













LLM推理暴漲,數(shù)學(xué)邏輯開掛! DeepSeek等華人團(tuán)隊(duì)新大招,Ai2大牛狂點(diǎn)贊
如今,DeepSeek團(tuán)隊(duì)成員的一舉一動(dòng),都頗受圈內(nèi)關(guān)注。
近日,來(lái)自DeepSeek、上海交通大學(xué)、香港科技大學(xué)的研究人員推出的全新力作CODEI/O,就獲得了Ai2大牛Nathan Lambert的力薦!

論文地址:https://arxiv.org/abs/2502.07316
項(xiàng)目主頁(yè):https://codei-o.github.io/
Lambert表示,非常高興能看到DeepSeek團(tuán)隊(duì)成員撰寫的更多論文,而不僅僅是有趣的技術(shù)報(bào)告。(順便還調(diào)侃了一句自己真的想他們了)
這篇論文的主題,是通過(guò)一種CodeI/O的方法,利用代碼輸入/輸出,來(lái)提煉LLM的推理模式。
值得注意的是,這篇論文是一作Junlong Li在DeepSeek實(shí)習(xí)期間完成的研究。
一經(jīng)發(fā)布,網(wǎng)友們就立馬開始了仔細(xì)研究。畢竟,現(xiàn)在在研究人員心目中,DeepSeek已經(jīng)是一個(gè)GOAT team。

有人總結(jié)道,除了主線論文之外,DeepSeek作者還發(fā)表了許多論文,比如Prover 1.0、 ESFT、Fire-Flyer AI-HPC、DreamCraft 3D等等,雖然都是實(shí)習(xí)生的工作,但十分具有啟發(fā)性。

LLM推理缺陷,靠代碼打破
推理,是LLM的一項(xiàng)核心能力。以往的研究主要關(guān)注的是數(shù)學(xué)或代碼等狹窄領(lǐng)域的提升,但在很多推理任務(wù)上,LLM依然面臨挑戰(zhàn)。
原因就在于,訓(xùn)練數(shù)據(jù)稀疏且零散。
對(duì)此,研究團(tuán)隊(duì)提出了一種全新方法——CODEI/O!
CODEI/O通過(guò)將代碼轉(zhuǎn)換為輸入/輸出預(yù)測(cè)格式,從而系統(tǒng)性地提煉出蘊(yùn)含在代碼上下文中的多種推理模式。
研究團(tuán)隊(duì)提出將原始代碼文件轉(zhuǎn)換成可執(zhí)行的函數(shù),并設(shè)計(jì)一個(gè)更直接的任務(wù):給定一個(gè)函數(shù)及其相應(yīng)的文本查詢,模型需要以自然語(yǔ)言的CoT推理形式預(yù)測(cè)給定輸入的執(zhí)行輸出或給定輸出的可行輸入。
這種方法將核心推理流程從代碼特定的語(yǔ)法中解脫出來(lái),同時(shí)保留邏輯的嚴(yán)謹(jǐn)性。通過(guò)收集和轉(zhuǎn)換來(lái)自不同來(lái)源的函數(shù),生成的數(shù)據(jù)包含了各種基礎(chǔ)推理技能,如邏輯流程編排、狀態(tài)空間探索、遞歸分解和決策。
實(shí)驗(yàn)結(jié)果表明,CODEI/O在符號(hào)推理、科學(xué)推理、邏輯推理、數(shù)學(xué)與數(shù)值推理以及常識(shí)推理等任務(wù)上均實(shí)現(xiàn)了一致的性能提升。
下圖1概述了CODEI/O的訓(xùn)練數(shù)據(jù)構(gòu)建流程。該流程從收集原始代碼文件開始,到組裝完整的訓(xùn)練數(shù)據(jù)集結(jié)束。
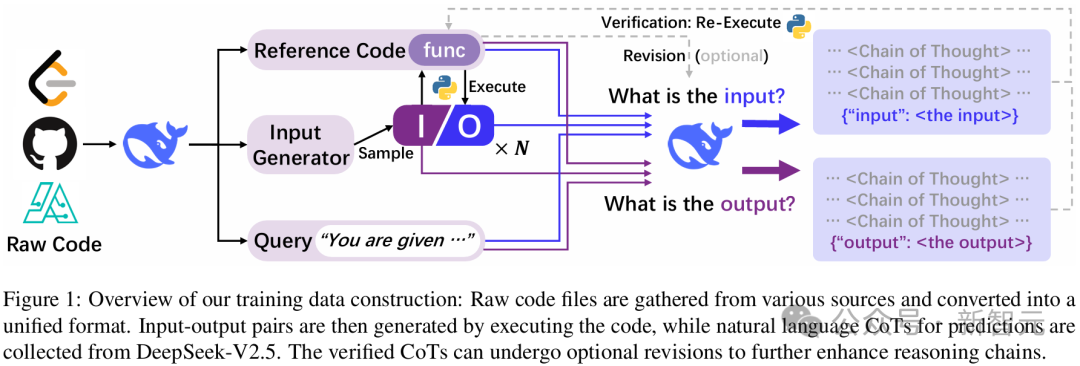
分解CODEI/O架構(gòu)
收集原始代碼文件
CODEI/O的有效性在于選擇多樣化的原始代碼來(lái)源,以涵蓋廣泛的推理模式。
主要的代碼來(lái)源包括:
- CodeMix:從內(nèi)部代碼預(yù)訓(xùn)練語(yǔ)料庫(kù)中檢索的大量原始Python代碼文件集合,經(jīng)過(guò)篩選去除過(guò)于簡(jiǎn)單或過(guò)于復(fù)雜的文件。
- PyEdu-R(推理):Python-Edu的一個(gè)子集,側(cè)重于復(fù)雜的推理任務(wù),如STEM、系統(tǒng)建模或邏輯謎題,并排除以純算法為中心的文件。
- 其他高質(zhì)量代碼文件:來(lái)自各種小型、信譽(yù)良好的來(lái)源,包括綜合算法存儲(chǔ)庫(kù)、具有挑戰(zhàn)性的數(shù)學(xué)問(wèn)題和知名的在線編碼平臺(tái)。
合并這些來(lái)源后,總共產(chǎn)生了大約810.5K個(gè)代碼文件。

構(gòu)造的LeetCode-O基準(zhǔn)測(cè)試中的一個(gè)示例
轉(zhuǎn)換為統(tǒng)一格式
收集到的原始代碼文件往往結(jié)構(gòu)混亂,含有冗余內(nèi)容,并且難以獨(dú)立執(zhí)行。
使用DeepSeek-V2.5對(duì)原始代碼文件進(jìn)行預(yù)處理,將其提煉成統(tǒng)一的格式,強(qiáng)調(diào)主要的邏輯功能,使其可執(zhí)行,以便收集輸入-輸出對(duì)。
研究團(tuán)隊(duì)通過(guò)清理和重構(gòu)代碼,將核心邏輯功能提取到函數(shù)中,排除不必要的元素,然后添加一個(gè)主要入口點(diǎn)函數(shù),總結(jié)代碼的整體邏輯。
該函數(shù)可以調(diào)用其他函數(shù)或?qū)胪獠繋?kù),并且必須具有非空的參數(shù)(輸入)以及返回有意義的輸出。所有輸入和輸出都需要是JSON可序列化的,以方便進(jìn)一步處理。
過(guò)程中需明確定義主要入口點(diǎn)函數(shù)的輸入和輸出,包括數(shù)據(jù)類型、約束(例如,輸出范圍)或更復(fù)雜的要求(例如,字典中的鍵)等信息。
然后創(chuàng)建一個(gè)獨(dú)立的、基于規(guī)則的Python輸入生成器函數(shù),而不是直接生成測(cè)試用例。此生成器返回遵循主要入口點(diǎn)函數(shù)要求的非平凡輸入。在約束條件下應(yīng)用隨機(jī)性,實(shí)現(xiàn)可擴(kuò)展的數(shù)據(jù)生成。
最后,根據(jù)主要入口點(diǎn)函數(shù)生成一個(gè)簡(jiǎn)潔的問(wèn)題陳述,作為描述代碼預(yù)期功能的查詢。

如何將原始代碼文件轉(zhuǎn)換為所需同一格式的示例
收集輸入和輸出對(duì)
在將收集的原始代碼文件轉(zhuǎn)換為統(tǒng)一格式后,使用輸入生成器為每個(gè)函數(shù)抽樣多個(gè)輸入,并通過(guò)執(zhí)行代碼獲得相應(yīng)的輸出。
為了確保輸出是確定性的,會(huì)跳過(guò)所有包含隨機(jī)性的函數(shù)。在執(zhí)行這些代碼期間,研究團(tuán)隊(duì)還會(huì)對(duì)運(yùn)行時(shí)和輸入/輸出對(duì)象的復(fù)雜性施加一系列限制。
在過(guò)濾掉不可執(zhí)行的代碼、超過(guò)運(yùn)行時(shí)限制的樣本以及超過(guò)所需復(fù)雜性的輸入-輸出對(duì)后,獲得了從454.9K個(gè)原始代碼文件派生的3.5M個(gè)實(shí)例。輸入和輸出預(yù)測(cè)實(shí)例的分布大致平衡,各占 50%。
構(gòu)建輸入輸出預(yù)測(cè)樣本
收集輸入-輸出對(duì)以及轉(zhuǎn)換后的函數(shù)后,需要將它們組合成可訓(xùn)練的格式。
研究團(tuán)隊(duì)采用的有監(jiān)督微調(diào)過(guò)程,每個(gè)訓(xùn)練樣本都需要一個(gè)提示和一個(gè)響應(yīng)。由于目標(biāo)是輸入-輸出預(yù)測(cè)任務(wù),研究團(tuán)隊(duì)使用設(shè)計(jì)的模板將函數(shù)、查詢、參考代碼以及特定的輸入或輸出組合起來(lái)構(gòu)建提示。
理想情況下,響應(yīng)應(yīng)該是一個(gè)自然語(yǔ)言的CoT,用于推理如何得出正確的輸出或可行的輸入。
研究團(tuán)隊(duì)主要通過(guò)以下兩種方式構(gòu)建所需的CoT響應(yīng)。
· 直接提示(CODEI/O)
使用DeepSeek-V2.5合成所有需要的響應(yīng),因?yàn)樗哂许敿?jí)的性能,但成本極低。此處生成的數(shù)據(jù)集稱為 CODEI/O。
下圖2展示了CODEI/O數(shù)據(jù)集中輸入和輸出預(yù)測(cè)的2個(gè)示例,在這兩種情況下,模型都需要以自然語(yǔ)言的思維鏈 (CoT)形式給出推理過(guò)程。

· 充分利用代碼(CODEI/O++)
對(duì)于預(yù)測(cè)不正確的響應(yīng),將反饋?zhàn)鳛榈诙嗇斎胂⒆芳樱⒁驞eepSeek-V2.5重新生成另一個(gè)響應(yīng)。將所有四個(gè)組件連接起來(lái):第一輪響應(yīng)+第一輪反饋+第二輪響應(yīng)+第二輪反饋。研究人員將通過(guò)這種方式收集的數(shù)據(jù)集稱為CODEI/O++。

CODEI/O++中的一個(gè)完整訓(xùn)練樣本
一個(gè)框架,彌合代碼推理與自然語(yǔ)言鴻溝
如下表1所示,主要展示了Qwen 2.5 7B Coder 、Deepseek v2 Lite Coder、LLaMA 3.1 8B、Gemma 2 27B模型的評(píng)估結(jié)果。
CODEI/O在各項(xiàng)基準(zhǔn)測(cè)試中,模型的性能均實(shí)現(xiàn)了提升,其表現(xiàn)優(yōu)于單階段基線模型和其他數(shù)據(jù)集(即使是更大規(guī)模的數(shù)據(jù)集)。
不過(guò),競(jìng)爭(zhēng)數(shù)據(jù)集,比如OpenMathInstruct2在數(shù)學(xué)特定任務(wù)上表現(xiàn)出色,但在其他任務(wù)上有會(huì)出現(xiàn)退步(混合綠色和紅色單元格)。
CODEI/O展現(xiàn)出的是,持續(xù)改進(jìn)的趨勢(shì)(綠色單元格)。
盡管其僅使用以代碼為中心的數(shù)據(jù),在提升代碼推理能力同時(shí),還增強(qiáng)了所有其他任務(wù)的表現(xiàn)。
研究人員還觀察到,與單階段基線相比,使用原始代碼文件(PythonEdu)進(jìn)行訓(xùn)練,只能帶來(lái)微小的改進(jìn),有時(shí)甚至?xí)a(chǎn)生負(fù)面影響。
與CODEI/O相比表現(xiàn)明顯不足,這表明從這種結(jié)構(gòu)性較差的數(shù)據(jù)中學(xué)習(xí)是次優(yōu)的。
這進(jìn)一步強(qiáng)調(diào)了性能提升,不僅僅取決于數(shù)據(jù)規(guī)模,更重要的是經(jīng)過(guò)深思熟慮設(shè)計(jì)的訓(xùn)練任務(wù)。
這些任務(wù)包含了廣義思維鏈中多樣化、結(jié)構(gòu)化的推理模式。
此外,CODEI/O++系統(tǒng)性地超越了CODEI/O,在不影響單個(gè)任務(wù)性能的情況下提高了平均分?jǐn)?shù)。
這突顯了基于執(zhí)行反饋的多輪修訂,可以提升數(shù)據(jù)質(zhì)量并增強(qiáng)跨領(lǐng)域推理能力。
最重要的是,CODEI/O和CODEI/O++都展現(xiàn)出了跨模型規(guī)模和架構(gòu)的普遍有效性。
這進(jìn)一步驗(yàn)證了實(shí)驗(yàn)的訓(xùn)練方法(預(yù)測(cè)代碼輸入和輸出),使模型能夠在不犧牲專業(yè)基準(zhǔn)性能的情況下,在各種推理任務(wù)中表現(xiàn)出色。

為了進(jìn)一步研究,新方法中不同關(guān)鍵方面的影響,研究人員進(jìn)行了多組分析實(shí)驗(yàn)。
所有實(shí)驗(yàn)均使用Qwen 2.5 Coder 7B模型進(jìn)行,且報(bào)告的結(jié)果均為經(jīng)過(guò)第二階段通用指令微調(diào)后獲得的結(jié)果。
消融實(shí)驗(yàn)
研究團(tuán)隊(duì)首先對(duì)數(shù)據(jù)構(gòu)建過(guò)程進(jìn)行了兩項(xiàng)關(guān)鍵的消融研究,結(jié)果如下表2所示。
輸入/輸出預(yù)測(cè)
作者通過(guò)分別訓(xùn)練,來(lái)研究輸入和輸出預(yù)測(cè)。
結(jié)果顯示,總體得分相似,但輸入預(yù)測(cè)在KorBench上表現(xiàn)出色,同時(shí)略微影響了GPQA的表現(xiàn);而輸出預(yù)測(cè)在BBH等符號(hào)推理任務(wù)上顯示出更大的優(yōu)勢(shì)。CRUXEval-I和-O分別偏向于輸入和輸出預(yù)測(cè)。
拒絕采樣
他們還探索了使用拒絕采樣來(lái)過(guò)濾不正確響應(yīng)的方法,這導(dǎo)致50%的訓(xùn)練數(shù)據(jù)被刪除。然而,這造成了普遍的性能下降,表明可能損失了數(shù)據(jù)的多樣性。
作者還嘗試通過(guò)代碼執(zhí)行將所有不正確的響應(yīng),替換為正確答案(不包含思維鏈)。
這種方法在LeetCode-O和CRUXEval-O等設(shè)計(jì)用于衡量輸出預(yù)測(cè)準(zhǔn)確性的基準(zhǔn)測(cè)試上,確實(shí)帶來(lái)了改進(jìn),但在其他方面降低了分?jǐn)?shù),導(dǎo)致平均性能下降。
當(dāng)將這兩種方法與訓(xùn)練在樣本數(shù)量相當(dāng)?shù)腃ODEI/O約50%子集上進(jìn)行比較時(shí),它們?nèi)匀粵](méi)有顯示出優(yōu)勢(shì)。
因此,為了保持性能平衡,研究人員在主要實(shí)驗(yàn)中保留了所有不正確的響應(yīng),不做任何修改。
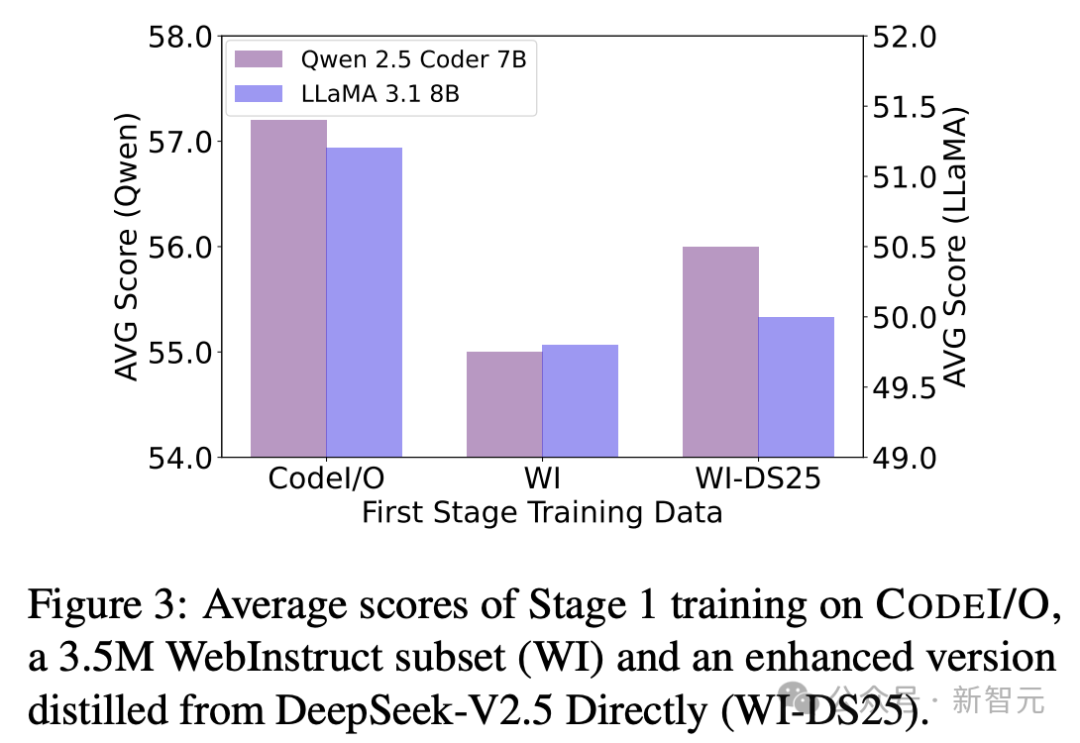
不同合成模型的效果
為了研究不同綜合模型的效果,作者使用DeepSeek-V2.5重新生成了350萬(wàn)條WebInstruct數(shù)據(jù)集的響應(yīng),創(chuàng)建了一個(gè)更新的數(shù)據(jù)集,稱為WebInstruct-DS25。
如圖3所示,雖然WebInstruct-DS25在Qwen 2.5 Coder 7B和LLaMA 3.1 8B上,表現(xiàn)優(yōu)于原始數(shù)據(jù)集,但仍然不及CODEI/O。
這突顯了代碼中多樣化推理模式的價(jià)值,以及訓(xùn)練中任務(wù)選擇的重要性。
總的來(lái)說(shuō),這個(gè)比較表明,預(yù)測(cè)代碼的輸入和輸出能夠提升推理能力,而不僅僅是從高級(jí)模型中進(jìn)行知識(shí)蒸餾。
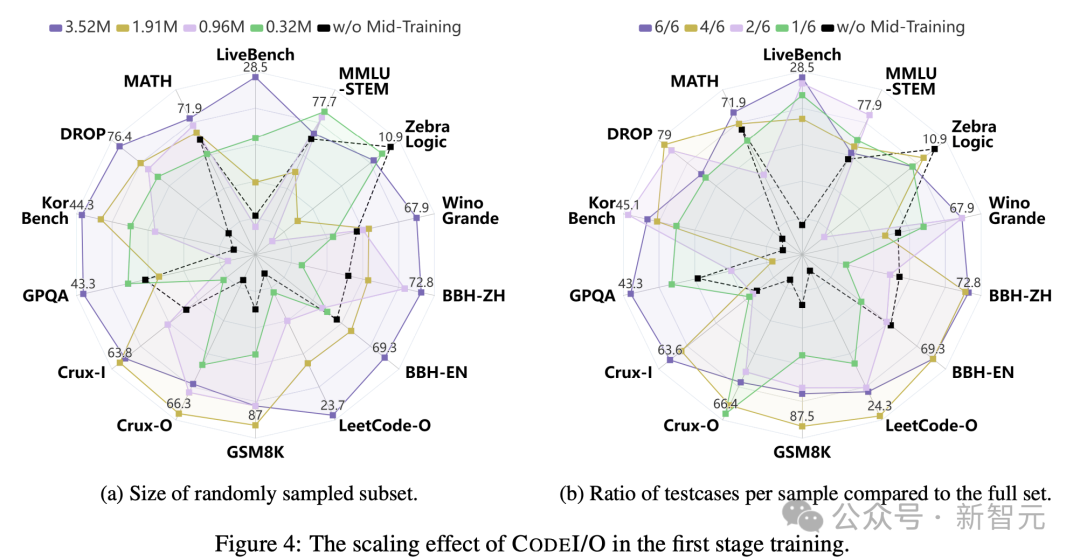
CODEI/O的Scaling效應(yīng)
研究人員還評(píng)估了CODEI/O在不同訓(xùn)練數(shù)據(jù)量下的表現(xiàn)。
通過(guò)隨機(jī)抽樣訓(xùn)練實(shí)例,圖4a揭示了一個(gè)明顯的趨勢(shì):增加訓(xùn)練樣本數(shù)量,通常會(huì)導(dǎo)致各項(xiàng)基準(zhǔn)測(cè)試的性能提升。
具體來(lái)說(shuō),使用最少量的數(shù)據(jù)在大多數(shù)基準(zhǔn)測(cè)試中表現(xiàn)相對(duì)較弱,因?yàn)槟P腿狈ψ銐虻挠?xùn)練來(lái)有效泛化。
相比之下,在完整數(shù)據(jù)集上訓(xùn)練時(shí),CODEI/O實(shí)現(xiàn)了最全面和穩(wěn)健的性能。
中等數(shù)量的數(shù)據(jù)產(chǎn)生的結(jié)果介于這兩個(gè)極端之間,隨著訓(xùn)練樣本的增加表現(xiàn)出逐步改善。這突顯了CODEI/O在提升推理能力方面的可擴(kuò)展性和有效性。
此外,他們還在輸入-輸出對(duì)的維度上進(jìn)行了數(shù)據(jù)scaling,方法是固定并使用所有唯一的原始代碼樣本,但改變每個(gè)樣本的輸入-輸出預(yù)測(cè)實(shí)例數(shù)量。
圖4b顯示了,使用的I/O對(duì)相對(duì)于完整集合的比例。
雖然scaling效應(yīng)不如訓(xùn)練樣本明顯,但仍可以觀察到明顯的益處,特別是在從1/6增加到6/6時(shí)。
這表明,某些推理模型需要多個(gè)測(cè)試用例,才能完全捕獲和學(xué)習(xí)其復(fù)雜的邏輯流程。
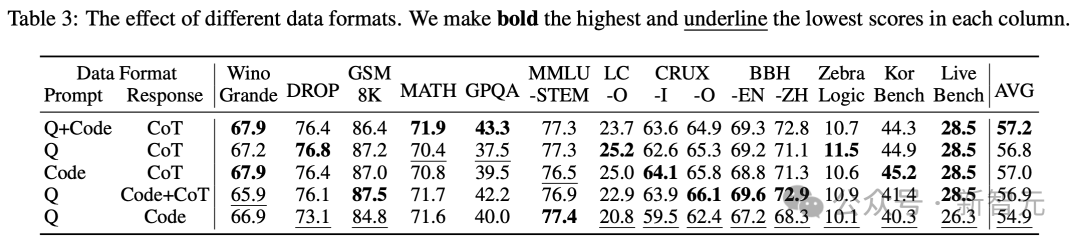
不同的數(shù)據(jù)格式
這一部分,主要研究了如何在訓(xùn)練樣本中最佳安排查詢、參考代碼和思維鏈(CoT)。
如表3所示,將查詢和參考代碼放在提示中,而將思維鏈放在響應(yīng)中,可以在各項(xiàng)基準(zhǔn)測(cè)試中實(shí)現(xiàn)最高的平均分?jǐn)?shù)和最平衡的性能。
其他格式的結(jié)果顯示出,略低但相當(dāng)?shù)男阅埽畈畹慕Y(jié)果出現(xiàn)在查詢放在提示中,而參考代碼放在響應(yīng)中的情況。
這類似于標(biāo)準(zhǔn)的代碼生成任務(wù),但訓(xùn)練樣本要少得多。
這突顯了思維鏈和測(cè)試用例的規(guī)模對(duì)于學(xué)習(xí)可遷移推理能力的重要性。
多輪迭代
基于CODEI/O(無(wú)修訂)和CODEI/O++(單輪修訂),研究人員將修訂擴(kuò)展到第二輪,通過(guò)對(duì)第一輪修訂后仍然不正確的實(shí)例,重新生成預(yù)測(cè)來(lái)評(píng)估進(jìn)一步的改進(jìn)。
如下圖7中,可視化了每一輪中響應(yīng)類型的分布。
結(jié)果顯示,大多數(shù)正確的響應(yīng)都在初始輪中預(yù)測(cè)出來(lái),約10%的錯(cuò)誤響應(yīng)在第一輪修訂中得到糾正。
然而,第二輪產(chǎn)生的糾正顯著減少,通過(guò)檢查案例作者發(fā)現(xiàn)模型經(jīng)常重復(fù)相同的錯(cuò)誤CoT,而沒(méi)有添加新的有用信息。
在整合多輪修訂后,他們?cè)趫D5中觀察到從第0輪到第1輪有持續(xù)的改進(jìn),但從第1輪到第2輪的收益很小——對(duì)LLaMA 3.1 8B顯示出輕微改進(jìn),但對(duì)Qwen 2.5 Coder 7B反而出現(xiàn)了性能下降。
因此,在主要的實(shí)驗(yàn)中,研究人員停留在了單輪修訂,即CODEI/O++。

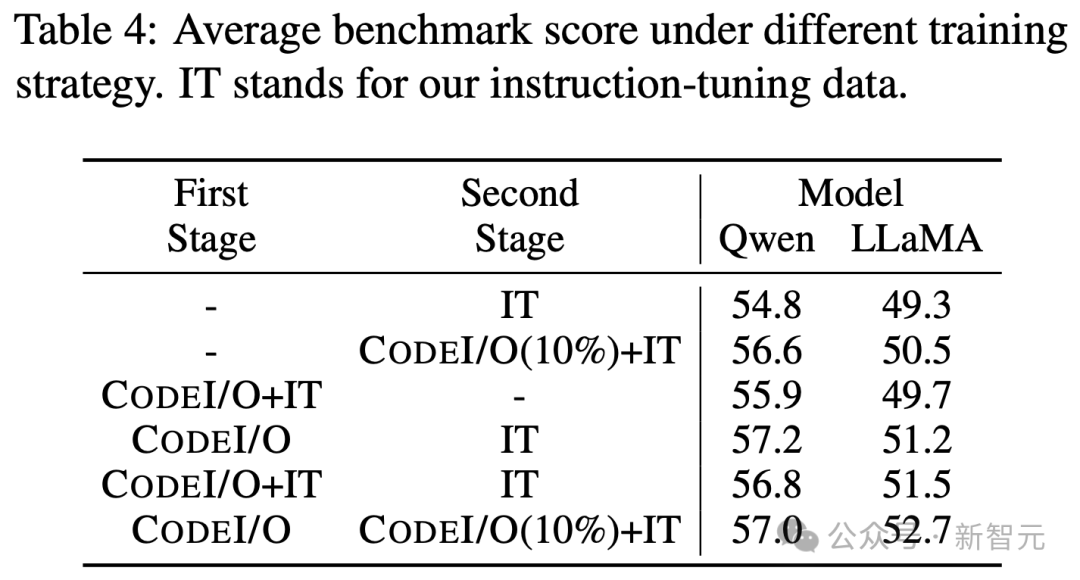
兩階段訓(xùn)練的必要性
最后,研究人員通過(guò)測(cè)試單階段混合訓(xùn)練和不同數(shù)據(jù)混合的兩階段訓(xùn)練,強(qiáng)調(diào)了使用CODEI/O數(shù)據(jù)進(jìn)行單獨(dú)訓(xùn)練階段的必要性。
如表4所示,所有兩階段變體模型的表現(xiàn)都優(yōu)于單階段訓(xùn)練。
同時(shí),兩階段訓(xùn)練期間混合數(shù)據(jù)的效果在不同模型間有所不同。
對(duì)于Qwen 2.5 Coder 7B,最好的結(jié)果是將CODEI/O和指令微調(diào)數(shù)據(jù)完全分開,而LLaMA 3.1 8B在混合數(shù)據(jù)的情況下表現(xiàn)更好,無(wú)論是在第一階段還是第二階段。
論文作者
Junlong Li

Junlong Li是上交計(jì)算機(jī)科學(xué)專業(yè)的三年級(jí)碩士生,師從Hai Zhao教授。
此前,他于2022年在上交IEEE試點(diǎn)班獲得計(jì)算機(jī)科學(xué)學(xué)士學(xué)位。
他曾在微軟亞洲研究院(MSRA)NLC組擔(dān)任研究實(shí)習(xí)生,在Lei Cui博士的指導(dǎo)下,參與了多個(gè)與Document AI相關(guān)的研究課題,包括網(wǎng)頁(yè)理解和文檔圖像基礎(chǔ)模型。
2023年5月至2024年2月期間,他與GAIR的Pengfei Liu教授緊密合作,主要研究LLMs的評(píng)估與對(duì)齊等方面的問(wèn)題。
目前,他在Junxian He教授的指導(dǎo)下從事相關(guān)研究。
Daya Guo

Daya Guo在中山大學(xué)和微軟亞洲研究院聯(lián)合培養(yǎng)下攻讀博士學(xué)位,并由Jian Yin教授和Ming Zhou博士共同指導(dǎo)。目前在DeepSeek擔(dān)任研究員。
2014年到2018年,他在中山大學(xué)取得計(jì)算機(jī)科學(xué)學(xué)士學(xué)位。2017年到2023年,他曾在微軟亞洲研究院擔(dān)任研究實(shí)習(xí)生。
他的研究主要聚焦于自然語(yǔ)言處理和代碼智能,旨在使計(jì)算機(jī)能夠智能地處理、理解和生成自然語(yǔ)言與編程語(yǔ)言。長(zhǎng)期研究目標(biāo)是推動(dòng)AGI的發(fā)展,從而徹底改變計(jì)算機(jī)與人類的交互方式,并提升其處理復(fù)雜任務(wù)的能力。
目前,他的研究方向包括:(1)大語(yǔ)言模型(Large Language Model);(2)代碼智能(Code Intelligence)。
Runxin Xu(許潤(rùn)昕)

Runxin Xu是DeepSeek的研究科學(xué)家,曾深度參與DeepSeek系列模型的開發(fā),包括DeepSeek-R1、DeepSeek V1/V2/V3、DeepSeek Math、DeepSeek Coder、DeepSeek MoE等。
此前,他在北京大學(xué)信息科學(xué)技術(shù)學(xué)院獲得碩士學(xué)位,由Baobao Chang博士和Zhifang Sui博士指導(dǎo),并在上海交通大學(xué)完成本科學(xué)業(yè)。
他的研究興趣主要聚焦于AGI,致力于通過(guò)可擴(kuò)展和高效的方法不斷推進(jìn)AI智能的邊界。
Yu Wu(吳俁)

Yu Wu目前是DeepSeek技術(shù)人員,負(fù)責(zé)領(lǐng)導(dǎo)LLM對(duì)齊團(tuán)隊(duì)。
他曾深度參與了DeepSeek系列模型的開發(fā),包括DeepSeek V1、V2、V3、R1、DeepSeek Coder和DeepSeek Math。
在此之前,他曾在微軟亞洲研究院(MSRA)自然語(yǔ)言計(jì)算組任高級(jí)研究員。
他獲得了北京航空航天大學(xué)的學(xué)士學(xué)位和博士學(xué)位,師從Ming Zhou和Zhoujun Li教授。
他本人的研究生涯取得了諸多成就,包括在ACL、EMNLP、NeurIPS、AAAI、IJCAI和ICML等頂級(jí)會(huì)議和期刊上發(fā)表了80多篇論文。
他還發(fā)布了多個(gè)具有影響力的開源模型,包括WavLM、VALL-E、DeepSeek Coder、DeepSeek V3和DeepSeek R1。
Junxian He(何俊賢)

Junxian He現(xiàn)任香港科技大學(xué)計(jì)算機(jī)科學(xué)與工程系助理教授(終身教職)。
他于2022年在卡內(nèi)基梅隆大學(xué)語(yǔ)言技術(shù)研究所獲得博士學(xué)位,由Graham Neubig和Taylor Berg-Kirkpatrick共同指導(dǎo)。他還于2017年獲得上海交通大學(xué)電子工程學(xué)士學(xué)位。
此前,Junxian He還曾在Facebook AI研究院(2019年)和Salesforce研究院(2020年)工作過(guò)一段時(shí)間。






























