













最強全模態模型Ola-7B橫掃圖像、視頻、音頻主流榜單,騰訊混元Research&清華&NTU聯手打造
Ola 是騰訊混元 Research、清華大學智能視覺實驗室(i-Vision Group)和南洋理工大學 S-Lab 的合作項目。本文的共同第一作者為清華大學自動化系博士生劉祖炎和南洋理工大學博士生董宇昊,本文的通訊作者為騰訊高級研究員饒永銘和清華大學自動化系魯繼文教授。
GPT-4o 的問世引發了研究者們對實現全模態模型的濃厚興趣。盡管目前已經出現了一些開源替代方案,但在性能方面,它們與專門的單模態模型相比仍存在明顯差距。在本文中,我們提出了 Ola 模型,這是一款全模態語言模型,與同類的專門模型相比,它在圖像、視頻和音頻理解等多個方面都展現出了頗具競爭力的性能。
Ola 的核心設計在于其漸進式模態對齊策略,該策略逐步擴展語言模型所支持的模態。我們的訓練流程從差異最為顯著的模態開始:圖像和文本,隨后借助連接語言與音頻知識的語音數據,以及連接所有模態的視頻數據,逐步拓展模型的技能集。這種漸進式學習流程還使我們能夠將跨模態對齊數據維持在相對較小的規模,從而讓基于現有視覺 - 語言模型開發全模態模型變得更為輕松且成本更低。

- 項目地址:https://ola-omni.github.io/
- 論文:https://arxiv.org/abs/2502.04328
- 代碼:https://github.com/Ola-Omni/Ola
- 模型:https://huggingface.co/THUdyh/Ola-7b
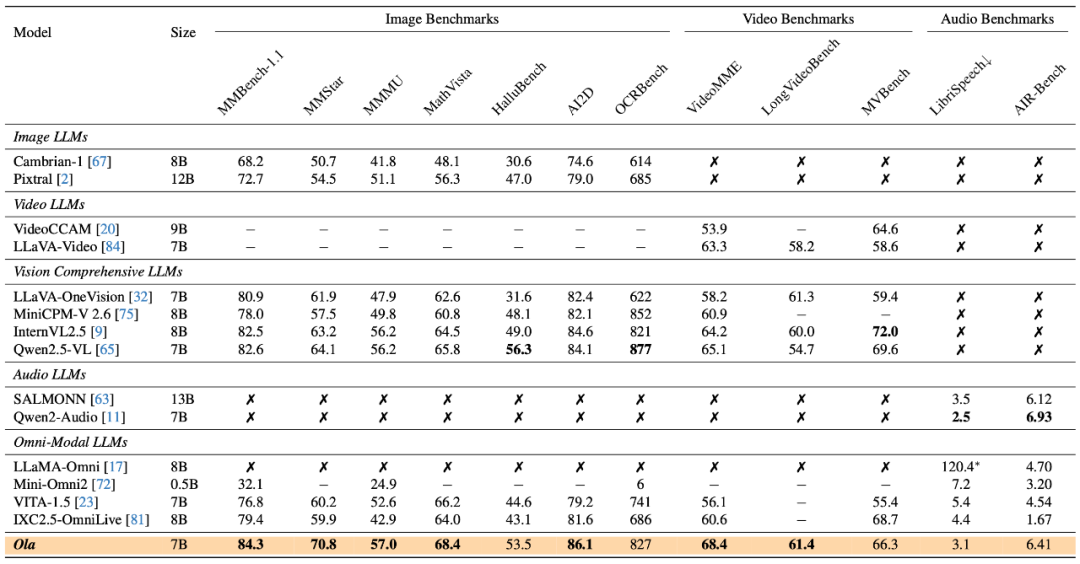
Ola 模型大幅度推動了全模態模型在圖像、視頻和音頻理解評測基準中的能力上限。我們在涵蓋圖像、視頻和音頻等方面的完整全模態基準測試下,Ola 作為一個僅含有 7B 參數的全模態模型,實現了對主流專有模型的超越。
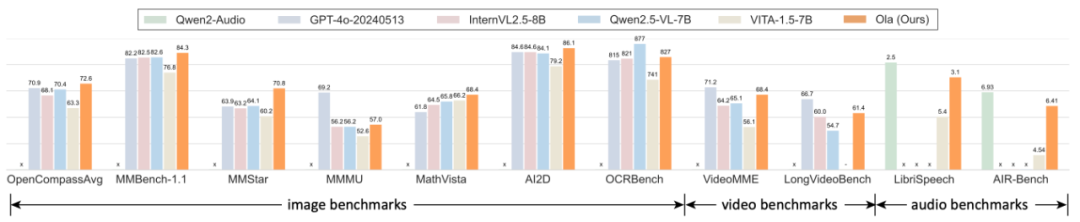
圖 1:Ola 全模態模型超越 Qwen2.5-VL、InternVL2.5 等主流多模態模型。
在圖像基準測試方面,在極具挑戰性的 OpenCompass 基準測試中,其在 MMBench-1.1、MMMU 等 8 個數據集上的總體平均準確率達到 72.6%,在市面上所有 30B 參數以內的模型中排名第 1,超越了 GPT-4o、InternVL2.5、Qwen2.5-VL 等主流模型。在綜合視頻理解測試 VideoMME 中,Ola 在輸入視頻和音頻的情況下,取得了 68.4% 的準確率,超越了 LLaVA-Video、VideoLLaMA3 等知名的視頻多模態模型。另一方面,Ola 在諸如語音識別和聊天評估等音頻理解任務方面也表現卓越,達到了接近最好音頻理解模型的水平。
完整的測試結果表明,與現有的全模態大語言模型(如 VITA-1.5、IXC2.5-OmniLive 等)相比,Ola 有巨大的性能提升,甚至超越了最先進的專有多模態模型的性能,包括最新發布的 Qwen2.5-VL、InternVL2.5 等。目前,模型、代碼、訓練數據已經開源,我們旨在將 Ola 打造成為一個完全開源的全模態理解解決方案,以推動這一新興領域的未來研究。
1. 介紹
訓練全模態大模型的核心挑戰在于對于多種分布的模態進行建模,并設計有效的訓練流程,從而在所有支持的任務上實現有競爭力且均衡的性能。然而,在以往的研究中,高性能與廣泛的模態覆蓋往往難以兼顧,現有的開源全模態解決方案與最先進的專用大語言模型之間仍存在較大的性能差距,這給全模態概念在現實世界的應用帶來了嚴重障礙。
在本文中,我們提出了 Ola 模型,探索如何訓練出性能可與最先進的專用多模態模型相媲美、具備實時交互能力且在對齊數據上高效的全模態大語言模型。Ola 模型的核心設計是漸進式模態對齊策略。為在語言與視覺之間建立聯系,我們從圖像和文本這兩種基礎且相互獨立的模態入手,為全模態模型構建基礎知識。隨后,我們逐步擴充訓練集,賦予模型更廣泛的能力,包括通過視頻幀強化視覺理解能力,借助語音數據連通語言與音頻知識,以及利用包含音頻的視頻全面融合來自語言、視頻和音頻的信息。這種漸進式學習策略將復雜的訓練過程分解為小步驟,使全模態學習變得更容易,從而保持較小規模的跨模態對齊數據,也更容易基于視覺 - 語言模型的現有成果展開研究。
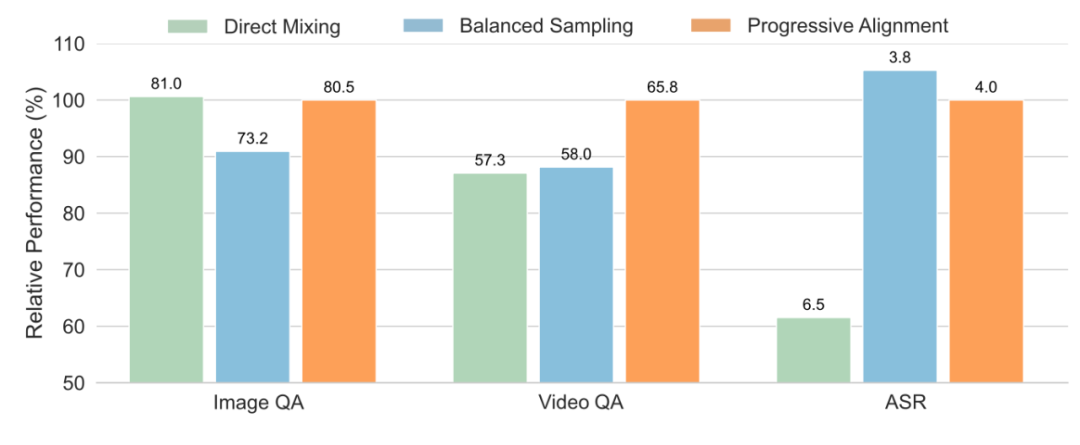
圖 2:漸進式模態學習能夠訓練更好的全模態模型
為配合訓練策略,我們在架構和數據領域也進行了重要改進。
- Ola 架構支持全模態輸入以及流式文本和語音生成,其架構設計可擴展且簡潔。我們為視覺和音頻設計了聯合對齊模塊,通過局部 - 全局注意力池化層融合視覺輸入,并實現視覺、音頻和文本標記的自由組合。此外,我們集成了逐句流式解碼模塊以實現高質量語音合成。
- 除了在視覺和音頻方面收集的微調數據外,我們深入挖掘視頻與其對應音頻之間的關系,以構建視覺與音頻模態之間的橋梁。具體而言,我們從學術及開放式網絡資源收集原始視頻,設計獨立的清理流程,然后利用視覺 - 語言模型根據字幕和視頻內容生成問答對。
2. 方法概覽
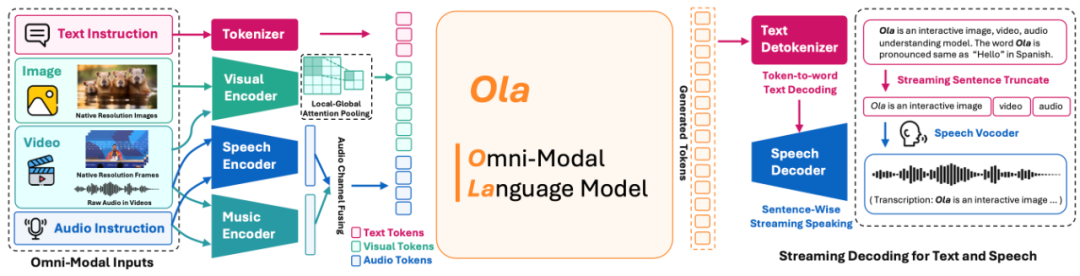
圖 3:Ola 模型結構圖
全模態結構設計
全模態輸入編碼:基于先前文本到單模態大語言模型的成功實踐,我們分別對視覺、音頻和文本輸入進行編碼。對于視覺輸入,我們使用任意分辨率視覺編碼器 OryxViT 進行編碼,保留每個圖像或幀的原始寬高比;對于音頻輸入,我們提出雙編碼器方法,使用 Whisper-v3 作為語音編碼器,BEATs 作為音樂編碼器;對于文本輸入,我們直接使用預訓練大語言模型中的嵌入層來處理文本標記。
視覺與音頻聯合對齊:對齊模塊充當從特定模態空間到文本嵌入空間的轉換器,這是全模態大語言模型的關鍵部分。為了提高效率并減少視覺特征的標記長度,我們進一步提出了 “局部 - 全局注意力池化” 層,以在減少信息損失的情況下獲得更好的下采樣特征。具體而言,我們采用雙線性插值進行 2 倍下采樣以獲得全局特征,將原始特征和全局特征結合用于局部 - 全局嵌入,并使用 Softmax 預測每個下采樣空間區域的重要性,此后通過哈達瑪積確定每個先前區域的權重。
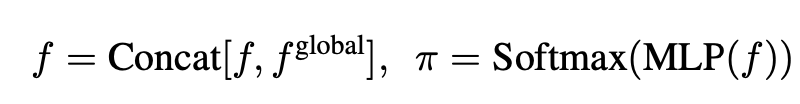
我們參照先前的工作,應用兩層非線性 MLP 將特定模態特征投影到語言空間中。
流式語音生成:我們采用 CosyVoice 作為高質量的語音解碼器進行語音生成。為支持用戶友好的流式解碼,我們實時檢測生成的文本標記,一旦遇到標點符號就截斷句子。隨后,將前一個句子輸入語音解碼器進行音頻合成。因此,Ola 無需等待整個句子完成即可支持流式解碼。
漸進式模態對齊策略
語言、視覺與音頻之間的模態差距:通過探索,我們認識到全模態訓練中的兩個關鍵問題。
- 模態平衡:直接合并來自所有模態的數據會對基準性能產生負面影響。我們認為,文本和圖像是全模態學習中的核心模態,而語音和視頻分別是文本和圖像的變體。學會識別文本和圖像可確保模型具備基本的跨模態能力,所以我們優先處理這些較難的情況。隨后,我們逐步將視頻、音頻和語音納入全模態大語言模型的訓練中。
- 音頻與視覺之間的聯系:在全模態學習中,聯合學習音頻和視覺數據能夠通過提供跨不同模態的更全面視角,產生令人驚喜的結果。對于 Ola 模型,我們將視頻視為音頻與視覺之間的橋梁,因為視頻在幀與伴隨音頻之間包含自然、豐富且高度相關的信息。我們通過優化訓練流程和準備有針對性的訓練數據來驗證這一假設。
在訓練流程中,訓練階段 1 為文本 - 圖像訓練,包括 MLP 對齊、大規模預訓練以及監督微調;階段 2 為圖像與視頻的持續訓練,利用視頻數據持續擴展 Ola 的能力;階段 3 為通過視頻連接視覺與音頻,我們遵循視覺 MLP 適配器的訓練策略,同時通過基本的 ASR 任務初始化音頻 MLP。然后,我們將文本與語音理解、文本與音樂理解、音頻與視頻聯合理解以及最重要的文本 - 圖像多模態任務混合在一起進行正式訓練。在這個階段,Ola 專注于學習音頻識別以及識別視覺與音頻之間的關系,訓練完成后,便得到一個能夠綜合理解圖像、視頻和音頻的模型。
全模態訓練數據
圖像數據中,在大規模預訓練階段,我們從開源數據和內部數據中收集了約 20M 個文本 - 圖像數據對;對于 SFT 數據,我們從 LLaVA-Onevision、Cauldron、Cambrian-1、Mammoth-VL、PixMo 等數據集中混合了約 7.3M 圖像訓練數據。視頻數據中,我們從 LLaVA-Video-178k、VideoChatGPT-Plus、LLaVA-Hound、Cinepile 中收集了 1.9M 個視頻對話數據。音頻數據中,我們設計了 ASR、音頻字幕、音頻問答、音樂字幕、音樂問答等文本 - 語音理解任務,總體音頻訓練數據包含 1.1M 個樣本,相關的文本問答表示則從 SALMONN 數據集中收集。
進一步地,我們構造了一種跨模態視頻數據的生成方法,旨在揭示視頻與音頻之間的內在關系,引導全模態大語言模型學習跨模態信息。現有的大多數視頻訓練數據僅從幀輸入進行注釋或合成,常常忽略了伴隨音頻中的寶貴信息。具體而言,我們為跨模態學習開發了兩個任務:視頻 - 音頻問答和視頻語音識別。我們使用視覺 - 語言模型基于視頻和相應字幕生成問題和答案,并要求模型以字幕輸入為重點,同時將視頻作為補充信息生成問答。我們為每個視頻創建了 3 個問答對,獲取了 243k 個跨模態視頻 - 音頻數據。此外,我們還納入了包含 83k 個訓練數據的原始視頻字幕任務,以幫助模型在嘈雜環境中保持其語音識別能力。
3. 實驗結果
全模態理解
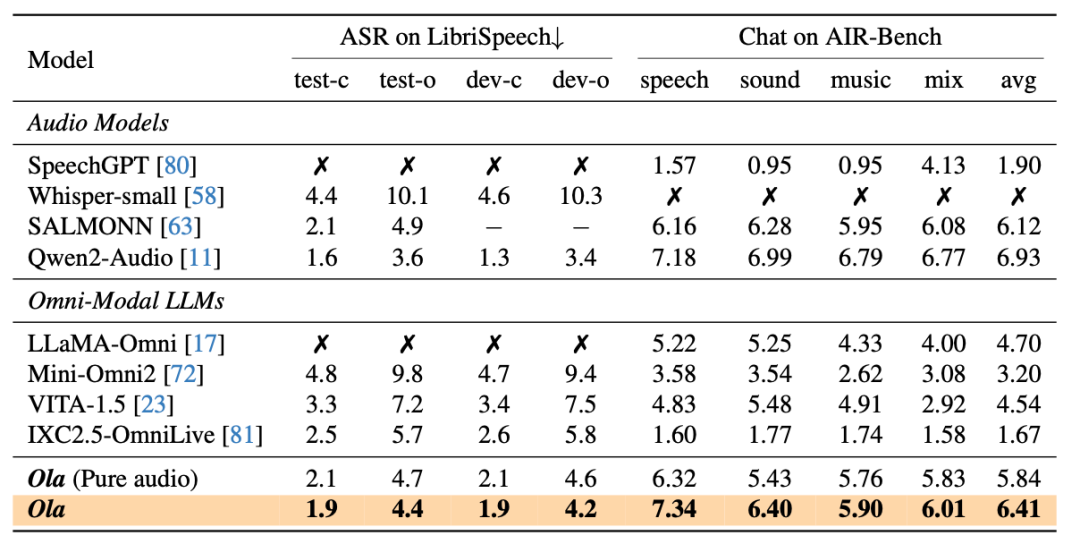
與當前最先進的多模態大語言模型和全模態模型相比,Ola 在主要多模態基準測試中表現出極強的競爭力。具體而言,在圖像基準測試中,Ola 在 MMBench-1.1 中達到 84.3%,在 MMStar 上達到 70.8%,在 MMMU 上達到 57.0%,超越了所有參數數量相近的相關多模態大語言模型。在視頻基準測試中,Ola 在 VideoMME 上取得了 68.4% 的準確率。在音頻基準測試中,Ola 在 LibriSpeech 上的 WER 為 3.1%,在 AIR-Bench 上的平均得分為 6.41,超過了現有的全模態模型。
音頻評測集上的分析
在音頻評測集上的細節結果表明,Ola 相較于現有的全模態模型展現出顯著優勢,甚至接近專門的音頻模型,突顯了其強大的通用性。此外,我們可以觀察到通過跨模態聯合學習,性能仍有穩定提升。盡管視頻音頻與語音相關數據集之間存在顯著的分布差異,但這種提升表明了視頻與語音模態之間存在穩固的聯系。
全模態訓練的影響
通過比較全模態訓練前后的結果,我們發現在 VideoMME 上的性能從 63.8% 提升到了 64.4%。此外,在原始視頻中加入音頻模態后,性能顯著提升,在 VideoMME 上的分數從 64.4% 提高到了 68.4%。這些發現表明音頻包含有助于提升整體識別性能的有價值信息。
值得注意的是,經過全模態訓練并輸入音頻的 Ola 準確率甚至超過了使用原始文本字幕的結果,總體性能達到 68.4%,而使用原始文本字幕的總體性能為 67.1%。結果表明,在某些基準測試中,音頻數據可能包含超出原始文本信息的更多內容。

漸進式模態對齊的影響
我們評估了每個階段中間模型的基本性能,我們可以觀察到,從圖像、視頻到音頻的漸進式模態訓練能夠最大程度地保留先前學到的能力。

4. 總結
我們提出了 Ola,這是一款功能全面且強大的全模態語言模型,在圖像、視頻和音頻理解任務中展現出頗具競爭力的性能。我們基于漸進式模態對齊策略給出的解決方案,為訓練全模態模型提供了一種自然、高效且具競爭力的訓練策略。通過支持全模態輸入和流式解碼的架構設計改進,以及高質量跨模態視頻數據的準備,進一步拓展了 Ola 的能力。我們期望這項工作能夠啟發未來對更通用人工智能模型的研究。


























