:
- 降低成本與延遲:通過 chunk 技術(shù)壓縮上下文長度,可以顯著降低推理計(jì)算成本,同時(shí)減少響應(yīng)延遲,提升系統(tǒng)整體性能。
- 提升信息利用效率:大模型在處理過長上下文時(shí)容易出現(xiàn)「Lost in the Middle」現(xiàn)象,難以準(zhǔn)確抓住關(guān)鍵信息。chunk 通過提煉核心內(nèi)容,幫助模型更高效地利用有限的上下文窗口。
而不合適的 chunk 會(huì)帶來如下一些風(fēng)險(xiǎn):
- 語義連貫性受損:不當(dāng)?shù)?chunk 處理可能導(dǎo)致上下文割裂,引發(fā)模型產(chǎn)生錯(cuò)誤理解和虛假信息。
- 信息完整性缺失:過度壓縮可能造成重要信息丟失,導(dǎo)致模型無法提供完整準(zhǔn)確的回答。
- 噪聲干擾問題:在信息提取過程中可能引入無關(guān)信息,影響最終輸出的質(zhì)量和準(zhǔn)確性。
最初的方案是基于固定窗口長度進(jìn)行文檔切分。該方案的特點(diǎn)為:
- 技術(shù)實(shí)現(xiàn)簡單,處理速度快。
- 分塊大小的選擇直接影響效果,較大分塊能保持完整語義,有助于理解全局內(nèi)容;而較小分塊處理更快,資源消耗更少。
這一方案面臨的核心挑戰(zhàn)是文檔的多樣性帶來的問題。由于不同類型的文檔和查詢需求存在巨大差異,固定長度的分塊策略難以同時(shí)滿足語義完整性和處理效率的要求。該方案無法靈活適應(yīng)不同場景,最終限制了系統(tǒng)的實(shí)際應(yīng)用效果。
進(jìn)而,我們又探索了生成式 chunk,但未能成功落地。該方案的核心思路是不顯式切分段落,而是直接使用大語言模型從原文中找出最相關(guān)的子串作為候選答案。也就是采用 End2End 的方式,解決靈活性和分塊與問題相關(guān)性的問題。
我們采用大語言模型+prompt 的方式合成 ranker,用約束解碼的方式約束生成過程。

通過這一嘗試,我們認(rèn)識到性能優(yōu)化是關(guān)鍵。推理延遲是核心挑戰(zhàn),為確保用戶體驗(yàn),我們必須最小化模型前向計(jì)算次數(shù),每一次 forward 都需要嚴(yán)格控制計(jì)算開銷。
同時(shí),我們還觀察到大語言模型存在明顯的最近信息偏好(recency bias),prompt 中的信息對模型評分的影響主要集中在序列的開始部分。
在實(shí)踐中發(fā)現(xiàn)評分模型具有局限性:
?評分模型在使用相同 prompt 時(shí)能夠較好區(qū)分答案質(zhì)量,高質(zhì)量答案確實(shí)能獲得更高分?jǐn)?shù)
?但在前綴對比測試中表現(xiàn)不佳,同一個(gè)答案配上相關(guān)/無關(guān)前綴時(shí)的得分差異不明顯。這反映了模型訓(xùn)練范式的局限,模型從未經(jīng)過這種對比場景的訓(xùn)練。
更合適的方案是歸并式 chunk。包括三個(gè)步驟:相關(guān)度排序、片段合并和邊界擴(kuò)展。

下圖展示了大致的流程,對于候選 chunk 會(huì)進(jìn)行細(xì)粒度的切分,之后用相關(guān)性模型對這些 chunk 和 query 的相關(guān)性進(jìn)行打分,再進(jìn)行 rank、merge 和外推,最后對每一個(gè)文檔僅生成一個(gè) chunk。

5. Rerank 相關(guān)經(jīng)驗(yàn)
Rerank 方面主要關(guān)注的問題為以下幾點(diǎn):
- 關(guān)鍵信息感知:過多的上下文可能會(huì)引入更多的噪聲,削弱 LLM 對關(guān)鍵信息的感知。因此需要通過相關(guān)性控制,確保生成的內(nèi)容集中于最重要的信息。
- 多樣性控制:冗余信息可能會(huì)干擾 LLM 的最終生成,因此需要通過多樣性控制,確保生成內(nèi)容具備豐富性和創(chuàng)新性。
- 提升生成內(nèi)容權(quán)威度:結(jié)合知乎社區(qū)投票機(jī)制加權(quán)排序,可以提升生成內(nèi)容的權(quán)威性和可信度,滿足用戶對高質(zhì)量內(nèi)容的需求。
6. Generation 相關(guān)經(jīng)驗(yàn)
生成模塊是與用戶交互的橋梁,是整個(gè)流程中至關(guān)重要的一環(huán)。我們在生成環(huán)節(jié)的經(jīng)驗(yàn)主要包括:
- 上下文信息元數(shù)據(jù)增強(qiáng):通過精心組織上下文結(jié)構(gòu),融入可驗(yàn)證的元數(shù)據(jù)信息(如來源、時(shí)間、作者等),顯著提升輸出內(nèi)容的可信度和權(quán)威性。同時(shí)確保生成內(nèi)容的準(zhǔn)確性和連貫性。
- Planning 能力探索:探索大模型的 planning 能力,通過任務(wù)分解和推理鏈等技術(shù),不斷增強(qiáng)系統(tǒng)解決復(fù)雜多步驟問題的能力。重點(diǎn)提升對專業(yè)領(lǐng)域問題的處理水平。
- 模型優(yōu)化與對齊:持續(xù)優(yōu)化模型調(diào)優(yōu)與對齊策略,通過細(xì)致的 badcase 分析和針對性訓(xùn)練,全面提升模型的指令理解和執(zhí)行能力。確保生成結(jié)果始終符合預(yù)期標(biāo)準(zhǔn)和用戶需求。
喂給模型的上下文中,會(huì)添加更豐富的元數(shù)據(jù)信息,以提升生成效果,包括時(shí)間維度元數(shù)據(jù)、用戶互動(dòng)數(shù)據(jù),以及創(chuàng)作者專業(yè)背景信息等。

我們對復(fù)雜 query 的 planning 能力也進(jìn)行了探索。傳統(tǒng) RAG 方案在處理復(fù)雜查詢場景時(shí)存在局限性,如難以處理多步推理問題,存在知識幻覺,以及難以有效整合上下文信息等等。

針對這些問題,我們采用了基于 Plan X RAG 的方案,進(jìn)行任務(wù)拆解、逐層推理,優(yōu)化生成 DAG 過程,如預(yù)檢索機(jī)制降低錯(cuò)誤累積、精細(xì)化管理子任務(wù)等。

生成過程的模型優(yōu)化:采用 DPO、step-DPO、PPO、GRPO 等對齊訓(xùn)練方式提升模型效果,注意強(qiáng)化學(xué)習(xí)方案問題;通過樣本增強(qiáng)、拉齊等手段改善性能。

7. 評估機(jī)制
評測結(jié)果可能與線上用戶體驗(yàn)不符,受語言風(fēng)格、評測人員主觀差異、錯(cuò)誤偏好等因素影響。
- 偏向語言風(fēng)格:評測結(jié)果可能更多地反映了模型的語??格,而不是其真實(shí)的能?。恭維、幽默或?qū)I(yè)術(shù)語的使用都可能影響評測結(jié)果。
- 觀點(diǎn)差異:不同的評測人對功能、價(jià)值、及重要性等問題可能有較大的主觀觀點(diǎn)差異,這會(huì)影響評測結(jié)果的一致性和可信度。
- 錯(cuò)誤偏好:如果某個(gè)模型固定會(huì)犯某些錯(cuò)誤,這些錯(cuò)誤可能會(huì)在后續(xù)的評測中更容易被注意到,從而影響結(jié)果。
為了全面保障產(chǎn)品質(zhì)量與可靠性,我們構(gòu)建了一套多層次評估體系,包含自動(dòng)化評估(利用大語言模型、偏好模型、歷史 bad case 驗(yàn)證集合等多維度打分及檢測相關(guān)問題)、多維人工評估(多機(jī)盲評、專員復(fù)檢、GSB 評估保證客觀公平、標(biāo)準(zhǔn)一致和穩(wěn)定性),并且最后有 AB 實(shí)驗(yàn)最終確認(rèn),提升了評測效率和準(zhǔn)確率。

具體的評測流程如下圖所示:

8. 工程優(yōu)化和成本控制
包括系統(tǒng)架構(gòu)升級、全鏈路監(jiān)控體系和成本優(yōu)化三個(gè)方面。
系統(tǒng)基于 DAG 的任務(wù)編排架構(gòu),將核心模塊算子化,便于應(yīng)對新增需求,提升開發(fā)效率;并且實(shí)現(xiàn)了全鏈路監(jiān)控體系,顯著縮短了問題解決的時(shí)間。


成本優(yōu)化方面,通過模型量化在基本不損失效果情況下實(shí)現(xiàn)了 50% 左右的成本降低;對垂直場景采用遷移手段將大模型方案轉(zhuǎn)為專用模型方案,縮小模型尺寸同時(shí)保持 95% 以上專業(yè)性能。

三、直答專業(yè)版介紹
知乎直答專業(yè)版的入口與知乎直答是一樣的,在通用搜索下方,有專業(yè)搜索入口。

直答專業(yè)版具有如下特點(diǎn):
- 引入優(yōu)質(zhì)數(shù)據(jù)源:知乎直答專業(yè)版引入了多種高質(zhì)量的數(shù)據(jù)源,包括維普論文庫、公開英文文獻(xiàn)、知乎精選等內(nèi)容,經(jīng)過嚴(yán)格篩選確保內(nèi)容專業(yè)可信。
- 海量論文期刊數(shù)據(jù)庫:引入國內(nèi)外海量的論文庫和期刊庫,用戶可以全面搜索并獲取相關(guān)原文內(nèi)容,滿足對高質(zhì)量信息的需求。
- 支持學(xué)術(shù)研究和專業(yè)工作:這些優(yōu)質(zhì)的數(shù)據(jù)源為用戶的學(xué)術(shù)研究和專業(yè)工作提供了堅(jiān)實(shí)的基礎(chǔ)和全面的信息支持。
在此基礎(chǔ)上,專業(yè)版還為用戶提供了強(qiáng)大的個(gè)性化知識管理功能,讓用戶可以構(gòu)建和管理自己的專屬知識庫。主要功能包括:
- 文檔上傳:支持 PDF 等多種格式上傳,系統(tǒng)可智能解析文檔內(nèi)容。單輪交互最多支持 99 個(gè)文檔,滿足專業(yè)需求。
- 智能解析:系統(tǒng)自動(dòng)處理上傳的文檔內(nèi)容,支持基于文檔的智能問答功能。
- 定向問答:支持基于個(gè)人知識庫的定向問答,幫助用戶更高效地利用已有知識,打造結(jié)構(gòu)化的知識體系。
同時(shí),支持深度閱讀,在檢索到一些內(nèi)容或是上傳了一些內(nèi)容后,可以開啟深度閱讀模式,對單篇文檔進(jìn)行問答。

為了支持深度閱讀,我們自研了一套智能 PDF 解析方案,以提升閱讀體驗(yàn)。

下一步規(guī)劃主要包括以下幾大方面:
- 融合:將直答與知乎社區(qū)深度融合,滿足用戶「找答案」的需求,提供更加豐富、全面、及時(shí)的內(nèi)容。
- 多模態(tài):拓展更加豐富的交互模式和富媒體結(jié)果展示,讓用戶獲取信息更加便捷生動(dòng)。
- 推理能力:Reasoning 能力 o1 化,使直答具備更強(qiáng)的解決復(fù)雜問題能力
- 專業(yè)化:不斷優(yōu)化專業(yè)版,滿足科研群體的專業(yè)需求,提供極致的使用體驗(yàn)。